이번에는 실제로 SQL을 사용해서 어떻게 데이터베이스를 만드는 쿼리를 작성해야하는지 알아보겠습니다.
목차
- 기본개념 - Join과 SubQuery 개념
- 여러가지 요구 사항에 대한 SQL 쿼리 짜는 방법 배우기
- offset paging(페이징)과 cusor-based paging 배우기
0. 기본개념 - Join과 SubQuery 개념
해당 주제는 스터디 워크북에서 sql 문법에 대해 잘 알고 있다고 가정하고 시작했기에, 아래 블로그들을 참고해서 사전공부를 진행했습니다!
SQL 기본 문법: JOIN(INNER, OUTER, CROSS, SELF JOIN)
[SQL] 테이블 JOIN의 개념과 예제
[MYSQL] 📚 테이블 조인(JOIN) - 그림으로 알기 쉽게 정리
SQL / MySQL 서브쿼리(SubQuery)
[MYSQL] 📚 서브쿼리 개념 & 문법 💯 정리
0.1. Join
1) join: 서로 다른 각각의 테이블 속 데이터를 동시에 보여주려고 할 때 사용하는 SQL문
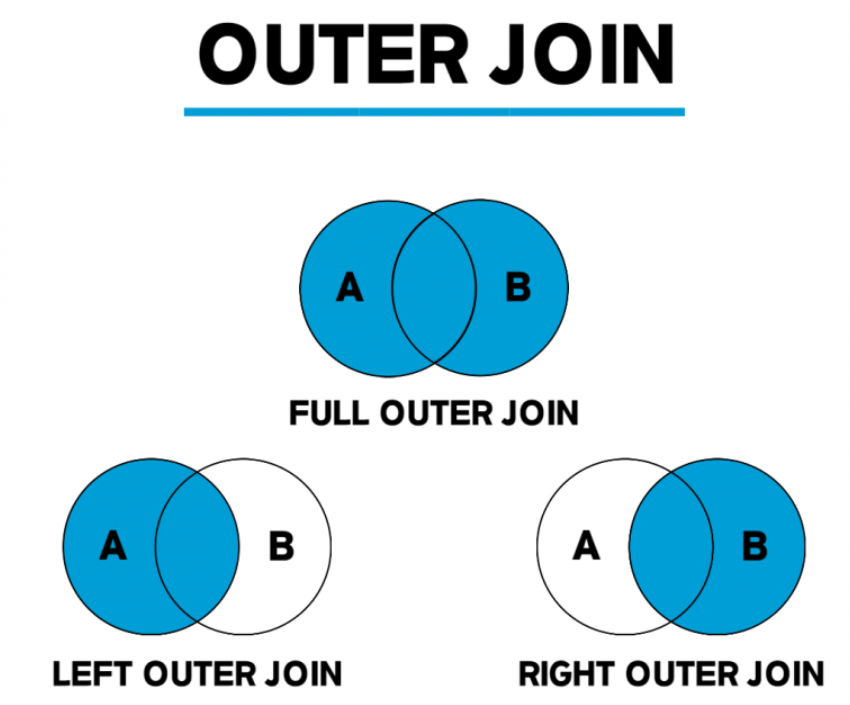
2) join의 종류
- inner join: 가장 basic, 양측 모두에 존재하는 것만 조인 (교집합)
- outer join
- left join: 좌측 테이블 데이터에 추가로 우측 정보를 조인하는 문법, 좌측 테이블 중 조인 불가능한 것들도 모두 결과(Null)로 채운다.
