
1. 캐시 메모리란?
1) 기능/역할
- CPU와 메모리 사이에서 자주 사용되는 프로그램과 데이터를 저장해두는 범용 메모리
2) 목적
- 처리 속도 향상
- CPU와 메모리의 속도차에 따른 병목현상 감소
3) 물리적 특성
- DRAM보다 작지만 속도가 빠른 SRAM을 기반으로 만들어진 메모리 소자
cf) 'CPU와 메모리 사이' & DRAM/SRAM 은 이후 메모리 계층구조에서 확인 필요.
2. 캐시 메모리 사상기법
1) direct-mapping
2) fully-associative mapping
3) n-way associative mapping
캐시 메모리에 대해 구글링 하다보면 세 가지 사상기법이 있다고 나온다.
처음에 이 부분을 읽어볼 때 왠지 모르게 이해가 잘 안 되었는데,
돌이켜 생각해보면 세가지가 완전히 다른 방식이라고 생각하고 이해하려 해서 그런 것 같다.
개인적으로 정리한 결론은 세 가지 방식이라곤 하지만
똑같은 방식에 다른 설정을 적용한 것에 가깝다고 생각한다.
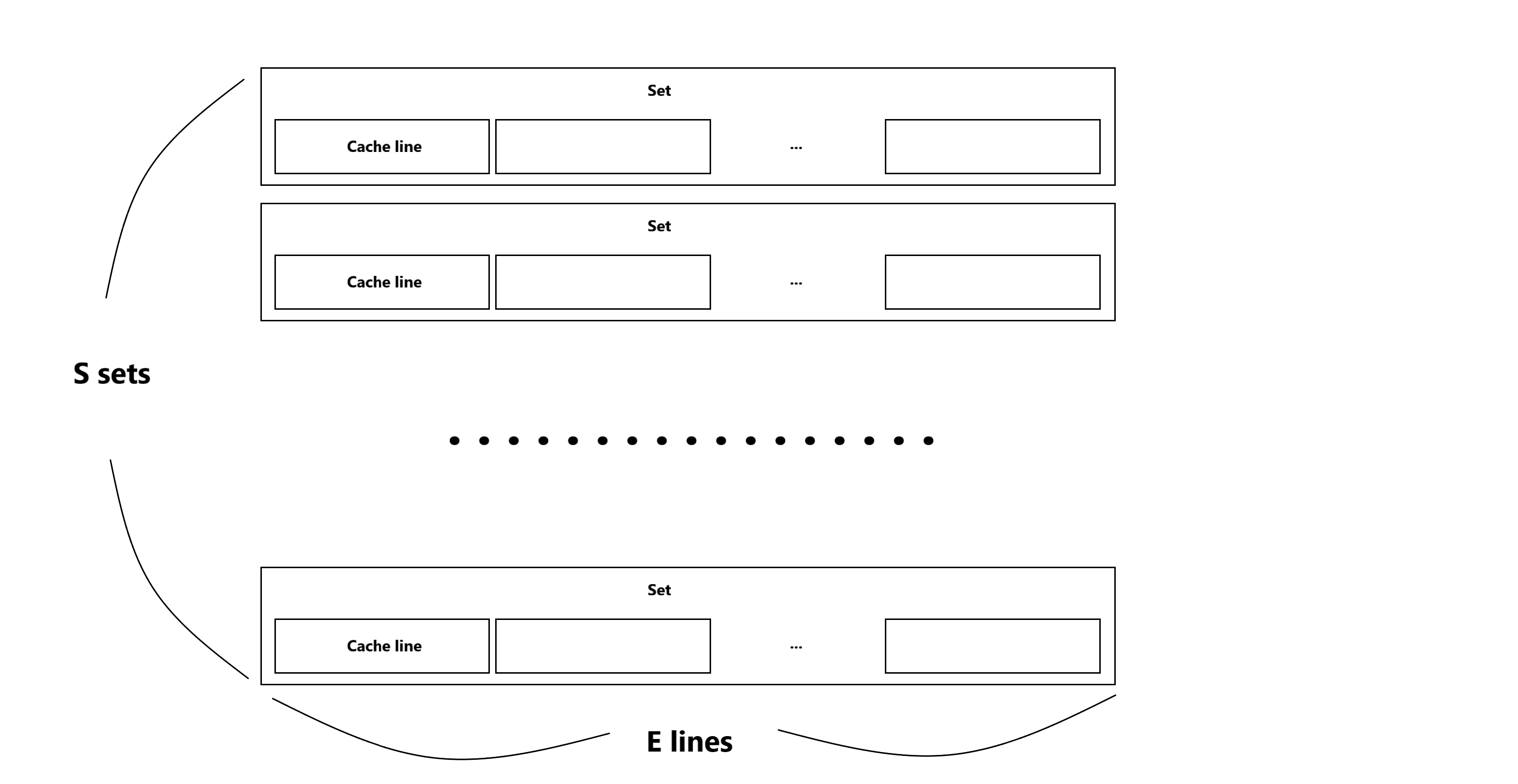
E == 1이면 direct-mapping
S == 1이면 fully-associative mapping
S > 1 && E > 1 이면 E-way set associative mapping
1) direct-mapping
- 하나의 set에 하나의 entry만 존재하기 때문에 메모리 경합/충돌 비율이 높다.
