시작하기에 앞서
"페이지네이션(Pagination)" 이란 개념을 들어본 적이 있을 것이다. 흔히 페이지 수(쪽 수)를 매기고 정렬할때 쓰이는 개념으로써 우리가 웹 혹은 앱에서 자주 다루게 된다.
개발 초보인 나로써는 "페이지네이션"을 오로지 프론트 단에서만 필요한 개념이라 생각했다.
아무튼 이번 포스팅에서는 백엔드에선 페이지네이션이 어떻게 쓰이는가를 간단히 알아보고, Nest 프레임워크를 통해 구현해보고자 한다.
그 과정속에서 얻게 되었고, 경험하게 되었던 여러 코드및 방법들을 녹여보고자 한다.
Pagination & Backend
"페이지네이션" 하면 위와 같은 이미지를 많이 떠올릴 것이다.
유저가 애플리케이션을 사용 중 특정 게시판 혹은 상품 목록을 조회한다고 가정하자. 조회를 한다는 것은 서버에 요청을 보낸다는 것이고, 서버는 해당 요청에 대해 데이터를 클라이언트에게 보내주게 될 것이다.
만약, 조회에 대한 결과 데이터가 100만건, 1000만건이라면 어떨까?
이것을 전부 한번에 가져오게 되면 상당히 부하가 걸릴 것이 분명하다. 그렇게 되면 유저또한 불편함을 느끼게 될 것이다. 물론 UI나 UX 적으로도 좋지 않을 것이다.
이것이 우리가 "Pagination"을 구현하는 이유이다.
데이터를 전부가 아닌 10개 or 20개 단위(상황에 따라 적합하게)로 나눠서 가져오고, 그 후의 데이터들은 유저의 요청에 의해서 가져오게 된다면 확연히 빠르게 결과를 마주할 수 있을 것이다.
화면단(프론트단)에서도 페이지네이션을 구현하는 것이 중요하지만, 이처럼 서버에서도 페이지네이션을 적절히 구현하여 보내주는 것이 중요하다.
(Backend에서 페이지네이션의 역할)
(이 글은 단순 개념을 설명 및 소개하는 글이 아닙니다. 인지하고 읽어주시면 감사하겠습니다.)
Pagination in NestJS (offset 방식)
User 객체 (Entity)
이번 포스팅에서 응답으로 보내주게 될 유저 데이터이다.
import { Exclude } from "class-transformer";
import { Column, Entity, PrimaryGeneratedColumn } from "typeorm";
@Entity('users')
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
first_name: string;
@Column()
last_name: string;
@Column({unique: true})
email: string;
@Column()
@Exclude({toPlainOnly: true})
password: string;
}유저 레포지터리 생성에 관한 내용은 생략하겠습니다. 해당 내용을 진행하면서 "커스텀 레포지터리"를 직접 생성해 시행하였고 해당 구현체에 관한 설명 및 코드는 아래 포스팅 참조 바랍니다.
NestJS - Custom Repository
페이지네이션 구현하기
일반적으로 우리가 생각하게 되는 페이지네이션은 아마 "offset" 방식이지 않을까 싶다. nest를 통해 간단히 offset 방식의 페이지네이션이 어떻게 구현되고 동작되는지 빠르게 알아보자.
( 이번 포스팅은 페이지네이션의 종류와 개념에 대해 설명하는 글이 아닙니다. Offset 방식에 대한 정확한 개념을 설명하진 않겠습니다. 많은 블로그 및 문서를 참조 바랍니다. )
우린 기존에 유저 데이터를 조회하는 요청을 구현할때 모든 데이터를 한번에 조회하도록 하였다.
// user.controller.ts
@Controller('users')
export class UserController {
constructor(private userService: UserService){}
@Get()
async all(): Promise<User[]>{
return await this.userService.all();
}
}// user.service.ts
@Injectable()
export class UserService {
constructor(
private readonly userRepository: UserRepository
){}
async all(): Promise<User[]> {
return await this.userRepository.find();
}
}위에서도 언급하였지만 몇 건 되지 않는 데이터를 조회하는 경우엔 위의 방식도 무관하지만 데이터의 양이 10만건, 100만건이나 된다면 얘기가 달라진다. 그럼 이제 페이지네이션을 구현해보자.
💨 Controller
// user.controller.ts
@Controller('users')
export class UserController {
constructor(private userService: UserService){}
@Get()
async all(@Query('page') page: number = 1): Promise<User[]>{
return await this.userService.paginate(page);
}
}💨 Service
// user.service.ts
@Injectable()
export class UserService {
constructor(
private readonly userRepository: UserRepository
){}
async paginate(page: number = 1): Promise<any> {
const take = 1;
const [users, total] = await this.userRepository.findAndCount({
take,
skip: (page - 1) * take,
});
return {
data: users,
meta: {
total,
page,
last_page: Math.ceil(total / take),
}
}
}
}유저 데이터를 불러오는데 있어 서비스단에서 paginate() 메서드를 통해 구현하였고, 해당 메서드를 컨트롤러에서 GET 요청으로 호출하게 되는 구조이다.
원리 알아보기
그럼 먼저 paginate() 함수부터 알아보자.
