Web API 배우기
1. JSON (JavaScript Object Notation)

fetch("https://jsonplaceholder.typicode.com/users')
.then((response) => response.text())
.then((result) => { console.log(result); });정보를 교환할 때 사용하기 위한 데이터 포맷으로 JavaScript 문법을 빌려서 만들어진 데이터 포맷이다. 대괄호([])를 통해 객체들을 요소로 담고, 여러 프로퍼티와 값들을 중괄호{{})를 통해 담고 있는 모습이 JavaScript와 비슷하다.
1-1. 자바스크립트 객체 표기법과 JSON 문법의 차이
1. JSON에는 프로퍼티의 이름과 값을 표현하는 방식에 제한이 있다.
(1) JSON에서는 각 프로퍼티의 이름을 반드시 큰따움표("")로 감싸줘야 한다.
// JavaScript (Object Literal)
const member = {
name: 'Michael Kim',
height: 180,
weight: 70,
hobbies: ['Basketball', 'Listening to music']
};{
"name":"Michael Kim",
"height":180,
"weight":70,
"hobbies":["Basketball", "Listening to music"]
}(2) JSON에서는 값이 문자열인 경우 큰따움표("")를 사용해야 한다.
위 JavaScript 코드에서는 문자열 값에 작은따움표('')를 사용해서 감쌌지만, JSON에서는 문자열 값에 무조건 큰따움표("")를 사용해야 한다.
2. JSON에서는 표현할 수 없는 값들이 있다.
JSON에서는 프로퍼티 값으로 undefined, NaN, Infinity 등을 사용할 수 없다. JSON이 비록 JavaScript부터 비롯된 데이터 포맷이지만, 탄생 목적은 언어나 환경에 종속되지 않고, 언제 어디서든 사용할 수 있는 데이터 포맷이 되는 것이니 어찌보면 당연한 결과이다.
3. JSON에는 주석을 추가할 수 없다.
2. JSON 데이터를 객체로 변환하기
fetch("https://jsonplaceholder.typicode.com/users")
.then((response) => response.text())
.then((result) => {
const users = JSON.parse(result); // JSON -> JS
console.log(users.length); // 배열 길이 출력, 10
users.forEach((user) => { // 배열의 각 요소를 파라미터로 받은 함수를 실행
console.log(user.name) // name 출력
});
});JSON 객체에 parse 메소드를 사용하면 string 타입의 JSON 데이터를 자바스크립트 객체로 표현할 수 있게 된다. 즉, 자바스크립트 배열 형태로 변환한다.
3. 메소드의 의미

결국 각각의 메소드에 대해서 서버는 그에 맞는 데이터 관련 조작을 하게 된다. 만약 서버가 데이터베이스를 사용한다면 CRUD 작업을 하게 된다. CRUD란 Create-Read-Update-Delete의 약자로 데이터베이스 관점에서 데이터에 관한 처리를 나타내는 합성어이다.
| 메소드 | 데이터 처리 |
|---|---|
| GET | READ |
| POST | CREATE |
| PUT | UPDATE |
| DELETE | DELTETE |
4. Request의 Head와 Body
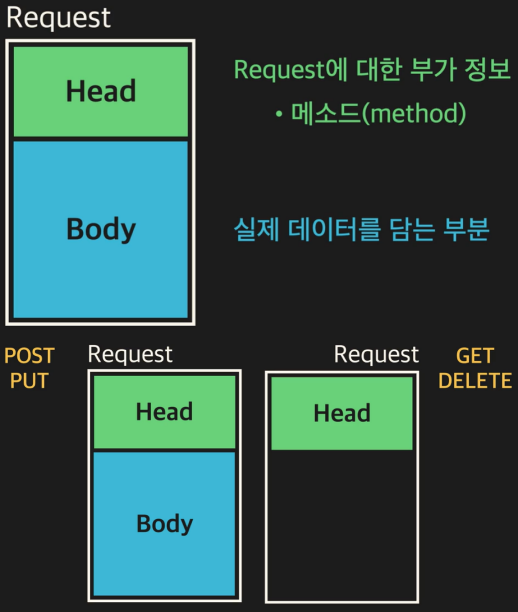
GET과 DELETE의 경우에는 단순히 request를 조회하고 삭제하기 때문에 Body가 존재하지 않는다.
이제 웹 브라우저가 서버로 보내는 request의 종류에는 4가지가 있다는 것을 배웠다.
