Intro
Google Colab에서 무료 이용자에게 gradio UI 사용을 내용으로 새로운 제한사항을 추가하였다. 따라서 Easy GUI 또한 이에 영향을 받아 유료 사용자가 아닌 이상 graio UI 기반으로 사용할 수 없게 되었다. 이 변동사항에 대응하여 colab에서 수동으로 코드를 직접 실행할 수 있게끔 하는 노트북을 추가하였다.
처음에는 당황했는데 오히려 UI 뒤에 가려져있던 전체 코드가 깔끔한 형식으로 공개되어 RVC 모델 공부에 도움이 되었다.
기존 EasyGUI
https://colab.research.google.com/drive/1r4IRL0UA7JEoZ0ZK8PKfMyTIBHKpyhcw#scrollTo=FFfC9x239kC1
Colab 기반으로 RVC 실행할 수 있게 해놓은 또다른 기여자
https://github.com/ardha27/AI-Song-Cover-RVC
00.Setup
- drive.mount는 찝찝하므로 주석처리하고
if not os.path.exists('/content/drive'): print("Your drive is not mounted. Creating Fake Drive.")
조건문 타고 들어가도록 처리 - 온갖 설치가 이뤄지는 단계. 엄청나게 긴 로그가 3분가량 줄줄 출력되다가 Success 버튼이 뿅 나타난다.
%cd /content
#from google.colab import drive
#drive.mount('/content/drive')
from IPython.display import clear_output
from ipywidgets import Button
import os
if not os.path.exists('/content/drive'):
print("Your drive is not mounted. Creating Fake Drive.")
os.makedirs('/content/drive/MyDrive')
if not os.path.exists('/content/drive/MyDrive/project-main'):
!wget https://huggingface.co/Rejekts/project/resolve/main/project-main.zip -O '/content/project-main.zip' && unzip 'project-main.zip' -d /content/drive/MyDrive
!cd '/content/drive/MyDrive/project-main' && python download_files.py && pip install -r 'requirements-safe.txt'
!rm /content/project-main.zip
!rm -r /content/sample_data
!mkdir -p /content/dataset
clear_output()
Button(description="\u2714 Success", button_style="success")01.Preprocess Data
- model_name 입력해준다
- /content/dataset/ 에 학습용 데이터 업로드한다
/content/drive/MyDrive/project-main Starting...로그 한줄 뜨고 동일하게 Success 버튼 뿅 나타난다
%cd /content/drive/MyDrive/project-main
model_name = 'My-Voice' #@param {type:"string"}
#@markdown <small> Enter the path to your dataset, or if you want just upload the audios using the File Manager into the 'dataset' folder.
dataset_folder = '/content/dataset' #@param {type:"string"}
while len(os.listdir(dataset_folder)) < 1:
input("Your dataset folder is empty.")
!mkdir -p ./logs/{model_name}
with open(f'./logs/{model_name}/preprocess.log','w') as f:
print("Starting...")
!python infer/modules/train/preprocess.py {dataset_folder} 40000 2 ./logs/{model_name} False 3.0 > /dev/null 2>&1
with open(f'./logs/{model_name}/preprocess.log','r') as f:
if 'end preprocess' in f.read():
clear_output()
display(Button(description="\u2714 Success", button_style="success"))
else:
print("Error preprocessing data... Make sure your dataset folder is correct.")
2.Extract Features
"pm", "harvest", "rmvpe", "rmvpe_gpu"중에서 하나 선택- 동일하게 Success 버튼 뿅 나타난다
f0method = "rmvpe_gpu" # @param ["pm", "harvest", "rmvpe", "rmvpe_gpu"]
%cd /content/drive/MyDrive/project-main
with open(f'./logs/{model_name}/extract_f0_feature.log','w') as f:
print("Starting...")
