Historical Review
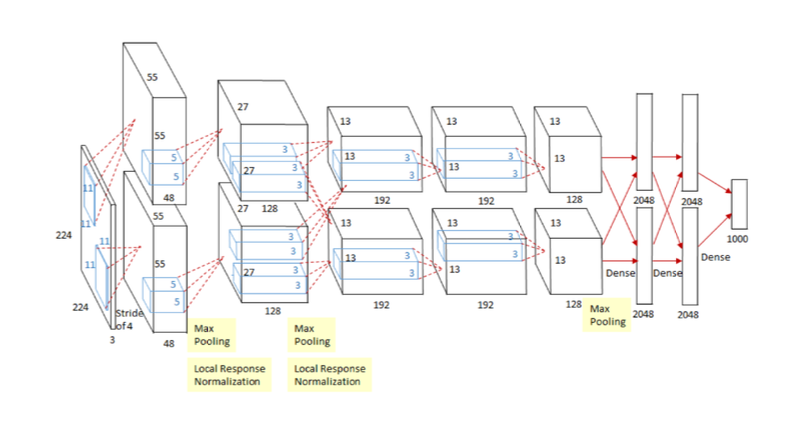
2012 AlexNet
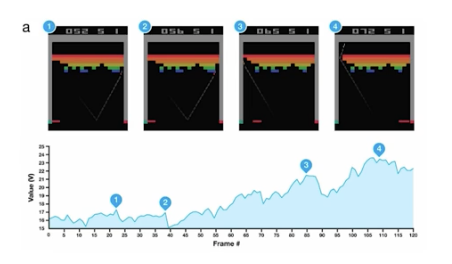
2013 DQN
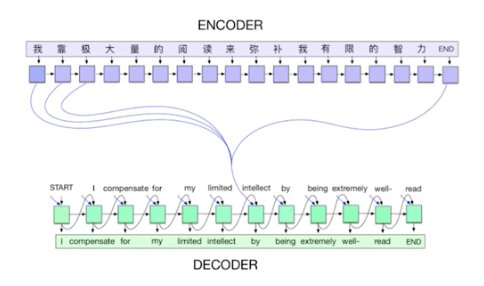
2014 Encoder/Decoder, Adam
2015 GAN, ResNet
2016
2017 Transformer
2018 Bert
2019 Big Launguage Models (GPT-X)
2020 Self-Supervised Learning
2012 AlexNet
ImageNet 우승
2013 DQN
알파고
강화학습
딥마인드
2014 Encoder/Decoder
Neural Machine Translation
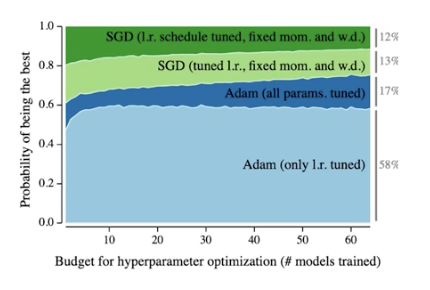
2014 Adam Optimizer
2015 GAN Geenerative Adversarial Network

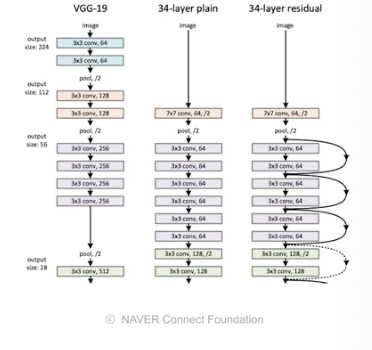
2015 Residual Networks
why deep learning? 네트워크를 깊게 쌓기 때문
이전에 layer를 깊게 쌓아서 생긴 문제를 개선
2017 Transformer
Attention Is All You Need

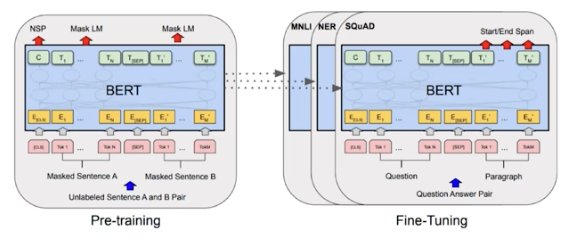
2018 BERT
fine-tuned NLP models
Bidirectional Encoder Representations from Transformers
2019 BIG Launguage Models
GPT-3, an autoregressive language model with 175 billion parameters

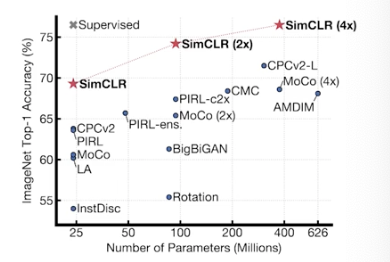
2020 Self Supervised Learning
SimCLR
a simple framework for contrastive learnign of visual representation
주어진 학습 데이터 외에 라벨을 모르는 unsupervised data 함께 사용