- 기존 데이터를 조회하는 request -
GET - 새 데이터를 추가하는 request -
POST - 기존 데이터를 수정하는 request -
PUT - 기존 데이터를 삭제하는 request -
DELETE
(1) 전체 직원 정보 조회 - GET
(2) 특정 직원 정보 조회 - GET
(3) 새 직원 정보 추가 - POST
(4) 기존 직원 정보 수정 - PUT
(5) 기존 직원 정보 삭제 - DELETE
이러한 5가지 작업을 수행할 때 URL의 유형에는 크게 2가지가 있다.
(2), (4), (5) 작업들을 수행할 때는 작업의 대상이 되는 직원 정보를 특정할 수 있도록 URL 끝에 고유 식별자를 붙여줘야 한다. (직원의 id값)
(https://learn.codeit.kr/api/members/3)
위의 URL은 3번 직원 정보에 대한 작업을 수행하겠다는 의미이다. 이렇게 작업의 종류에 따라 메소드뿐만 아니라 URL도 적절하게 변경해가며 써줘야 한다.
(1), (3) 작업들은 특정 직원 정보를 대상으로 수행하는 작업이 아니라 전체 직원 정보에 대해서 수행하는 작업이기 때문에 그대로 URL을 사용해도 된다.
5. POST request 보내기
// 기본
fetch("https://learn.codeit.kr/api/members")
.then((response) => response.text())
.then((result) => { console.log(result); });
// 직원 추가
const newMemeber = {
name: 'Jerry',
email: 'jerry@cracked.kr',
department: 'enginerring',
};
fetch("https://learn.codeit.kr/api/members", {
// 옵션 객체
method: 'POST', // Get request가 디폴트 값이다.
body: JSON.stringify(newMember), // JS -> JSON
})
.then((response) => response.text())
.then((result) => { console.log(result); });stringify 메소드는 parse 메소드와 정반대의 기능을 수행한다. JavaScript 객체를 string 타입의 JSON 데이터로 변환한다. (개발자 도구를 통해 볼 수 있듯이 'Request Payload'가 body에 해당하는 부분이다.)
6. PUT request, DELETE request 보내기
// PUT request (부서 바꾸기)
const member = {
name: 'Alice',
email: 'alice@codeitmall.kr',
department: 'marketing',
};
fetch("https://learn.codeit.kr/api/members/2", {
method: 'PUT',
body: JSON.stringify(member),
})
.then((response) => response.text())
.then((result) => { console.log(result); });
// DELETE request
fetch("https://learn.codeit.kr/api/members/2", {
method: 'DELETE',
})
.then((response) => response.text())
.then((result) => { console.log(result); });7. 모범적인 Web API, REST API
(1) Web API
어떤 reqest를 보냈을 때, 무슨 response를 받는지는 모두 그 서비스를 만드는 개발자들이 정하는 부분이다. 개발자는 크게 프론트엔드(Front-end) 개발자와 백엔드(Back-end) 개발자로 나뉘는 것을 알고 있을 것이다.
하나의 서비스를 만들 때는 프론트엔드 개발자들과 백엔드 개발자들이 모여 '프론트엔드에서 이 URL로 이렇게 생긴 request를 보내면, 백엔드에서 이런 처리를 하고 이런 response를 보내주자.'와 같은 논의를 하고, 이런 내용들을 정리한 후에 개발을 시작하게 된다.
이것을 'Web API 설계'라고 한다. API란 Application Programming Interface의 약자로, 원래는 '개발할 때 사용할 수 있도록 특정 라이브러리나 플랫폼 등이 제공하는 데이터나 함수 등'을 의미한다. 웹 개발에서는 어느 URL로 어떤 request를 보냈을 때, 무슨 처리가 수행되고 어떤 response가 오는지에 관해 미리 정해진 규격을 Web API라고도 한다.
Web API를 설계한다는 것은 서비스에서 사용될 모든 URL들을 나열하고, 각각의 URL에 관한 예상 request와 response의 내용을 정리한다는 뜻이다. 만약 위의 코드에서 직원 정보 추가 기능을 설계하면 다음과 같이 할 수 있다.
...
3. 직원 정보 추가
https://learn.codeit.kr/api/members
(1) Request
- Head
Method : POST
...
- Body
{
"name": "Jerry",
"email: "jerry@codeitshopping.kr",
"department": "engineering",
}
...
(2) Response
Success인 경우 :
- Head
...
- Body
{
"id": "[부여된 고유 식별자 값]",
"name": "Jerry",
"email": "jerry@codeshopping.kr"
"department": "engineering",
}
Fail인 경우 :
...오늘날 많은 회사 내의 개발팀은 이런 식으로 Web API를 설계하고 웹 서비스를 만든다. 그런데 문제가 하나 있다. Web API는 어떻게 설계해도 동작하는 데는 아무런 지장이 없다는 것이다.