핵심이 되는 부분은 유저 레포지터리를 통해 조회하게 되는 아래 구문이다.
const [users, total] = await this.userRepository.findAndCount({
take,
skip: (page - 1) * take,
});typeorm의 find 계열 메서드 중 findAndCount를 간단히 확인해보자.
/**
* Finds entities that match given find options.
* Also counts all entities that match given conditions,
* but ignores pagination settings (from and take options).
*/
findAndCount(options?: FindManyOptions<Entity>): Promise<[Entity[], number]>;findAndCount()의 리턴 타입이 Promise<[Entity[], number]> 인 것으로 보아 우리는 해당 함수를 가지는 변수를 구조 분해 할당으로 다음과 같이 [users, total] 선언할 수 있을 것이다.
또한, 해당 users 변수는 User 엔티티를 할당받은 UserRepository를 돌고 있으므로 User 객체 자체일 것이고(조회 데이터에 따라 하나가 될 수도 있고, 여러 유저 객체가 될 수도 있다.), total은 데이터의 전체 카운팅이 될 것으로 예상할 수 있다. (실제로 콘솔에 찍어보면 그러하다.)
그렇다면 findAndCount() 내부 파라미터로 선언된 take와 skip은 무엇일까?
위 findAndCount()의 정의를 보면 나와있지만 파라미터로 옵션 값 FindManyOptions를 받게 된다. 해당 인터페이스의 구현체를 꺼내보자.
export interface FindManyOptions<Entity = any> extends FindOneOptions<Entity> {
/**
* Offset (paginated) where from entities should be taken.
*/
skip?: number;
/**
* Limit (paginated) - max number of entities should be taken.
*/
take?: number;
}FindManyOptions는 FindOneOptions를 확장자로 가지는 만큼 FindOneOptions 인터페이스의 내부 프로퍼티인 where, select, relations와 같은 속성들 또한 사용가능하다.
여하튼 skip과 take는 무엇이고 어떻게 쓰이는지에 대해 알아보자.
여기서 skip에는 Offset, take에는 Limit이라고 정의되어 있다.
처음엔 skip이란 속성. 즉, offset이 정확히 어떤 역할인지 감이 오질 않았다. 컴퓨터 프로그래밍에선 offset이 어떤 의미인지 고민하던 찰나 "3D 캐드"를 다룰때 기능으로 사용했던 offset을 떠올리니 바로 어떤 느낌인지 알았다.
캐드에선 offset 기능을 통해 특정 선 혹은 면을 지정해 준 길이에 따라 그대로 이동해주는 또다른 선 혹은 면을 생성하게끔 한다.
이것을 우리의 페이지네이션에 빗대어보면 offset은 이전의 요청 데이터 갯수라고 생각해도 무방하다. take는 말 그대로 한 페이지에 가져올 데이터의 "제한" 갯수일 것이다.
다시 우리의 구현체를 확인해보자.
const take = 1;
const [users, total] = await this.userRepository.findAndCount({
take,
skip: (page - 1) * take,
});take를 1로 둠으로써 한 페이지(or 영역)에 하나의 유저 데이터만 불러온다는 것을 확인했고, 그렇다면 skip은 왜 다음과 같이 나타내는 것일까?
skip 즉, offset은 이전의 요청 데이터 갯수임과 동시에 현재 요청이 시작되는 위치이다. 즉, 만약 위와 같이 limit가 1이고, 요청 page가 1일 경우엔 당연히 0부터 시작할 것이다. 또한, limit가 1이고, 요청 page가 2일 경우엔 offset은 1이 될 것이다.
그냥 직관적으로 쉽게 생각하면 위와 같은 원리일 것이고, 조금 더 "DB" 적으로 접근하면 쿼리문을 확인해 보면 된다.
SELECT * FROM admin.users;위 구문은 모든 데이터를 조회하게 된다. 이왕 이렇게 된 김에 우리의 모든 데이터를 한번 알아보자.
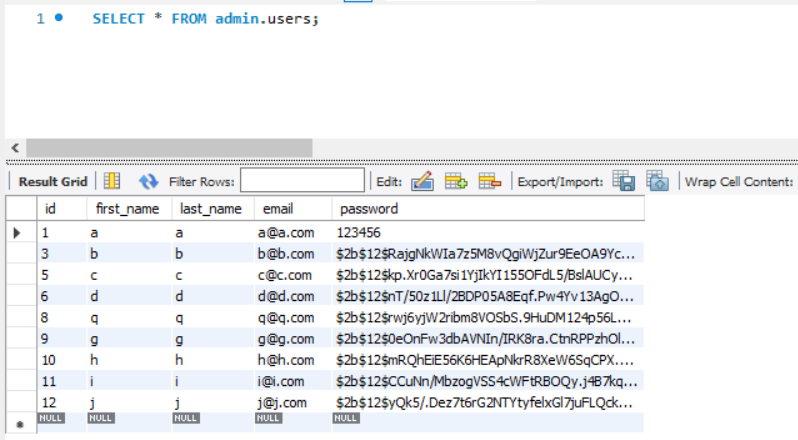
여기서 만약 첫 번째 데이터부터 총 5건의 데이터를 불러오고 싶을때 어떻게 쿼리문을 날리는가?
