
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
1. Introduction
넓은 범위의 보안 목표 및 보안 정책들을 다뤄야 한다면, OS에는 어떤 것이 필요할까? OS는 프로세스를 위한 서비스들을 제공하고, 그 중 일부는 보안에 관한 것이다.
OS가 서비스를 수행할지, 혹은 수행을 거부할지를 결정하는 데 있어서 중요한 것은 "맥락"이며, 그 중에서도 가장 중요한 것은 "누가 그것을 요청하는지"다. 만약 시스템 관리자가 OS에 새로운 프로그램을 설치하라고 요청한다면 OS는 이를 따를 것이지만, 만약 임의의 웹 페이지에서 다운로드 된 스크립트가 새 프로그램을 설치하라고 요청한다면, OS는 그렇게 해도 되는지를 검토해야할 것이다. 컴퓨터 보안에서는 이렇게 무언가를 요청하는 사람들을 가리켜 보안 주체(principal)라 부른다. 주체는 보안상 의미 있는 엔티티들로, 사용자, 사용자 그룹, 혹은 복잡한 소프트웨어 시스템과 같이 자원에 대한 접근을 요청하는 것들을 말한다. 보안 목표를 달성하기 위해서는 누가 OS 서비스를 요청하는지를 아는 것이 중요하다. 그렇다면 OS는 어떻게 그것을 알 수 있을까?
OS 서비스는 보통 특정 프로세스에서 만들어진 시스템 콜을 통해 요청된다. 이때 OS는 제어를 가지고 시스템 콜에 대한 응답 서비스를 수행한다. 이때 OS는 호출 프로세스와 연관된, OS에 의해 제어되고 해당 프로세스를 설명하는 자료 구조를 통해 프로세스를 식별하며, 그 식별 정보와 보안 정책에 기반해 요청된 연산을 수행할지에 대한 결정을 내리게 된다. 컴퓨터 보안에서는 이렇게 보안 주체 대신 요청을 수행하는 프로세스, 혹은 컴퓨팅 엔티티를 가리켜 에이전트(agent)라 부른다.
요청은 특정 자원에 대한 접근을 위한 것이며, 이렇게 접근되는 자원을 가리켜 접근 요청의 객체(object)라 부른다. OS는 이미 해당 에이전트 프로세스가 해당 객체에 접근할 수 있는지에 대한 정보를 가지고 있다. 만약에 해당 프로세스의 접근이 허용된다면 OS는 이 결정을 기억해놓고, PCB와 같은 자료 구조를 이용해 자원을 요청한 프로세스가 그것에 접근할 수 있는지를 파악한다. 이렇게 이후의 접근 결정을 위해 OS가 만들고 관리하는 데이터들을 가리켜 자격 증명(credential)이라 부른다.
하지만 만약 OS에 아직 에이전트 프로세스가 특정 오브젝트에 접근할 수 있음을 보여주는 자격 증명이 만들어지지 않았다면, 해당 요청이 서비스되어야 하는지를 판단하기 위해 프로세스 주체의 신원(identity)을 식별하기 위한 정보가 필요하다. 서로 다른 OS는 보안 주체를 식별하기 위해 서로 다른 종류의 신원을 이용한다. 예를 들어 대부분의 OS는 사용자가 어떤 "사람"임을 말하는 사용자 신원 개념을 사용한다. 따라서 특정인이 실행하는 거의 모든 프로세스들은 그와 결부된 동일한 신원을 가지게 된다. 또 다른, 흔히 쓰이는 신원 종류에는 사용자 그룹도 있다.
프로세스가 실행하는 프로그램도 신원을 가질 수 있다. 프로세스가 현재 실행 중인 프로그램이라는 사실을 떠올려보자. 안드로이드 OS 등의 시스템에서는 특정 프로그램에 특정 권한을 부여할 수 있으며, 이들은 실행될 때 자신에게 부여된 권한을 사용한다(ex. 카메라 사용 등).
