
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
6. Share File Table Entries: fork() And dup()
대부분의 경우 파일 디스크립터는 open file table에 일대일 매핑된다. 예를 들어 프로세스는 실행되어 파일을 열고 읽고 닫는다. 이 예에서 파일은 open file table에서 유일한 엔트리를 차지한다. 어떤 다른 프로세스가 같은 파일을 동시에 읽는 경우에도, 각 프로세스는 open file table에 자신만의 엔트리를 가진다. 이런 방식으로 파일을 읽고 쓰는 일은 독립적으로 일어나고, 각각은 해당 파일에 접근할 때에도 고유한 현재 오프셋을 가진다.
하지만 open file table의 엔트리가 공유되는 몇몇 흥미로운 경우들도 있다. 그 중 하나는 부모 프로세스가 fork()로 자식 프로세스를 생성하는 경우다. 아래의 코드에서 부모 프로세스는 자식을 생성하고 완료되기를 기다린다. 자식은 현재 오프셋을 lseek()을 호출해 변경하고 종료된다. 마지막으로 부모는 현재 오프셋을 확인하고 그 값을 출력한다.
int main(int argc, char *argv[]) {
int fd = open("file.txt", O_RDONLY);
assert(fd >= 0);
int rc = fork();
if (rc == 0) {
rc = lseek(fd, 10, SEEK_SET);
printf("child: offset %d\n", rc);
} else if (rc > 0) {
(void) wait(NULL);
printf("parent: offset %d\n", (int) lseek(fd, 0, SEEK_CUR));
}
return 0;
}위 프로그램을 실행했을 때의 출력은 다음과 같다.
prompt> ./fork-seek
child: offset 10
parent: offset 10
prompt>아래의 그림은 각 프로세스 고유의 디스크립터 배열, 공유 open file table 엔트리, 그리고 그 기저에 있는 파일 시스템의 아이노드로의 참조에 대한 연결 관계를 보여주고 있다. 여기서 드디어 참조 카운트(reference count)를 사용하고 있음에 주목하자. 파일 테이블 엔트리가 공유될 때, 그 참조 카운트는 증가하며, 오직 두 프로세스 모두가 파일을 닫을 때 엔트리는 사라지게 된다.
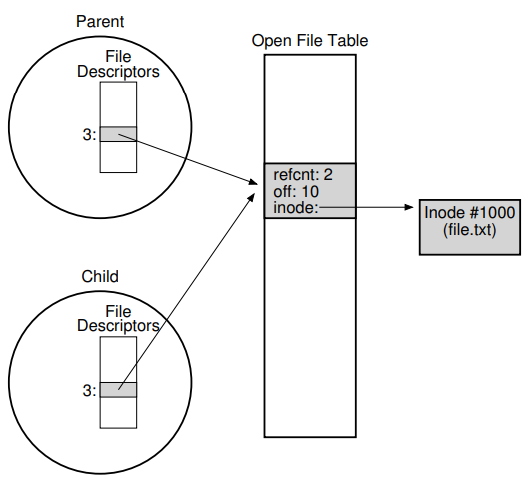
부모 자식 사이의 open file table 엔트리 공유는 상황에 따라 유용하게 쓰인다. 예를 들어 한 작업을 위해 협동하는 여러 프로세스들을 만들었을 때, 그것들은 이외의 추가적인 조정 없이도 같은 출력 파일에 쓸 수 있게 된다. fork()가 호출되었을 때 프로세스 사이에서 공유되는 것들에는 무엇이 더 있는지 알고 싶다면 man 페이지를 참고하라.
또 다른 흥미로운, 그리고 아마 더 유용한 공유 케이스는 dup() 시스템 콜을 사용할 때다. dup()은 프로세스가 이미 열려있는 파일의 디스크립터를 이용해 새로운 파일 디스크립터를 만들 수 있도록 한다. 간단한 사용 예시는 다음과 같다.
int main(int argc, char *argv[]) {
int fd = open("README", O_RDONLY);
assert(fd >= 0);
int fd2 = dup(fd);
// now fd and fd2 can be used interchangeably
return 0;
}dup() 콜은 UNIX 쉘을 만들고 출력 리디렉션과 같은 작업들을 수행할 때 유용하게 쓰일 수 있다.