SELECT * FROM admin.users LIMIT 0, 5;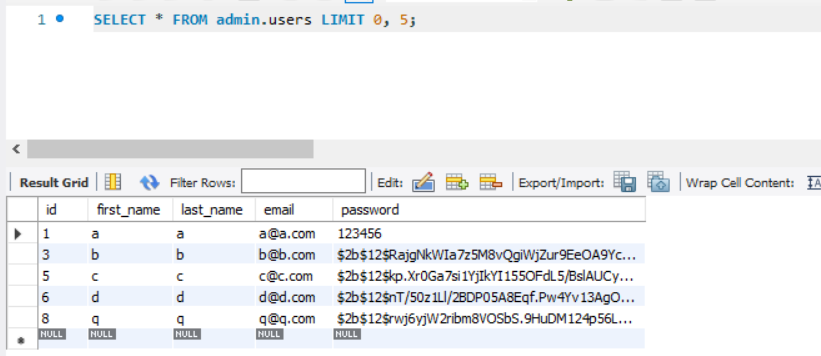
당연히 LIMIT 범위를 0, 5로 둔다. 1, 5로 두지 않는것 처럼 위에 작성한 skip문의 값 또한 그 이유라고 접근하면 좋다.
우린 findAndCount함수를 통해 구현했지만 find와 count 이 두개의 함수로 나눠서 구현해도 무방하다.
const total = await this.userRepository.count();
const users = await this.userRepository.find({
take,
skip: (page - 1) * take,
});우리가 paginate()를 통해 리턴하게 될, 즉 client에게 넘겨주게 될 값들을 확인해보자.
async paginate(page: number = 1): Promise<any> {
const take = 1;
const [users, total] = await this.userRepository.findAndCount({
take,
skip: (page - 1) * take,
});
return {
data: users,
meta: {
total,
page,
last_page: Math.ceil(total / take), // <-- 이것에 대한 구현 설명은 구글링 참조바랍니다.
}
}
}가장 메인이 될 User 객체를 data 프로퍼티의 value로 리턴하고, 그 이외에 메타데이터로써 페이지 인덱스, 총 페이지 수, 마지막 페이지와 같은 값을 받아온다.
지금은 간단한 테스트여서 서비스단에서 직접 리턴할 값들을 정의해주었지만 리턴해야할 메타데이터의 값들이 많아질 경우 위의 방식은 좋지 못하다 생각한다.
일단 위의 내용은 추후 알아보기로 하고, 컨트롤러 단으로 넘어가 보자.
@Controller('users')
export class UserController {
constructor(private userService: UserService){}
@Get()
async all(@Query('page') page: number = 1): Promise<User[]>{
return await this.userService.paginate(page);
}
}우리는 page라는 이름을 url내에서 가져오길 원하므로 @Query 데코레이터를 이용한다. 현재 page 값을 1로 고정해둠으로써 쿼리문을 요청하지 않은 디폴트 상태에선 첫 번째 페이지만 불러올 것으로 한다.
포스트맨을 통해서 페이지네이션 결과를 확인하기에 앞서 한가지 해 줄 작업이 있다. 클라이언트에게 응답을 보내줄때 "password"와 같은 특정 필드를 보안 상(혹은 다른 이유들로) 넘겨주지 않는 것이 일반적이다.
해당 방법을 간단히 언급하자면
// user.service.ts
return {
data: users.map(user => { // password를 제외한 data만 넘겨주기
const {password, ...data} = user;
return data;
}),
meta: {
total,
page,
last_page: Math.ceil(total / take),
}
}위와 같이 "spread operator"를 활용하는 것이다. 페이지에 들어갈 전체 유저 데이터를 map 함수를 통해 돌면서 각 각의 user 객체를 "spread operator"를 활용해 password와 그 나머지 프로퍼티들로 분리하는 것이다.
그 후 최종 data 반환시에 그 나머지 data들만 반환해주면 된다.
하지만 본인은 위와 같은 방법을 사용하지 않았다. 애플리케이션 전체에서 적용할 "Custom Interceptor"를 생성해 컨트롤러 레벨에서 주입시키는 방법을 택하였다. 훨씬 재사용성이 있고 가독성도 있지 않나 싶다.
해당 인터셉터 구현은 이번 포스팅에서 다루긴 주제를 벗어나므로 구현체를 알고 싶다면 아래 포스팅을 통해 확인하길 바란다.
➡ Custom-Interceptor 생성하기
✔ 포스트맨을 통한 응답 확인
그럼 포스트맨을 통해서 클라이언트의 요청에 따라 어떠한 응답을 보일지 확인해 보자.