어떤 종류의 신원을 쓰든, 이것이 실제로 사용되기 위해서는 신원을 특정 프로세스에 부착할 방법이 필요하며, 이 작업은 시스템 보안에서 아주 중요하다. OS의 자신의 활동을 제외한 모든 것들은 프로세스에 의해 수행된다. 따라서 이 작업을 제대로 완료할 수 있다면, 프로세스에 의해 수행되는 모든 중요한 동작들에 대한 확인도 할 수 있을 것이다. 다만 OS에서는 기본적으로 보안 주체의 인증이 성공하면 해당 프로세스의 존속 기간동안은 해당 인증을 신뢰하는 정책을 사용한다는 것에 유의하자. 인증에 일어난 실수를 바로잡기가 힘든 이유다.
2. Attaching Identities To Processes
프로세스는 어디서 시작하는 걸까? 프로세스는 보통 다른 프로세스에 의해 생성된다. 그렇기 때문에 새 프로세스에 신원을 부착하는 가장 간단한 방법은 자식 프로세스가 부모 프로세스의 신원을 상속케 하는 것이다. OS는 부모 프로세스가 자식 프로세스를 생성할 때, 부모 프로세스의 PCB에서 그 신원을 가져와 새로운 프로세스에 해당 신원을 복사한다.
이 방법은 모든 프로세스가 동일한 신원을 가지는 경우에는 좋은 방법이다. OS가 부팅될 때 제일 먼저 만들어지는 프로세스에 사람인 사용자에게는 할당되지 않는 특수한 시스템 신원을 할당하고, 그 자손이 되는 프로세스들은 모두 해당 신원을 상속하게 하면 된다. 하지만 이렇게 단일 신원만을 사용하는 경우, 특정 프로세스의 권한을 다른 프로세스들과 구분하는 보안 정책을 구현할 수는 없게 된다.
그렇기 때문에 보안 정책을 관리하기 위해서는 어떤 프로세스들은 다른 신원을 갖고 사용할 수 있게 해야 한다. 다중 사용자 시스템을 생각해보자. 여기에서는 프로세스에 어떤 사람 사용자가 속하는지를 바탕으로 신원을 할당한다. 만약 프로세스가 사용자 ID와 같은, 보안과 관련된 신원을 가지고 있다면, 새 프로세스를 생성할 때 이 ID를 사용할 수 있다. 대부분의 시스템에서 사용자는 자신이 작업하는 프로세스를 가지고 있고, 쉘에 커맨드를 입력하거나, 아이콘을 더블 클릭해 프로세스를 시작하는 것은 사실 OS에 자신의 신원을 바탕으로 한 새로운 프로세스를 만들기를 요청하는 것과 같다.
그렇다면 신원의 부착은 어떻게 되는 걸까? 여기에는 OS의 도움이 필요하다. 사용자가 시스템과 처음으로 상호작용할 때 OS는 그 사용자에 맞는 프로세스 하나를 시작한다. OS는 PCB와 같은, 자신이 가지고 있는 자료 구조들을 조작할 수 있으므로, 이렇게 생성된 프로세스의 소유권도 해당 사용자로 변경할 수 있다.
OS는 프로세스 소유권 변경을 위한 작업을 수행하기 위해 해당 사용자의 신원을 결정할 수 있어야 한다. 이를 위해 필요한 게 로그인이다. 사용자가 로그인을 한다는 것은 시스템에 자신을 증명하기 위한 신원 정보를 제공한다는 것이다. OS는 사람 사용자로부터 신원을 가져오기 위한 질의를 할 수 있어야 하고, 그 응답을 검증할 수 있어야 한다. 만약 검증에 성공한다면 이후에 쓰일 프로세스들에서는 해당 신원을 사용한다.
3. How To Authenticate Users?
그렇다면 시스템은 어떻게 그 사람이 누구인지를 결정할 수 있을까? 만약 그 사람이 시스템에 허용된 사람이 아니라면, 시스템은 그 사람이 숨어 들어오는 것을 전적으로 거부해야 한다. 또한 그 사람이 권한을 가진 사용자라면, 어떤 사람인지도 알아야 한다.
고전적으로, 그 사람이 어떤 사람인지를 식별하기 위해 쓰이는 인증 방식에는 세 가지가 있다.