- right join: LEFT 조인을 뒤집은 개념
- full join: 좌측,우측 상관없이 데이터가 있는 것은 모두 가져오고 없는 것은 모두 Null 이 되는 것 (합집합)
3) 형식
-- inner join
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인 조건>
[WHERE 검색 조건]
#INNER JOIN을 JOIN이라고만 써도 INNER JOIN으로 인식-- outer join
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두 번째 테이블(RIGHT 테이블)>
ON <조인 조건>
[WHERE 검색 조건]4) 예시 쿼리
-- (inner) join
SELECT
comments.body,
users.nickname
FROM
comments
JOIN users ON
users.id = comments.user_id
WHERE
comments.photo_id = 1
;
-- outer left join
SELECT photos.filename, users.nickname
FROM photos
LEFT JOIN users ON users.id = photos.user_id0.2. Subquery
1) Subquery: 쿼리 안에 포함된 또 다른 쿼리. 주로 데이터 검색, 조건 필터링, 집계 연산 등 특정한 데이터를 추출하거나 처리할 때 사용.
2) Subquery의 특징 및 종류
-
특징:
()안에 작성되며, 메인 쿼리에서 활용됨.- 독립적으로 실행 가능한 쿼리로, 메인 쿼리에서 필요로 하는 데이터를 반환함.
- 반환값 형태에 따라 스칼라 값, 단일 행, 다중 행, 다중 열로 나뉨.
-
종류:
- 스칼라 서브쿼리: 하나의 값을 반환하며, SELECT 문의 필드나 조건에 사용.
- 다중 행 서브쿼리: 여러 행을 반환하며,
IN,ANY,ALL과 같은 연산자와 함께 사용. - 다중 열 서브쿼리: 여러 열을 반환하며, 일반적으로
EXISTS와 함께 사용. - 상관 서브쿼리 (Correlated Subquery): 메인 쿼리의 값을 참조하여 동작. 서브쿼리가 메인 쿼리와 반복적으로 실행됨.
3) 형식
-- 일반적인 서브쿼리
SELECT <열 목록>
FROM <테이블>
WHERE <열> = (
SELECT <열>
FROM <테이블>
WHERE <조건>
);
-- 다중 행 서브쿼리
SELECT <열 목록>
FROM <테이블>
WHERE <열> IN (
SELECT <열>
FROM <테이블>
WHERE <조건>
);
-- 상관 서브쿼리
SELECT <열 목록>
FROM <테이블> T1
WHERE EXISTS (
SELECT 1
FROM <테이블> T2
WHERE T2.<열> = T1.<열> AND <조건>
);4) 예시 쿼리
-- 1. 스칼라 서브쿼리: 가장 높은 급여를 받는 직원의 이름 출력
SELECT name
FROM employees
WHERE salary = (
SELECT MAX(salary)
FROM employees
);
-- 2. 다중 행 서브쿼리: 특정 부서에서 근무하는 직원의 이름 출력
SELECT name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location = 'New York'
);
-- 3. 상관 서브쿼리: 자신보다 급여를 적게 받는 직원의 수 출력
SELECT name, (
SELECT COUNT(*)
FROM employees E2
WHERE E2.salary < E1.salary
) AS lower_salary_count
FROM employees E1;0.3. Join vs Subquery 비교
- Join은 여러 테이블의 데이터를 결합하여 하나의 결과로 출력하는 데 사용.
- Subquery는 메인 쿼리에 필요한 데이터를 제공하기 위한 용도로 사용.
- 성능 면에서 Join이 일반적으로 효율적이며, Subquery는 간단한 작업에서 가독성을 높이는 데 유리.
Tip: Join은 관계형 데이터 처리에서 성능과 효율성을 중시할 때 유용하며, Subquery는 특정 데이터 추출이나 조건 필터링에 적합.
