
1. 프로젝트 소개
2023.10.10 ~ 2023.11.17 SSAFY 9기 자율 프로젝트로 진행했던 프로젝트다.
깃허브는 여기
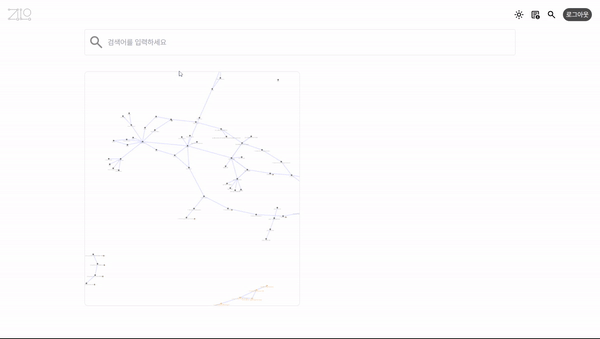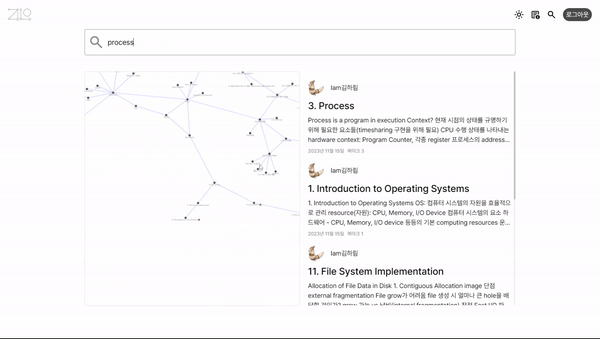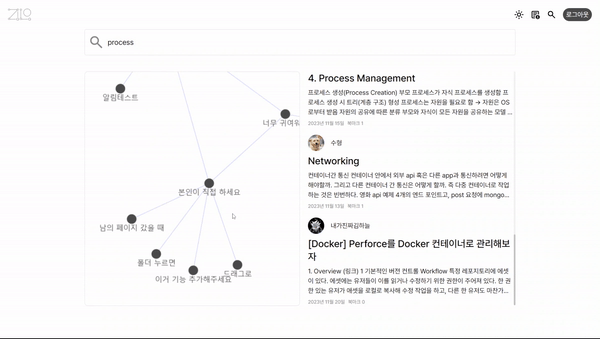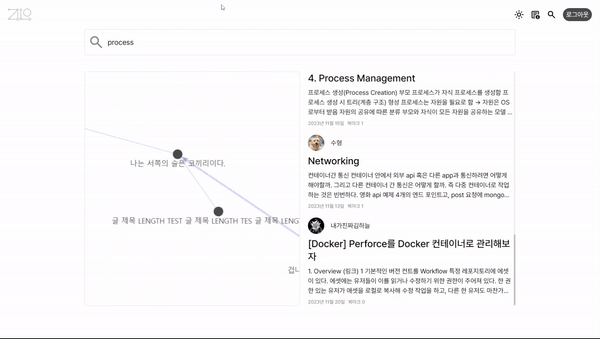
프로젝트의 컨셉은 글 사이의 관계를 그래프로 보여주는, 공개적인 퍼블리시가 가능한 노트앱을 만드는 것이었다.
비교 대상으로 삼았던 서비스들에는 벨로그, 노션, 옵시디언이 있었다. 사실 노션 + 옵시디언 + 벨로그라 생각해도 좋다.
-
벨로그
- 글의 구조 파악이 힘듦. (디렉토리 구조 없음)
- 여러 글들을 분류하려면 시리즈나 태그를 써야함.
- 시리즈는 말 그대로 연재물의 느낌이고 이전에 사용한 태그로 자동 완성을 해준다든지 하는 기능이 없음. -
노션
- 다양한 기능의 블록들을 사용할 수 있고, 팀 스페이스로 쓰기도 좋음.
- 내 워크스페이스 밖의 다른 사람의 글을 검색하는 기능이 없음.
- 게시된 링크를 통해 접속하거나 구글링으로 노출된 경우에만 볼 수 있음. -
옵시디언
- 기본적으로 로컬 서비스. 퍼블리시를 하려면 월 정액을 끊어야 함.