- 알고 있는 것에 기반한 인증
- 소유하고 있는 것에 기반한 인증
- 누구인가에 기반한 인증
여기서 "고전적"이라는 말은, 고대 그리스-로마 시대까지도 거슬러 올라가는, 말 그대로 "고전적"이라는 말이다. 그 자세한 예들은 생략하고, 컴퓨터 시대에서는 어떻게 이 방식들을 통해 인증을 진행했는지에 대해 알아보자.
4. Authentication By What You Know
알고 있는 것에 기반한 인증은 보통 패스워드를 통해 이루어진다. 패스워드는 컴퓨터 보안에서 긴 역사를 가지고 있다. 패스워드는 인증된 사람들에게만 알려진 비밀로, 그들은 OS에 로그인할 때 그것을 알려줌으로써 자신을 증명한다. 이 형태의 인증이 가지는 효과는 여러 요인들에 달려 있다. 해당 사용자가 아닌 다른 사람들은 그 패스워드를 몰라야 하고, 패스워드를 추측할 수도 없어야 한다.
시스템의 경우, 패스워드를 검즈아는 역할을 한다. 그렇다고 해서 시스템에 패스워드를 그대로 검증하는 일은 위험하다. 누출될 가능성이 있기 때문이다. 하지만 사실 시스템은 패스워드를 알 필요가 없으며, 검증을 할 수만 있으면 된다. 알지도 못하는 패스워드를 어떻게 검증할 수 있을까?
패스워드 검증을 위해 시스템은 패스워드 그 자체가 아닌, 그 해시값을 저장한다. 이후 사용자가 패스워드를 제시하면 시스템은 입력을 해시하고 저장된 값과 비교한다. 만약 두 값이 같으면 시스템은 그 사람이 패스워드를 알고 있다고, 따라서 합당한 사용자라고 판단한다.
해시값을 저장함으로써 얻는 이점에는 공격자가 시스템 내에 저장된 패스워드를 탈취하더라도 이를 사용해 로그인할 수 없다는 것, 또한 공격자가 탈취한 패스워드로부터 패스워드 원문을 찾아내기도 어렵다는 것이 있다. 원문을 알아내기 힘든 해시값을 만들어내기 위해서는 암호화 해시 함수(cryptographic hash function)가 쓰인다.
공격자가 패스워드를 추측하지 못하게 하기 위해서는 어떻게 해야할까? 가장 간단한, 1비트 패스워드를 생각해보자. 공격자는 50%의 확률로 공격에 성공할 것이고, 첫 번째 공격이 실패한다면 다음 공격에는 반드시 성공할 것이다. 패스워드의 길이를 늘리면 어떻까? 8비트 패스워드라면 256개의 가능한 조합이 있고, 공격자는 평균 128번의 시도만 하면 로그인에 성공할 수 있다. 물론 이것도 너무 위험하기는 하지만, 적어도 최대 2번의 시도에 뚫리는 1비트 패스워드보다는 낫다. 이처럼 패스워드의 길이는 추측을 방지하는 데 중요한 역할을 한다.
입력할 수 있는 문자의 종류를 넓히는 것도 도움이 된다. 8자리 패스워드에 알파벳 대소문자, 숫자를 쓸 수 있게 한다면 총 개의 조합이 가능해지니, 0과 1만 사용할 수 있던 8비트의 경우보다 패스워드를 추측하기 훨씬 어려워진다. 실제로 시간이 지남에 따라, 패스워드 시스템들은 패스워드에 사용할 수 있는 문자의 수를 늘리고 있다.
하지만 문제는 사람들이 늘 그런 문자들로 이루어진 랜덤 문자열을 패스워드로 지정하지는 않는다는 것이다. 사람들은 종종 이름, 성, 또는 그 외의 기억하기 쉬운 단어들을 패스워드로 지정하곤 한다. 공격자들도 이 사실을 잘 알고 있기 때문에, 임의의 문자열보다는 자주 쓰이는 이름과 단어들로 공격을 시작한다. 이런 형태의 공격을 가리켜 사전 공격(dictionary attack)이라 부르며, 이 공격법은 상당히 효과적이다. 좋은 사전 공격의 경우 흔히 쓰는 사이트 패스워드의 90%는 추측할 수 있다고 한다.