- 구현이 가장 간단하며, 캐시 접근이 가장 간단하다.
2) fully-associative mapping
- 메모리 블록 별로 정해진 위치가 없기 때문에 캐시 메모리가 가득 차지 않는 이상 메모리 경합/충돌이 발생하지 않는다.
- 캐시 접근 시 모든 태그를 검사해야 하기 때문에 비용이 많이 발생한다.
3) n-way associative mapping
- 그래서 1/2를 적당히 섞어놨다.
| 저장 | 접근 | |
|---|---|---|
| direct-mapping | 빠름 | 느림 |
| fully-associative | 느림 | 빠름 |
| n-way associative | 보통 | 보통 |
3. 캐시라인 구조
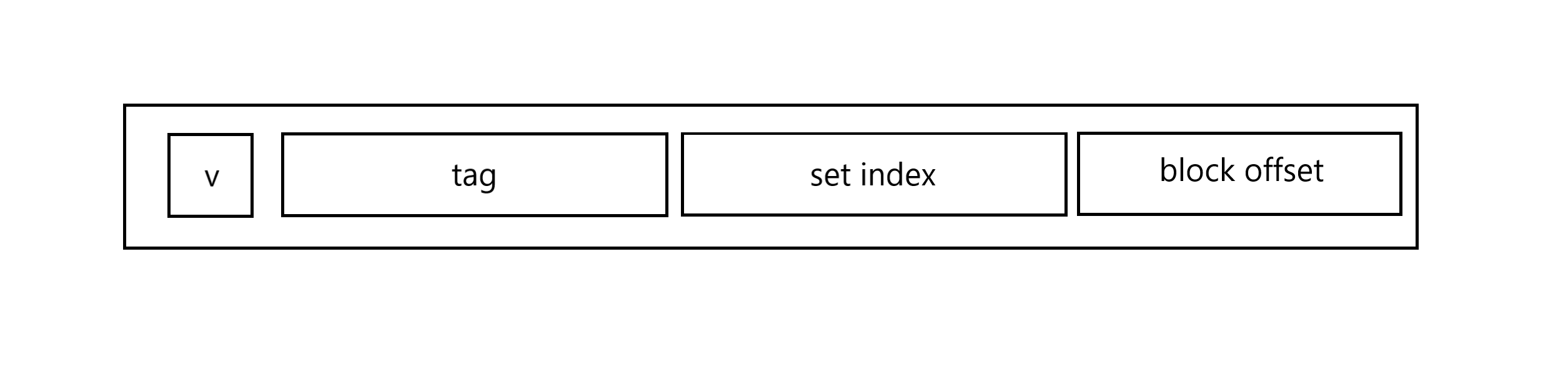
1) 유효비트 (v)
2) tag
- 캐시 탐색 시 사용되는 메모리 주소의 일부이며, 동일한 set 내에서 블록을 구별해주는 비트
3) set index - 캐시 탐색 시 저장된 set의 주소를 저장하고 있는 비트
- fully-associative mapping 에서는 set이 하나뿐이기 때문에 지정되지 않음.
4) block offset - 캐시에 저장된 데이터
=> 캐시 탐색 시,
1 - set index로 목표 캐시가 저장된 set 탐색
2 - tag / v 로 목표 set 내에서 목표 캐시 탐색
4. 캐시 메모리 내에서의 계층구조
- 캐시 메모리 자체가 L1/L2/L3 와 같이 계층적으로 나누어지기도 한다.
- 메모리 계층구조와 같이 캐시 탐색 시 L1 => L2 => L3 순으로 접근되며,
level이 낮아질수록 느리지만 커진다.
5. cf) TLB (Translation Lookaside Buffer)
1) TLB란?
- 가상 메모리 주소를 물리적인 주소로 변환하는 속도를 높이기 위해 사용되는 캐시
- 최근에 일어난 가상 메모리 주소와 물리 주소의 변환 테이블 저장
2) 배경
- 기존의 가상메모리 접근방식
1 - 가상주소 획득
2 - 페이징 테이블 (메인메모리 접근 +1) 에서 가상주소 조회 및 물리주소 구성
3 - 물리주소 접근 (메인메모리 접근 +2)
이에 따라, 메인메모리 접근 횟수를 줄이기 위해 TLB 등장
- TLB 접근방식
1 - 가상주소 획득
2 - TLB 에서 가상주소 조회 및 물리주소 구성
3-1 (2에서 주소 획득 시) 물리주소 접근 (메인메모리 접근 +1)
3-2 (2에서 주소 미획득 시) 페이징 테이블 (메인메모리 접근 +1) 에서
가상주소 조회 및 물리주소 구성 후 물리주소 접근 (메인메모리 접근 +2)
3) 목적
- CPU - 메모리 사이에 메모리 보다 작지만 빠른 캐시 메모리 참조 단계를
하나 끼워 넣어서 메모리 참조횟수를 줄인다. - 결국 메모리 계층 구조에서의 캐시 메모리의 존재 의의와 같다.
4) 개인적인 정리
페이징 테이블의 캐시 테이블