프로젝트는 총 6인 1팀으로 진행됐다. 보통은 백엔드 4, 프론트엔드 2로 팀을 구성하는데, 한 번 빡세게 해보자는 마인드로 백엔드 1, 인프라 1, 프론트엔드 4로 팀을 꾸렸다. 결과적으로는 반에서 3등을 했다. 하지만 그것도 사실은 프론트가 예쁘게 나와서가 아닐까... 생각한다. 아쉬움이 많이 남고, 개선할 점들도 많이 보인다.
2. 개선할 점
2-1. 기능
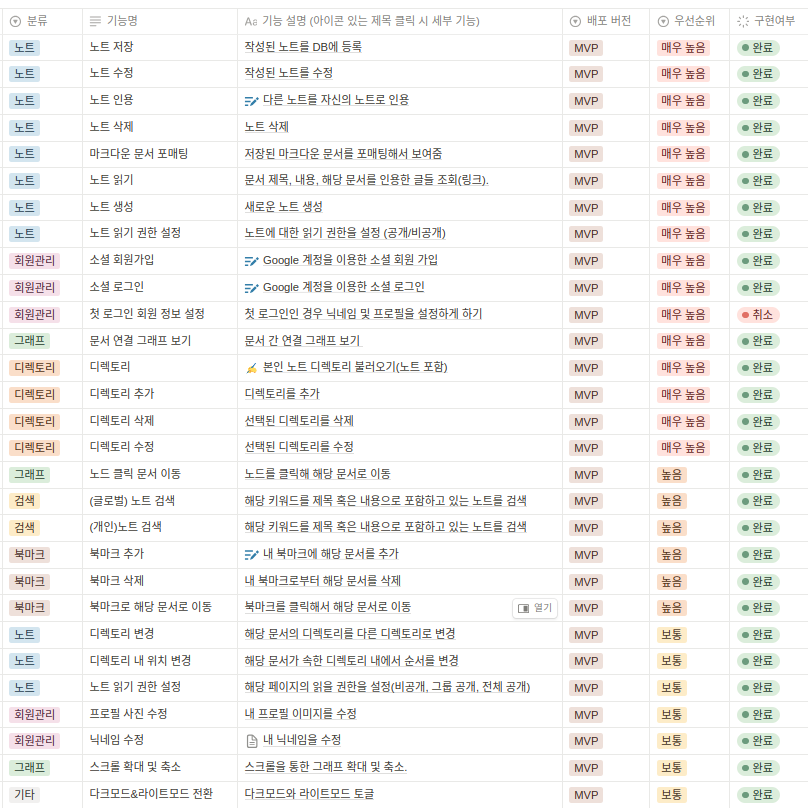
프로젝트 기간 중에 구현한 기능은 대충 위와 같다. 그런데 이를 보면 알 수 있듯, 사실 백엔드 로직은 그저 간단한 게시판 기능일 뿐이고, 프로젝트의 핵심 개념인 그래프와 관련한 내용은 대부분 프론트엔드에서 구현됐다. 백엔드에서는 사용자 인증과 JSON 상하차만 열심히 했을 뿐, 데이터를 적극적으로 처리하는 로직이 없었다.
원래는 그래프의 특징을 살려, 그래프 알고리즘으로 사용자에게 유의미한 정보를 제공하는 기능들이 있어야 했다. (위상 정렬을 해서 어떤 순서로 글을 읽어야 하는지를 보여주기, MST 찾기 등등..) 글의 내용을 처리해서 분류하고 추천하는 로직도 추가 기능에 있었지만 구현하지 못했다. 그래프라는 컨셉에 집중해서, 단순히 글을 그래프 형식으로 보여주는 것 이상의 기능들을 추가했더라면 좋았을 것이라는 아쉬움이 남는다.
2-2. 구현
그럼 구현된 기능들이라도 잘 만들었나? 사실 그것도 아니었다. 전체적으로 설계를 잘못하거나 테스트를 잘못해서 오류도 많았고 수정하는 데에도 많은 시간을 쏟았다. 프론트 팀원들의 도움이 없었으면 더 심각한 버그 투성이였을 것 같다. 한 달 하고도 반이 지난 지금 다시 볼 때, 확실히 해결돼야 할 문제들에는 다음의 것들이 있다.
