
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
구글이나 페이스북과 같은 현대 웹 서비스에 접속한다는 것은 단지 하나의 기기와 상호 작용하는 것만이 아니라, 해당 사이트의 특정 서비스를 제공하기 위해 협력하는 수 많은 기기들로 이루어진 서비스를 이용하는 것이다.
이러한 분산 시스템을 만들 때에는 여러 새 문제들이 등장하게 되는데, 여기서 집중할 것은 오류 처리에 관한 것이다. 사실 오류가 일어나지 않는 완벽한 시스템이란 없다. 하지만 현대 웹 서비스를 만들 때, 적어도 클라이언트에게는 오류가 절대 일어나지 않는 것처럼 보이게 해야만 한다.
오류 발생의 가능성이 분산 시스템 구축에 있어서의 핵심 문제가 되는 한편, 흥미롭게도 이러한 오류 가능성이 또 하나의 기회를 시사한다. 해당 시스템을 구성하는 몇 개의 기기에서의 오류가 전체 시스템의 오류를 함축하지는 않는다는 것이다. 시스템 구성 요소들은 종종 오류를 일으키면서도, 그것들을 모아놓은 전체 시스템은 드물게 오류를 일으킬 수 있다. 이것이 분산 시스템의 핵심 미학이자 가치이며, 우리가 사용하는 거의 모든 웹 서비스의 기저에서 사용되고 있는 이유다.
다른 중요한 이슈들도 물론 있다. 예를 들어 시스템 성능이 있다. 분산 시스템들을 연결하는 네트워크를 사용하는 경우, 시스템 디자이너는 어떻게 송신 메시지 수를 줄이고 통신을 가능한 한 효율적으로 만들 것인지 등을 고려해야 한다.
보안의 경우도 중요한 고려 대상이다. 원격 사이트에 접속할 때에는 해당 사이트가 접속하려는 바로 그곳이라는 보장이 있어야 한다. 또한 해당 통신에 참여하지 않는 외부 그룹이 그 통신을 모니터링하고 메시지를 바꾸는 일도 일어나지 않도록 하는 일도 중요하다.
여기에서는 분산 시스템에서 가장 기본적인 통신(communication)에 대해서 다룬다. 분산 시스템 내의 기기들은 어떻게 다른 기기와 통신할까? 이 통신 계층에서는 어떻게 오류를 처리해야 할까?
1. Communication Basics
현대 네트워킹에서는 기본적으로 통신을 신뢰할 수 없는 것으로 본다. WAN이든 LAN이든, 패킷 손실, 손상 등은 드물지 않게 일어난다.
이런 패킷 손실, 혹은 손상을 일으키는 원인에는 많은 것들이 있다. 어떨 때는 데이터 전송 중, 전기적이거나 혹은 다른 비슷한 문제들로 인해 몇 개의 비트가 뒤집힐 수 있다. 어떤 경우는 네트워크 링크나 패킷 라우터, 혹은 심지어 원격 호스트 등, 시스템의 구성 요소들이 손상되거나 제대로 작동하지 않는 경우일 수도 있다.
하지만 가장 기초적인 패킷 손실은 네트워크 스위치, 라우터, 엔드포인트에 버퍼링 부족으로 인해 발생한다. 구체적으로, 모든 링크들이 제대로 동작하고, 시스템 내 구성 요소들이 바라던대로 동작한다고 하더라도 패킷 손실은 일어날 수 있다. 패킷이 어떤 라우터에 도착했다고 하자. 이 패킷은 처리되기 위해서 라우터 어딘가에 있는 메모리에 위치해야 한다. 그런데 많은 패킷들이 해당 라우터에 동시에 도착하면, 해당 라우터 내 메모리가 그 모든 패킷들을 수용하지 못하게 될 수도 있다. 이런 경우 라우터가 취할 수 있는 유일한 선택은 하나 이상의 패킷을 포기(drop)하는 것이다. 마찬가지의 동작이 종단의 호스트에게도 일어날 수 있다. 많은 양의 메시지를 하나의 기기에 보내면 해당 기기의 자원이 부족해져 패킷 손실이 일어날 수 있다.
