
배경
ORM에 대해 찾아보면, 생각보다 내가 정말 아무것도 모르고 개발을 했구나...라는 느낌이 든다. 예의가 없었다랄까.
ORM이 없던 시절에는 JDBC를 사용했는데, 나는 이걸 최근에야 배웠다. 그런데 이게 신기술이 아니라 ORM으로 대체되고 있다고 하니 혼란스러웠다. JDBC를 공부하면서 놀랐던 점은 Statement를 쓰든 PreparedStatement를 쓰든, 내가 직접 사용해본 적이 없었다는 것이다. 그래서 그냥 내가 경험이 없어서 못 본 건가 했는데, 운 좋게 오늘 이걸 접하게 되어 공부하게 됐다.
ORM이 없을 때는 JDBC(Java DataBase Connectivity)를 사용해서 직접 쿼리문을 작성해야 했다.
Statement를 사용하면 "SELECT Name FROM DB_USERS"처럼 String 형태로 쿼리를 직접 작성해야 했고, PreparedStatement라는 좀 더 향상된 클래스를 쓰면 "SELECT ? FROM DB_USERS"처럼 ? 인자만 바꿔 끼우는 형태로, 미리 컴파일된 쿼리를 비교적 빠르게 실행할 수 있었다. 결국 둘 다 쿼리문을 String으로 작성해야 하는 방식이다.
이제 ORM을 배워보자.
ORM
ORM(Object Relational Mapping)은 SQL을 직접 작성하지 않고 객체 지향적인 방식으로 데이터베이스를 다룰 수 있게 해주는 기술이다. 자바 객체와 데이터베이스 테이블을 자동으로 매핑해주기 때문에, 개발자가 객체를 조작하듯이 데이터베이스를 조작할 수 있다.
JDBC에서 ORM으로
ORM이 나오기 전에는 JDBC(Java Database Connectivity) 를 사용해서 직접 SQL 쿼리를 작성했다.
Statement: "SELECT name FROM DB_USERS" 처럼 완전한 문자열 쿼리를 작성
PreparedStatement: "SELECT ? FROM DB_USERS" 처럼 ?를 변수 형태로 넣고 실행. 미리 컴파일된 상태라 비교적 빠르다.
둘 다 결국 SQL 쿼리를 문자열로 작성해야 하고, 코드와 SQL이 뒤섞이는 불편함이 있었다.
ORM 종류
-
Java: JPA(Java Persistence API), Hibernate
-
Python: SQLAlchemy
-
Node.js: Sequelize
JPA
JPA는 인터페이스로, 자바에서 ORM 표준을 제공한다. 구현체로는 Hibernate, OpenJPA 등이 있다.
-
RAW JPA(EntityManager 사용): JPA를 직접 호출해서 DB 연결
-
Spring Data JPA: JPA를 스프링 부트 환경에서 더 편하게 쓰도록 추상화한 모듈. Repository 인터페이스로 앱과 DB를 연결한다.
Spring Data JPA 내부 구현도 결국 JPA(EntityManager)를 사용한다.
Spring Data JPA
Spring Data JPA를 설정하기 위해서는 pom.xml 이나 build.gradle에 의존성을 추가해야 하는데, 이는 우리가 많이 본 다음과 같다.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
(...생략)
</dependencies>의존성 추가 후, 기본 사용 흐름은 다음과 같다.
- Entity 생성
@Entity
@Getter @Setter
public class User {
@Id
@GeneratedValue
private Long id;
private String name;
}- Repository 생성
public interface UserRepository extends JpaRepository<User, Long> {
// 기본 CRUD + 필요시 메서드 추가
}-> 여기서 JPA Repository라는 마지막에 추가 예정
- Service으로 등록
@Service
public class UserService {
private final UserRepository repo;
public UserService(UserRepository repo) {
this.repo = repo;
}
public List<User> getAllUsers() {
return repo.findAll();
}
}- Controller
@RestController
@RequestMapping("/users")
public class UserController {
private final UserService service;
public UserController(UserService service) {
this.service = service;
}
@GetMapping
public List<User> list() {
return service.getAllUsers();
}
}JPA Repository
org.springframework.data.jpa.repository.JpaRepository는 기본 CRUD 메서드를 제공하는 인터페이스로, 제네릭 타입을 사용한다.
