질문_붓꽃분류_9월 28일
1
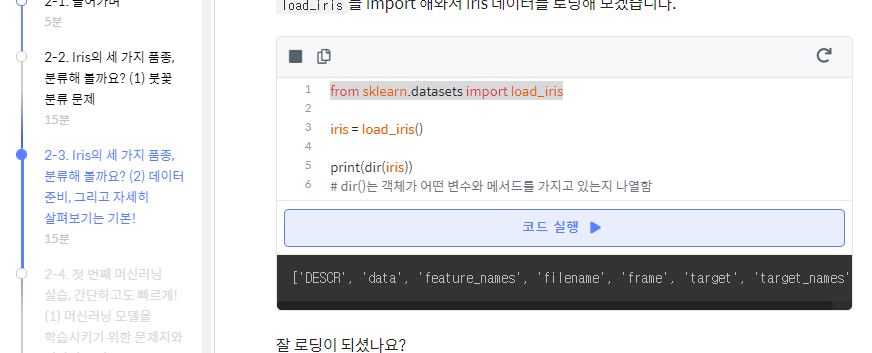
ex1 에서, 이렇게 확인하는건 뭐였지?
keys() 메서드 : iris에 어떤 정보 담겼나 확인 <- 이걸로 한것 같아
그럼 dir(), keys() 둘다 같은 결과 인것 같은딩... 각각 언제 쓰냐?
2
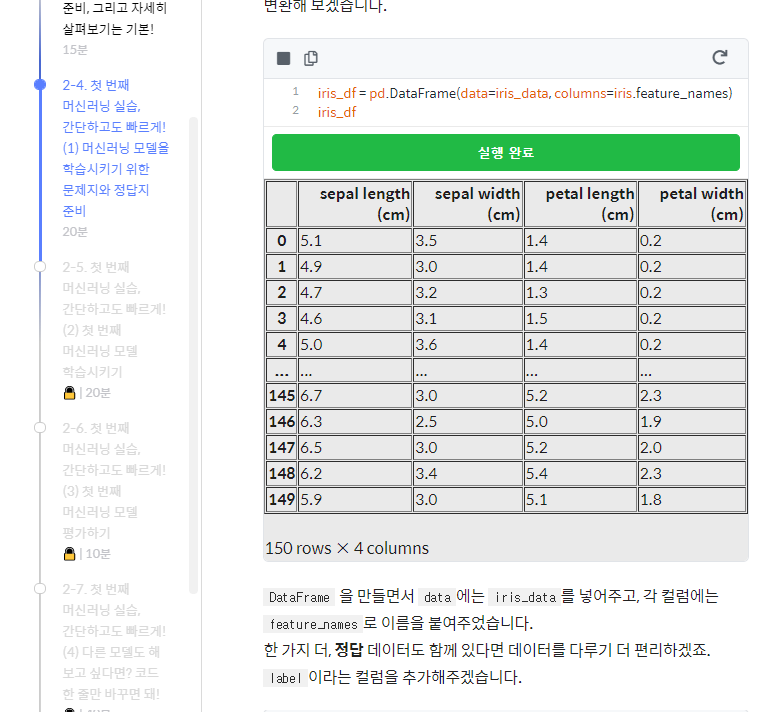
데이터 프레임이 뭔가?
아마 이렇게 잘 보여주는게 데이터 프레임이였던거 같아
코드형식으로 행렬나오는게 아니라 !
맞즤~?