패킷 손실은 네트워킹에서 일어날 수 있는 근본적인 문제다. 그렇다면 이 문제는 어떻게 처리해야할까?
2. Unreliable Communication Layers
한 가지 간단한 방법은 처리하지 않는 것이다. 어떤 응용 프로그램들은 이러한 패킷 손실이 일어나는 경우를 어떻게 처리할지를 알고 있기 때문에, 해당 프로그램들이 신뢰성이 낮은 메시징 계층과 직접 통신하도록 하는 것이 유용한 경우들이 있다. 이렇게 신뢰할 수 없는 계층의 한 가지 훌륭한 예시는 UDP/IP 네트워킹 스택에서 찾아볼 수 있다. UDP를 사용하는 경우, 프로세스는 통신 엔드포인트를 만들기 위해 소켓 API를 사용한다. 다른 기기, 혹은 같은 기기의 프로세스는 원 프로세스로 UDP 데이터그램을 보낸다.
아래의 코드는 UDP/IP 상에서 만들어진 간단한 클라이언트-서버를 보여주고 있다. 클라이언트는 서버로 메시지로 보내고, 서버는 해당 메시지에 답한다.
//UDP 예시 코드
// client code
int main(int argc, char *argv[]) {
int sd = UDP_Open(20000);
struct sockaddr_in addrSnd, addrRcv;
int rc = UDP_FillSockAddr(&addrSnd, "cs.wisc.edu", 10000);
char message[BUFFER_SIZE];
sprintf(message, "hello world");
rc = UDP_Write(sd, &addrSnd, message, BUFFER_SIZE);
if (rc > 0)
rc = UDP_Read(sd, &addrRcv, message, BUFFER_SIZE);
return 0;
}
// server code
int main(int argc, char *argv[]) {
int sd = UDP_Open(10000);
assert(sd > -1);
while (1) {
struct sockaddr_in addr;
char message[BUFFER_SIZE];
int rc = UDP_Read(sd, &addr, message, BUFFER_SIZE);
if (rc > 0) {
char reply[BUFFER_SIZE];
sprintf(reply, "goodbye world");
rc = UDP_Write(sd, &addr, reply, BUFFER_SIZE);
}
}
return 0;
}//간단한 UDP 라이브러리
int UDP_Open(int port) {
int sd;
if ((sd = socket(AF_INET, SOCK_DGRAM, 0)) == -1)
return -1;
struct sockaddr_in myaddr;
bzero(&myaddr, sizeof(myaddr));
myaddr.sin_family = AF_INET;
myaddr.sin_port = htons(port);
myaddr.sin_addr.s_addr = INADDR_ANY;
if (bind(sd, (struct sockaddr *) &myaddr, sizeof(myaddr)) == -1) {
close(sd);
return -1;
}
return sd;
}
int UDP_FillSockAddr(struct sockaddr_in *addr, char *hostname, int port) {
bzero(addr, sizeof(struct sockaddr_in));
addr->sin_family = AF_INET; // host byte order
addr->sin_port = htons(port); // network byte order
struct in_addr *in_addr;
struct hostent *host_entry;
if ((host_entry = gethostbyname(hostname)) == NULL)
return -1;
in_addr = (struct in_addr *) host_entry->h_addr;
addr->sin_addr = *in_addr;
return 0;
}
int UDP_Write(int sd, struct sockaddr_in *addr, char *buffer, int n) {
int addr_len = sizeof(struct sockaddr_in);
return sendto(sd, buffer, n, 0, (struct sockaddr *)addr, addr_len);
}
int UDP_Read(int sd, struct sockaddr_in *addr, char *buffer, int n) {
int len = sizeof(struct sockaddr_in);
return recvfrom(sd, buffer, n, 0, (struct sockaddr *) addr, (socklen_t *) &len);
}UDP는 신뢰할 수 없는 통신 계층의 훌륭한 예다. UDP를 사용하는 경우, 패킷이 손실되어 목적지에 도달하지 못하는 상황을 만날 수 있다. 이 경우 발신자는 해당 패킷 손실에 대한 정보를 제공받지도 못한다. 하지만 UDP가 어떤 데이터 손실도 막지 못한다는 것은 아니다. 예를 들어 패킷 손상을 탐지하기 위해 체크섬을 사용하는 UDP도 있을 수 있다.