(1) N + 1 문제
이 프로젝트에서는 N+1 문제를 전혀 해결하고 있지 않다. N+1 문제의 개념이나 해결법에 대해서는 얼핏 들어본 적이 있었지만, 프로젝트를 진행할 때는 객체 리스트를 받아 각각에 대한 세부 내용을 얻기 위해 계속해서 쿼리를 날리는 게 당연하다고 생각했다. N+1 문제가 나타나는 코드들 중 하나는 다음과 같다.
@Override
public QuotationListResponseDto getQuotationLists(Long noteId) throws NoteNotFoundException {
Note note = noteRepository.findNoteById(noteId).orElseThrow(NoteNotFoundException::new);
List<Note> quoted = getNotesQuotingThis(note);
List<Note> quoting = getNotesQuotedByThis(note);
return QuotationListResponseDto.toDto(quoting, quoted);
}
@Override
public List<Note> getNotesQuotingThis(Note note) throws NoteNotFoundException {
return note.getQuoted().stream().map(Quotation::getEndNote).toList();
}
@Override
public List<Note> getNotesQuotedByThis(Note note) throws NoteNotFoundException {
return note.getQuoting().stream().map(Quotation::getStartNote).toList();
}getQuotationLists()는 해당 노트로 향하는 노트들과 해당 노트가 향하는 노트들의 리스트를 반환하는 메서드다. 이때 getNotesQuotingThis()와 getNotesQuotedByThis()에서 note.getQuoted()는 Note 클래스의 필드로 들어가있는 List<Quotation> 들을 가져온다. Quotation 클래스는 아래와 같다.
public class Quotation {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "s_note_id")
private Note startNote;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "e_note_id")
private Note endNote;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member owner;
}객체를 참조하는 모든 필드는 FetchType.LAZY를 쓰고 있기 때문에 .map(Quotation::getEndNote)를 쓰는 시점에 한 번 더 쿼리가 발생한다. 다시 말해 List<Quotation>을 가져오는 데에 한 번 쿼리가 발생하고, 그 각각의 원소에서 startNote를 가져오기 위한 N번의 쿼리가 발생한다.
프로젝트 기간 중에는 글이 많아 봐야 백 개가 안 됐기 때문에 사실 크게 생각하지 않아도 되는 부분이었지만, 성능 저하가 확실히 일어날 걸 알면서도 남겨 놓고 있다는 건 당연히 문제다.
(2) 검색 문제
구현된 검색 기능에도 문제가 있다. 지금 프로젝트에서는 LIKE 쿼리를 통해서 검색 키워드를 포함하는 제목, 또는 내용을 가진 글들을 조회한다. 조회 대상이 되는 글은 (1) 글 전체거나 (2) 특정 유저 페이지 내의 글이다.
다만 이를 위해서 쿼리를 여러 개 만들지는 않고, 한 메서드에 조건만 다르게 하는 식으로 구현을 했는데, 이것 저것 조건들이 많아 동적 쿼리를 위해 QueryDSL을 사용했다.
@RequiredArgsConstructor
public class NoteRepositoryImpl implements NoteRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public Slice<Note> searchByKeyword(String keyword, Member member, String nickname, Pageable pageable){
String keywordWithNoWhiteSpace = keyword.replace(" ", "");
//내가 페이지의 주인이면 전체 검색하고, 아니면 공개 자료만 검색한다.