방법1)
(1) 'https://learn.codeit.kr/api/members' URL로
(2) request의 헤드에 POST 메소드를 설정하고,
(3) request의 바디에 새 직원 정보를 넣어서 보낸다.
방법2)
(1) 'https://learn.codeit.kr/api/members' URL로
(2) request의 헤더에 GET 메소드를 설정하고,
(3) request의 바디에 새 직원 정보를 넣어서 보낸다.
어느 방법으로 설계해도 서비스가 동작하는 데는 아무런 문제가 없다. 하지만 기능적으로 아무런 문제가 없다고 해도 Web API를 아무렇게나 설계해도 되는 것은 아니다. 사실 Web API가 잘 설계되었는지에 관한 기준으로는 보통 REST API라는 기준이 사용된다.
(2) REST API
REST API는 오늘날 많은 웹 개발자들이 Web API 설계를 할 때, 준수하기 위해 노력하는 일종의 가이드라인이다. REST API를 이해하기 위해서는 REST architecture가 무엇인지 알아야 한다.
REST architecture란 웹이 갖추어야 할 이상적인 구조를 의미한다. REST는 Representational State Transfer(표현적인 상태 이전)을 의미한다. 웹 서핑을 생각해라. 만약 웹을 하나의 거대한 컴퓨터 프로그램이라고 생각한다면, 각각의 웹 페이지는 그 프로그램의 내부 상태를 나타낸다고 할 수 있다. 그렇다면 웹 페이지들을 계속 옮겨 다니면서 보게 되는 내용은, 웹이라는 프로그램의 매번 새로운 상태를 나타내는 표현이라고 할 수 있다. 어떤 느낌인지 알겠는가?
REST architecture가 되기 위한 6가지 기준은 아래와 같다.
1. Client-Server
2. Stateless
3. Cache
4. Uniform Interace
5. Layered System
6. Code on Demand
각 기준들에 대해 간략히 설명해 보도록 하겠다.
- (Client-Server)
Client-Server 구조를 통해 양측의 관심사를 분리해야 한다. 웹 브라우저가 실행되고 있는 컴퓨터가 Client, 서비스를 제공하는 컴퓨터가 Server에 해당한다. Client 측은 사용자에게 어떻게 하면 더 좋은 화면을 보여줄지, 다양한 기기에 어떻게 적절하게 대처해야할지 등의 문제에 집중할 수 있고, Server 측은 서비스에 적합한 구조, 확장 가능한 구조를 어떻게 구축할 것인지 등의 문제에 집중할 수 있다. 이렇게 각자가 서로를 신경쓰지 않고 독립적으로 운영될 수 있다.
- (Stateless)
Client가 보낸 각 request에 관해서 Server는 그 어떤 맥락(context)도 저장하지 않는다. 즉, 매 request는 각각 독립적인 것으로 취급된다. 이 때문에 request에는 항상 필요한 모든 정보가 담겨야 한다.
- (Cache)
Cache를 활용해서 네트워크 비용을 절감해야 한다. Server는 response에, Clinet가 response를 재활용해도 되는지 여부(Cacheable)를 담아서 보내야한다.
- (Uniform Interface)
Client가 Server와 통신하는 인터페이스는 다음과 같은 하위 조건 4가지를 준수해야 한다. 이 조건이 REST API와 연관이 깊은 조건이다.
4-1. (identification of resources)
리소스(resource)는 웹상에 존재하는 데이터를 나타내는 용어이다. 리소스(resource)를 URI(Uniform Resource Identifier)로 식별할 수 있어야 한다는 조건이다. URI는 URL의 상위 개념이다.
4-2. (manipulation of resources through representations)
Client와 Server는 둘 다 리소스를 직접적으로 다루는 게 아니라 리소스의 '표현(representations)'을 다뤄야 한다. 즉, 동일한 리소스라도 여러 개의 표현일 있을 수도 있다는 의미이다. 사실, 리소스는 웹에 존재하는 특정 데이터를 나타내는 추상적인 개념이다. 실제로 다루게 되는 것은 리소스의 표현들뿐이다. 이렇게 '리소스'와 '리소스의 표현'이라는 개념 2개를 구분하는 것이 REST architecture의 특징이다.
4-3. (self-descriptive messages)
self-descriptive는 '자기설명적인'이라는 의미를 갖고 있다. Stateless 조건 때문에 Client는 매 request마다 필요한 모든 정보를 담아서 전송해야 한다. 이 때 Client의 request와 Server의 response 모두 그 자체에 있는 정보만으로 모든 것을 해석할 수 있어야 한다.