2) 조인과 서브쿼리의 형식 비교
| 구분 | 조인 | 서브쿼리 |
|---|---|---|
| 작성 방식 | 여러 테이블을 JOIN 절로 연결하여 하나의 결과 집합으로 결합. | 쿼리 내부에 또 다른 쿼리를 포함 (() 안에 작성). |
| 주요 키워드 | JOIN, ON, LEFT, RIGHT, FULL, INNER 등. | SELECT, WHERE, IN, EXISTS, =, <, > 등. |
| 사용 위치 | FROM 절에서 테이블을 결합하거나 필요한 데이터를 조건에 따라 연결. | 메인 쿼리의 SELECT, WHERE, FROM, HAVING 절 등에 사용. |
| 반환 값 | 하나의 테이블 형태로 반환되며 모든 연결된 열과 데이터가 결과에 포함됨. | 스칼라 값, 단일 행, 다중 행, 다중 열 등. |
| 종속성 | 완전히 통합된 실행으로, 모든 연결된 테이블이 한 번에 처리됨. | 독립적 실행 가능하며 메인 쿼리와 연결되거나, 상관 서브쿼리로 메인 쿼리에 종속될 수 있음. |
| 복잡성 | 여러 테이블을 연결하므로 관계가 명확히 정의되지 않으면 혼란스러울 수 있음. | 쿼리 안에 쿼리가 포함되어 논리가 중첩되므로 이해와 디버깅이 어려울 수 있음. |
| 성능 | 일반적으로 더 효율적이며, 특히 큰 데이터셋이나 복잡한 조건에서도 성능이 우수. | 작은 데이터셋이나 간단한 조건에서는 효율적. 하지만 중첩 쿼리가 많아지면 성능 저하 가능. |
| 예시 | 아래 참고 | 아래 참고 |
3) 조인 형식 예시
-- 조인: 두 테이블 연결
SELECT employees.name, departments.department_name
FROM employees
INNER JOIN departments
ON employees.department_id = departments.department_id;
-- 조인: 왼쪽 테이블의 모든 데이터 포함
SELECT products.product_name, orders.order_date
FROM products
LEFT JOIN orders
ON products.product_id = orders.product_id;4) 서브쿼리 형식 예시
-- 서브쿼리: 특정 조건을 만족하는 데이터를 추출
SELECT name
FROM employees
WHERE department_id = (
SELECT department_id
FROM departments
WHERE department_name = 'Sales'
);
-- 서브쿼리: 집계된 데이터를 조건으로 사용
SELECT product_id, product_name
FROM products
WHERE price > (
SELECT AVG(price)
FROM products
);5) 핵심 차이점 요약
-
사용 용도:
- 조인은 여러 테이블의 데이터를 결합하고, 테이블 간의 관계를 명확히 정의하는 데 유용.
- 서브쿼리는 특정 조건을 만족하는 데이터를 추출하거나 필터링에 적합.
-
성능:
- 조인이 일반적으로 더 빠르고 효율적.
- 서브쿼리는 직관적이지만 데이터 양이 많으면 비효율적일 수 있음.
-
가독성:
- 조인은 관계형 데이터를 다룰 때 명확성을 높여줌.
- 서브쿼리는 간단한 작업에서 더 읽기 쉽고 간단.
참고) join과 서브쿼리의 성능 차이의이유
이유: 내부 처리 방식의 차이
- JOIN: 데이터베이스는 JOIN을 할 때 두 테이블을 결합하며, 조인된 데이터를 한 번에 처리하도록 쿼리 최적화를 적용할 수 있다. 이를 통해 단일 스캔으로 결과를 가져올 수 있다.
- 서브쿼리: 서브쿼리는 외부 쿼리의 각 행에 대해 독립적으로 실행되므로, 각 행마다 서브쿼리를 처리하는 오버헤드가 발생. 특히 서브쿼리가
SELECT와 같은 필터링을 포함할 때, 반복적인 조회로 인해 성능이 느려질 수 있음.
⇒ JOIN을 기본으로 사용하고, 서브쿼리는 필요한 경우에만 활용하는 것이 좋다!!
1. 여러가지 요구 사항에 대한 SQL 쿼리 짜는 방법
이제 실제로 여러 시나리오를 살펴보면서 SQL문을 어떻게 짜는지 살펴보자.