자주 쓰는 기능:
save(entity): 저장 및 업데이트
findById(id): id로 조회
findAll(): 전체 조회
delete(entity): 삭제
근데 생각보다 기능이 그렇게 많지 않아서 다 정리해보면
| Method Name | 설명 |
|---|---|
| save | 엔티티 저장 및 업데이트 |
| findById | ID로 엔티티 조회 |
| findAll | 전체 엔티티 조회, 정렬/페이징 가능 |
| delete | 엔티티 삭제 |
| flush | 변경사항 즉시 DB 반영 |
| saveAndFlush | 저장 후 즉시 flush |
| saveAllAndFlush | 여러 엔티티 저장 후 즉시 flush |
| deleteInBatch | 여러 엔티티 일괄 삭제(주의: DB sync 문제 가능) |
| deleteAllInBatch | 전체 엔티티 일괄 삭제 |
| getReferenceById | 프록시 객체 반환(실제 접근 시 EntityNotFoundException 가능) |
JPA Repository의 추가 기능(사실 이건 아직 잘 모르겠지만, 추후에 알게쬬)
-
페이징과 정렬: Pageable, Sort를 활용해 대량 데이터 처리에 유리하다.
-
커스텀 쿼리 메서드: 메서드 이름만으로 자동 쿼리 생성, 복잡한 쿼리는 @Query로 직접 작성 가능.
-
DTO 프로젝션: 엔티티 전체가 아니라 필요한 필드만 조회할 수 있다.
-
Query by Example(QBE): 예시 객체로 동적 쿼리 생성.
-
Auditing: 엔티티 생성/수정 시점 자동 기록.
-
커스텀 리포지토리 구현: 직접 인터페이스/클래스 만들어 복잡한 로직 추가 가능.
Hibernate은?
하나의 ORM 프레임워크로, Hibernate는 JPA 명세를 실제로 구현한 라이브러리로, Spring Data JPA와는 역할이 다르다.
Spring Data JPA는 JPA를 더 쉽게 쓰도록 추상화한 모듈이며, 내부적으로 Hibernate를 구현체로 사용할 수 있다.
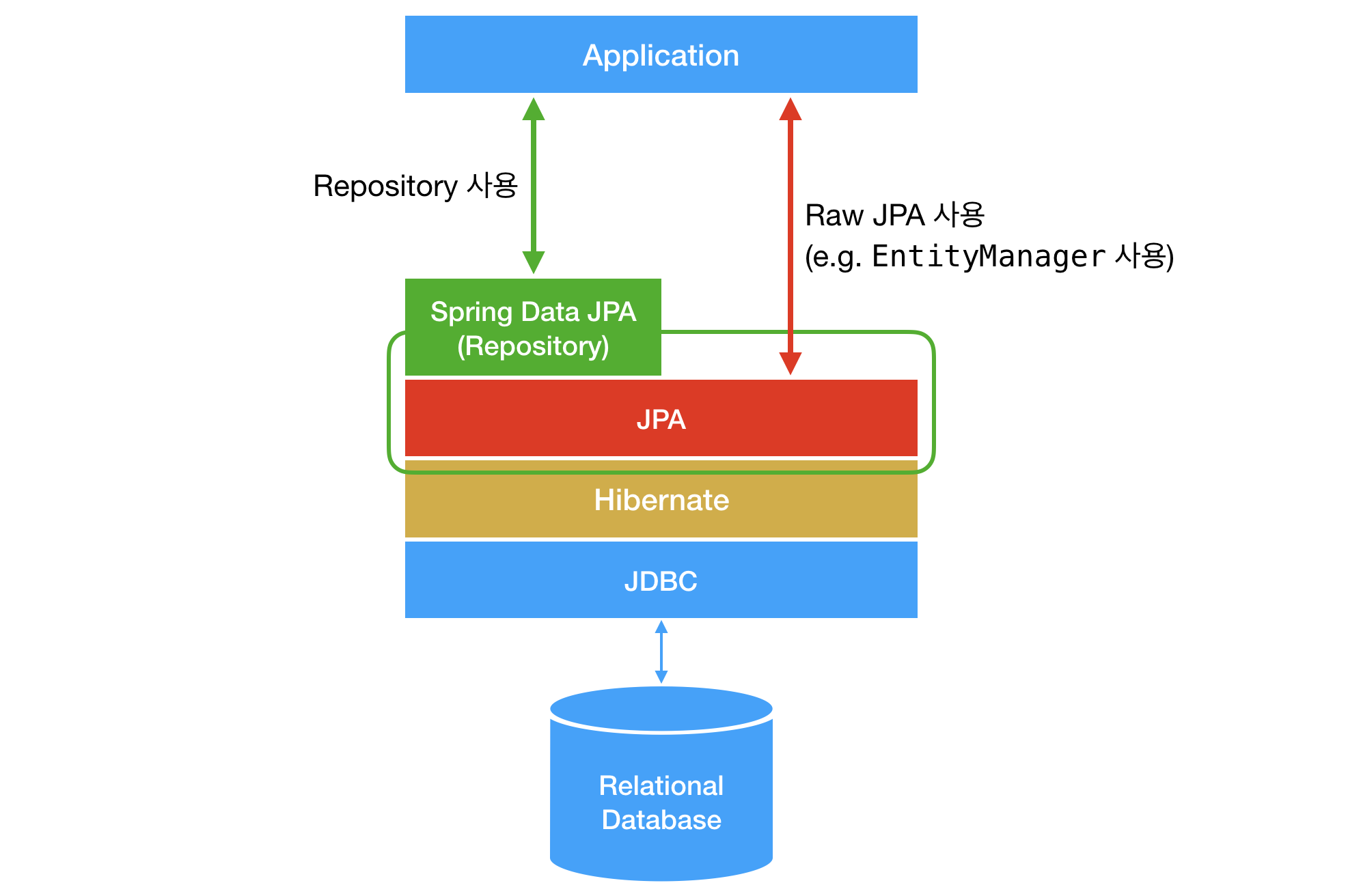 출처 :https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
출처 :https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
즉, Spring Data JPA 의존성을 추가하면 Hibernate가 자동으로 포함되고, application.yml에서 다양한 Hibernate 옵션을 설정해 동작 방식을 세밀하게 제어할 수 있다
server:
port: 8080