4-4. (hypermedia as the engine of application state)
REST architecture는 웹이 갖추어야 할 이상적인 구조라고 했다. 이때 '웹'을 좀더 어려운 말로 설명하자면 '분산 하이퍼미디어 시스템(Distributed Hypermedia System)'이라고 할 수 있다. 하이퍼미디어(Hypermedia)는 하이퍼텍스트(HyperText)처럼 서로 연결된 '문서'에 국한된 것이 아니라 이미지, 소리, 영상 등까지 모두 포괄하는 더 넓은 개념의 단어이다. 즉, 웹은 수많은 컴퓨터에 하이퍼미디어들이 분산되어 있는 형태이기 때문에, '분산 하이퍼미디어 시스템'에 해당한다. 이 조건은 웹을 하나의 프로그램으로 간주했을 때, Server의 response에는 현재 상태에서 다른 상태로 이전할 수 있는 링크를 포함하고 있어야 한다는 조건이다. 즉, response에는 리소스의 표현, 각종 메타 정보들뿐만 아니라 계속 새로운 상태로 넘어갈 수 있도록 해주는 링크들도 포함되어 있어야 한다.
- (Layered System)
Client와 Server 사이에는 프록시(proxy), 게이트웨이(gateway)와 같은 중간 매개 요소를 두고, 보안, 로드 밸런싱 등을 수행할 수 있어야 한다. 이를 통해 Client와 Server 사이에는 계층형 층(hierarchical layers)들이 형성된다.
- (Code-On-Demand)
Client는 받아서 바로 실행할 수 있는 applet이나 script 파일을 Server로부터 받을 수 있어야 한다. 이 조건은 Optional한 조건으로 REST architecture가 되기 위해 반드시 만족될 필요는 없다.
어려운 내용이지만 기억해야 할 사실은, REST API는 이런 REST architecture에 부합하는 API를 의미한다는 사실이다. 참고로 이런 REST API를 사용하는 웹 서비스를 'RESTful 서비스'라고 한다. 다음으로는 어떤 식으러 Web API를 설계해야 REST API가 될 수 있는지 개발자들이 강조하는 규칙 2가지만 보도록 하겠다.
- URL은 리소스를 나타내기 위해서만 사용하고, 리소스에 대한 처리는 메소드로 표현해야 한다.
URL에서 리소스에 대한 처리를 드러내면 안 된다는 규칙이다. 위의 직원 정보를 추가하기 위한 방법을 보도록 하자.
방법1)
(1) 'https://learn.codeit.kr/api/members' URL로
(2) request의 헤드에 POST 메소드를 설정하고,
(3) request의 바디에 새 직원 정보를 넣어서 보낸다.
방법1)의 경우, URL은 리소스만 나타내고, 리소스에 대한 처리(리소스 추가)는 메소드 값인 POST로 나타냈기 때문에 이 규칙을 준수했다고 불 수 있다.
방법2)
(1) 'https://learn.codeit.kr/api/members' URL로
(2) request의 헤더에 GET 메소드를 설정하고,
(3) request의 바디에 새 직원 정보를 넣어서 보낸다.
방법2)는 URL에서 리소스뿐만 아니라 해당 리소스에 대한 처리까지도 나타내고 있다. 그리고 정작 메소드 값으로는 리소스 추가가 아닌 리소스 조회를 의미하는 GET을 설정했기 때문에 규칙을 어겼다고 볼 수 있다.
- 도규먼트는 단수 명사로, 컬렉션은 복수 명사로 표시한다.
(https://www.soccer.com/europe/teams/manchester-united/players/pogba)
path 부분에서 특정 리소스를 나타낼 때 슬래시(/)를 사용해서 계측적인 형태로 나타낸다. 이렇게 계층적 관계를 잘 나타내면, URL만으로 무슨 리소를 의미하는지를 누구나 쉽게 이해할 수 있다. 그런데 이 때 지켜야 할 규칙이 있다.
리소스는 특징에 따라 여러 종류로 나눠볼 수 있지만, 지금은 '컬렉션(collection)'과 '도큐먼트(document)'에 대해서만 설명하도록 하겠다. 보통 우리가 하나의 객체로 표현할 수 있는 리소스를 '도큐먼트'라고 한다. 그리고 여러 개의 '도큐먼트'를 담을 수 있는 리소스를 '컬렉션'이라고 한다. 즉, 도규먼트는 하나의 '파일', 컬렉션은 여러 '파일'들을 담을 수 있는 하나의 '디렉터리'에 해당한다.
