
문제 이해
[ 입력형태 / 조건 ]
name
그리워하는 사람의 이름을 담은 문자열 배열 | ["may", "kein", "kain", "radi"]
yearning
각 사람별 그리움 점수를 담은 정수 배열 | [5, 10, 1, 3]
photo
각 사진에 찍힌 인물의 이름을 담은 이차원 문자열 배열 | [["may", "kein", "kain", "radi"],["may", "kein", "brin", "deny"], ["kon", "kain", "may", "coni"]]
[ 문제 ]
=> 사진들의 추억 점수를 photo에 주어진 순서대로 배열에 담아 return
[ 풀이 ]
Map에 각 인물당 추억점수를 기록하고, photo를 순회하며 맵의 값을 합산
코드
> [성공] 1차 시도 : Map + .containsKey 이용
- 생각한 풀이 그대로 구현
import java.util.*;
class Solution {
public int[] solution(String[] name, int[] yearning, String[][] photo) {
Map<String, Integer> map = new HashMap<>();
for(int i=0; i<name.length; i++){
map.put(name[i], yearning[i]);
}
int[] answer = new int[photo.length];
int point = 0;
for(String[] names : photo){
for(String n : names){
answer[point] += map.containsKey(n) ? map.get(n) : 0;
}
point++;
}
return answer;
}
}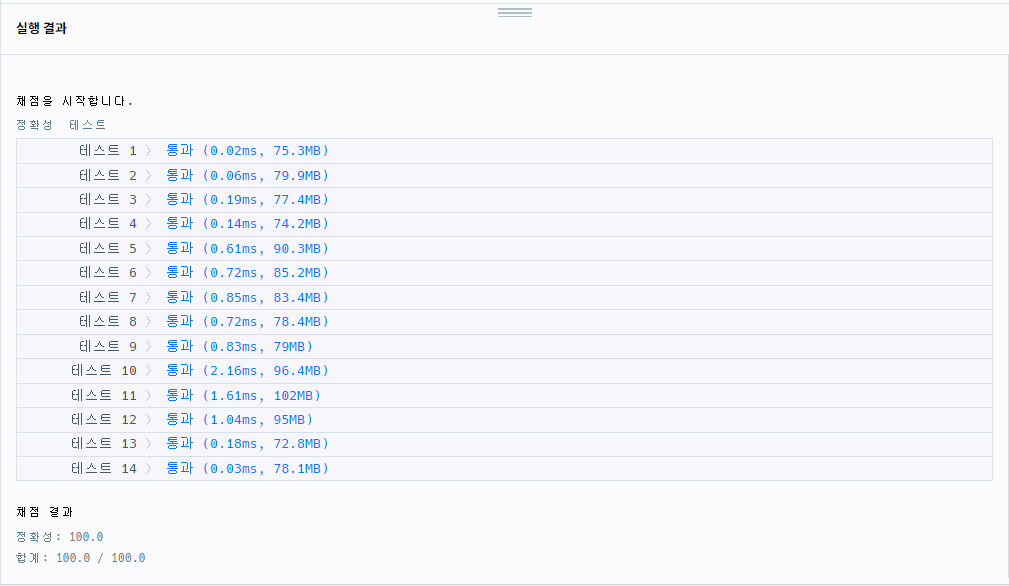
=> 테케 10에서 2.16ms라는 상당히 느린 실행 결과가 나왔음
> [성공] 2차 시도 : Map + .get 이용 - 1
- 생각한 풀이 그대로 구현
import java.util.*;
class Solution {
public int[] solution(String[] name, int[] yearning, String[][] photo) {
Map<String, Integer> map = new HashMap<>();
for(int i=0; i<name.length; i++){