List<Note> result = queryFactory
.selectFrom(note)
.where(isOwner(member, nickname), matches(keywordWithNoWhiteSpace))
.orderBy(getOrderSpecifiers()
.stream()
.toArray(OrderSpecifier[]::new))
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.fetch();
boolean hasNext = false;
if (result.size() > pageable.getPageSize()) {
result.remove(pageable.getPageSize());
hasNext = true;
}
return new SliceImpl<>(result, pageable, hasNext);
}
private BooleanExpression isOwner(Member member, String nickname){
//공개만 가져온다
if (nickname == null){
return note.isPublic;//전체 검색
}
else if (member == null || !member.getNickname().equals(nickname)){
return note.isPublic.and(note.author.nickname.eq(nickname));//타인의 개인 페이지 검색
}
else {
return note.author.nickname.eq(nickname);//자신의 개인 페이지 검색
}
}
private BooleanBuilder matches(String keyword){
BooleanBuilder booleanBuilder = new BooleanBuilder();
booleanBuilder.or(Expressions.stringTemplate("function('lower', {0})", note.content).contains(keyword));
booleanBuilder.or(Expressions.stringTemplate("function('lower', {0})", note.title).contains(keyword));
return booleanBuilder;
}
private List<OrderSpecifier> getOrderSpecifiers(){
List<OrderSpecifier> orderSpecifiers = new ArrayList<>();
orderSpecifiers.add(new OrderSpecifier(Order.DESC, note.quoted.size()));
orderSpecifiers.add(new OrderSpecifier(Order.DESC, note.bookmarks.size()));
orderSpecifiers.add(new OrderSpecifier(Order.DESC, note.postDatetime));
return orderSpecifiers;
}
}그런데 사실 서로 다른 조건의 두 검색은 각각 다른 API로, 각각 다른 쿼리를 이용하는 게 나았을 것 같다. 또 근본적으로, 띄어쓰기나 대소문자 문제로 검색이 되지 않는 경우를 없애기 위해서 공백을 모두 지우고, 글 제목과 내용의 대문자는 모두 소문자로 치환시킨 것도 문제가 된다. 이것도 물론 사용자도 없고 글 수도 적은 지금이야 별 문제가 아닐 수도 있겠지만, 글이 많아지고 글자 수도 많아지면 심각한 성능 저하의 요인이 될 것이다. 만약 대박이 나서 글이 수 만개, 수 십 만개가 된다면? 좀 더 최적화 해야할 필요가 있다.
(3) 그래프 탐색 최적화 문제
지금 프로젝트의 검색 페이지에서는 전체 글의 그래프를 보여주고 있다. 이 또한 이렇게 글 수가 적을 때는 크게 상관이 없겠지만, 수 만~십 수만 개의 글이 있는 경우를 가정한다면 어떨까?
그래프를 띄우기 위해서는 이 라이브러리를 사용했다. 해당 레포의 README 예제 중에는 75K개의 노드로 이루어진 그래프가 있는데, 이 예제의 경우 노드와, 노드 간의 연결 정보를 제외하면 아무 정보도 없음에도 상당히 느리게 렌더링된다. 아마 많아도 수 천개의 노드 정도만 보이게 하는 게 좋을 것 같아 보인다.
그런데 십 수만 개의 글이 있다고 가정했을 때, 서버에 해당 요청이 들어올 때마다 DB에서 수 천개를 뽑아 주는 것도 사실 적잖은 부담이 될 것 같기도 하다. 서버에서는 어떤 기준으로 그래프들을 보여줘야 할까? 그리고 이 그래프를 클라이언트에게 보내기 위한 최적화는 어떻게 해야 할까?
(4) 인터페이스 및 계층 분리 문제
public interface QuotationService {
QuotationListResponseDto getQuotationLists(Long noteId) throws NoteNotFoundException;
QuotingIdListResponseDto getQuotingNoteIds(Long noteId) throws NoteNotFoundException;
// 인용
List<Note> getNotesQuotingThis(Note note) throws NoteNotFoundException;
List<Note> getNotesQuotedByThis(Note note) throws NoteNotFoundException;
void addQuotation(Member member, AddQuotationRequestDto requestDto) throws NoteNotFoundException, UserNotFoundException;
void deleteQuotation(Member member, DeleteQuotationRequestDto requestDto) throws NoteNotFoundException, UserNotFoundException;
void updateQuotations(Member member, Long noteId, UpdateQuotationsRequestDto requestDto) throws UserNotFoundException, NoteNotFoundException;
}프로젝트 내에서 글 사이의 관계를 나타내기 위한 서비스의 인터페이스다. 초기에는 글과 글이 맺는 관계는 "인용" 관계로, 옵시디언과 같이 "[[]]"를 이용해서 다른 글의 링크를 가져옴으로써 생기는 관계로 생각했다. 프로젝트를 진행하면서는 "인용" 이라는 개념과 그래프 내 간선이 가지는 "방향"으로 표현하고자 하는 개념이 엄밀하게 맞아 떨어지지는 않는다는 것을 문제로 "인용" 개념을 포기하게 됐는데, 그럼에도 이전에 쓰던 이름(Quotation)을 바꾸지 않고 계속 써서, 인터페이스가 실제 서비스에서 사용하는 개념을 제대로 반영하지 못하는 문제가 발생하고 있다.