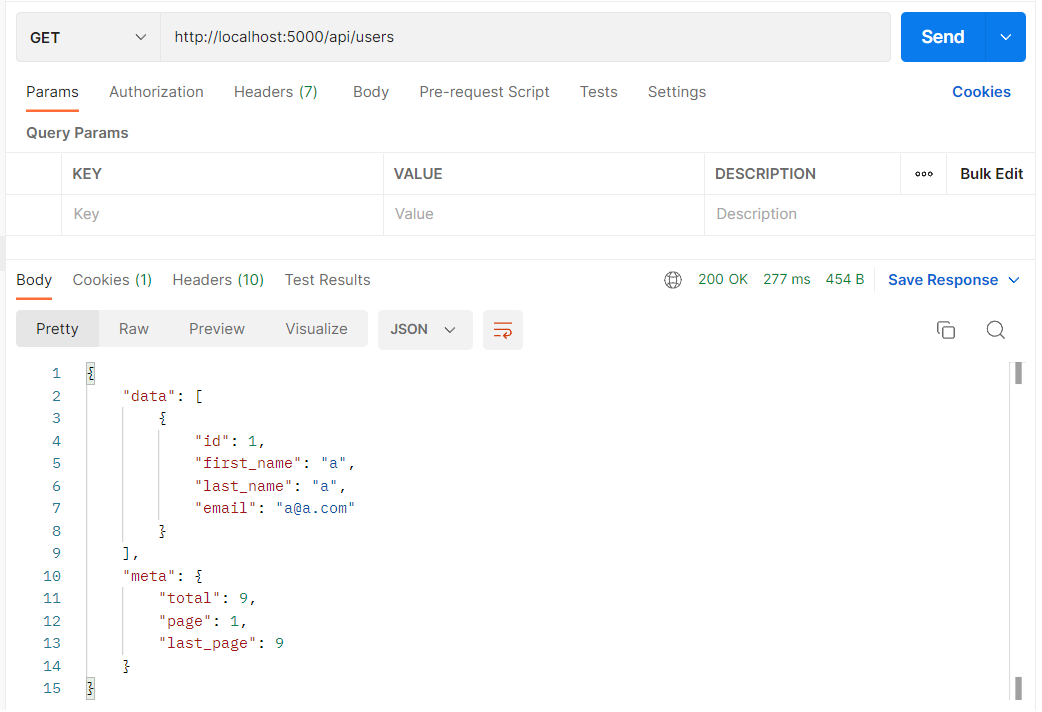
요청 시 어떠한 쿼리문도 날려주지 않은 디폴트(전체 조회) 요청이다. 앞서 디폴트 시 page=1로 고정해두었고, take = 1이기 때문에 첫 페이지에 가장 첫 번째의 유저 데이터가 불러져온다.
두 번째 페이지를 요청하면 (page=2) 아래와 같을 것이다.
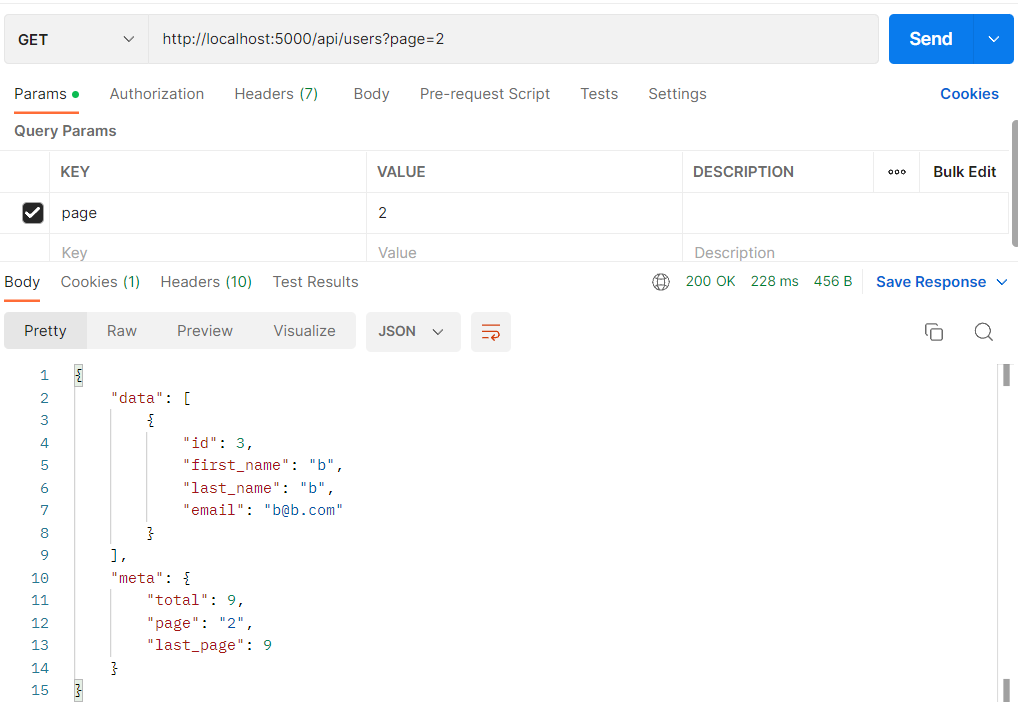
url에 경로 뒤에 쿼리문을 작성해줌으로써 불러올 수 있다.
만약, 한 페이지에 3개의 데이터를 순차적으로 불러오고자 하면 어떻게 할까?
우리의 유저 데이터는 총 9개의 데이터로 구성되어있고, 한 페이지 당 3개의 데이터를 담게끔 페이지네이션을 한다면 총 3개의 페이지로 될 것이다.
이것을 구현하기 위해선 우리가 서비스 단에서 take 값을 조절해야한다. 기존에 take=1 이었던 것을 take=3으로 변경하여준다.
http://localhost:5000/api/users?page=1위의 url로 첫 번째 페이지를 조회해보면
{
"data": [
{
"id": 1,
"first_name": "a",
"last_name": "a",
"email": "a@a.com"
},
{
"id": 3,
"first_name": "b",
"last_name": "b",
"email": "b@b.com"
},
{
"id": 5,
"first_name": "c",
"last_name": "c",
"email": "c@c.com"
}
],
"meta": {
"total": 9,
"page": "1",
"last_page": 3
}
}다음과 같이 "data"에 3건의 유저 데이터가 조회되고 "meta"의 last_page 속성또한 3으로 호출된다.