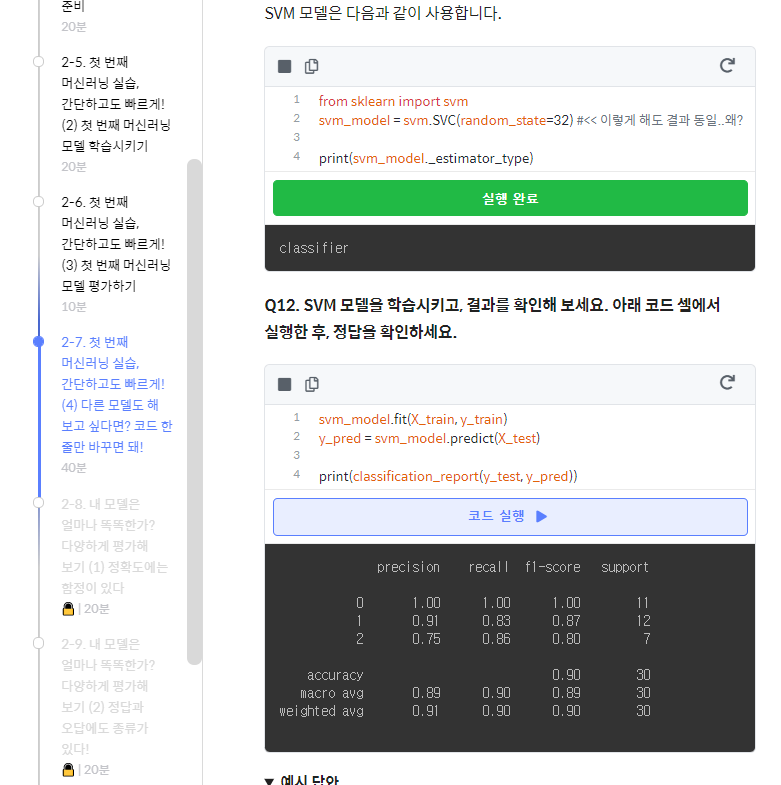
질문은 아니고 랜덤 seed에 관한 이야기
마지막으로 쓰인 random_state는 train데이터와 test데이터를 분리(split)하는데 적용되는 랜덤성을 결정합니다. 위에서 데이터를 출력했을때 라벨이 0부터 순서대로 정렬된 것을 보셨을 겁니다.
만약 이 데이터 그대로 학습용 데이터와 테스트용 데이터를 나눈다면 뒤쪽의 20%가 테스트용 데이터셋으로 만들어지기 때문에 테스트용 데이터셋은 라벨이 2인 데이터로만 구성됩니다.
이런 데이터셋을 테스트용으로 사용한다면 학습이 제대로 되었는지 확인할수가 없겠죠? 그래서 데이터를 분리할 때 랜덤으로 섞는 과정이 필요하고 random_state가 이 역할을 하게되는 것이죠.
컴퓨터에서의 랜덤은 아무리 랜덤이라고 해도 특정 로직에 따라 결정되는 랜덤이기 때문에 완벽한 랜덤이라고 할 수 없습니다.
그러한 랜덤을 조절할 수 있는 값이 바로 random_state, 또는 random_seed입니다. 이 값이 같다면 코드는 항상 같은 랜덤 결과를 나타냅니다.
랜덤인데 왜 같은 결과를 원하냐구요? 내가 실험한 결과를 다른 사람의 컴퓨터에서도 재현가능(reproducible) 하게 하려면 같은 랜덤시드가 필요할 때가 있답니다.
랜덤성을 조절하고 싶지 않다면, 해당 인자는 없어도 코드상의 문제는 없습니다.
3
4
SGD Classifier
5
랜덤하게 뽑는 것도 알고리즘인데, 랜덤하게 뽑지가 않아짐,,, ? > 완전 랜덤이 아닌걸 이용하는 것 같음
랜덤 시드가 같으면 같은 결과가 나옴 -> 왜?
랜덤 시드를 그럼 초기에 결정하는 기준은? -> 없엉 ㅋㅋㅋㅋㅋ
컴퓨터 프로그램에서 발생하는 무작위 수는 사실 엄격한 의미의 무작위 수가 아니다.