시나리오 1
책의 좋아요 개수를 집계하는데, 내가 차단한 사용자의 좋아요는 집계하지 않는 경우
두 entity에 대한 ERD는 아래와 같다
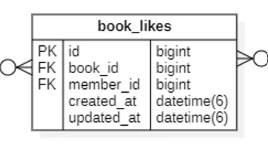
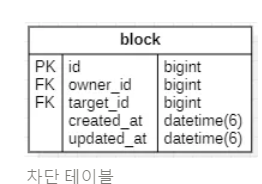
-- 책의 아이디가 3, 내 아이디가 2라고 가정
-- 1) subquery 사용해서 구현
select count(*) from book_like where book_id = 3
and user_id not in (select target_id from block where owner_id = 2);
-- 2) left join 사용해서 구현
select count(*)
from book_like as bl
left join block as b on bl.user_id = b.target_id and b.owner_id = 2
where bl.book_id = 3 and b.target_id is null;#참고사항 - in과 on의 차이
sql문을 처음 배우는 나는 등호(=) 사용 대신에 in, on 등을 사용하는 걸 보고 둘의 차이점이 궁금했다.
- in: 서브쿼리에서 여러 값이 나올 때 사용하는 연산자, 여러 값이나 서브쿼리에서 반환한 다중 결과와 비교가능 / not in 으로도 사용 가능
SELECT * FROM user WHERE user_id IN (1, 2, 3); -- 여러 값 중 하나에 일치하는 경우 SELECT * FROM user WHERE region_id IN (SELECT id FROM region WHERE name = 'Seoul'); -- 서브쿼리에서 반환된 값 중 일치 - on: JOIN 조건에서 두 테이블 간의 관계를 정의할 때 사용, 테이블을 결합할 때 특정 컬럼 값이 서로 일치하는지 확인하는 데 사용
SELECT u.username, r.name AS region_name FROM user AS u JOIN region AS r ON u.region_id = r.id; -- 두 테이블 간의 관계를 정의
시나리오 2 - n:m 관계 경우
해시태그를 통한 책의 검색인데, N : M 관계로 인해 가운데 매핑 테이블이 추가 된 경우
-- 서브쿼리
select * from book where id in
(select book_id from book_hash_tag
where hash_tag_id = (select id from hash_tag where name = 'mango' ));
-- join
select b.*
from book as b
inner join book_hash_tag as bht on b.id = bht.book_id
inner join hash_tag as ht on bht.hash_tag_id = ht.id -- join을 두 번 진행해야 돼
where ht.name = 'mango';시나리오 3 - 나열
- 최신 순 조회
select * from book order by created_at desc;내림차순으로 정렬해야 최신 것부터 조회된다.
- 좋아요 개수 순 조회
(해당 table에 likes 칼럼이 없는 상황)
select * from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
order by likes.like_count desc;2. 페이징(paging)
목록 조회를 시나리오3처럼 하게 되면 db의 모든 book 데이터를 다 가져오는 등의 쿼리를 하니까, 엄청난 렉이 걸려서 이에 대한 해결책이 필요하다!
=> paging 필요 - 페이징이란, Db에서 끊어서 데이터 보내도록 쿼리 보내는 것
paging의 종류
1. offset based 페이징
2. cursor based 페이징
1) Offset based 페이징

우리가 자주 보는 이런 목록이 오프셋 페이징이다.
1-1. Offset based 페이징 형식과 내용
- limit: 한 페이지에서 보여줄 데이터 개수
- offset으로 몇 개를 건너뛸지를 정함
-- 형식
select *
from book
order by likes desc
limit y offset(x - 1) * y; -- 보통 1페이지가 첫 페이지이기 때문에 1 빼줌
-- 예시: 2페이지이고 한 페이지에 10개씩 보여주는 경우(x=2, y=10)
select *
from book
order by likes desc
limit 10 offset 10;
-- 인기순 정렬
select * from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
order by likes.like_count desc
limit 15 offset (n - 1) * 15; -- 실제로는 n자리에 계산해서 넣어야 해1-2. Offset based 페이징 단점
- 페이지가 뒤로 갈수록 넘어가는 데이터가 많아져 성능 상의 이슈
- 사용자가 다음 페이지로 넘어갈 때, 게시글이 추가되면 전 페이지에서 보이던 게 다음 페이지에도 보이게 됨.
