
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
Andrew File System은 1980년대 카네기 멜런 대학교에서 만들어진 것으로, 그 주 목적은 확장에 있다. 최대한 많은 수의 클라이언트를 지원할 수 있는 분산 파일 시스템 서버를 만드려면 어떻게 해야할까?
설계와 구현의 다양한 측면들이 이러한 확장 가능성에 영향을 미치는데, 그 중 가장 중요한 것은 클라이언트와 서버 사이의 프로토콜이다. 예를 들어 NFS 프로토콜에서 클라이언트는 주기적으로 캐싱된 내용이 변했는지를 확인해야 한다. 이러한 확인은 서버 자원을 사용하므로, 잦은 내용 확인은 서버가 응답할 수 있는 클라이언트의 수를 제한하게 되고, 따라서 확장 가능성도 제한되게 된다.
AFS는 사용자에게 이해할 만한 동작을 제공하는 것을 최우선 과제로 삼는다는 점에서도 NFS와 다르다. NFS에서 캐시 일관성은 세부적인 낮은 수준의 구현 직접 의존하고 있으므로 설명하기 어렵다. 이와 달리 AFS에서 캐시 일관성은 간단하고 이해하기도 쉽다. 파일이 열릴 때 일반적으로 클라이언트는 서버로부터 데이터의 최신본을 받아올 수 있다.
1. AFS Version 1
여기에서는 두 가지 버전의 AFS에 대해 논의하게 될 것이다. 첫 번째 버전은 기본적인 설계는 갖추고 있으나, 원하는 만큼의 확장성은 가지고 있지 않다.
모든 버전의 AFS에서 가장 기본적인 것은 파일에 접근하는 클라이언트 기기의 로컬 디스크에 전체 파일 캐싱(whole-file caching)을 하는 것이다. open()을 통해 파일을 열면 파일 전체가 서버로부터 불려와 로컬 디스크의 파일에 저장된다. 이후 애플리케이션이 호출하는 read()와 write()는 파일이 저장된 로컬 파일 시스템으로 리다이렉트되며, 따라서 추가적인 네트워크 통신이 필요하지 않게 된다. 마지막으로 close()가 호출되면 파일은 모두 서버에 저장된다. NFS의 경우는 블럭 단위로, 로컬 디스크가 아닌 클라이언트 메모리에 캐싱한다는 차이점을 염두에 두자.

이제는 좀 더 자세하게 알아보자. 클라이언트 애플리케이션이 open()을 호출할 때, AFS의 클라이언트-사이드 코드는 서버에 Fetch 프로토콜 메시지를 보낸다. Fetch 프로토콜 메시지는 파일 서버에 접근하고자 하는 파일의 전체 경로명을 전달한다. 서버는 이를 가지고 경로명을 순회해 원하는 파일을 찾고 전체 파일을 클라이언트에게 다시 담아 보낸다. 크라이언트-사이드 코드는 이 파일을 클라이언트의 로컬 디스크에 캐싱한다.
위에서 말했듯 이후의 read(), write()는 파일의 로컬 복사본으로 리다이렉트된다. read()와 write()가 로컬 파일 시스템의 시스템 콜과 같이 동작하므로, 이를 사용하는 경우 파일의 블럭들은 클라이언트 메모리에도 캐싱된다. 마지막으로 모든 작업이 끝나면 AFS 클라이언트는 파일이 수정된 적이 있는지를 확인하고, 만약 그렇다면 새 버전을 서버로 보내 저장한다. 이때는 Store 프로토콜 메시지를 사용하며, 전체 파일 및 그 경로명을 서버로 보내 영구적으로 저장한다.