하지만 많은 응용 프로그램들은 패킷 손상에 대한 걱정없이 데이터를 목적지까지 보내기를 원한다. 따라서 뭔가 추가적으로 더 필요하다. 구체적으로, 이런 신뢰할 수 없는 네트워크 위에서 신뢰할 수 있는 통신이 가능해야만 한다.
3. Reliable Communication Layers
신뢰성 있는 통신 계층을 만드려면, 패킷 손실을 다루기 위한 새로운 메커니즘과 테크닉이 필요하다. 클라이언트가 신뢰할 수 없는 통신을 이용해 서버에 메시지를 보내는 예를 살펴보자. 여기서 발신자는 어떻게 수신자가 바로 그 메시지를 받았음을 알 수 있을까?
여기서 사용할 테크닉은 acknowledgment, 줄여서 ack이라 부른다. 아이디어는 간단하다. 발신자가 수신자에게 메시지를 보내고, 수신자는 해당 메시지를 받았다는 것을 알리기 위한 짧은 메시지를 답으로 보낸다. 아래의 그림은 해당 프로세스를 보여주고 있다.
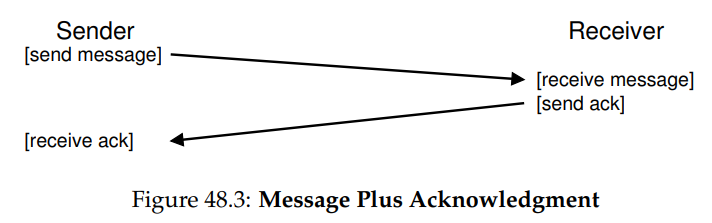
발신자는 해당 메시지의 ack를 받으면, 수신자가 원래의 바로 그 메시지를 받았음을 확신할 수 있다. 그런데 만약 발신자가 ack를 받지 못하는 경우에는 어떻게 해야할까?
이러한 경우를 처리하기 위해서는 timeout 메커니즘이 추가적으로 필요하다. 이제 발신자는 메시지를 보낼 때, 어느 정도의 기간 후에 꺼지는 타이머를 설정한다. 만약 그 시간 동안 ack를 받지 못하면 발신자는 해당 메시지가 손실되었다고 결론 내리고, 이번에는 제대로 도착하기를 희망하면서 같은 메시지를 재발송한다. 이러한 접근법이 동작하려면 발신자는 재발송할 때를 대비해 해당 메시지의 복사본을 저장해놓야한다. 이 방식을 timeout/retry라 부른다.
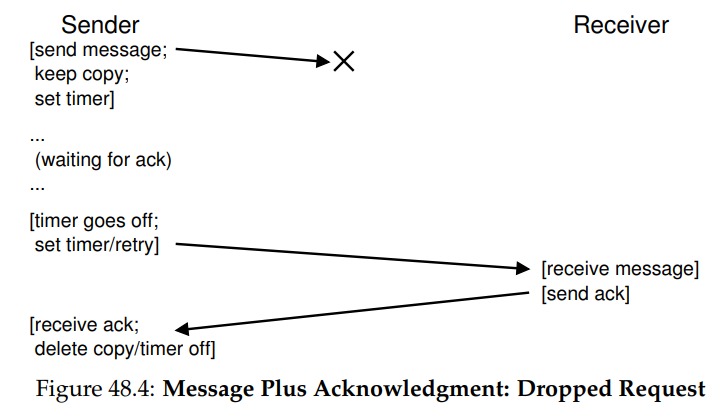
하지만 이러한 timeout/retry 방식이 충분하지는 않다. 원래 메시지가 아닌 ack 메시지가 손실되는 경우가 발생할 수 있기 때문이다.