Exception Handling (예외상황 다루기)
nest에서 해당 offset 방식의 페이지네이션을 구현하면서 발생한 몇 가지 예외 상황에 관해 한번 다뤄보고자 한다.
( 해당 에러는 본인이 마주한 상황을 토대로 작성했으므로 또 다른 예외 핸들링 과정이 요해진다면 말씀해주시면 감사하겠습니다!! )
💨 오버된 페이지를 요청하였을 경우
바로 위의 예제를 통해 알아보면 편할 것이다. 현재 한 페이지당 유저 데이터는 3건을 불러오게 되었다. 이에 따라 마지막 페이지의 인덱스는 3 일 것이다. 해당 상황으로 보았을 때, 만약 클라이언트 단에서 page = 4 를 요청한다면 어떻게 될까? ( ==> 오버된 페이지 요청 )
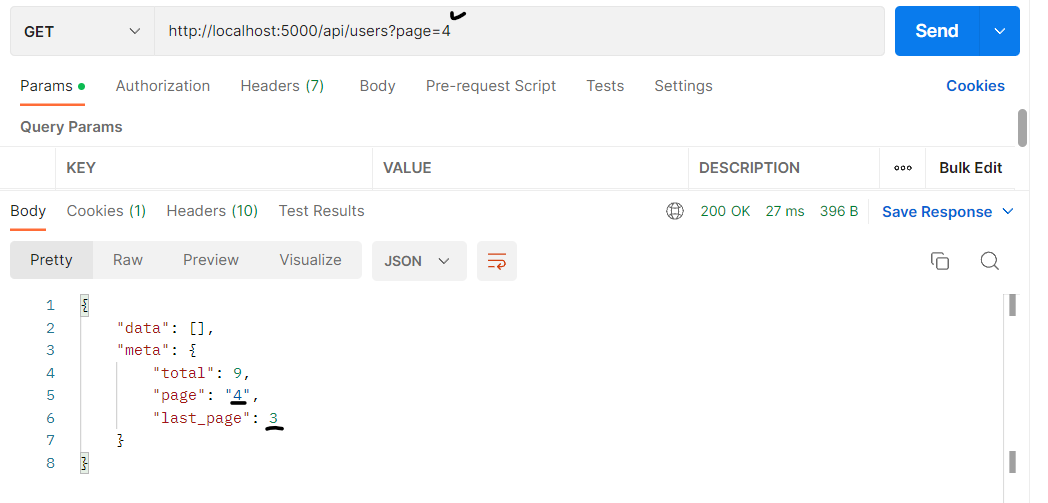
에러를 띄우진 않는다. 사실 에러를 띄우진 않았으므로 에러 핸들링? 이라고 말할 순 없겠지만 위와 같은 상황을 다뤄볼 필요가 있다 생각하였다.
data는 더 이상 유저 객체가 존재하지 않으므로 [] 빈 배열이 출력되었다. 또한 메타데이터의 page 값은 요청한 그대로 4가 출력되었다. 당연한 결과겠지만 오버된 페이지를 요청하였을 때 위와 같이 응답하는 것이 과연 맞을까? 생각하였다.
그에 따라 오버된 페이지 요청 시 NotFoundException을 띄우기로 하였다. 구현체는 아래와 같다.
(사실 이런 경우엔 마지막 페이지를 불러오도록 하는것이 일반적이다. 이는 두 번째 에러상황에서 구현해보고자 한다.)
async paginate(page: number = 1): Promise<any> {
const take = 3;
const [users, total] = await this.userRepository.findAndCount({
take,
skip: (page - 1) * take,
});
const last_page = Math.ceil(total/take);
if (last_page >= page) {
return {
data: users,
meta: {
total,
page,
last_page: last_page,
}
}
} else {
throw new NotFoundException('해당 페이지는 존재하지 않습니다')
}
}다음 상황을 알아보자.
💨 쿼리 문법에 어긋나는 페이지 요청 경우
이번엔 page = -1과 같이 존재할 수가 없는(?) 페이지를 요청하였을 경우이다.
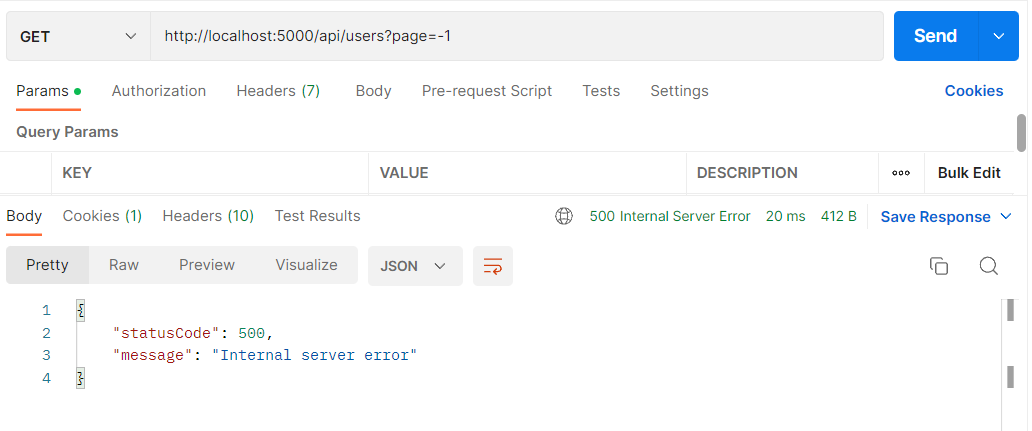
500 "Internal server error" 를 띄우게 된다. 로컬에서 에러 문구를 확인해보니 아래와 같다.