해당 파일에 대한 다음 접근은 좀 더 효율적으로 일어난다. 클라이언트-사이드 코드는 우선은 서버를 통해 해당 파일이 수정된 적이 있는지를 확인한다. 만약 수정이 되지 않았다면 클라이언트는 로컬 디스크에 저장된 복사본을 사용하면 되고, 이 경우 추가적인 네트워킹은 필요하지 않으므로 높은 성능을 기대할 수 있다. 위의 AFsv1 Protocol Highlights는 AFSv1에서 주목할 만한 프로토콜 메시지들을 보여주고 있는데, 초기 버전의 프로토콜은 파일 컨텐츠만을 캐싱했다는 점에 유의하자. 예를 들어 디렉토리의 경우는 오직 서버에만 저장되고, 캐싱되지 않는다.
2. Problems with Version 1
AFSv1의 주된 문제에는 두 가지가 있다.
- 경로 순회의 비용이 너무 높음
클라이언트는 Fetch와 Store 프로토콜 메시지에 전체 경로명을 담아 보낸다. 해당 메시지를 받은 서버는 원하는 파일에 접근할 때까지 루트부터 순차적으로 트리를 순회해나가야 한다. 많은 수의 클라이언트가 서버에 동시에 접근하게 되는 경우, 서버는 디렉토리 경로를 따라가는 데에만 대부분의 CPU 시간을 소모하게 된다.
- 클라이언트가 너무 많은 TestAuth 프로토콜 메시지를 보냄
NFS에서 GETATTR 메시지가 그랬던 것과 같이, AFS에서는 많은 TestAuth 메시지가 만들어진다. 서버는 클라이언트에게 해당 파일을 써도 된다고 말해주기 위해 너무 많은 시간을 쓰게 된다. 대부분 경우 파일에 변화는 일어나지 않지만 말이다.
AFSv1에는 사실 또 다른 문제 두 가지도 있다. 첫 번째는 서버 간 부하 불균형 문제다. 이 문제는 볼륨을 도입함으로써 해결된다. 두 번째는 클라이언트마다 하나의 프로세스를 사용함으로써 일어나는 컨텍스트 스위칭 등의 오버헤드 발생이다. 이는 AFSv2에서 프로세스 대신 스레드를 사용함으로써 해결된다.
3. Improving the Protocol
위에서 언급된 두 개의 주 문제는 AFS의 확장 가능성을 제한한다. 서버 CPU가 전체 시스템의 병목이 되고, 각 서버는 많아야 20개의 클라이언트에게만 서비스를 제공할 수 있었다. 서버는 Fetch 및 Store 메시지를 받을 때마다 TestAuth 메시지도 받아 디렉토리 트리르 순회하는 데 대부분의 시간을 사용한다. 서버 상호작용을 최소한으로 줄이는 프로토콜은 어떻게 만들 수 있을까? 서버 상호작용은 어떻게 효율적으로 만들 수 있을까?
4. AFS Version 2
AFSv2는 클라이언트/서버 상호작용의 수를 줄이기 위해 콜백(callback)이라는 개념을 도입했다. 콜백이란 간단히 말해 클라이언트가 캐싱하고 있는 파일이 수정되면 이를 클라이언트에게 알려주겠다는, 서버로부터 클라이언트로의 약속이다. 이러한 상태(state)를 시스템에 추가함으로써, 클라이언트는 더 이상 서버에 연결해 캐싱된 파일이 유효한지를 확인할 필요가 없고, 서버가 해당 파일이 이제는 유효하지 않다고 말해줄 때까지 그 파일을 유효한 것으로 간주하고 사용할 수 있게 된다.
AFSv2는 또한 클라이언트가 원하는 파일을 명시하기 위해 경로명을 쓰지 않고, NFS의 파일 핸들과 비슷한 파일 식별자(file identifier, FID)라는 개념도 도입해 사용한다. AFS의 FID에는 볼륨 식별자, 파일 식별자, 그리고 "uniquifier"(파일이 삭제된 경우 볼륨 및 파일 ID를 재사용하기 위해 사용)가 포함된다. 이제는 원하는 파일을 찾기 위해 서버에 전체 경로명을 알려 주고 서버가 그 경로를 따라가게 할 필요 없이, 클라이언트가 경로명을 따라 순회하고 그 결과를 캐싱함으로써 서버의 부하를 줄인다.