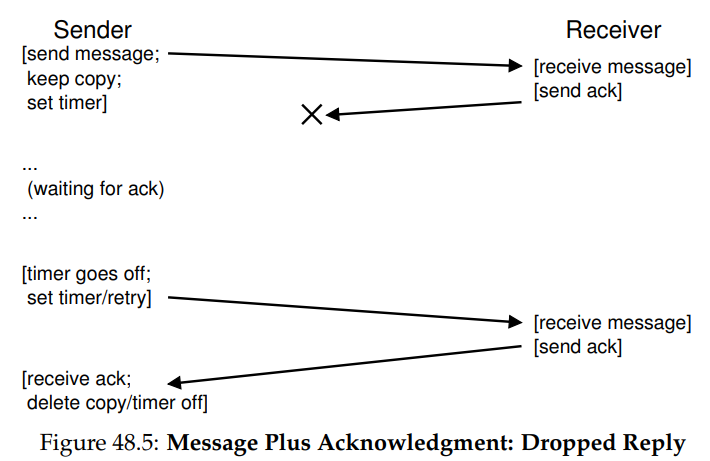
발신자의 입장에서는 ack를 받지 않았으므로 메시지를 재발송하지만, 수신자의 입장에서는 같은 메시지를 두 번 받게 된다. 이러한 경우가 괜찮은 경우도 있을 수 있지만, 일반적으로는 그렇지 않다. 따라서 신뢰할 수 있는 메시지 계층을 만들기 위해서는 수신자가 각 메시지를 정확히 한 번 받음을 보장할 수도 있어야 한다.
수신자가 데이터의 중복 전송을 감지할 수 있게 하기 위해, 발신자는 각 메시지를 고유한 방식으로 식별할 수 있어야 하고, 수신자는 각 메시지를 이미 이전에 본 적이 있는지를 확인할 방법도 가지고 있어야 한다. 수신자는 중복 전송임을 확인하면, ack을 보내주기는 하지만 해당 메시지를 응용 프로그램에는 전달하지 않는다. 이렇게 하면 발신자는 ack을 받지만, 수신자는 메시지를 두 번 받지 않고 정확히 한 번의 메시지만을 처리할 수 있게 된다.
이런 중복 메시지 확인을 위해서도 무수히 많은 방법들이 있다. 예를 들어 발신자는 각 메시지에 고유한 ID를 만들고, 수신자는 자신이 받은 모든 ID를 추적하는 방법이 있다. 다만 이러한 방식은 잘 동작하겠지만 그 비용이 너무 크다. 모든 ID를 확인하기 위해서는 너무 많은 메모리를 필요로 하기 때문이다.
더 적은 메모리를 필요로 하는, 더 간단한 해결법으로는 순차 카운터(sequence counter)라 불리는 메커니즘이 있다. 순차 카운터를 이용하는 경우, 발신자와 수신자는 우선 각자 가지고 있는 카운터의 시작 값에 대해 합의한다. 이후 메시지가 보내질 때마다 카운터의 현재 값이 메시지와 함께 보내지며, 이 카운터의 값이 메시지의 ID 역할을 한다. 메시지가 보내지고 나면 발신자는 카운터 값을 하나 올린다.
수신자는 자신의 카운터 값을 발신자로부터 받은 메시지의 ID의 기대값으로 사용한다. 해당 값이 수신자로부터 받은 메시지의 ID와 동일한 경우, 수신자는 해당 메시지를 처음 받았다고 결론 내리고, ack을 보내고 메시지를 애플리케이션에 전달한다. 이후 수신자는 카운터를 하나 올리고 다음 메시지를 기다린다.
만약 ack이 손실됐다면, 발신자는 timeout 되고 해당 메시지를 재발송한다. 이번에는 수신자의 카운터가 해당 메시지에 담긴 값보다 크므로, 수신자는 해당 메시지를 이미 예전에 받아본 적이 있음을 알 수 있다. 그러므로 이번에는 메시지에 대한 ack는 보내되, 해당 메시지를 애플리케이션으로는 전달하지 않는다. 이렇게 순차 카운터를 통한 간단한 방법을 통해 메시지 중복을 피할 수 있다.
가장 흔히 쓰이는 신뢰할 수 있는 통신 계층은 TCP/IP, 줄여서는 그냥 TCP라 부른다. TCP는 위에서 설명한 것보다 더 많은 세련된 기술들을 포함하고 있다.
