보통 식별자의 고유 값을 보장하기 위한 방법으로 가장 UUID 혹은 snowflake를 활용한다.
저번에 ULID라는 개념을 들은적이 있어 정리한다.
등장 이유
UUID를 사용하게 되면 정렬 없이 무작위의 값을 생성해낸다.
그런 이유로 어떤 식별자가 먼저 만들어진건지는 알 수가 없다.
이를 해결하기 위한 대안으로 ULID가 등장한다.
ULID?
Universally Unique Lexicographically Sortable Identifier의 줄임말로
대소문자를 구별하지 않고 시간을 나타내는 26글자와 16글자의 임의의 값으로 구성된다.
번역하면 Lexicographically(사전적으로) Sortable(정렬가능한) Universally Unique Identifier(범용 고유 식별자).
Lexicographically는 보통 ascii 코드의 숫자를 기준으로 문자열의 크기를 비교할 수 있다는 점을 생각하면 되겠다.
ULID의 Monotonicity
이러한 개념에서 가장 큰 관심사는 충돌 가능성이다.
ULID는 최대 ms까지 감지하고, 동일한 ms가 감지되면 최하위 비트에서 1비트를 증가하는 방법인 monotonicity를 제공한다.
이때 Randomness에서 80bit를 제공하기 때문에 2^80 이라는 무작위성이 제공되어 매우 큰 수를 갖게 된다.
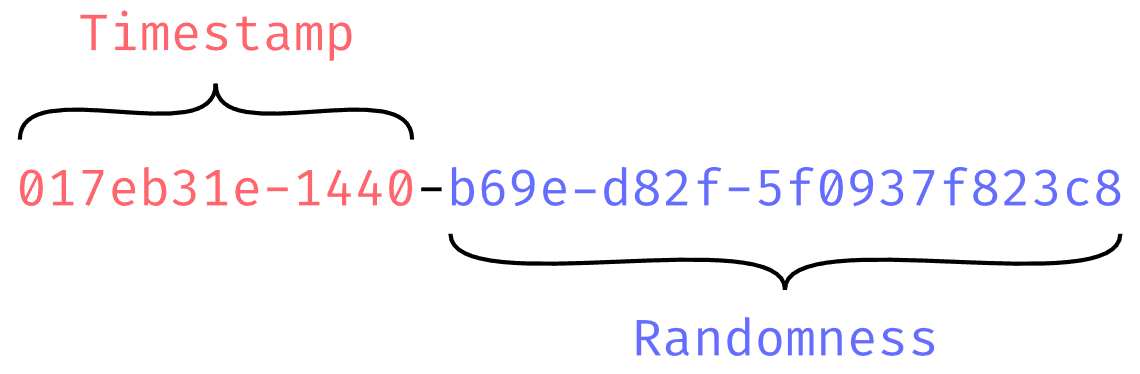
01EX8Y7M8MDVX3M3EQG69EEMJW
01EX8Y7M8MDVX3M3EQG69EEMJX
01EX8Y7M8MDVX3M3EQG69EEMJY
01EX8Y7M8MDVX3M3EQG69EEMJZ
01EX8Y7M8MDVX3M3EQG69EEMK0
01EX8Y7M8MDVX3M3EQG69EEMK1
01EX8Y7M8MDVX3M3EQG69EEMK2
01EX8Y7M8MDVX3M3EQG69EEMK3
01EX8Y7M8N1G30CYF2PJR23J2J < millisecond changed
01EX8Y7M8N1G30CYF2PJR23J2K
01EX8Y7M8N1G30CYF2PJR23J2M
01EX8Y7M8N1G30CYF2PJR23J2N
01EX8Y7M8N1G30CYF2PJR23J2P
01EX8Y7M8N1G30CYF2PJR23J2Q
01EX8Y7M8N1G30CYF2PJR23J2R
01EX8Y7M8N1G30CYF2PJR23J2S
^ look ^ look
|---------|--------------|
time randomms가 변경되면 time 쪽의 bit가 변경되고, ms가 같은 경우 초기에 생성된 난수를 1비트씩만 증가시키는 Monotonicity 옵션의 예시
Monotonicity 옵션을 활용하는 경우 오히려 무작위 ULID를 사용하는 것보다 충돌 가능성이 적다.
또한 밀리 초당 1000개의 이벤트를 처리한다고 가정한다면 향후 100년 동안 충돌할 확률이 0.000126%라고 한다.