따라서 제대로 된 시스템들은 공격자들의 사전 공격을 방지하는 여러 방법들을 사용한다. 패스워드에 조금만 신경을 쓴다면 5-6번 시도 내에 사전 공격을 성공하는 일은 없을 것이기에, 많은 시스템들은 패스워드 불일치가 너무 많이 일어나는 경우 접근을 막거나 패스워드 체크 프로세스를 급격하게 느리게 만듦으로써 사전 공격을 막는다.
그런데 공격자가 패스워드 파일을 탈취한 경우는 어떨까? 만약 공격자가 해시된 패스워드, 해싱 알고리즘 등등을 갖게 됐다고 해보자. 공격자는 직접 서버에 패스워드를 시도하지 않고, 자신의 컴퓨터에서 가능할 만한 패스워드들을 해싱해보고, 탈취한 해시값과 일치하는 것을 찾아낼 수 있다.
이를 방지하기 위해서는 솔트(salt)를 사용한다. 이는 임의의 큰 숫자 혹은 문자열로, 패스워드 해싱이 일어나기 전에, 사용자가 입력한 패스워드에 붙는다. 솔트를 이용하면 실제로 해시 함수의 입력이 되는 문자열과 사용자가 입력하는 문자열이 서로 달라지므로, 위의 공격을 방지할 수 있게 된다. 예컨대 솔트가 32비트의 길이라면, 사전 내 각 단어에 대해 개의 경우의 수가 생기게 되고, 로컬에서 해시 함수를 돌려서 패스워드 원문을 찾는 일은 계산적으로 불가능해진다.
5. Authentication By What You Have
일상 생활에서 ID 카드나 티켓을 사용하는 경우를 생각해보자. 이 경우 우리는 우리가 가지고 있는 것들을 가지고서 자신을 증명한다. 하지만 OS에서 자신을 인증하는 경우는 조금 다르다. ATM의 경우를 생각해보면, 여기에는 ATM 카드를 읽기 위한 특수한 하드웨어가 있다. 하지만 대부분의 데스크탑 컴퓨터, 랩탑, 태블릿 등에는 그런 특수 하드웨어가 없다. 그렇다면 우리는 우리가 무엇을 가지고 있는지를 어떻게 알려줄 수 있을까?
만약 USB를 사용하는 하드웨어 토큰 등을 이용할 수 있는 경우라면, OS는 그에 맞는 소프트웨어의 지원을 통해 로그인하려고 하는 사용자가 적절한 사용자인지 아닌지를 판단할 수 있다. 몇몇 보안 토큰들은 이러한 방식으로 동작하도록 설계된다.
다른 경우로는 그 사람의 소유물에 있는 정보를 인증이 필요한 시스템으로 전환하는 능력을 사용할 수도 있다. 예를 들어 사용자 소유 장치의 스크린에 임의의 숫자, 혹은 문자열을 나타내고, 사용자가 이를 키보드를 통해 컴퓨터에 입력하는 경우를 생각해보자. OS가 사용자가 그 장치를 가지고 있음을 직접적으로 알 수 있는 것은 아니지만, 오직 그 장치를 가지고 있는 사용자만이 해당 정보를 알고 입력할 수 있으므로, 이러한 방식은 충분히 믿을 만하다.
이 경우 장치에 나타나 OS로 전달될 정보는 빈번히 바뀌어야 한다. 그렇지 않다면 한 번 그 정보를 외운 이후, 해당 장치를 가지고 있지 않더라도 그 정보를 계속해서 사용할 수 있을 것이기 때문이다. 이 경우, 인증 메커니즘은 "가지고 있는 것" 기반에서 "알고 있는 것" 기반으로 바뀌게 되며, 이제 그 보안성은 공격자가 얼마나 그 비밀을 알기 어려워지는가에 달린 문제로 바뀌게 된다.