4. Communication Abstractions
기본적인 메시징 계층이 마련됐으니, 이번에는 분산 시스템을 만들기 위해 써야할 통신 추상화에 대해 알아보자.
개발된 많은 방식들이 있는데, 그 중에는 OS 추상화를 이용하고 확장해 분산 환경에서 동작할 수 있게 만든 것이 있다. 예를 들어 분산 공유 메모리(distributed shared memory) 시스템은 서로 다른 기기에 있는 프로세스들이 큰 가상 주소 공간을 공유할 수 있도록 한다. 이 추상화는 분산 시스템 내의 연산을 멀티 스레드 애플리케이션에서와 비슷하게 만드는데, 유일한 차이는 스레드들이 같은 기기 내의 다른 프로세서가 아니라 다른 기기에서 실행된다는 점이다.
대부분의 DSM 시스템의 동작은 OS의 가상 메모리 시스템을 통해서다. 한 기기의 페이지에 접근할 때에는 두 가지 일이 일어날 수 있다. 첫 번째 경우로, 페이지가 이미 기기에 로컬로 있어서 데이터를 빠르게 가져올 수 있는 경우가 있다. 두 번째 경우로는 페이지가 다른 기기에 있는 경우가 있을 수도 있다. 페이지 폴트가 일어나는 경우, 페이지 폴트 핸들러는 다른 기기에 페이지를 보내 달라는 메시지를 보내고, 그 결과를 요청 프로세스의 페이지 테이블에 넣고 실행을 계속한다.
하지만 이런 방식은 많은 이유로 오늘날에는 잘 쓰이지 않는다. DSM의 가장 큰 문제점은 이것이 오류를 처리하는 방식에 있다. 예를 들어 기기가 고장났다고 해보자. 그렇다면 그 기기의 페이지에는 어떤 일이 일어날까? 분산 연산의 자료 구조들이 전체 주소 공간에 흩어져 있는 경우에는 어떨까? 이 경우, 이 자료 구조들의 일부분은 갑자기 사용할 수 없게될 것이다. 주소 공간의 일부분이 손실됐을 때 일어나는 오류를 처리하는 것은 어려운 일이다. 연결 리스트의 "next" 포인터가 손실된 주소 공간의 부분을 가리키는 경우를 생각해보자.
더 심각한 문제는 성능에 있다. 코드를 작성할 때, 보통은 메모리에의 접근 비용이 더 낮다고 가정한다. 하지만 DSM 시스템에서는 페이지 폴트가 일어나 원격 기기에서 데이터를 가져와야 하는 경우, 더 많은 비용이 발생하게 된다. 그러므로 DSM 시스템 프로그래머들은 통신이 거의 일어나지 않을 수 있게 연산을 조직하도록 해야한다. 사실상 DSM을 쓸 필요가 없어지게 하는 것이다. 이 분야에 대해 많은 연구가 있기는 했지만 실질적인 영향은 적었고, 오늘날에는 누구도 DSM을 통해 신뢰할 수 있는 분산 시스템을 만들지 않는다.
5. Remote Procedure Call (RPC)
분산 시스템 제작을 위해 OS의 추상화를 차용하는 것은 잘 동작하지 않았지만, 프로그래밍 언어의 추상화 방식을 가져온 것은 잘 동작한다. 가장 주된 추상화는 원격 프로시저 콜(remote procedure call, RPC)라 부르는 아이디어에 기반한다.
RPC 패키지는 한 가지 간단한 목표를 가지고 있는데, 원격 기기에서의 코드 실행 과정을 로컬 함수 호출만큼 간단하고 쉽게 만드는 것이다. 클라이언트는 프로시저 콜을 만든 후 얼마간의 시간이 지나 그 결과를 반환받을 수 있게 된다. 서버는 그저 익스포트(export)할 루틴들을 정의해놓기만 하면 된다. 나머지는 RPC 시스템이 전부 다 처리해주는데, 여기에는 일반적으로 두 부분들이 있다. 스텁 생성기(stub generator, 혹은 프로토콜 컴파일러, protocol compiler)와 런타임 라이브러리(run-time library)가 바로 그것이다. 이 두 부분 요소들에 대해 좀 더 자세히 알아보자.