어떤 특정한 시작 숫자를 정해 주면 컴퓨터가 정해진 알고리즘에 의해 마치 난수처럼 보이는 수열을 생성한다. 이런 시작 숫자를 시드(seed)라고 한다. 일단 생성된 난수는 다음번 난수 생성을 위한 시드값이 된다. 따라서 시드값은 한 번만 정해주면 된다. 시드는 보통 현재 시각등을 이용하여 자동으로 정해지지만 사람이 수동으로 설정할 수도 있다. 특정한 시드값이 사용되면 그 다음에 만들어지는 난수들은 모두 예측할 수 있다. 이 책에서는 코드의 결과를 재현하기 위해 항상 시드를 설정한다
6
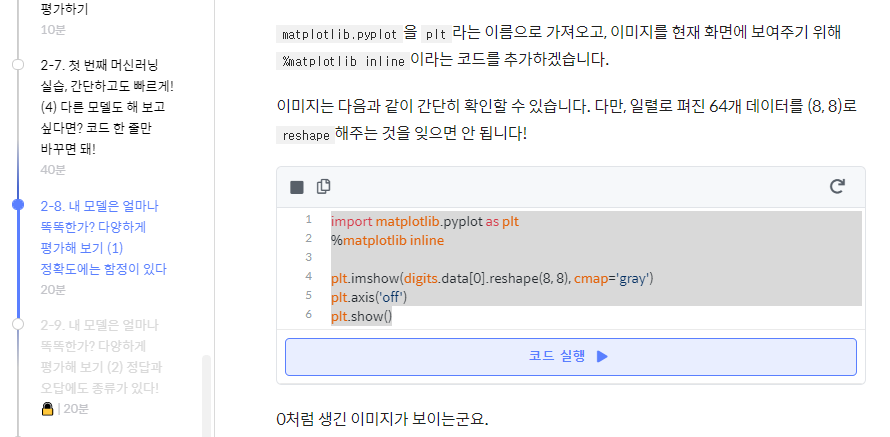
axis off는 무슨의미지?
7
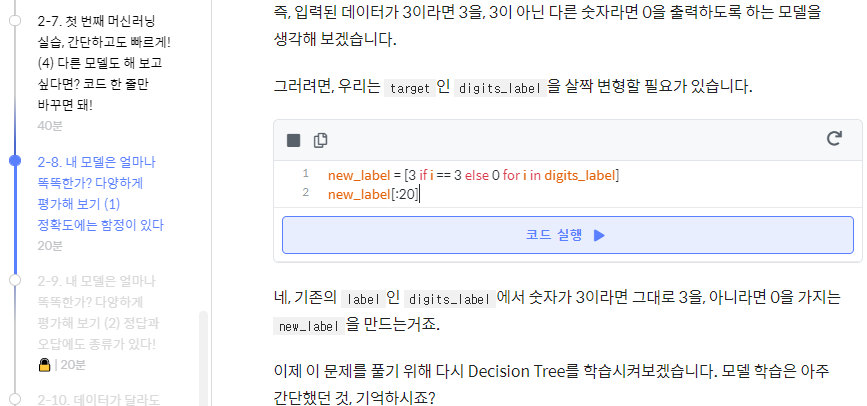
for구문이 앞에오고, 그담에 if 아냐?
8 프로젝트질문
그리고 질문이 있는데 정확도랑 오차행렬이랑 둘 값을 비교해서
- 모델간 각 수치 비교해서
제일 적절한 모델을 찾는거죠..?
근데 어떻게 값이 나와야 좋은건지 모르겠어서..