모든 종류의 소유 기반 인증에서 나타날 수 있는 공통된 단점들이 있다. 첫 번째는 적합한 사용자라 하더라도 그것을 가지고 있지 않은 경우에는 자신을 인증할 수 없다는 것이고, 두 번째는 부당한 사용자가 소유물을 탈취하고 정당한 사용자인양 행동할 수도 있다는 것이다. 후자의 경우는 다인자 인증 방식을 통해 어느 정도 해결될 수 있다. 장치에 표시된 토큰을 입력하고 패스워드를 추가로 입력하는 경우를 생각해보자.
다만 이런 학술적 연구와 실제에서 말하는 '보안상 안전'에는 조금 차이가 있다. 이 차이는 실제 세계에서는 사용자 편의와 같은 실제 이슈를 다루고, 학계에서는 실제로는 그럴 가능성은 없더라도 원리적으로 뚫을 수 있는 보안을 폄하하는 경향이 있기 때문에 발생한다. 예를 들어 흔히 사용하는 SMS 인증을 생각해보자. 사용자는 자신의 휴대폰에 보내진 문자 메시지 내용을 입력함으로써 자신을 인증한다. 이 경우는 사실 사용자가 휴대폰을 잃어버리거나, 공격자가 문자 메시지를 리다이렉트시키는 등의 경우가 있을 수 있기 때문에 이론적으로는 그리 안전하지 않다.
하지만 실제에서 사람들은 늘 휴대폰을 자기 곁에 두고 잃어버리지 않도록 조심하며, 잃어버리는 경우에도 빨리 그것을 알아채고 문제를 해결하려 한다. 문자 메시지를 리다이렉트시키는 경우도 현실적으로는 거의 불가능하다. 대부분의 경우, 문자 메시지를 리다이렉트시키는 데에는 인증 시스템을 속임으로써 얻을 수 있는 이득보다 훨씬 더 큰 노력이 필요하기 때문이다.
6. Authentication By What You Are
위의 두 인증 방식이 마음에 들지 않는다면, 다른 방법도 있다. 이 방식은 사람들이 모두 서로 다른 신체적 특징과 행동 양식을 가진다는 점에 착안한다. OS가 그런 특징들을 정확히 측정할 수 있다면, 서로 다른 사람들을 구별하는 데에도 쓸 수 있을 것이라는 것이다. 다만 기본적인 아이디어는 간단하지만, 이것을 실제로 동작하게 만드는 일은 어렵다.
누구인지에 기반한 인증을 위해서는 사람의 특징을 정확히 측정하고 이를 통해 사람을 특정할 수 있는 컴퓨터 프로그램을 만들어야 한다. 예를 들어 스마트폰의 주인임을 인증하기 위해 카메라로 안면 인식을 하는 경우를 생각해보자. 여기에는 몇 가지 어려운 문제들이 있다. 우선 컴퓨터 프로그램은 사람만큼 얼굴을 잘 인식하지는 못한다. 마스크를 쓰는 경우, 얼굴의 각도가 조금 다른 경우, 조명에 차이가 있는 등의 경우, 컴퓨터 프로그램은 얼굴을 잘못 인식하곤 한다.
패스워드의 경우, 옳은 패스워드를 저장해 놓고 이후 인증에서 입력된 것과 정확히 일치하는지를 대조하면 된다. 하지만 사진이나 그림의 경우, 저장된 사람의 사진과 각 비트가 정확히 일치하는지를 통해 사용자의 일치를 판단할 수 없다. 사진의 비교에서는 그 대신, 각 사진으로부터 눈의 색, 코의 길이, 입 모양 등 높은 수준의 특징(feature)들을 추출하고 이것들을 비교해야 한다. 하지만 이 특징 비교에서도 추출한 특징들이 서로 정확하게 일치하는지를 이용할 수는 없다. 예컨대 눈의 경우, 같은 사람이더라도 조명이 바뀌면 눈의 색이 바뀔 수 있기 때문이다.