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/devbeekei?characterEncoding=UTF-8&serverTimezone=Asia/Seoul
username: root
password: password
jpa:
show-sql: true
hibernate:
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
ddl-auto: validate
properties:
hibernate:
enable_lazy_load_no_trans: false
format_sql: true
use_sql_comments: true
logging:
level:
org:
hibernate:
type:
descriptor:
sql: trace대표적인 설정 사항은 다음과 같다.
jpa.hibernate.dialect
데이터베이스 종류와 버전에 맞게 SQL 문법을 자동으로 맞춰주는 옵션
jpa.hibernate.ddl-auto
스키마 자동생성 설정
- none
- update : 테이블의 내용이 변경된 경우 자동으로 스키마 update
- create : 애플리케이션 구동 시 스키마 create
- create-drop : 애플리케이션 구동 시 스키마 create, 종료 시 drop
- validate : 매핑 유효성 검증만 실행
jpa.properties.hibernate.enable_lazy_load_no_trans
영속성 컨텍스트가 종료되어도, 새로운 데이터베이스 커넥션을 획득해서 지연로딩이 가능하도록 설정
(성능상 false 권장)
jpa.properties.hibernate.format_sql
Query 출력 시 Query를 가독성 좋게 줄바꿈(jpa.show-sql이 true일때)
jpa.properties.hibernate.use_sql_comments
Query 출력 시 설명 주석 추가(jpa.show-sql이 true일때)
logging.level.org.hibernate.type.descriptor.sql
Query 출력 시 데이터 값도 출력
결론
ORM 을 사용하면 객체지향적으로 Database를 다룰 수 있어서, JAVA의 특징과도 잘 맞는다. ORM을 사용해서 개발자도 Database와 더 쉽게 소통이 가능하고, 또한 코드의 가독성과 재사용성이 높아지고, 만약 데이터베이스 구조가 변경되어도 객체모델만 수정하면 되기 때문에 유지 보수성이 크게 향상된다. 그리고 Spring을 사용하면 ORM으로 JPA가 구현된 hibernate을 사용한다.
출처
https://devbksheen.tistory.com/entry/JPA-%ED%95%98%EC%9D%B4%EB%B2%84%EB%84%A4%EC%9D%B4%ED%8A%B8