이때 URL에서 '도큐먼트'를 나타낼 때는 단수형 명사, '컬렉션'을 나타낼 때는 복수형 명사를 사용해야 한다는 규칙이 적용된다.
| 제목 | /members | /members/3 |
|---|---|---|
| GET | 전체 직원 정보 조회 | 3번 직원 정보 조회 |
| POST | 새 직원 정보 추가 | X |
| PUT | 전체 직원 정보 수정(잘 쓰이지 않음) | 3번 직원 정보 갱신 |
| DELETE | 전체 직원 정보 삭제(잘 쓰이지 않음) | 3번 직원 정보 삭제 |
전체 직원 정보를 대상으로 PUT, DELETE request를 보내는 것은 전체 직원 정보를 모두 수정 또는 모두 삭제한다는 뜻이기 때문에 사실상 잘 쓰이지 않는다. 위험한 동작이기 때문에 앷에 Web API 설계에 반영하지도 않고, 서버에서 허용하지 않을 때가 일반적이다.
POST request를 보낼 때, 컬렉션(members) 타입의 리소스를 대상으로 작업을 수행한다는 것에 주목해 보자. POST request를 보낼 때는 전체 직원 정보를 의미하는 컬렉션에 하나의 직원 정보(하나의 도큐먼트)를 추가하는 것이기 때문에 URL로는 컬레션까지만 /members 이렇게 표현해줘야 한다. 따라서 /membetrs/3 이렇게 특정 도큐먼트를 나타내는 URL에 POST request를 보내는 것은 문맥상 맞지 않는 표현이다. 그리고 지금 같은 경우는 추가될 직원 정보가 어떤 id값을 할당받을지 알 수도 없기 때문에 앷에 /members/[id]에 id 값을 지정한다는 것도 불가능하다.
8. JSON 데이터 다루기 종합
자바스크립트 객체를 string 타입의 JSON 데이터로 변환하느 것을 직렬화(Serialization), string 타입의 JSON 데이터를 자바스크립트 객체로 변환하는 것을 역직렬화(Deserialization)이라고 한다.
(1) string 타입의 JSON 데이터 vs 자바스크립트 객체
Serialization을 수행하기 위해서는 JSON이라는 자바스크립트 기본 내장 객체의 stringify 메소드를 사용하면 되고, Deserialization을 수행하기 위해서는 JSON 객체의 parse 메소드를 사용하면 된다. 이렇게 string 타입의 JSON 데이터와 자바스크립트 객체 사이에 어떤 차이가 있고 왜 필요한지에 대해서 설명하도록 하겠다.
const obj = { x: 1, y: 2 }; // 객체
const jsonString = JSON.stringify(obj); // string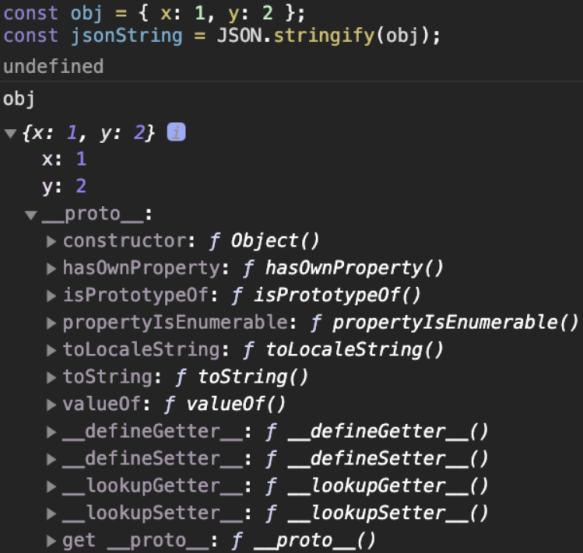
obj 객체는 자바스크립트 객체로서, 직접 정의하지는 않았지만, 기본으로 내장하는 프로퍼티들이 존재한다. 이런 것들은 자바스크립트 실행 환경에서, 객체라면 가지는 프로퍼티들일뿐 서버에는 전혀 보낼 필요가 없는 것들이다. 그리고 특히 이 객체의 메소드 같은 경우 서버에서 이를 인식 가능하도록 보낼 수 있는 방법도 없다. 이러한 이유가 객체(object)가 가진 데이터만을 string 타입으로 변환하는 Serialization 작업을 하는 이유이다.