예를 들어, 클라이언트가 파일 /home/remzi/notes.txt라는 파일에 접근하려 한다 하자. 클라이언트는 우선 home 디렉토리의 내용들을 Fetch하고 이를 로컬 디스크 캐시에 넣고 home 에대한 콜백을 설정한다. 이후 remzi 디렉토리에 대해서도 마찬가지의 작업을 한다. 마지막으로는 notes.txt를 Fetch하고 이를 로컬 디스크에 캐싱한 후, 호출 애플리케이션에 파일 디스크립터를 반환한다.

NFS와의 핵심적인 차이는, AFS의 경우 디렉토리나 파일을 가져올 때 서버에 콜백을 설정하고 해당 파일에 변경 사항이 생기는 경우 클라이언트에 곧장 알리도록 한다는 것이다. 그 이점은, 파일에 처음 접근하는 경우 서버에 많은 프로토콜 메시지를 보내야 하지만, 이후의 첩근의 경우 로컬에서만 이루어지므로 추가적인 서버 상호작용이 필요하지 않다는 것이다. 따라서 파일이 클라이언트에 캐싱되어 있는 보통의 경우, AFS는 거의 로컬 디스크 기반 파일 시스템과 동일한 정도의 성능을 보인다.
5. Cache Consistency
NFS에서 대해 논의할 때 언급했던, 고려해야할 캐시 일관성의 문제로는 두 가지가 있다. 바로 업데이트 가시성 문제(update visibility problem)와 오래된 캐시 문제(stale cache problem)다. 업데이트 가시성 문제는 언제 서버에 파일의 최신 버전을 업데이트할 것인가 하는 것이고, 오래된 캐시 문제는 서버가 새 버전을 가지게 되고 나서 클라이언트가 새 버전을 볼 수 있을 때까지 얼마나 걸리느냐 하는 문제였다.
콜백과 전체 파일 캐싱을 통해, AFS에서의 캐시 일관성 문제는 설명하기 쉬우며, 이해하기도 쉽다. 여기서 고려해야 할 두 가지 경우가 있는데, 하나는 서로 다른 기기들에 있는 프로세스의 일관성이고, 다른 하나는 같은 기기 내에 있는 프로세스들 간의 일관성이다.
서로 다른 기기들인 경우, AFS는 업데이트된 파일이 닫힐 때 업데이트를 반영하고 저장된 캐시를 무효화한다. 클라이언트가 파일을 열고 쓰고 결국 닫으면, 이 때 새 파일이 서버에 저장된다. 그러면 서버는 기존의 파일 복사본을 캐싱하고 있는 클라이언트와의 콜백을 끊는다. 이 콜백 단절은 서버가 각 클라이언트에게 해당 파일에 대한 콜백이 더 이상 유효하지 않다고 알림으로써 일어난다. 이 단계는 클라이언트가 해당 파일의 오래된 버전을 읽지 않도록 보장한다. 이후 해당 파일을 읽으려는 클라이언트의 경우, 콜백이 끊어졌기 때문에 서버로부터 그 파일을 다시 가져와야 하기 때문이다. 단, AFS는 같은 기기에 있는 프로세스들의 경우를 예외로 두는데, 이 경우 파일 쓰기는 다른 로컬 프로세스들에게 곧장 보이게 된다.
여러 기기들의 경우 고려해야 할 흥미로운 케이스가 있는데, 바로 서로 다른 기기들이 동시에 한 파일을 쓰고자 할 때다. AFS는 이를 위해 last writer wins 방식을 채택하고 있다. 가장 마지막에 close()를 호출한 클라이언트의 전체 파일이 서버에 반영된다는 것이다. 여기서 NFS와의 차이점을 염두에 두자. NFS의 경우 독립적으로 쓰인 파일 블럭들이 서버에 보내지며, 따라서 서버에 있는 파일은 여러 클라이언트들이 쓴 내용들의 혼합 결과가 될 수도 있다.