map.put(name[i], yearning[i]);
}
int[] answer = new int[photo.length];
int point = 0;
for(String[] names : photo){
for(String n : names){
answer[point] += map.get(n) == null ? 0 : map.get(n);
}
point++;
}
return answer;
}
}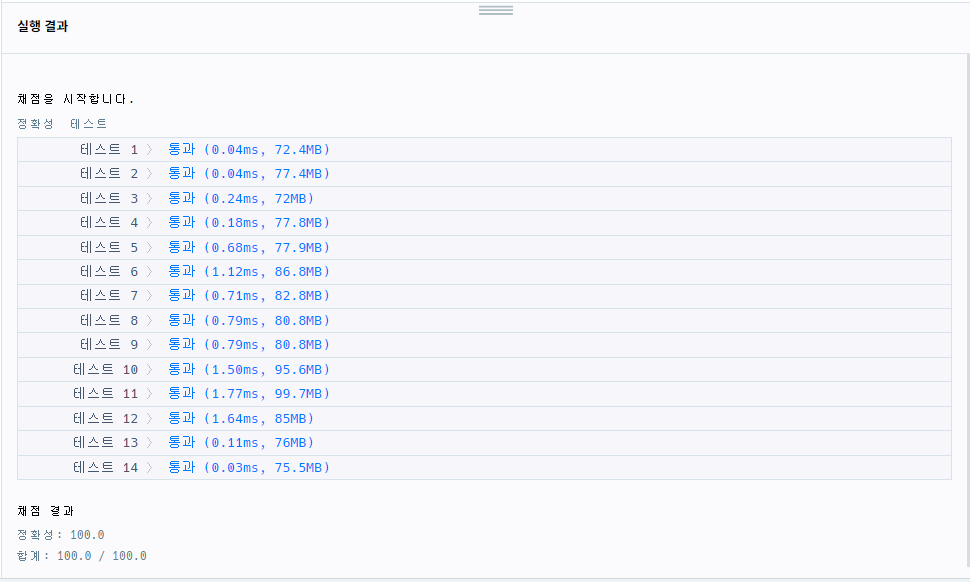
=> 큰 차이는 없어보임
시도 1,2 둘다 중복 연산이므로 비효율적인 방식이었음..
> [성공] 3차 시도 : Map + .get 이용 - 2
- 생각한 풀이 그대로 구현
import java.util.*;
class Solution {
public int[] solution(String[] name, int[] yearning, String[][] photo) {
Map<String, Integer> map = new HashMap<>();
for(int i=0; i<name.length; i++){
map.put(name[i], yearning[i]);
}
int[] answer = new int[photo.length];
int point = 0;
for(String[] names : photo){
for(String n : names){
answer[point] += map.get(n) == null ? 0 : map.get(n);
}
point++;
}
return answer;
}
}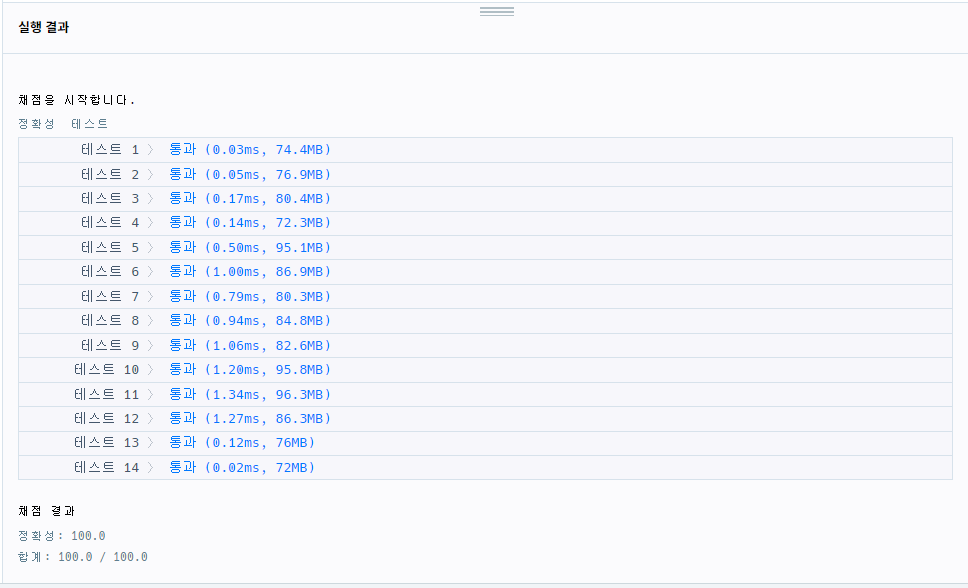
=> 중복 연산을 줄이니 좀더 빠르게 실행이 가능했음
< 참고 - map.containsKey()와 map.get()의 차이 >
-
map.containsKey()
해당 key값이 존재하는지에 따라 true/false로 return -
map.get()
해당 key값이 존재하는지에 따라 value값/null 로 return
따라서, value값이 null일 경우는 판단할 수 없음!
TIP : 만약 Map에서 value 값으로 null을 허용하지 않는다면, map.containskey()와 map.get() 둘 다 맵의 특정 key 유무를 알아낼 수 있다. 중복 연산을 하지 않도록 조심하자