const jsonString = '{"x": 1, "y": 2}';
const obj = JSON.parse(jsonString);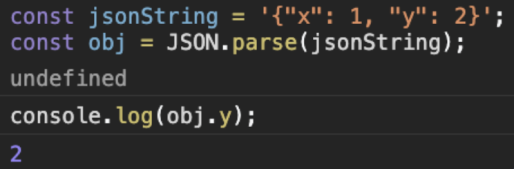
obj.y처럼 자바스크립트에서 객체의 프로퍼티 값을 읽을 때 쓰는 문법을 사용해서, obj 객체의 y프로퍼티에 바로 접근할 수 있다. 굳이 string 타입의 값에서 문자열을 파싱하여 어렵게 데이터를 추출하기보다는 자바스크립트 객체로 변환해서 편하게 데이터를 다루면 된다.
(2) text 메소드 말고 json 메소드도 있다.
fetch('https://jsonplaceholder.typicode.com/users')
.then((response) => response.text())
.then((result) => { const users = JSON.parse(result); });response 내용을 추출하기 위해 response.text()를 호출했고, 그 리턴값인 JSO 데이터(result, 실제로는 JSON 데이터를 품은 Promise 객체라는 것이 리턴된다.)를 Deserialize(JSON.parse(result))해서 생성한 객체를 users에 할당한다. 이때 코드의 양을 조금이나마 줄일 수 있는 방법이 있다.
fetch('https://jsonplaceholder.typicode.com/users')
.then((response) => response.json())
.then((result) => { const users = result; });response 객체의 text 메소드 대신 json 메소드를 호출하면, response 내용이 JSON 데이터에 해당하는 경우, 바로 Deserialization까지 수행한다. 이렇게 json 메소드를 사용하면, 두 번째 콜백의 result 파라미터로는 Deserialization 결과로 생성된 자바스크립트 객체가 넘어가게 된다. 그래서 두 번째 콜백 안에서 JSON.parse를 해주지 않아도 result를 바로 사용할 수 있는 것이다. 참고로, response의 내용이 JSON 데이터에 해당하지 않을 경우에는 에러가 발생한다.
response의 내용이 JSON 데이터로 미리 약속된 경우에는 response 객체의 text 메소드 대신 json 메소드를 사용해서 Deserialization까지 한 번에 수행하기도 한다.
9. Status Code (상태 코드)

(1) 각각의 상태 코드에는 대응되는 상태 메시지가 있다.
모든 상태 코드(Status Code)는 각각 그에 대응하는 상태 메시지(Status Message)를 갖고 있다. 예를 들어, 200번은 OK, 404번은 Not Found라는 상태 메시지를 갖고 있다.
(2) 상태 코드는 100번 ~ 500번대까지 있다.
1. 100번대
서버가 Client에게 정보성 응답(Information response)을 줄 때 사용되는 상태 코드들이다.
-
100 Continue
Client가 Server에게 게속 request를 보내도 괜찮은지 물어봤을 때, 계속 request를 보내도 괜찮다고 알려주는 상태 코드이다. 예를 들어, Client가 용량이 좀 큰 파일을 request의 바디에 담아 업로드하려고 할 때 Server에게 미리 괜찮은지를 물어보는 경우가 있다고 할 때, Server가 이 100번 상태 코드의 response를 주면 그제서야 본격적인 파일 업로드를 시작한다. -
1p1 Switching Protocols
Client가 프로토콜을 바꾸자는 request를 보냈을 때, Server가 '좋다. 그 프로토콜로 전환한다'라는 뜻을 나타낼 때 쓰이는 상태 코드이다.
2. 200번대
Client의 request가 성공 처리되었음을 의미하는 상태 코드이다.
-
200 OK
request가 성공적으로 처리되었음을 포괄적으로 의미하는 상태 코드이다. -
201 Created
request의 내용대로 리소스가 잘 생성되었다는 뜻이다. POST request가 성공한 경우에 200번 대신 201번이 올 수도 있다. -
202 Accpeted
request의 내용이 일단은 잘 접수되었다는 뜻이다. 즉, 당장 request의 내용이 처리된 것은 아니지만 언젠가 처리할 것이라는 뜻이다. request를 어느 정도 모아서 한번에 실행하는 Server인 경우 등에 이런 응답을 줄 수도 있다.
3. 300번대
Client의 request가 아직 처리되지 않았고, request 처리를 원하면 Client 측의 추가적인 작업이 필요함을 의미하는 상태 코드들이다.