또, 원래는 서비스 계층에서는 컨트롤러에서 반환될 DTO를 쓰지 않으려 했다. 클라이언트에게 보내 화면으로 나타날 정보와 서비스 계층을 확실히 분리시키기 위해서다. 그래서 모든 응답 DTO 클래스에는 엔티티, 또는 엔티티 컬렉션을 매개변수로 받아 DTO로 포매팅해 반환하는 메서드를 뒀다. (요청 DTO는 반대로 엔티티로나 엔티티 컬렉션으로 변환하는 메서드를 뒀다.)
문제는 알림 기능을 SSE를 사용할 때, SSE 로직에 DB 트랜잭션이 포함되는 경우 커넥션 고갈 문제가 발생할 수 있다는 것이었다. 이를 방지하기 위해서 기본으로 켜져 있는 OSIV를 off로 뒀는데, 다음과 같은 문제가 추가로 발생했다.
엔티티에서 DTO로의 변환은 컨트롤러 단에서 DTO에 정의된 메서드를 호출함으로써 이루어지고 있었다. 그런데 이때 lazy fetch를 이용해 필드의 객체를 참조하는 경우가 있었고, OSIV를 껐으니 트랜잭션으로 설정되지 않은 곳에서는 해당 필드의 객체에 대한 정보를 조회할 수 없었다. 사실 근본적으로는 컨트롤러단에서 lazy하게 DB 조회를 하게 두는 것부터가 잘못이었다. 따라서 DTO 변환 로직을 서비스 단으로 옮겼다.
그런데 이렇게 DTO 변환 로직을 서비스 단으로 옮기니, 서비스에는 순수하게 엔티티와 엔티티 컬렉션만을 이용하던 메서드들과 DTO를 이용하는 메서드들이 혼재하게 됐다. 사실상 동일한 로직인데 반환 타입에 따라 여러 개의 메서드가 생긴 것이다. 실제로 이런 점이 문제시 될 것인지는 잘 모르겠다. 취향 차이라고는 하지만 서비스 단에서 컨트롤러로 반환될 DTO를 사용하는 게 그리 마음에 들지 않기는 하다. 어떻게 구성하는 게 더 나을지에 대해서는 조금 더 고민해봐야 할 것 같다.
(5) SSE 관련 문제
북마크, 또는 인용 시, 대상 글의 소유자에게 실시간으로 알림을 보내는 기능을 구현하기 위해 SSE를 사용했다. 하지만 기능 상으로 미흡한 점이 많이 있다. 우선 여러 탭에서 한 계정으로 로그인 하는 경우, 여러 개의 탭 중 하나로만 알림이 발송된다. 처리해야하는 문제지만 미루다가 그냥 넘어가버렸다. 프론트와의 연결이 끊겨서 제대로 작동하지 않는 경우도 있었는데, 이 부분도 제대로 핸들링하지 못해서 시연할 때 오류가 터지지 않기를 기도했다.
(6) 리프레시 토큰 저장 문제
인증과 관련해서, 리프레시 토큰은 Redis에 담아서 관리하게 했다. 리프레시 요청이 들어오면 쿠키에 담긴 리프레시 토큰으로 Redis를 조회해 이메일을 가져오고 리프레시 토큰을 재발급 해주는 식이었다. 그런데 사실 Redis에는 저장만 하고 있고, 기존에 저장된 리프레시 토큰을 무효화하는 로직은 빠져 있다. 리프레시 토큰으로는 간단하게 UUID를 쓰고 있기 때문에 사실상 겹칠 염려는 없지만, 그럼에도 한 계정에 여러 리프레시 토큰이 할당된 채로 남아있을 수 있다는 건 바람직하지 않다.
public void saveRefreshToken(String refreshToken, String email) {
log.info("save refresh token");
refreshTokenRepository.save(new RefreshToken(refreshToken, email));
}(7) 네이밍 문제
private void recursivelyRetrieveFolderAndAddToFolderList(List<FolderBriefDto>
//...