1-3. Offset based 페이징 형식 동적으로 구현하기
=> 변수 활용: 클라이언트 측에서 마지막 레코드의 커서 값(예: created_at이나 id)을 서버로 전송하고, 서버에서 이를 받아 SQL 쿼리의 조건으로 사용
-
SQL에서 변수를 사용하는 방법 (Prepared Statements 또는 Dynamic SQL)
대부분의 프로그래밍 언어에서 SQL 쿼리에 변수를 넣어 동적으로 커서 값을 적용 가능하다. Python, Node.js, Java 등과 같은 언어에서는 Prepared Statements를 사용하여 안전하게 변수를 SQL 쿼리에 삽입한다.예시 (Python에서 MySQL 쿼리 실행):
cursor_value와user_id값을 쿼리에 넣고, 동적으로 결과를 가져오기cursor_value = '2024-10-04 12:00:00' # 클라이언트로부터 받은 마지막 커서 값 sql = """ SELECT mission.restaurant_id FROM mission WHERE mission.created_at < AND mission.status = '진행중' AND mission.user_id = %s ORDER BY mission.created_at DESC LIMIT 5; """ cursor.execute(sql, (cursor_value, 3)) # 커서 값과 user_id 값을 쿼리에 동적으로 넣음 results = cursor.fetchall()
-
변수를 이용한 동적 SQL 쿼리 (MySQL 변수 사용)
MySQL에서 쿼리 안에 변수를 직접 사용하려면, MySQL 세션 변수 또는 프로시저 내에서 입력 매개변수를 활용예시 (MySQL 변수 사용):
@변수명형식으로 MySQL 내에서 변수를 정의하고, 이 변수를 SQL 쿼리 안에 넣음SET @cursor_value = '2024-10-04 12:00:00'; SET @user_id = 3; SELECT mission.restaurant_id FROM mission WHERE mission.created_at < **@cursor_value** AND mission.status = '진행중' AND mission.user_id = @user_id ORDER BY mission.created_at DESC LIMIT 5;
- 클라이언트-서버 구조에서 동적 커서 페이징 구현
일반적으로 커서 기반 페이징을 구현할 때는 클라이언트-서버 구조에서 다음과 같은 방식으로 동작:
1. 첫 번째 요청: 클라이언트가 서버에 페이지를 요청할 때는 커서 값이 없으므로, 서버는 기본 쿼리로 처음 5개의 레코드를 반환합니다.
2. 응답 데이터와 커서 값 반환: 서버는 응답할 때 마지막으로 반환한 레코드의 커서 값(예:created_at)을 함께 반환합니다.json { "data": [...], "next_cursor": "2024-10-04 12:00:00" }- 다음 페이지 요청 시 커서 값 전송: 클라이언트는 다음 페이지를 요청할 때
next_cursor값을 서버에 전달합니다. - 서버에서 커서 값으로 쿼리 실행: 서버는 이 커서 값을 받아, 동적으로 쿼리에 넣어 데이터를 가져옵니다.
- 다음 페이지 요청 시 커서 값 전송: 클라이언트는 다음 페이지를 요청할 때
2) Cursor based 페이징 - offset 페이징 보완책
앞서 말한 offset의 성능이나 여러 버그를 해결할 수 있는 또다른 페이징 방법입니다.
2-1. Cursor based 페이징 형식과 내용
cusor paing의 경우 이름에서 유추 할 수 있듯이 커서로 무언가를 가르켜 페이징을 하는 방법입니다.
여기서 커서는? 마지막으로 조회한 콘텐츠입니다.
마지막으로 조회한 대상 그 다음부터 가져와!