SQL의 문법과 어긋나는 경우가 발생하였다는 문구를 띄운다. SQL 쿼리문에서 데이터를 요청하는데 있어 -1의 데이터를 불러오는 행위는 문법적으로 오류이다. (0 역시 마찬가지이다.)
해당에러는 첫 번째 처리와는 다르게 0 이하의 페이지를 요청하는 경우 첫 번째 페이지를 불러오게끔 처리해주었다.
async paginate(page: number = 1): Promise<any> {
const take = 3;
const [users, total] = await this.userRepository.findAndCount({
take,
// 삼항 연산자를 통해 구현
skip: page <= 0 ? page = 0 : (page - 1) * take,
});
const last_page = Math.ceil(total/take);
if (last_page >= page) {
return {
data: users,
meta: {
total,
// 위의 skip 절의 page와 결과값의 page는 같다. 즉, page값이 0이 찍힐수도 있으므로
// page가 0이하일 경우 page=1을 가지도록 해준다.
page: page <=0 ? page = 1 : page,
last_page: last_page,
}
}
}
else {
throw new NotFoundException('해당 페이지는 존재하지 않습니다')
}
}위와 같이 skip 옵션을 삼항 연산자를 통해 page<=0일 경우 page=1을 받게 함을 구현하였다.
마찬가지로 리턴하는 page의 값 또한 적절하게 수정해준다. (주석 내용 참고)
착각하지 말아야 할 것은 첫 번째 페이지를 보여줌을 구현한다고, page=1로 작성하면 안된다. skip은 offset의 역할이므로 0으로 부터 시작되야 한다. 즉, page=0으로써 작성하는 것이 올바르다.
그럼 포스트맨을 통해 확인해보자. 쿼리문을 통해 page를 0으로 요청하였다.
(가시성을 위해 캡쳐본이 아닌 수기 작성입니다.)
http://localhost:5000/api/users?page=0{
"data": [
{
"id": 1,
"first_name": "a",
"last_name": "a",
"email": "a@a.com"
},
{
"id": 3,
"first_name": "b",
"last_name": "b",
"email": "b@b.com"
},
{
"id": 5,
"first_name": "c",
"last_name": "c",
"email": "c@c.com"
}
],
"meta": {
"total": 9,
"page": 1,
"last_page": 3
}
}관심 분리를 통한 리펙토링 구현
시행 이유 (객체지향적 관점)
우린 여태까지 Nest에서 offset 기반의 페이지네이션을 어떻게 구현하는지 유저 데이터를 불러오는 예시를 통해 알아보았다.
사실 위 코드의 경우엔, 그 다지 불러오게 되는 데이터 및 메타데이터들이 많지 않고, 구현할 로직또한 별 것 없기 때문에 모두 서비스단에서 처리해주었다.
굳이, 간단한 코드에서 과한 분리는 오히려 불필요하기도 하단 생각이 들었기 때문이다.
하지만, 불러오게 될(반환해야 할) 값들이 점점 많아진다고 가정해보자. return 하게 되는 data 와 meta에 담겨할 값, 즉 클라이언트에게 응답해주어야 할 값들이 점점 늘어난다고 하면 이 모든 것들을 서비스단에서 전부 처리해주는 것은 결코 좋은 아키텍처라고 할 수 없을 것이다.
"Page"에 관련된 dto를 생성해 서비스 로직으로부터 분리하여 값을 넘겨주는 형태로 구현해보는 것이 좋지 않을까 생각한다.
또한, 쿼리에서 전달할 파라미터를 처리하는 코드또한 별도로직으로 분리할 필요가 있다고 본다. page 프로퍼티 뿐만 아니라, 페이지네이션의 offset과 limit을 나타내는 findAndCount()의 option 파라미터인 take와 skip 또한 해당 로직에서 구현하면 좋을 것이다.
특히, take와 skip은 페이지네이션을 구성하는 핵심 요소이다. 해당 옵션에 어떠한 값을 주느냐에 따라 구현이 달라질 수 있으므로, 따로 분리하여 외부자가 쉽게 값을 변경하지 못하도록 하는것이 좋다.
그럼 이제 페이지네이션을 위한 모델들을 직접 코드로 생성해보자.
모델을 생성해보자
우리는 몇 개의 "DTO" 클래스가 필요할 것이고, 이를 토대로 모델을 구성한다.
DTO를 생성 및 분류하는 기준은 바로 위의 내용(시행 이유)을 바탕으로 진행한다.