위 타임라인은 서버에 있는 파일 F에 대해 일어날 수 있는 여러 시나리오들을 보여주고 있다.
6. Crash Recovery
AFS에서의 충돌 복구 문제는 NFS보다 더 복잡하다. 예를 들어, 잠시동안 서버 S가 클라이언트 C1에 컨택할 수 없게 됐다고 해보자. 이 시간동안 S가 C1에 콜백 리콜 메시지를 보낸다면 어떻게 될까? 예를 들어 C1이 파일 F를 자신의 로컬 디스크에 캐싱해놓고, 다른 클라이언트 C2가 F를 업데이트 했다고 하자. 이 경우 서버는 F를 캐싱하고있는 모든 클라이언트에 해당 파일을 캐시로부터 삭제하라는 메시지를 보내야하지만, C1은 그 메시지를 받을 수 없다.
따라서 C1은 다음에 F에 접근할 때, 우선 서버에 자신이 가지고 있는 파일 F의 복사본이 여전히 유효한지를 물어봐야 한다. 만약 그렇다면 C1은 캐싱된 것을 사용하고, 그렇지 않으면 서버로부터 새 버전을 가져오게 될 것이다.
충돌 이후 서버 복구 문제는 더 복잡하다. 서버는 콜백들을 메모리에 보관하고 있으므로, 서버가 재시작되는 경우, 이 서버는 어떤 클라이언트 기기가 어떤 파일을 가지고 있는지 알 수가 없다. 따라서 서버가 재시작되는 경우, 서버의 각 클라이언트는 서버에 충돌이 일어났다는 것을 알고, 파일들에 접근하기 전에 자신이 캐싱하고 있는 내용들이 유효한지를 재확인해야 한다.
따라서 AFS에서 서버 충돌은 큰 문제다. 설계자는 각 클라이언트가 서버 충돌을 제때 알 수 있도록 만들거나, 혹은 클라이언트가 오래된 파일 접근을 허용하는 것을 감수해야 한다. 이러한 복구를 구현하는 방법에도 여러 가지가 있다. 예를 들면 서버가 재시작되면 해당 서버의 모든 클라이언트에게 메시지를 보내는 방법을 사용할 수 있다. 혹은 클라이언트가 주기적으로 서버가 살아 있는지를 확인하는 방법을 사용할 수도 있다.
7. Scale And Performance Of AFSv2
AFSv2는 v1에 비해 더 높은 확장성을 가진다. 이제 각 서버는 거의 50개의 클라이언트를 지원할 수 있다. 또 다른 이점으로는 클라이언트 사이드의 성능이 거의 로컬 성능에 가까워졌다는 것이다. 대부분의 경우 모든 파일 접근은 로컬에서 일어난다. 파일 읽기는 로컬 디스크 캐시, 혹은 메모리까지만 가면 된다. 오직 클라이언트가 새로운 파일을 만들거나 이미 존재하는 파일에 쓰는 경우에만 서버에 Store 메시지를 보내게 된다.
AFS의 성능을 NFS와 비교한다면 어떨까? 아래의 표는 두 파일 시스템 사이의 질적 비교 결과를 보인다.
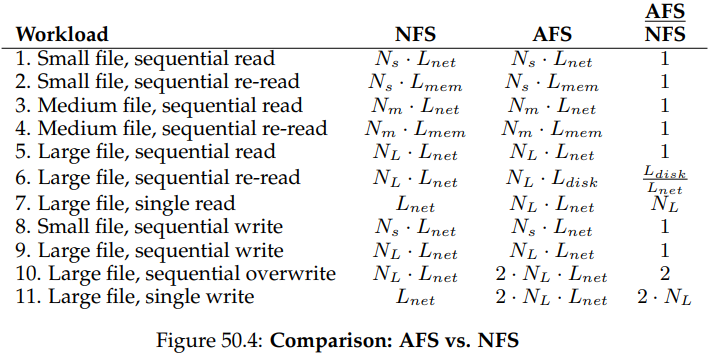
여기서 은 각각 접근하고자 하는 파일이 가지는 블럭의 수를 나타낸다. 작은 파일은 , 중간 파일은 , 큰 파일은 개의 블럭을 가지고 있다. 와 의 경우는 클라이언트의 메모리 안에 들어갈 수 있는 크기이고, 은 로컬 디스크에는 들어갈 수 있지만 메모리에는 들어갈 수 없는 크기다.