0이라고 딱 안좋은거면 아 안좋네 ! 싶겠는데
좋게 나오면, 뭔가 이상해서 좋게나왔나 싶고
안좋게 나오면 그냥 안좋은.. 모델과 성능 평가 척도 같구 ㅠㅠ
펀더멘털 12
1
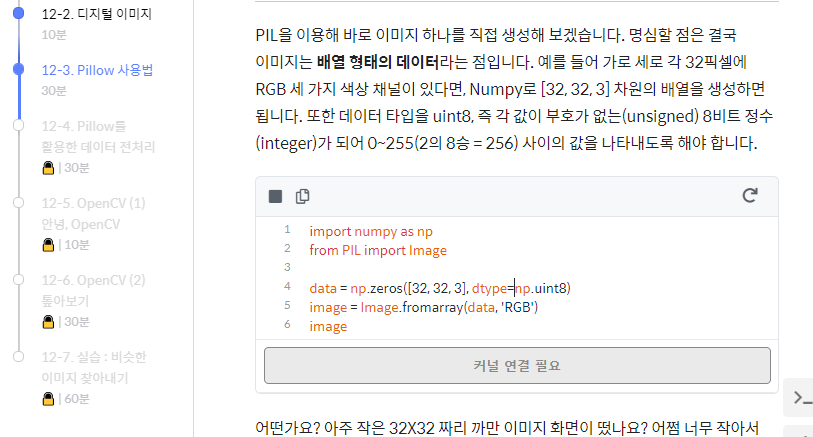
formarray 함수 공부
formarray 함수 : NumPy 배열을 PIL 이미지로 변환하는 방법
2
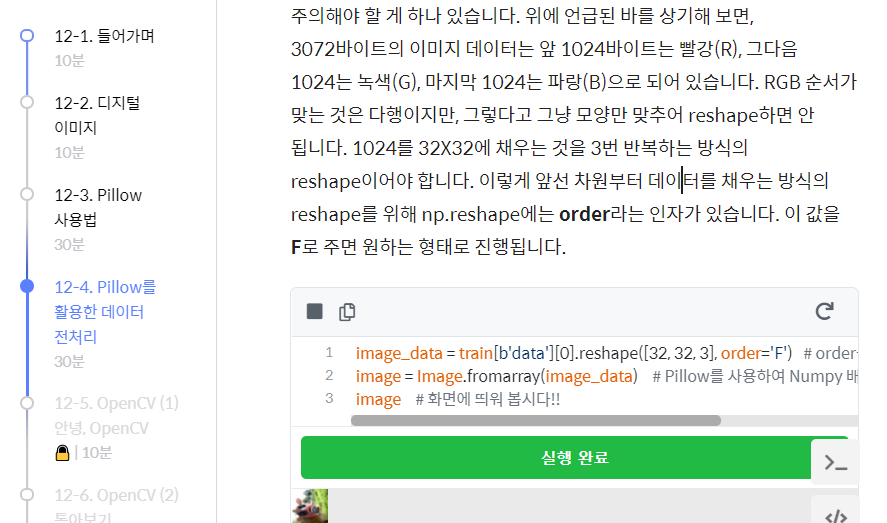
1) 여기서 rgb 순서 맞게 된건 어떻게 아랑?
2) 3번 반복하는 방식 아니면 어케 되는데?
3) 코드에서 pillow가 사용된건 어느 부분이지
<<< order = f, c 넣어서 하는건데
열로 들어가는걸 행으로 들어가게 해줘야해서 order로 하기
3
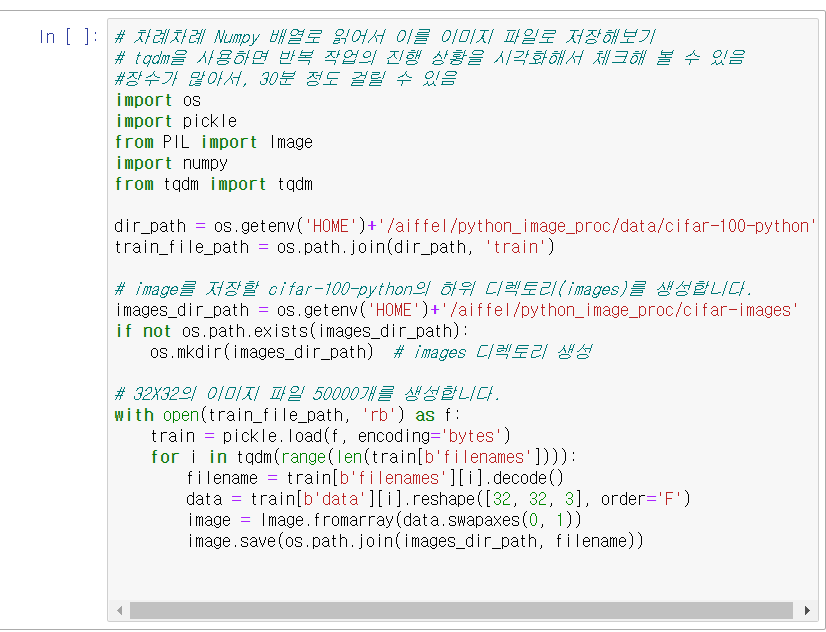