if f0method != "rmvpe_gpu":
!python infer/modules/train/extract/extract_f0_print.py ./logs/{model_name} 2 {f0method}
else:
!python infer/modules/train/extract/extract_f0_rmvpe.py 1 0 0 ./logs/{model_name} True
!python infer/modules/train/extract_feature_print.py cuda:0 1 0 0 ./logs/{model_name} v2
with open(f'./logs/{model_name}/extract_f0_feature.log','r') as f:
if 'all-feature-done' in f.read():
clear_output()
display(Button(description="\u2714 Success", button_style="success"))
else:
print("Error preprocessing data... Make sure your data was preprocessed.")03.Train Index
-
동일하게 Success 버튼 뿅 나타난다
import numpy as np import faiss %cd /content/drive/MyDrive/project-main def train_index(exp_dir1, version19): exp_dir = "logs/%s" % (exp_dir1) os.makedirs(exp_dir, exist_ok=True) feature_dir = ( "%s/3_feature256" % (exp_dir) if version19 == "v1" else "%s/3_feature768" % (exp_dir) ) if not os.path.exists(feature_dir): return "请先进行特征提取!" listdir_res = list(os.listdir(feature_dir)) if len(listdir_res) == 0: return "请先进行特征提取!" infos = [] npys = [] for name in sorted(listdir_res): phone = np.load("%s/%s" % (feature_dir, name)) npys.append(phone) big_npy = np.concatenate(npys, 0) big_npy_idx = np.arange(big_npy.shape[0]) np.random.shuffle(big_npy_idx) big_npy = big_npy[big_npy_idx] if big_npy.shape[0] > 2e5: infos.append("Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0]) yield "\n".join(infos) try: big_npy = ( MiniBatchKMeans( n_clusters=10000, verbose=True, batch_size=256 * config.n_cpu, compute_labels=False, init="random", ) .fit(big_npy) .cluster_centers_ ) except: info = traceback.format_exc() logger.info(info) infos.append(info) yield "\n".join(infos) np.save("%s/total_fea.npy" % exp_dir, big_npy) n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39) infos.append("%s,%s" % (big_npy.shape, n_ivf)) yield "\n".join(infos) index = faiss.index_factory(256 if version19 == "v1" else 768, "IVF%s,Flat" % n_ivf) infos.append("training") yield "\n".join(infos) index_ivf = faiss.extract_index_ivf(index) # index_ivf.nprobe = 1 index.train(big_npy) faiss.write_index( index, "%s/trained_IVF%s_Flat_nprobe_%s_%s_%s.index" % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19), ) infos.append("adding") yield "\n".join(infos) batch_size_add = 8192 for i in range(0, big_npy.shape[0], batch_size_add): index.add(big_npy[i : i + batch_size_add]) faiss.write_index( index, "%s/added_IVF%s_Flat_nprobe_%s_%s_%s.index" % (exp_dir, n_ivf, index_ivf.nprobe, exp_dir1, version19), ) infos.append( "成功构建索引,added_IVF%s_Flat_nprobe_%s_%s_%s.index" % (n_ivf, index_ivf.nprobe, exp_dir1, version19) ) training_log = train_index(model_name, 'v2') for line in training_log: print(line) if 'adding' in line: clear_output() display(Button(description="\u2714 Success", button_style="success")) ```
04. Train Model
- 맨처음 입력했던 것과 동일한 model_name 입력
- 아래처럼 epoch 로그 출력되면 Train 시작된 것
INFO:yuri:Train Epoch: 1 [0%] INFO:yuri:[0, 0.0001] INFO:yuri:loss_disc=4.686, loss_gen=2.666, loss_fm=14.291,loss_mel=40.714, loss_kl=9.000 INFO:yuri:====> Epoch: 1 [2023-09-20 12:36:45] | (0:00:34.700875) INFO:yuri:====> Epoch: 2 [2023-09-20 12:36:50] | (0:00:05.268260)
%cd /content/drive/MyDrive/project-main
from random import shuffle
import json
import os
import pathlib
from subprocess import Popen, PIPE, STDOUT
now_dir=os.getcwd()
#@markdown <small> Enter the name of your model again. It must be the same you chose before.
model_name = ''#@param {type:"string"}
#@markdown <small> Choose how often to save the model and how much training you want it to have.
save_frequency = 25 # @param {type:"slider", min:5, max:50, step:5}
epochs = 200 # @param {type:"slider", min:10, max:1000, step:10}
#@markdown <small> ONLY cache datasets under 10 minutes long. Otherwise leave this unchecked.