Stub Generator
스텁 생성기가 하는 일은 간단하다. 함수의 인자들을 묶고 메시지로 보내는 일을 자동화하는 일이다. 이로 인한 많은 이점들이 있는데, 우선은 해당 코드를 직접 쓸 때 일어날 수 있는 간단한 실수들을 줄일 수 있고, 또한 그런 코드들을 최적화해 성능을 높여주기도 한다.
컴파일러의 인풋은 단순히 서버가 클라이언트에게 익스포트하고 싶어하는 함수들의 집합이다. 개념적으로는 다음과 같은 것이라 생각할 수 있다.
interface {
int func1(int arg1);
int func2(int arg1, int arg2);
}스텁 생성기는 이와 같은 인터페이스를 가지고 몇 개의 다른 코드들을 만든다. 클라이언트에게는 클라이언트 스텁(client stub)이 생성되는데, 이는 인터페이스에 명시된 각 함수들이 포함되어 있다. 이 RPC 서비스를 쓰고자 하는 클라이언트 프로그램은 이 클라이언트 스텁에 연결하고 그 안의 함수를 호출한다.
내부적으로, 클라이언트 스텁 내의 각 함수들은 RPC를 수행하기 위해 필요한 모든 일들을 한다. 클라이언트에게 코드는 그저 함수 호출로 보이지만, 내부적으로 클라이언트 스텁 내의 코드는 다음과 같은 일을 한다.
- 메시지 버퍼 생성
+ 메시지 버퍼는 보통 그저 특정 사이즈의 연속적인 바이트 배열이다. - 필요한 정보들을 메시지 버퍼로 묶음
+ 이 정보에는 호출될 함수의 식별자, 함수에 필요한 인자 등이 포함되어 있다.
+ 이렇게 정보들을 하나의 연속적인 버퍼에 모두 집어 넣는 과정을 가리켜 인자 합병(marshaling), 또는 메시지 직렬화(serialization)이라 부른다. - 목적 RPC 서버에 메시지 전송
+ RPC 서버를 이용한 통신 및 동작에 필요한 모든 상세 정보들은 RPC 런타임 라이브러리에 의해 처리된다. - 응답 대기
+ 함수 호출은 보통 동기적(synchronous)이므로, 해당 호출은 완료될 때까지 대기한다. - 리턴 코드 및 다른 인자들 풂
+ 함수가 단일한 리턴 코드를 반환하면 이 과정은 간단해진다.
+ 하지만 더 복잡한 함수들은 좀 더 복잡한 결과를 반환하고, 따라서 스텁은 이것들도 잘 풀어낼 수 있어야 한다.
+ 이 단계를 가리켜 합병해제(unmarshaling), 또는 역직렬화(deserialization)라 부른다. - 호출자에 반환
+ 클라이언트 스텁에서 클라이언트 코드로 반환한다.
서버의 경우에도 코드가 생성되며, 다음과 같은 단계를 거친다.
- 메시지 풀기
+ 합병해제, 혹은 역직렬화라 부르는 과정으로, 들어오는 메시지로부터 정보들을 꺼낸다.
+ 함수 식별자와 인자 등이 추출된다. - 실제 함수 호출
+ 원격 함수가 실제로 실행되는 지점이다.
+ RPC 런타임이 ID로 지정된 함수를 호출하고 적절한 인자를 전달한다. - 결과 패키징
+ 반환 인자들이 다시 단일 응답 버퍼로 합병된다. - 응답 보내기
+ 호출자에게 응답을 보낸다.
스텁 컴파일러에 대해 고려해봐야 할 중요한 이슈들이 몇 가지 더 있다. 첫 번째는 복잡한 인자를 사용하는 경우다. 복잡한 자료 구조의 경우는 어떻게 패키징 하고 보낼 수 있을까? 예를 들어 write() 시스템 콜을 호출하는 경우에는 정수형 파일 디스크립터, 버퍼 포인터, 얼마나 많은 바이트를 쓸지를 가리키는 크기의 세 인자를 전달해야한다. RPC 패키지는 포인터를 전달 받았을 때, 해당 포인터를 어떻게 해석할지를 알아야 하고, 그에 따른 올바른 액션을 수행할 수 있어야 한다. 보통 이는 잘 알려진 타입을 사용하거나, 컴파일러가 어느 바이트를 직렬화할지 알 수 있도록 자료 구조에 대한 추가 정보를 표기함으로써 이루어진다.