decode 뭐징?? 여기 코드 좀 뜯어서 다시 공부해야할것 같아
4
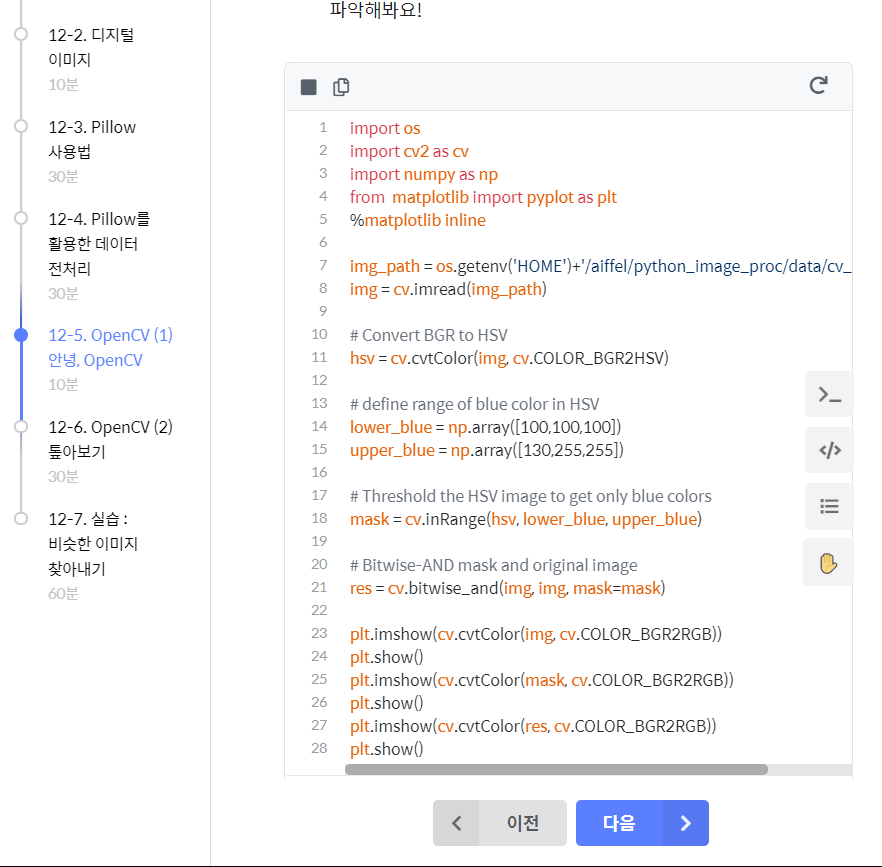
1) cv.cvtColor?
2)mask = cv.inRange?
5
[픽셀, 픽셀, rgb][r, g, b]
인데 해당행렬 어 케 ...
어디서 어떻게 넣고 빼오고 그러즤..?
6

근데 왜 lower가 110이 아니라 100이지?
HSV 색 공간에서 색상(Hue) 값 110~130 사이, 채도(Saturation) 및 명도(Value) 값 50~255 사이의 색들을 파란색이라고 정의 -> [색상hue, 채도, 명도] 이렇게 배열 되는것 맞나?
각각 픽셀 당 BGR, HSV 세 개의 색상 채널별 값을 가질 테기 때문에,
-> 여기도 이해안감
HVS 100까지 밖에 안되어있어서 어떻게 할래..?!!