이렇게 생각하면 됩니다.
예시를 함께 봐봅시다.
-- 예시 1: 마지막으로 조회한 책의 아이디가 4인 경우
-- 원래대로 구현하면, 마지막으로 조회한 책의 아이디를 가져와서
select * from book where book.likes <
(select likes from book where id = 4)
order by likes desc limit 15;
-- 커서페이징으로 구현한 책 목록 조회 쿼리
select * from book where created_at <
(select created_at from book where id = 3)
order by created_at desc limit 15;
-- 커서페이징으로 구현한 인기순 목록 조회 쿼리
select * from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
where likes.like_count < (select count(*) from book_likes where book_id = 3)
order by likes.like_count desc limit 15;
2-2. 위의 인기순 정렬에서 생기는 문제점과 해결
🔥 예를 들어 좋아요가 0개인 게시글이 400개이고,
공교롭게 마지막으로 조회한 책의 좋아요가 0개라면,
그리고 아직 뒤에 조회를 하지 않은 책이 있다면
=> 다음 페이지에 책이 목록으로 조회가 되지 않음!
인기 순 정렬같이 같은 값이 있을 수 있는 경우, 정렬 기준이 하나 더 있어야 한다는 결론!!
해결코드
-- 좋아요 수가 같을 경우 PK값을 정렬 기준을 추가
select * from book as b
join (select count(*) as like_count
from book_likes
group by book_id) as likes on b.id = likes.book_id
where likes.like_count < (select count(*) from book_likes where book_id = 3)
order by likes.like_count desc, b.id desc limit 15;
-- 좋아요 갯수가 같은 book이 15개가 넘어가면 그 이상의 것은 무시가 됨
LPAD 함수를 이용한 해결 코드
SELECT b.*,
CONCAT(LPAD(likes.like_count, 10, '0'), LPAD(b.id, 10, '0')) AS cursor_value
FROM book AS b
JOIN (SELECT book_id, COUNT(*) AS like_count
FROM book_likes
GROUP BY book_id) AS likes ON b.id = likes.book_id
HAVING cursor_value < (SELECT CONCAT(LPAD(like_count_sub.like_count, 10, '0'), LPAD(like_count_sub.book_id, 10, '0'))
FROM (SELECT book_id, COUNT(*) AS like_count
FROM book_likes
GROUP BY book_id) AS like_count_sub
WHERE like_count_sub.book_id = 3) # 여기에 cursor_value 값이 들어가면 됨.
ORDER BY likes.like_count DESC, b.id DESC
LIMIT 15;
-- having 절 없이, where 절로 구현하면
SELECT b.*,
CONCAT(LPAD(likes.like_count, 10, '0'), LPAD(b.id, 10, '0')) AS cursor_value
FROM book AS b
JOIN (SELECT book_id, COUNT(*) AS like_count
FROM book_likes
GROUP BY book_id) AS likes ON b.id = likes.book_id
WHERE CONCAT(LPAD(likes.like_count, 10, '0'), LPAD(b.id, 10, '0')) <
(SELECT CONCAT(LPAD(like_count_sub.like_count, 10, '0'), LPAD(like_count_sub.book_id, 10, '0'))
FROM (SELECT book_id, COUNT(*) AS like_count
FROM book_likes
GROUP BY book_id) AS like_count_sub
WHERE like_count_sub.book_id = 3) # 여기에 cursor_value 값이 들어가면 됨.
ORDER BY likes.like_count DESC, b.id DESC
LIMIT 15;
- LPAD 함수란?: 문자열의 길이를 지정하고, 지정된 길이만큼 왼쪽을 특정 문자로 채워주는 함수
LPAD함수의 기본 사용법LPAD(문자열, 목표 길이, 채울 문자)-
문자열: 왼쪽을 채울 대상이 되는 문자열.
-
목표 길이: 최종적으로 만들어질 문자열의 전체 길이.