중요한 또 다른 이슈로는 병행성의 측면에서의 서버 조직이다. 간단한 서버는 간단한 반복문 내에서 요청을 대기하고 한 번에 한 요청을 처리한다. 하지만 이건 너무 비효율 적이다. 만약 한 RPC 콜이 블럭하면 서버 자원들은 낭비되기 때문이다. 그러므로 대부분의 서버는 병행성을 살리는 방식으로 구축된다. 흔히 사용되는 조직 방식은 스레드 풀(thread pool)을 이용하는 것이다. 이 방식에서는 서버가 시작할 때 유한한 스레드 집합이 생성된다. 메시지는 도착하면 스레드 풀 내의 작업자 스레드(worker thread)로 분배되고, 이 스레드에서는 RPC 콜의 작업이 수행되어 최종 응답을 해준다. 이 시간 동안 메인 스레드는 계속해서 다른 요청들을 받아 다른 작업자 스레드들로 배치한다. 이런 조직 구조는 서버 내의 동시 실행을 가능케 함으로써 활용도를 높인다. 물론 비용도 있는데, 이제 RPC가 제대로 작동하기 위해 락 등의 동기화 기법들을 사용해야 하므로 프로그래밍의 복잡도가 올라가게 된다.
Run-Time Library
런타임 라이브러리는 RPC 시스템 내의 중요한 일 대부분을 처리하며, 대부분의 성능 및 신뢰성 이슈가 여기서 처리된다. 이 런타임 계층에서의 주요 문제 몇 가지들에 대해 논의해보자.
첫 번째로 해결해야 하는 문제는 원격 서비스의 위치에 대한 것이다. 가장 간단한 방식은 이미 존재하는 네이밍 시스템, 즉 현재 인터넷 프로토콜에서 제공하는 호스트명과 포트 번호를 사용하는 것이다. 이러한 시스템에서 클라이언트는 원하는 RPC 서비스를 실행하는 기기의 호스트명이나 IP 주소, 그리고 사용되는 포트의 번호를 알아야 한다. 그러면 프로토콜 스위트는 시스템 내 아무 기기로부터 특정 주소로 패킷을 라우팅하는 메커니즘을 제공해야 한다.
클라이언트가 어느 서버에 특정 원격 서비스를 요청해야할지 알게 됐다면, 다음 문제는 RPC가 어떤 전송 레벨 프로토콜에서 만들어져야 할지를 정해야한다. 구체적으로는 RPC 시스템이 TCP/IP 같이 신뢰성 있는 프로토콜을 사용할 것인지, 혹은 UDP/IP와 같이 신뢰할 수 없는 통신 계층을 사용할지 등을 정해야 한다. 순진하게 생각하면 요청이나 응답이 신뢰성을 가져야 하니 TCP 같이 신뢰성 있는 프로토콜을 써야할 것 같다.
하지만 신뢰할 수 있는 통신 계층 위에 RPC를 만드는 것은 큰 성능상 비효율로 이어질 수 있다. 위에서 논의했던 신뢰할 수 있는 통신 계층의 동작 방식을 다시 한 번 살펴 보자. 클라이언트가 서버에 RPC 요청을 보내면, 서버는 ack과 함께 응답을 보내 요청을 제대로 받았음을 알려줘야 한다. 비슷하게 서버가 응답을 클라이언트에게 보내면, 클라이언트 또한 서버에 ack을 보내 제대로 받았음을 알려줘야 한다. 신뢰성 있는 통신 계층 위에 RPC와 같은 요청/응답 프로토콜을 만들면 두 개의 추가적인 메시지 전송이 필요해진다.