cache = False #@param {type:"boolean"}
# Remove the logging setup
def click_train(
exp_dir1,
sr2,
if_f0_3,
spk_id5,
save_epoch10,
total_epoch11,
batch_size12,
if_save_latest13,
pretrained_G14,
pretrained_D15,
gpus16,
if_cache_gpu17,
if_save_every_weights18,
version19,
):
# 生成filelist
exp_dir = "%s/logs/%s" % (now_dir, exp_dir1)
os.makedirs(exp_dir, exist_ok=True)
gt_wavs_dir = "%s/0_gt_wavs" % (exp_dir)
feature_dir = (
"%s/3_feature256" % (exp_dir)
if version19 == "v1"
else "%s/3_feature768" % (exp_dir)
)
if if_f0_3:
f0_dir = "%s/2a_f0" % (exp_dir)
f0nsf_dir = "%s/2b-f0nsf" % (exp_dir)
names = (
set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)])
& set([name.split(".")[0] for name in os.listdir(feature_dir)])
& set([name.split(".")[0] for name in os.listdir(f0_dir)])
& set([name.split(".")[0] for name in os.listdir(f0nsf_dir)])
)
else:
names = set([name.split(".")[0] for name in os.listdir(gt_wavs_dir)]) & set(
[name.split(".")[0] for name in os.listdir(feature_dir)]
)
opt = []
for name in names:
if if_f0_3:
opt.append(
"%s/%s.wav|%s/%s.npy|%s/%s.wav.npy|%s/%s.wav.npy|%s"
% (
gt_wavs_dir.replace("\\", "\\\\"),
name,
feature_dir.replace("\\", "\\\\"),
name,
f0_dir.replace("\\", "\\\\"),
name,
f0nsf_dir.replace("\\", "\\\\"),
name,
spk_id5,
)
)
else:
opt.append(
"%s/%s.wav|%s/%s.npy|%s"
% (
gt_wavs_dir.replace("\\", "\\\\"),
name,
feature_dir.replace("\\", "\\\\"),
name,
spk_id5,
)
)
fea_dim = 256 if version19 == "v1" else 768
if if_f0_3:
for _ in range(2):
opt.append(
"%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s/logs/mute/2a_f0/mute.wav.npy|%s/logs/mute/2b-f0nsf/mute.wav.npy|%s"
% (now_dir, sr2, now_dir, fea_dim, now_dir, now_dir, spk_id5)
)
else:
for _ in range(2):
opt.append(
"%s/logs/mute/0_gt_wavs/mute%s.wav|%s/logs/mute/3_feature%s/mute.npy|%s"
% (now_dir, sr2, now_dir, fea_dim, spk_id5)
)
shuffle(opt)
with open("%s/filelist.txt" % exp_dir, "w") as f:
f.write("\n".join(opt))
# Replace logger.debug, logger.info with print statements
print("Write filelist done")