}이름에서도 드러나듯 연결된 폴더를 재귀적으로 탐색해 하나의 리스트로 만들어주는 메서드다. ≪클린 코드≫에 따르면 메서드 이름은 메서드의 용도가 잘 드러나게 지어야 한다고 하지만, 한 메서드의 이름이 43자나 되는 건 좀... 아닌 것 같다.
이외에도 서로 헷갈리는 이름들도 많고, 용도가 잘 드러나지 않는 이름들도 많았다.
2-3. 아키텍처
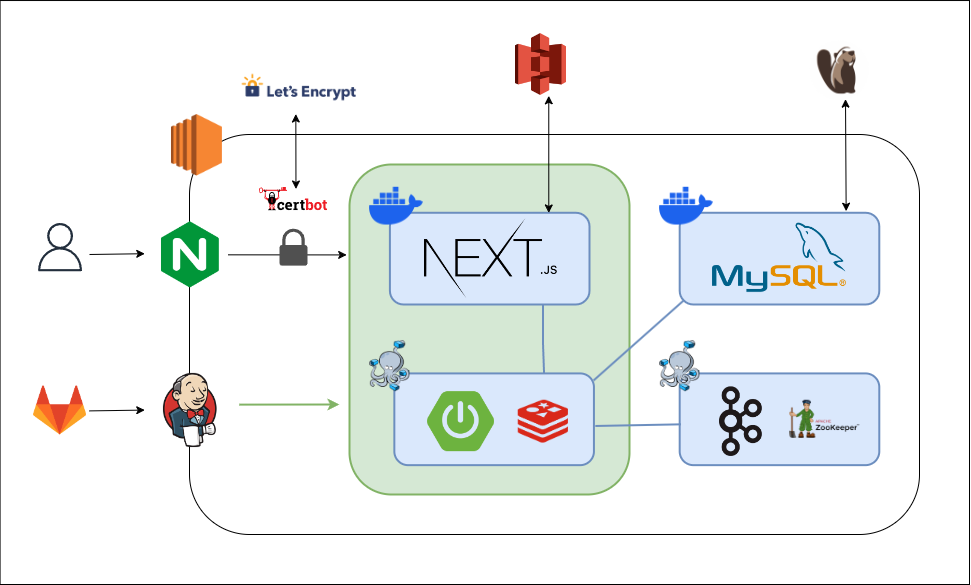
프로젝트를 시작할 때는 도메인 및 서비스 별로 서버를 최대한 나눠서 구성하려고 했다. 하지만 MSA를 해본 적이 없어서 일단은 모놀리식하게 구현하고 추후에 분리하는 방향으로 틀게 되었고, 시간상 그렇게 하지는 못했다.
그래도 적어도 다음과 같이는 해봐야 할 것 같다. 전체적으로는 서비스 분리 및 서버 이중화를 목표로 한다.
- 서비스 분리
- 사실 어떻게 서비스를 나눠야 할지는 아직도 가늠이 잘 안 된다.
- 서버 이중화와 로드 밸런싱
- 카프카를 통한 메시징 관리
- 브로커도 여러 개를 사용할 것 (지금은 SSE 메시지를 관리하기 위한 브로커 하나만 두고 있음)
- DB 이중화
- 넓은 범위의 그래프 조회를 위한 캐싱? (괜찮을지는 사실 잘 모르겠음)
- Redis 클러스터링
- 서버 이중화 시 리프레시 토큰 관리를 위한 리플리케이션
- 서버 이중화 시 SSE 객체 관리를 위한 pubsub
3. 마치며
프로젝트가 끝나고 한 달 반이 지났다. 또 새로운 프로젝트를 해보는 것도 좋겠지만, 이전에 진행했던 프로젝트를 리팩토링하고 보완해나가는 경험도 좋을 것 같다. 다른 팀원들 없이, 일단은 백엔드 및 인프라 쪽만 조금씩 수정해나갈 예정이라 프론트 쪽이 조금 걱정되기는 하지만, 일단은 해봐야겠다. 문제는 다른 것보다 여러 개의 EC2 인스턴스를 사용하는 게 상당히 부담스럽다는 점인데, 로컬로 돌린다 하더라도 이 컴퓨터가 받쳐줄지도 잘 모르겠다. 일단은 해봐야지.

잘 읽었습니다~
지그로그 화이팅!