따라서 사진 속 인물들이 서로 같다는 판단은 추출된 특징들이 그렇게 판단하기에 "충분히 비슷한 경우"에 내려진다. 하지만 이 경우, 허용할 유사도의 기준을 설정하는 것이 중요해진다. 기준 유사도를 너무 높게 잡으면 같은 사람이라도 인증에 실패할 수 있고(false negative), 너무 낮게 잡으면 다른 사람이라도 인증에 성공할 수 있기 때문이다(false positive).
이런 측정 방식은 어떻게 구현하든지 false positive와 false negative의 가능성이 있다. 두 경우의 가능성을 모두 최소화할 수 있다면 좋겠지만, 그건 불가능하다. false positive와 false negative의 비율이 서로 반비례 관계에 있기 때문이다.
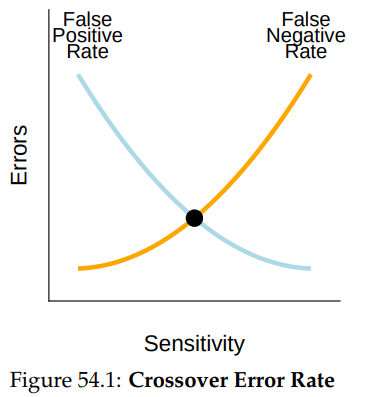
위 그래프에서 검은 원으로 표시된 부분은 false positive율과 false negative율 모두가 그럭저럭 낮을 때로, 보통 생체 측정의 정확도를 나타낼 때의 척도로 쓰인다. 하지만 시스템에 따라 false positive와 false negative 중 어떤 것을 더 선호하는지가 다를 수 있으므로 늘 여기에 맞출 필요는 없다. 생체 측정 인증의 신뢰성 이슈는 이 정도로만 하자.
사람의 특징을 사용한 인증에는 다른 문제가 있는데, 측정을 위해서는 보통 다른 특수한 하드웨어가 필요하다는 것이다. 요즘은 많은 컴퓨터들이 카메라를 가지고 있지만, 임베디드 장치나 서버 기기의 경우에는 그렇지 않은 경우가 만하다. 지문 인식 장치가 있는 것들은 더 적고, 그 외의 생소한 생체 인식에 필요한 장치를 가지고 있는 것들은 훨씬 더 적다. 타이핑 패턴들을 이용하는 기술 등, 흔히 쓰이는 하드웨어만을 필요로 하는 것들도 있지만, 그런 기술들이 많지는 않다. 또한 이런 특수 하드웨어 장치를 사용할 수 있다 하더라도, 과연 그것들이 사용하기에 편리한지는 또 다른 문제다.
생각해보아야 할 다른 이슈로는 생체 측정이 이루어지는 곳과 확인되는 곳 사이에 물리적인 틈이 있는지가 있다. 생체 정보는 비트의 형태로 보내지며, 비트의 패턴은 누구든지 마음대로 만들 수 있고, 만약 공격자가 사용자 생체 정보의 비트 패턴을 알 수 있다면, 그는 사용자의 지문이나 지문 인식 장치 없이 곧바로 해당 비트 패턴을 서버 기기로 보낼 수 있게 된다. 원격으로 제공되는 생체 인식 서비스를 사용할 때에는 주의를 기울여야 한다.
지금까지의 이야기만 보면 생체 측정은 형편 없는 인증 방식처럼 보이지만, 사실 그렇지만도 할 수 없다. 완벽한 인증 수단이란 없고, 모든 인증 수단에는 허점이 있기 마련이다. 시스템 설계자는 완벽한 인증 메커니즘을 찾는 것이 아니라, 시스템과 환경에 잘 맞는 인증 메커니즘을 사용하는 것이다. 한 인증 메커니즘이 실패하는 경우, 이차, 삼차 인증 메커니즘을 사용함으로써 인증 실패를 해결하는 것도 좋은 방법이다.
7. Authenticating Non-Humans
시스템 내에서 인증을 하는 사용자가 꼭 사람인 것은 아니다. 예를 들어 컴퓨터에 웹 서버 프로세스를 실행하는 경우, 꼭 인간 사용자가 로그인해 자기 신원을 웹 서버에 부착할 필요가 없다. 혹은 임베디드 장치의 경우를 생각해보자. 이 경우에도 인간 사용자가 로그인하지는 않지만, 장치 내에는 아마 프로세스 기반의 코드가 실행되고 있을 것이다.