7. Writing Immediately With fsync()
프로그램이 write()를 호출하는 대부분의 경우는, 그저 파일 시스템에 "미래의 어떤 시점에 영구 저장소에 데이터를 써달라."라고 말하는 것이다. 파일 시스템은 성능상의 이유로 얼마간 그런 쓰기 작업들을 메모리에 버퍼 처리한다. 나중의 어떤 시점에 쓰기 요청은 실제로 저장 장치에 전달된다. 이를 통해 호출 애플리케이션의 관점에서 봤을 때 쓰기는 빠르게 완료되는 것처럼 보이게 되고, 데이터 손실도 아주 드물게 일어나게 된다.
하지만 어떤 애플리케이션은 이런 결과적인 보장 이상의 것을 필요로 할 수도 있다. 예를 들어 DBMS에서, 정확한 복구 프로토콜의 개발은 디스크에 그때 그때 강제로 쓰기가 일어나기를 요구할 수도 있다.
이러한 종류의 애플리케이션들을 지원하기 위해, 대부분의 파일 시스템들은 추가적인 제어 API를 제공한다. UNIX에서 이 인터페이스는 fsync(int fd)이다. 프로세스가 특정한 파일 디스크립터에 대해 fsync()를 호출하면, 파일 시스템은 해당하는 파일의 모든 더티 데이터(메모리에는 올라와있지만 디스크에는 아직 쓰이지 않은 데이터)를 강제로 디스크에 쓴다. 이 모든 쓰기가 완료되면 fsync() 루틴은 리턴한다.
다음은 fsync()를 사용하는 간단한 예다. 이 코드는 파일 foo를 열고, 한 청크의 데이터를 쓴 후, fsync()를 호출해 디스크게 즉시 강제로 쓰게 한다. fsync()가 반환하면 애플리케이션은 데이터가 영구적으로 저장되었음을 알고 안전하게 다음으로 넘어갈 수 있게 된다.
int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC, S_IRUSR|S_IWUSR);
assert(fd > -1);
int rc = write(fd, buffer, size);
assert(rc == size);
rc = fsync(fd);
assert(rc == 0);흥미롭게도 위의 코드가 바라던 모든 일이 일어날 것이라 보장해주는 것은 아니다. 어떤 경우에는 foo 파일이 담겨있는 디렉토리에 대해 fsync()를 해야할 수도 있다. 이러한 단계를 추가하면 파일 그 자체도 디스크에 있음을 보장할 수 있을 뿐만 아니라, 새롭게 생성된 파일이 해당 디렉토리에 위치해 있음도 보장해준다. 놀랍지 않은 일이지만, 이러한 디테일은 종종 간과되어 많은 응용 프로그램 수준의 버그로 이어지곤 한다.
8. Renaming Files
파일에 다른 이름을 줄 수 있는 것은 유용하다. 커맨드 라인에서 이 작업은 mv 커맨드를 통해 수행될 수 있는데, 아래의 예에서는 파일 foo를 bar로 재명명하고 있다.
prompt > mv foo barstrace를 이용하면 mv가 시스템 콜 rename(char *old, char *new)를 이용하고 있음을 볼 수 있다. 이 시스템 콜은 기존 이름(old)와 새 이름(new)의 두 문자열을 인자로 가진다.
rename()이 보장하는 한 가지 흥미로운 사실은, 이것이 시스템 크래시에 대해 원자적으로 작동하게 구현되어 있다는 점이다. 만약 재명명 중에 시스템 크래시가 발생하면, 파일은 원래 이름이나 새 이름 둘 중 하나로 명명되며, 그 사이에 어떤 상태에 있지 않는다. 그러므로 rename()은 파일 상태의 원자적 갱신을 필요로 하는 특정 종류의 애플리케이션을 지원하는 데에 핵심적으로 쓰일 수 있다.