print("Use gpus:", str(gpus16))
if pretrained_G14 == "":
print("No pretrained Generator")
if pretrained_D15 == "":
print("No pretrained Discriminator")
if version19 == "v1" or sr2 == "40k":
config_path = "configs/v1/%s.json" % sr2
else:
config_path = "configs/v2/%s.json" % sr2
config_save_path = os.path.join(exp_dir, "config.json")
if not pathlib.Path(config_save_path).exists():
with open(config_save_path, "w", encoding="utf-8") as f:
with open(config_path, "r") as config_file:
config_data = json.load(config_file)
json.dump(
config_data,
f,
ensure_ascii=False,
indent=4,
sort_keys=True,
)
f.write("\n")
cmd = (
'python infer/modules/train/train.py -e "%s" -sr %s -f0 %s -bs %s -g %s -te %s -se %s %s %s -l %s -c %s -sw %s -v %s'
% (
exp_dir1,
sr2,
1 if if_f0_3 else 0,
batch_size12,
gpus16,
total_epoch11,
save_epoch10,
"-pg %s" % pretrained_G14 if pretrained_G14 != "" else "",
"-pd %s" % pretrained_D15 if pretrained_D15 != "" else "",
1 if if_save_latest13 == True else 0,
1 if if_cache_gpu17 == True else 0,
1 if if_save_every_weights18 == True else 0,
version19,
)
)
# Use PIPE to capture the output and error streams
p = Popen(cmd, shell=True, cwd=now_dir, stdout=PIPE, stderr=STDOUT, bufsize=1, universal_newlines=True)
# Print the command's output as it runs
for line in p.stdout:
print(line.strip())
# Wait for the process to finish
p.wait()
return "训练结束, 您可查看控制台训练日志或实验文件夹下的train.log"
%load_ext tensorboard
%tensorboard --logdir ./logs
training_log = click_train(
model_name,
'40k',
True,
0,
save_frequency,
epochs,
7,
True,
'assets/pretrained_v2/f0G40k.pth',
'assets/pretrained_v2/f0D40k.pth',
0,
cache,
True,
'v2',
)
print(training_log)Train 진행 로그
정상적으로 진행중
epoch 100 번째
INFO:yuri:loss_disc=3.579, loss_gen=3.896, loss_fm=14.513,loss_mel=21.135, loss_kl=0.846
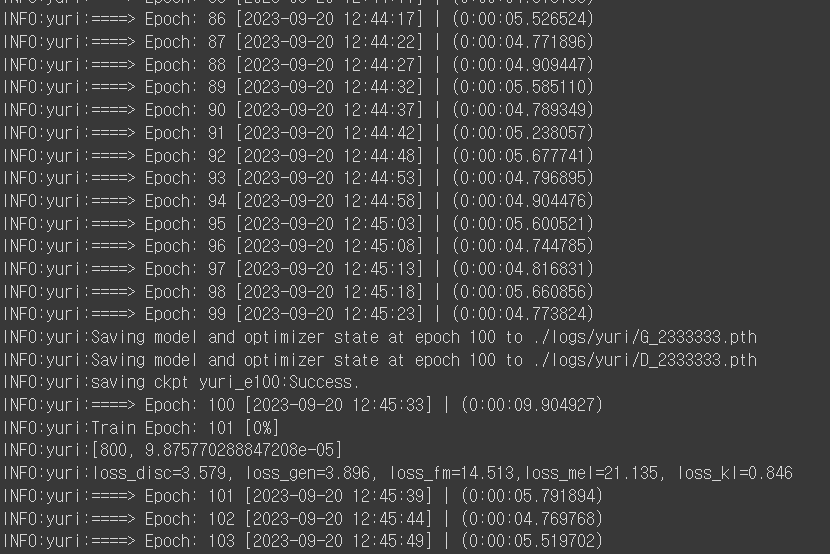
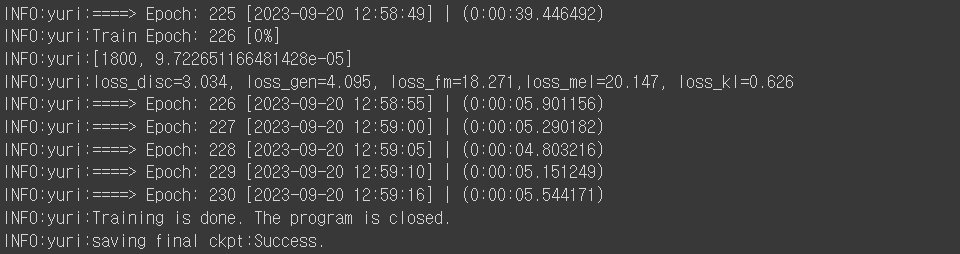
epoch 230번째. 학습 종료
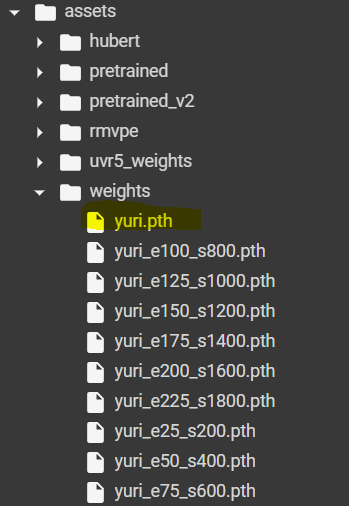
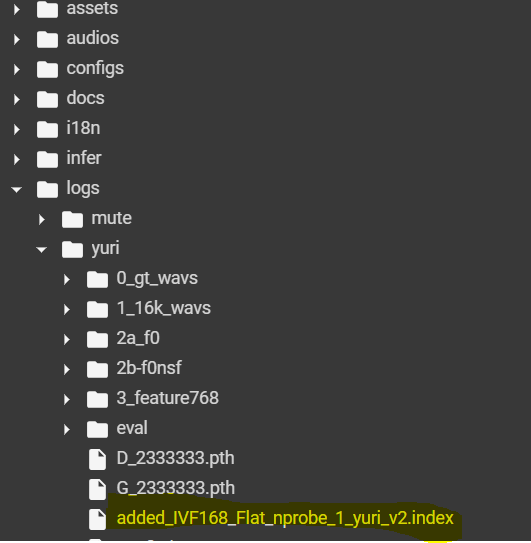
.pth 파일와 .index 파일 생성

설명을 할거면 제대로 하지