OS의 입장에서는 해당 프로세스의 신원과 관련한 문제가 일어나지 않는다. 간단히 시스템에 webserver와 같은 사용자를 설정하고, 그 사용자의 신원을 웹 서버 등과 결부된 프로세스에 부착하면 되기 때문이다. 하지만 이 경우, 허용된 바로 그 사용자만이 해당 프로세스를 실행할 수 있게 해야 한다는 문제가 있다.
한 가지 방법은 비-인간 사용자들의 경우에도 마찬가지로 패스워드를 사용하는 것이다. 웹 서버 사용자에 패스워드를 할당하자. 이 패스워드는 웹 서버에 속하는 프로세스를 생성하고자 할 때 쓰인다. 하지만 로그인한 사람의 경우와 달리, 지금은 웹 서버 신원을 상속시켜줄 프로세스가 없다. 그렇기 때문에 이 경우, 시스템 관리자가 웹 서버 사용자로 로그인하고, 커맨드 쉘에서 서버에 필요한 실제 프로세스들을 생성한다. 이렇게 만들어진 프로세스들은 부모의 신원을 상속하게 된다.
보다 흔하게는 로그인의 과정을 생략하고, 특권을 가진 사용자가 자신이 아닌 다른 사용자에 속하는 프로세스를 만들 수 있게 하는 메커니즘을 사용할 수도 있다. 혹은 프로세스가 자신의 소유권을 변경할 수 있는 메커니즘을 쓸 수도 있고, 혹은 원래의 신원을 기억해두고 프로세스 신원을 임시로 변경하는 방법을 사용할 수도 있다. 다만 그 중 어떤 것이든, 사용자가 자신이 아닌 다른 사용자에 속한 프로세스를 만들 수 있도록 하는 이 방식들에는 강력한 제어가 필요하다.
패스워드는 프로세스가 비-인간 사용자에게 할당될 수 있는지를 결정하기 위해 쓰이는 가장 흔한 인증 수단이다. 하지만 때로는 비-인간 사용자에 대한 인증이 전혀 필요하지 않을 때도 있다. 이 경우에는 특정 사용자에게 (자기 자신에 대한 인증을 제외하고는) 다른 인증 없이, 생성된 프로세스에 새 신원을 할당할 수 있게 한다. 리눅스, 혹은 여러 UNIX 시스템에서 sudo 커맨드가 이런 기능을 제공한다.
sudo -u webserver apache2이 커맨드는 apache2 프로그램이 webserver의 신원으로 실행되게 한다. 이 커맨드의 경우, 커맨드를 실행하는 사용자 자신의 이증 자격 증명을 필요로 하지만, webserver와 결부된 인증 정보는 필요로 하지 않는다. 이후 apache2가 생성하는 하위 프로세스들은 webserver 신원을 상속한다.
마지막으로 다룰 신원 이슈는 개인 사용자가 아니라, 사용자 그룹을 식별하는 것이다. 한 그룹 내의 사용자들은 보안과 관련해서 공통된 특징들을 가지며, 이렇게 여러 사용자들을 묶는 것은 사용자를 개인별로 관리하는 것에 비해 여러 이점을 가진다. 그룹 기능은 보안 정책들을 적용하는 데에 더 높은 편의성과 유연성을 제공하기 때문에, 대부분의 현대 OS는 이런 사용자 그룹 기능을 지원한다. 이들은 그룹 멤버십과 그룹 특권을 개별 사용자와 비슷한 방식으로 다루는데, 예를 들어, 자식 프로세스는 그 부모와 같은 그룹-관련 권한들을 갖는다. 이런 시스템에서 작업을 할 때에는, 그룹 멤버십이 사용자에게 자원 접근을 얻기 위한 다른 길을 제공해줌을 기억해두는 것이 좋다. 이 방식에는 이점도 있지만 위험성도 있기 때문이다.