은 각각 원격 서버의 한 파일 블럭에 접근하기 위해 걸리는 단위 시간과 로컬 메모리에 접근할 때 걸리는 시간, 디스크 접근 시간을 나타낸다. 이때 이라 가정한다.
마지막으로는 파일에의 첫 번째 접근 시에는 캐시 히트가 일어나지 않는다고 가정하고, 이후의 파일 접근에서는 캐시 히트가 일어난다고 가정한다.
위 표는 각 워크로드에 대해 NFS와 AFS에 필요한 대략적인 시간 및 그 비율을 보여준다. 이를 통해서는 다음과 같은 사실들을 알 수 있다. 우선 대부분의 경우 각 시스템의 성능은 거의 비슷하다. 파일을 처음 읽는 세 경우(1, 3, 5), 원격 서버로부터 파일을 가져오는 시간이 대부분이므로 두 시스템에서는 비슷한 시간이 걸린다. AFS의 경우 클라이언트가 서버로부터 전체 파일을 가져와 자신의 로컬 디스크에 써야하므로 이 시간이 좀 더 오래 걸릴 것이라 생각할 수도 있다. 하지만 그 차이는 클라이언트의 로컬 파일 시스템 캐시에 버퍼 처리함으로써 거의 사라진다. 비슷하게 AFS가 로컬 디스크에 캐싱된 복사본을 읽기 때문에 더 느릴 것이라 생각할 수 있지만, 이 또한 로컬 파일 시스템의 메모리 캐싱을 통해 해결될 수 있다.
두 번째로, 큰 파일을 순차적으로 다시 읽는 경우(6)에서 흥미로운 차이가 나타난다. AFS는 큰 로컬 디스크 캐시를 가지고 있고, 파일에 다시 접근할 때에는 거기에서 파일에 접근한다. 이와 달리 NFS는 클라이언트 메모리에만 블럭들을 캐싱할 수 있다. 그 결과 큰 파일을 읽는 경우, NFS 클라이언트는 전체 파일을 원격 서버에서 다시 가져와야 한다. 따라서 AFS는 NFS보다 배 빠르다. 이 경우 NFS에서는 서버 부하도 증가되어 확장성에 영향을 미친다는 것도 알 수 있다.
세 번째로, 새 파일의 순차적 쓰기의 경우 두 시스템에서 비슷한 시간이 걸린다(8, 9). 이 경우 AFS는 파일을 로컬 캐시 복사본에 쓰고, 파일을 닫을 때 프로토콜을 통해 서버에 강제로 쓰게 한다. NFS는 쓰기 작업을 클라이언트 메모리에 버퍼링하고, (클라이언트 쪽에 일정 수준 이상 메모리가 부족해지는 등의 경우 서버에 몇몇 블럭들을 쓰기도 하지만) 파일이 닫힐 때 서버에 씀으로써 NFS의 flush-on-close 일관성을 지킨다. 여기서도 AFS가 몇몇 블럭들을 쓰는 NFS와 달리 모든 데이터를 로컬 디스크에 쓰므로 더 느릴 것이라 생각할 수 있다. 하지만 이러한 쓰기는 로컬 파일 시스템에서 이루어진다. 쓰기는 일단 페이지 캐시에 커밋되고 나중에 디스크로 커밋된다. 따라서 여기서도 AFS는 클라이언트 OS의 메모리 캐싱이 가져다 주는 성능 상 이점을 그대로 활용할 수 있는 것이다.