-
채울 문자: 목표 길이를 채우기 위해 문자열 왼쪽에 추가할 문자.
예를 들어,
LPAD('123', 5, '0')는 결과로'00123'을 반환
예제 쿼리
cursor_value생성: -
CONCAT(LPAD(likes.like_count, 10, '0'), LPAD(b.id, 10, '0'))를 사용하여cursor_value를 생성. -
like_count와book_id를 각각 10자리 숫자 문자열로 변환하고 결합하여 좋아요 수와 책 ID 기반의 고유한 정렬 기준을 만듦.페이징 조건:
-
HAVING cursor_value < (...)구문에서cursor_value를 기준으로 커서 페이징을 구현 -
서브쿼리에서
book_id = 3인 책의cursor_value를 가져와, 이 값을 기준으로 이전 책 목록을 15개까지 조회
-
3) Offset 페이징 vs Cursor based 페이징
그렇다면 커서 페이징이 어떻게 offset 페이징의 문제점을 극복하는지 서로를 비교하면서 봐보겠습니다.
1. 성능 문제 극복
Offset 페이징의 주요 문제는 페이지가 뒤로 갈수록 많은 데이터를 건너뛰기 위해 DB가 불필요한 계산을 수행해야 한다는 점입니다.
- Offset 방식:
OFFSET값만큼 데이터를 스캔한 후, 해당 범위를 제외하고 필요한 데이터를 반환. 페이지가 뒤로 갈수록 처리 시간이 증가. - Cursor 방식:
WHERE조건을 통해 필요한 데이터만 직접 조회하므로, 건너뛰는 데이터를 처리하지 않아 효율적.
예시: 100만 개의 데이터에서 1만 번째 페이지를 조회
- Offset 방식 쿼리:
SELECT * FROM book ORDER BY created_at DESC LIMIT 10 OFFSET 99990; -- 앞의 99990개를 건너뜀- 이 경우, DB는 99990개의 데이터를 스캔하고 버린 후 필요한 10개를 반환.
- Cursor 방식 쿼리:
SELECT * FROM book WHERE created_at < '2024-10-04 12:00:00' -- 마지막 커서 값 ORDER BY created_at DESC LIMIT 10;WHERE조건을 사용하여 필요한 데이터만 조회. 건너뛰는 데이터 스캔이 없으므로 성능이 훨씬 우수.
2. 데이터 중복 및 누락 문제 극복
Offset 방식은 데이터가 추가/삭제될 경우 페이지 간 데이터 중복이 발생할 가능성이 높습니다.
- 문제 상황:
사용자가 1페이지를 보고 2페이지로 넘어가는 사이에 새로운 데이터가 추가되면, 다음 페이지에서 이미 본 데이터가 다시 나타날 수 있음.
예시
-
Offset 방식:
- 1페이지 쿼리:
SELECT * FROM book ORDER BY created_at DESC LIMIT 10 OFFSET 0; -- 처음 10개 - 2페이지 쿼리:
SELECT * FROM book ORDER BY created_at DESC LIMIT 10 OFFSET 10; -- 다음 10개- 1페이지와 2페이지 사이에 새로운 데이터가 추가되면, 중복 데이터가 포함될 가능성이 높음.
- 1페이지 쿼리:
-
Cursor 방식:
- 1페이지 쿼리:
SELECT * FROM book ORDER BY created_at DESC LIMIT 10;- 마지막 커서 값:
created_at = '2024-10-04 12:00:00'.
- 마지막 커서 값:
- 2페이지 쿼리:
SELECT * FROM book WHERE created_at < '2024-10-04 12:00:00' -- 마지막 커서 기준 ORDER BY created_at DESC LIMIT 10;- 새 데이터가 추가되더라도 커서 값 이후의 데이터만 조회하므로 중복 발생 없음.
- 1페이지 쿼리:
3. 안정적인 정렬 보장
Cursor 페이징은 일반적으로 정렬 가능한 고유한 값(예: created_at, id)을 기반으로 데이터를 조회합니다.