여기서 좀 더 자세하게 들어가보자. emacs와 같은 파일 편집기를 쓰고 있고, 파일의 중간에 한 줄을 삽입하려 한다고 해보자. 편집기가 새 파일이 기존 내용에 한 줄을 삽입한 것임을 보장하면서 파일을 갱신하는 방식은 다음과 같다.
int fd = open("foo.txt.tmp", O_WRONLY|O_CREAT|O_TRUNC, S_IRUSR|S_IWUSR);
write(fd, buffer, size); // write out new version of file
fsync(fd);
close(fd);
rename("foo.txt.tmp", "foo.txt");이 예에서 편집기가 한 일은 간단하다. 파일의 새 버전을 임시 이름으로 쓰고, 이를 fsync()로 디스크에 강제로 쓴다. 이후 애플리케이션이 새 파일 메타데이터와 내용이 디스크에 있음을 확신하게 되고 나면, 임시 파일을 원래 파일의 이름으로 재명명한다. 이 마지막 단계는 원자적으로 새 파일 이름을 해당 위치에 넣으면서, 동시에 파일의 옛 버전을 삭제한다. 이로써 원자적 파일 갱신이 이루어진다.
9. Getting Information About Files
우리는 파일 시스템이 저장된 파일에 대한 상당한 양의 정보도 가지고 있으리라 기대한다. 이러한 파일에 대한 데이터를 메타데이터(metadata)라 부른다. 특정 파일의 메타데이터를 보려면 stat()이나 fstat() 시스템 콜을 사용하면 된다. 이 콜들은 파일 경로명, 또는 파일 디스크립터를 받아, 아래와 같은 stat 구조체를 채운다.
struct stat {
dev_t st_dev; // ID of device containing file
ino_t st_ino; // inode number
mode_t st_mode; // protection
nlink_t st_nlink; // number of hard links
uid_t st_uid; // user ID of owner
gid_t st_gid; // group ID of owner
dev_t st_rdev; // device ID (if special file)
off_t st_size; // total size, in bytes
blksize_t st_blksize; // blocksize for filesystem I/O
blkcnt_t st_blocks; // number of blocks allocated
time_t st_atime; // time of last access
time_t st_mtime; // time of last modification
time_t st_ctime; // time of last status change
};아래는 리눅스에서의 출력이다.
prompt> echo hello > file
prompt> stat file
File: ‘file’
Size: 6 Blocks: 8 IO Block: 4096 regular file
Device: 811h/2065d Inode: 67158084 Links: 1
Access: (0640/-rw-r-----) Uid: (30686/remzi)
Gid: (30686/remzi)
Access: 2011-05-03 15:50:20.157594748 -0500
Modify: 2011-05-03 15:50:20.157594748 -0500
Change: 2011-05-03 15:50:20.157594748 -0500각 파일 시스템은 이러한 종류의 정보를 아이노드(inode)라 불리는 구조에 저장한다. 아이노드에 대한 자세한 내용은 파일 시스템 구현을 다룰 때 공부하게 될 것이다. 지금은 아이노드가 파일 시스템이 위와 같은 정보를 담기 위해 사용하는 영구 데이터 구조라는 것만 알아두자. 모든 아이노드는 디스크에 위치하며, 접근 속도를 향상 시키기 위해, 사용되는 것들의 복사본은 메모리에 캐시된다.
10. Removing Files
지금까지 파일을 어떻게 만들고 접근하는지에 대해 알아왔다. 그렇다면 파일의 삭제는 어떻게 이루어질까? 만약 UNIX를 사용하고 있다면 rm 커맨드를 생각할 것이다. 그런데 rm이 파일 삭제를 위해 쓰고 있는 시스템 콜에는 어떤 게 있을까?
foo 파일을 삭제하면서 strace를 다시 사용해보자.
prompt > strace rm foo
...
unlink("foo") = 0
...나머지 잡다한 시스템 콜들은 생략하고 unlink()를 보자. 이 시스템 콜은 삭제할 파일의 이름을 받고, 성공하는 경우 0을 반환한다. 하지만 이상한 점이 있다. 왜 remove나 delete가 아니라 unlink라는 이름을 쓰는 걸까? 이 물음에 답하기 위해서, 이제는 파일이 아닌 디렉토리에 대해 먼저 알아야 한다.