-
301 Moved Permanently
리소스의 위치가 바뀌었음을 나타낸다. 보통 이런 상태 코드가 있는 response의 헤드에는 Location이라는 헤더도 함께 포함되어 있다. 그리고 그 헤더의 값으로 리소스에 접근할 수 있는 URL이 담겨있다. 대부분의 브라우저는 만약 GET reqeust를 보냈는데 이런 상태 코드가 담긴 response를 받게 되면, 헤드에 포함된 Location 헤더의 값을 읽고, 자동으로 그 새 URL에 다시 request를 보내는 동작(리다이렉션, redirection)을 수행한다. -
302 Found
리소스의 위치가 일시적으로 바뀌었음을 나타낸다. 지금 당장은 아니지만 나중에 현재 요청한 URL이 정상적으로 인식될 것이라는 뜻이다. 이 상태 코드의 경우에도 보통 그 response의 헤드에 Location 헤더가 있고, 여기에 해당 리소스의 임시 URL 값이 있다. 이 경우에도 대부분의 브라우저들은 임시 URL로 리다이렉션한다. -
304 Not Modified
브라우저들은 보통 한번 response로 받았던 이미지 같은 리소스들을 그대로 내부에 저장하고 있다. 그리고 Server는 해당 리소스가 바뀌지 않았다면, response에 그 리소스를 보내지 않고 304번 상태 코드만 헤드에 담아서 보냄으로써 '네트워크 비용'을 절약하고 브라우저가 저장된 리소스를 재활용할도록 한다. 사실 이 상태 코드는 웹에서 '캐시(cache)'라는 주제에 대해서 공부해야 정확히 이해할 수 있다.
4. 400번대
request를 보내는 Client 쪽에 문제가 있음을 의미하는 상태 코드들이다.
-
400 Bad Request
말 그대로 request에 문제가 있음을 나타낸다. request 내부 내용의 문법에 오류가 존재하는 등의 이유로 인해 발생한다. -
401 Unauthorized
아직 신원이 확인되지 않은(unauthenticated) 사용자로부터 온 request를 처리할 수 없다는 뜻이다. -
403 Forbidden
사용자의 신원은 확인되었지만 해당 리소스에 대한 접근 권한이 없는 사용자라서 request를 처리할 수 없다는 뜻이다. -
404 Not Found
해당 URL이 나타내는 리소스를 찾을 수 없다는 뜻이다. 보통 이런 상태 코드가 담긴 response는 그 바디에 관련 웹 페이지를 이루는 코드를 포함하고 있는 경우가 많다. -
405 Method Not Allowed
해당 리소스에 대해서 요구한 처리는 허용되지 않는다는 뜻이다. 만약 어떤 Server 이미지 파일을 누구나 조회할 수는 있지만 아무나 삭제할 수는 없다고 하자. GET request는 허용되지만, DELETE 메소드는 허용되지 않는 상황이다. -
413 Payload Too Large
현재 request의 바디에 들어있는 데이터의 용량이 지나치게 커서 Server가 거부한다는 뜻이다. -
429 Too Many Requests
일정 시간 동안 Client가 지나치게 많은 request를 보냈다는 뜻이다. Server가 수많은 Client들의 request를 정상적으로 처리해야 하기 때문에 특정 Client에게만 특혜를 줄 수는 없다. 따라서 지나치게 request를 많이 보내는 Client에게는 이런 상태 코드를 담은 response를 보낼 수도 있다.
5. 500번대
Server 쪽의 문제로 인해 request를 정상적으로 처리할 수 없음을 의미하는 상태 코드들이다.
-
500 Internal Server Error
현재 알 수 없는 Server 내의 에러로 인해 request를 처리할 수 없다는 뜻이다. -
503 Service Unavailable
현재 Server 점검 중이거나, 트래픽 폭주 등으로 인해 서비스를 제공할 수 없다는 뜻이다.
10. Content-Type
(1) Content-Type 헤더
Content-Type 헤더는 현재 request 또는 response의 바디에 들어 있는 데이터가 어떤 타입인지를 나타낸다.
지금까지는 HTML, JavaScript 등의 코드 또는 JSON 데이터가 들어있는 경우만 보았지만, 텍스트부터 시작해서 이미지, 영상까지 많은 것들이 들어갈 수 있다.
Content-TYpe 헤더의 값은 '주 타입(main type)/서브 타입(sub type)'의 형식으로 나타낸다.