- Offset 방식: 데이터 정렬 순서가 변경될 경우, 페이지 이동 시 정확한 데이터를 보장하기 어려움.
- Cursor 방식: 특정 정렬 기준(예:
created_at)을 유지하며 데이터를 조회하므로 일관성 있는 결과를 보장.
결론 : Offset 기반 페이징 vs Cursor 기반 페이징 비교 표
| 구분 | Offset 기반 페이징 | Cursor 기반 페이징 |
|---|---|---|
| 사용 방식 | OFFSET과 LIMIT을 사용하여 건너뛸 데이터와 조회할 데이터 개수를 지정. | WHERE 조건과 커서 값을 사용하여 필요한 데이터만 조회. |
| 성능 | 페이지가 뒤로 갈수록 건너뛰는 데이터가 많아져 성능 저하 발생. | 건너뛰는 데이터 없이 필요한 데이터만 조회하므로 성능 우수. |
| 데이터 중복 및 누락 | 데이터 추가/삭제 시 중복 데이터가 발생하거나 누락될 가능성이 있음. | 커서 값 기준으로 데이터를 조회하므로 중복 및 누락 없음. |
| 정렬 안정성 | 데이터가 정렬 기준에 따라 변경될 경우, 페이지 이동 시 정확한 데이터 보장이 어려움. | 커서 값으로 정렬 기준을 유지하며 안정적인 결과를 보장. |
| 구현 난이도 | 구현이 간단하며 대부분의 DB에서 지원. | 커서 값을 저장 및 관리해야 하므로 약간의 추가 구현이 필요. |
| 적합한 데이터 크기 | 소규모 데이터셋이나 정렬이 자주 변경되지 않는 데이터셋에 적합. | 대규모 데이터셋이나 실시간 동기화가 필요한 데이터셋에 적합. |
| 적용 시나리오 | 간단한 페이지네이션이 필요한 경우 (예: 상품 목록, 기본적인 데이터 리스트). | 대규모 소셜 피드, 실시간 채팅 로그, 검색 결과 페이지 등 성능과 데이터 정합성이 중요한 경우. |
| 쿼리 예시 | sql SELECT * FROM book ORDER BY created_at DESC LIMIT 10 OFFSET 30; | sql SELECT * FROM book WHERE created_at < '2024-10-04 12:00:00' ORDER BY created_at DESC LIMIT 10; |
| 장점 | - 구현이 간단하며 대부분의 언어와 DB에서 바로 사용 가능. | - 성능이 우수하고, 데이터 중복 및 누락 문제가 발생하지 않음. - 대규모 데이터셋에서 효율적. |
| 단점 | - 성능 저하 문제 발생 (특히 페이지가 뒤로 갈수록). - 데이터 추가/삭제 시 중복 문제. | - 구현이 약간 복잡하며, 커서 값을 저장/관리해야 함. - 정렬 기준이 고유해야 함. |
요약
- Offset 기반 페이징은 간단하고 빠르게 구현할 수 있지만, 대규모 데이터셋이나 실시간 데이터 동기화에는 적합하지 않음.
- Cursor 기반 페이징은 성능과 데이터 정합성을 보장하며, 대규모 데이터 처리 및 실시간 시스템에서 매우 효과적.
Tip: 선택은 데이터 크기, 성능 요구사항, 정렬 기준에 따라 결정해야 하며, 대규모 데이터 처리에서는 Cursor 기반 페이징이 권장됩니다.
오늘 배운 것 정리
- sql 기본 문법인 join과 subquery
- ERD 바탕으로 쿼리 짜는 법(데이터 가져오기, 목록 조회, ~순 나열)
- 페이징(오프셋, 커서)을 사용해서 목록을 조회하는 방법
수고하셨습니다~! 다음 포스팅에는 본격적으로 API에 대해 알아보겠습니다! 🤗