◼ Page DTO
먼저 생성하게 될 DTO는 페이지네이션의 가장 큰 범주의 리턴 값에 접근하기 위한 객체이다.
import { IsArray } from "class-validator";
import { PageMetaDto } from "./page-meta.dto";
export class PageDto<T> {
@IsArray()
readonly data: T[]; // data
readonly meta: PageMetaDto; // meta
constructor(data: T[], meta: PageMetaDto) {
this.data = data;
this.meta = meta;
}
}결과 값으로 받을 data와 meta를 생성자에 정의한다.
data는 단일 유저 값이 아닌 유저 객체의 배열로써 받게 된다. data는 알다시피 유저 엔티티 (User)를 타입으로 가지는데, DTO 단에서 바로 받아와주기 보단 제네릭 타입으로 두고, 코드 재사용성을 높이는 방법을 선택하였다.
meta 속성과 같은 경우엔 바로 오브젝트 형태로써 값을 받아오기 보단, 또 다른 DTO 객체를 설정해주고, 해당 클래스를 참조하게 하도록 하였다.
그에 대한 설명은 아래에서 진행한다.
◼ Page-meta DTO
다음으로 생성하게 될 객체는 우리가 반환하는 값 중 메타 데이터(meta)에 해당 하는 부분이다.
우리는 앞서 메타 값으로써 {page, total, last_page}를 받아왔다. 하지만, 우리는 이 뿐만 아니라 "몇 개의 데이터를 가져오는가 (take)", "다음 페이지 혹은 이전 페이지가 존재하는가" 등등... 더 많은 메타적 요소를 내보내 주어야 할 상황이 생길 것이다.
즉, 우리는 meta값들에 대한 객체를 따로 분리하게 될 것이다.
import { PageMetaDtoParameters } from "./meta-dto-parameter.interface";
export class PageMetaDto {
readonly total: number;
readonly page: number;
readonly take: number;
readonly last_page: number;
readonly hasPreviousPage: boolean;
readonly hasNextPage: boolean;
constructor({pageOptionsDto, total}: PageMetaDtoParameters) {
this.page = pageOptionsDto.page <= 0 ? this.page = 1 : pageOptionsDto.page;
this.take = pageOptionsDto.take;
this.total = total;
this.last_page = Math.ceil(this.total / this.take);
this.hasPreviousPage = this.page > 1;
this.hasNextPage = this.page < this.last_page;
}
}기존에 page, total, last_page 만 보내준 것에서 위에서 언급한 3가지를 추가하였다.
여기서 중요하게 생각해야 할 것은 생성자 매개변수로 받게 되는 {pageOptionsDto, total}: PageMetaDtoParameters 이다. 우리는 고정된 디폴트 page 값을 제외하고는 클라이언트로부터 유동적으로 page 값 및 take(가져올 데이터 갯수)값을 요청받아야 할 것이다.
즉, 해당 필드에 대한 DTO 객체는 따로 생성을 해주고 라우터 메서드의 파라미터로 받아와 주는 것이 이상적이라 생각한다. 이를 구현하기 위해 PageOptionsDto라는 클래스 객체를 생성해 줄 것이고 위의 메타 객체의 생성자 매개변수로 받게 되는 pageOptionsDto가 바로 이를 의미한다.
생성자 파라미터의 타입은 아주 간단히 인터페이스로써 참조하게끔 한다.
◼ Page-meta-paremeter Interface
import { PageOptionsDto } from "./page-options.dto";
export interface PageMetaDtoParameters {
pageOptionsDto: PageOptionsDto;
total: number;
}◼ Page-options DTO
가장 핵심이 될 부분이다. 우리가 클라이언트에게 응답하게 되는 data 및 meta 값들은 클라이언트에서 쿼리문으로써 요청하게 되는 page와 take 값들에 의해 결정이 된다.
리팩토링 이전 서비스단의 paginate() 메서드 내부에서 findAndCount() 를 통해 페이지네이션을 구현체를 잠시 들여다 보자.
const [users, total] = await this.userRepository.findAndCount({
take,
skip: page <= 0 ? page = 0 : (page - 1) * take,
});위에서도 언급하였지만 findAndCount() 매개변수로 쓰인 take, skip은 optional하다. 본인은 여기서 어떤 점을 눈여겨 봤냐면 skip 옵션이 page와 take로 나타내질 수 있다는 것이다. 즉, 우리가 일반적 생각으로 클라이언트에서 요청할 시 take와 skip 옵션을 요청할 수 있겠지만 page와 take를 요청함으로써 거의 모든 것을 다 응답해 줄 수 있다고 생각하였다. (물론 단순히 생각해도 page를 요청하는것이 더 깔끔하긴 하다... ㅎ)
import { Type } from "class-transformer";
import { IsInt, IsOptional } from "class-validator";
export class PageOptionsDto {
@Type(() => Number)
@IsInt()
@IsOptional()
page?: number = 1;
@Type(() => Number)
@IsInt()
@IsOptional()
readonly take?: number = 3;
get skip(): number {
return this.page <=0 ? this.page = 0 : (this.page - 1) * this.take;
}
}옵션으로 쓰이게 될 page와 take를 class-validator의 @IsOptional로써 설정해주고, 고정 디폴트 값만 넣어준다.
클라이언트에서 쿼리문으로 요청 시 page값이 0이하의 수일 경우, 앞서 언급했다시피 쿼리 문법 오류를 띄우게 되므로 skip은 getter 접근자를 이용해 처리해주었다.