이러한 이유로 RPC 패키지들은 UDP와 같은, 신뢰성 없는 통신 계층 위에 만들어진다. 이는 RPC 계층을 좀 더 효율적으로 만들지만, RPC 시스템이 스스로 신뢰성을 보장할 수단을 마련해야 하게 만든다. RPC 계층은 위에서 논의한 timeout/retry, ack과 같은 방식을 이용해 그런 신뢰성을 보장한다. 순차 카운터와 같은 것을 사용함으로써 통신 레이어는 각 RPC가 많아도 한 번 일어남을 보장할 수 있다.
Other Issues
RPC 런타임이 해결해야 할 다른 이슈들도 있다. 예를 들어, 원격 호출이 완료되기까지 너무 오래 걸리는 경우에는 어떤 일이 일어날까? 타임아웃을 사용할 때, 너무 오래 걸리는 원격 호출은 클라이언트에게 실패로 보이고, 따라서 재발송을 일으키게 되므로 반드시 따로 올바르게 처리할 필요가 있다. 한 가지 방법은 응답이 즉시 만들어지지 않는 경우, 수신자로부터 발신자로의 명시적인 ack을 사용하는 것이다. 이를 통해 클라이언트는 서버가 해당 요청을 제대로 받았음을 알 수 있게 된다. 그러면 얼마간의 시간이 지나고 나서, 클라이언트는 주기적으로 서버가 아직도 해당 요청에 대한 작업을 하고 있는지를 물어본다. 만약 서버가 계속 "yes"라고 대답하면 클라이언트는 계속해서 기다린다.
런타임은 또한 단일 패킷에 딱 맞는 것 이상으로 큰 인자를 가지는 프로시저 콜의 경우도 처리해줘야 한다. 어떤 로우 레벨 네트워크 프로토콜들은 그런 발신자 측 단편화(큰 패킷을 작은 패킷 여러 개로 나눔)와 수신자 측 재조립(작은 여러 파트를 하나의 큰 전체로)을 지원하는데, 만약 이런 것이 없다면 RPC 런타임은 그런 기능을 스스로 구현해야 한다.
많은 시스템들이 다루는 다른 이슈는 바이트 순서(byte ordering)가 있다. 어떤 시스템은 빅 엔디안을 쓰고, 또 어떤 시스템은 리틀 엔디안을 쓰는데, 이렇게 서로 다른 엔디안을 쓰는 시스템들 사이의 통신을 어떻게 가능케 할지에 대해서도 처리해줘야 하기 때문이다.
RPC 패키지는 보통 이 문제를 그 메시지 포맷 내의, 잘 정의된 엔디안을 제공함으로써 해결한다. Sun의 RPC 패키지에서는 XDR 레이어가 이러하 기능을 제공한다. 만약 기기가 XDR과 맞는 엔디안의 메시지를 보내거나 받으면 메시지는 예상대로 보내지거나 받아진다. 한편, 만약 기기가 다른 엔디안을 쓰는 시스템과 통신하면 메시지의 각 정보는 변환되어야 한다. 때문에 엔디안의 차이는 약간의 성능 대가 지불을 필요로 한다.
마지막 이슈는 클라이언트에게 비동기 통신을 허용하고 성능 최적화를 가능케 할지를 결정하는 것이다. 구체적으로, 전형적인 RPC들은 동기적으로 동작하게 만들어진다. 즉 클라이언트는 프로시저 콜 요청을 보내고 그로부터의 반환을 대기한다. 하지만 이러한 대기가 길어질 수 있고, 그 시간 동안 클라이언트는 다른 것을 하고 싶을 것이기 때문에, 어떤 RPC 패키지들은 RPC를 비동기적으로 부를 수 있도록 하기도 한다. 비동기 RPC 요청이 만들어지면 RPC 패키지는 요청을 보내고 즉시 리턴한다. 클라이언트는 이제 다른 RPC를 호출하거나 유용한 연산을 하는 등의 일들을 할 수 있다. 어떤 시점에 클라이언트는 비동기 RPC의 결과를 알고 싶을 수도 있다. 그때는 다시 RPC 계층에 콜을 보내 진행중인 RPC가 완료되어 반환 인자들에 접근할 수 있을 때까지 대기시킨다.