네 번째, AFS가 순차 덮어쓰기(10)의 경우에서는 떨어지는 성능을 가짐을 볼 수 있다. 앞에서는 새로운 파일을 만드는 쓰기를 다뤄왔지만, 이번 경우는 파일이 이미 존재하고 덮어 쓰이는 경우다. AFS는 낮은 덮어 쓰기 성능을 가지는데, 클라이언트가 파일을 덮어쓰기 위해서 전체 파일을 가져와야 하기 때문이다. NFS의 경우는 이와 달리, 덮어 쓰기 전에 읽기를 수행하지 않고 그냥 덮어 쓰면 된다.
마지막으로, 큰 파일에서 작은 데이터 일부에만 접근하는 경우는 AFS보다 NFS가 훨씬 더 잘 처리한다(7, 11_. 이 경우, AFS는 파일을 열 때 파일 전체를 가져오고, 그 중 극히 일부에만 접근한다. 특히 그 파일이 수정되는 경우, AFS는 전체 파일을 서버로 보내 써야 하므로 훨씬 더 나쁘다. NFS는 블럭 기반의 프로토콜으로, 읽거나 쓸 크기에 비례한 만큼의 I/O를 수행한다.
전체적으로는 NFS와 AFS가 그렇게 큰 성능상 차이를 보이지 않음을 알 수 있다. 두 시스템 간의 차이가 유의미한지는 늘 그렇듯, 워크로드가 어떤지에 달려 있다.
8. AFS: Other Improvements
AFS의 설계자들은 시스템을 더 쉽게 사용하고 관리할 수 있도록 몇 가지 기능들을 추가했다. 예를 들어 AFS는 클라이언트들에 진정한 전역 네임스페이스를 제공하고, 모든 파일이 모든 클라이언트들에서 동일한 방식으로 이름지어지게 한다. NFS에는 이와 달리 각 클라이언트가 자신이 원하는 방식으로 NFS 서버를 마운트할 수 있게 하고, 파일이 여러 클라이언트 사이에서 비슷하게 이름 지어지는 것은 컨벤션에 맡긴다.
AFS는 또한 보안을 중요하게 생각했고, 사용자 인증을 위한 메커니즘들을 통합했으며, 사용자가 원한다면 파일들을 프라이빗하게 만드는 것도 가능하게 했다. NFS는 반대로 오랫동안 보안에 대해서는 상당히 기초적으로만 지원했다.
AFS는 또한 유연한 사용자-관리 접근 제어 기능을 가지고 있다. 따라서 AFS에서 사용자는 누가 어떤 파일에 접근할 수 있는지를 제어할 수 있다. NFS는 대부분의 UNIX 파일 시스템과 같이 이러한 종류의 공유에 대해서는 훨씬 적은 지원만을 한다.
마지막으로 AFS는 시스템 관리자가 서버들을 좀 더 간단히 관리할 수 있게 하기 위한 툴들도 제공한다.
9. Summary
AFS는 어떻게 분산 파일 시스템이 NFS와 다른 방식으로 만들어질 수 있는지를 보여준다. AFS의 프로토콜 설계는 특히 중요하다. 서버와의 상호작용을 최소화함으로써 각 서버는 많은 클라이언트들을 지원할 수 있게 되고, 특정 사이트를 관리하기 위해 필요한 서버의 수도 줄어들게 된다. 단일 네임스페이스, 보안, 접근 제어 등의 다른 기능들도 AFS를 사용하기 좋게 만드는 것들이다. AFS가 제공하는 일관성 모델도 이해하기 쉽고, NFS에서 가끔 볼 수 있는 오작동도 발생하지 않는다.
하지만 요즘 AFS는 거의 쓰이지 않는다. NFS는 오픈 표준이 되어 많은 다른 제조사들도 이를 지원한다. 하지만 AFS는 그것이 제공하는 아이디어들을 제외하고, 그 자체로써는 잘 쓰이지 않는다. 사실 NFSv4가 서버 상태를 추가하게 되면서, 이는 좀 더 기본 AFS 프로토콜에 가까워지고 있다.