이제 페이지네이션을 구현하는데 있어 (우리의 구현에 필요한 한정) 필요한 모델 객체들을 다 생성하였다.
이제 서비스단과 컨트롤러단에서 이를 녹여주기만 하면 된다.
◼ Service
컨트롤러의 요청에 대한 라우터 메서드 파라미터로써 pageOptionsDto를 받아올 것이므로 서비스의 paginate() 메서드 파라미터 또한 이를 받아준다.
async paginate(pageOptionsDto: PageOptionsDto): Promise<PageDto<User>> {
const [users, total] = await this.userRepository.findAndCount({
take: pageOptionsDto.take,
skip: pageOptionsDto.skip,
});
const pageMetaDto = new PageMetaDto({pageOptionsDto, total});
const last_page = pageMetaDto.last_page;
if (last_page >= pageMetaDto.page) {
return new PageDto(users, pageMetaDto);
} else {
throw new NotFoundException('해당 페이지는 존재하지 않습니다');
}
}더 좋은 코드가 분명히 있겠지만은 일단은 위와 같이 작성해보았다. 기존에 서비스 로직에서 모든 처리를 해주었던거에 비해 적절하게 책임과 관심을 분리해줌으로써 훨씬 가독성이 좋아진 것을 확인할 수 있었다. (의존 관계를 중점으로 간단한 설계)
◼ Controller
기존에 page 값만 Query 값으로써 받아온것과 달리 page와 take 값이 담긴 PageOptionsDto 자체를 넘겨줄 것이다.
// 생략
@Controller('users')
export class UserController {
constructor(private userService: UserService){}
@Get()
async all(@Query() pageOptionsDto: PageOptionsDto): Promise<PageDto<User>>{
return await this.userService.paginate(pageOptionsDto);
}
// 생략
}✔ 포스트맨을 통한 응답 확인
현재 page와 take의 디폴트 값은 page=1과 take=3이다.
즉, 쿼리문을 url 내에 작성하지 않았을 시에 위의 결과가 나올 것이다.
http://localhost:5000/api/users{
"data": [
{
"id": 1,
"first_name": "a",
"last_name": "a",
"email": "a@a.com"
},
{
"id": 3,
"first_name": "b",
"last_name": "b",
"email": "b@b.com"
},
{
"id": 5,
"first_name": "c",
"last_name": "c",
"email": "c@c.com"
}
],
"meta": {
"page": 1,
"take": 3,
"total": 9,
"last_page": 3,
"hasPreviousPage": false,
"hasNextPage": true
}
}이번엔 page=2, take=2의 값을 요청해보자.
http://localhost:5000/api/users?page=2&take=2{
"data": [
{
"id": 5,
"first_name": "c",
"last_name": "c",
"email": "c@c.com"
},
{
"id": 6,
"first_name": "d",
"last_name": "d",
"email": "d@d.com"
}
],
"meta": {
"page": 2,
"take": 2,
"total": 9,
"last_page": 5,
"hasPreviousPage": true,
"hasNextPage": true
}
}이번엔 에러처리를 해주었던 부분또한 테스트 해보자.
💨 page <= 0 의 경우
http://localhost:5000/api/users?page=-1&take=2{
"data": [
{
"id": 1,
"first_name": "a",
"last_name": "a",
"email": "a@a.com"
},
{
"id": 3,
"first_name": "b",
"last_name": "b",
"email": "b@b.com"
}
],
"meta": {
"page": 1,
"take": 2,
"total": 9,
"last_page": 5,
"hasPreviousPage": false,
"hasNextPage": true
}
}💨 오버된 page의 경우
http://localhost:5000/api/users?page=4&take=3{
"statusCode": 404,
"message": "해당 페이지는 존재하지 않습니다",
"error": "Not Found"
}이렇게 포스트맨을 통해 모든 요청 / 응답이 원활히 이루어지는 것을 확인할 수 있다.
생각정리
nest에서 페이지네이션을 어떻게 구현하는가에 대해 typeorm을 이용해 만들어보았고, 그 후 의존관계에 따른 관심 분리를 통한 모델 생성 작업까지 간단히 해보았다.
이번 포스팅에선 "TypeORM"의 FindOperator를 통한 페이지네이션 구현에 대해 알아보았지만, 다른 방법 또한 존재한다. 그 방법은 바로 "QueryBuilder"를 이용한 방법이다.
SQL 관점에서 좀 더 가깝게 접근하는 "QueryBuilder"와 같은 경우엔 몇 가지 단점(다음 포스팅에서 알아보자.)이 있지만 더 쉽게 작업을 수행할 수 있다. 기존 FindOperator를 통한 구현과 어떤 차이가 있는지를 알아보는 작업또한 유의미할 것이라 생각이 든다.
포스팅이 너무 길어지기 때문에 다음 포스팅에서 해당 내용에 대해 간단히 알아보고 QueryBuilder를 통한 페이지네이션 구현도 해보려고 한다.
뿐만 아니라, "Pagination"하면 필수적으로 연관이 있는 "Infinite Scroll" 방법과 "Searching"까지 nest에선 어떻게 구현하는지 알아보고자 한다.


잘 읽었습니다. 좋은 글 감사합니다 :)