- 주 타입이 text인 경우(텍스트)
- 일반 텍스트 : text/plain
- CSS 코드 : text/css
- HTML 코드 : text/html
- JavaScript 코드 : text/javascript
- 주 타입이 image인 경우(이미지)
- image/bmp : bmp 이미지
- image/gif : gif 이미지
- image/png : png 이미지
- 주 타입이 audio인 경우(오디오)
- audio/mp4 : mp4 오디오
- audio/ogg : ogg 오디오
- 주 타입이 video인 경우(비디오)
- video/mp4 : mp4 비디오
- viceo/H264 : H264 비디오
- 주 타입이 application인 경우(위 타입들에 속하지 않는 것들)
- application/json : JSON 데이터
- application/octet-stream : 확인되지 ㅇ낳은 바이너리 파일
보통 텍스트 파일 이외의 파일들을 바이너리 파일(binary file)이라고 한다. 이 바이너리 파일들 중에서도 특정 확장자(.png, .mp4 등)의 포맷에 해당하지 않는 데이터들을 보통 application/octet-stream으로 나타낸다. 참고로 브라우저는 response의 Content-Type 헤더의 값으로 application/octet-stream이 쓰여 있으면 보통, 사용자에게 '다운로드 받으시곘습니까'와 같은 alert 창을 띄운다.
왜 Content-Type 헤더가 필요한 것일까? Content-Type 헤더가 존재하면, 바디의 데이터를 직접 확인해서 그 타입을 추론하지 않아도 되기 때문이다. request든 response든 바디에 어떤 데이터가 존재하는 경우라면 이 Content-Type 헤더의 값을 적절하게 설정해주는게 좋다.
(2) Content-Type 설정해보기
const newMember = {
name: 'Jerry',
email: 'jerry@codeit.kr',
department: 'engineering',
};
fetch('https://learn.codeit.kr/api/members', {
method: 'POST',
headers: { // 추가된 부분
'Content-Type': 'application/json',
},
body: JSON.stringify(newMember),
})
.then((response) => response.text())
.then((result) => { console.log(result); });10-1. 알아두면 좋은 Content-Type들
(1) JSON 말고 XML도 있다.
개발자들이 어떤 정보를 나타내기 위해 흔히 쓰는 데이터 포맷으로는 JSON 뿐만 아니라 XML(Extensible Markup Language)이라고 하는 데이터 포맷도 있다. 쉽게 설명하자면, 태그를 사용해서 데이터를 나타내는 것이다.
{
"name":"Michael Kim",
"height":180,
"weight":70,
"hobbies":[
"Basketball",
"Listening to music"
]
}<?xml version="1.0" encoding="UTF-8" ?>
<person>
<name>Michael Kim</name>
<height>180</height>
<weight>70</weight>
<hobbies>
<value>Basketball</value>
<value>Listening to music</value>
</hobbies>
</person>XML을 쓸 때는 보통 스키마(Schema)라는 별도의 문서를 함께 사용한다. 이 스키마에는 각 조직, 기관 등에서 XML로 데이터를 나타낼 때, 어떤 태그들을 사용할 수 있고, 각 태그의 의미는 무엇이며, 특정 태그는 어떤 타입의 값을 가질 수 있는지 등의 정보가 담겨있다. 따라서 XML은 데이터에 대한 엄격한 유효성(validity) 검증에 특화된 데이터 포맷이라고 할 수 있다.
하지만 XML은 같은 양의 데이터를 표현하더라도, JSON에 비해 더 많은 용량을 차지하고, JSON에 비해 가독성이 떨어지며, 배우기가 어렵다는 문제 등으로 인해, 오늘날 XML의 입지는 다소 좁아진 것이 사실이다. 특히나 자바스크립트가 중심이 되는 웹 개발에서는 자바스크립트 문법과 JSON 문법이 대체로 호환되기 때문에 더더욱 JSON을 사용하는 것이 편리하다.
(2) form 태그에서 사용되는 타입들
(2-1) application/x-www-form-urlencoded
form 태그는 회원가입 화면이나 게시물 업로드 화면 등을 만들 때 주로 활용되는 HTML 태그이다. form 태그를 사용하면 자바스크립트 코드 없이 오로지 HTML만으로도 request를 보내는 것이 가능하다. 최근에는 form 태그를 사용하지 않고 자바스크립트 코드로 직접 사용자의 입력값을 취합해서 request를 보내는 방법이 많이 사용되고 있지만 form 태그만으로 request를 보내는 방식도 쓰이고는 있기 때문에 알아두면 좋다.
form 태그는 기본적으로 이 application/x-www-form-urlencoded 타입의 데이터를 바디에 담아서 보낸다.
{
"id": 6,
"name": "Jason",
"age": 34,
"department": "engineering"
}id=6&name=Jason&age=34&department=engineering프로퍼티의 이름과 값을 "이름=값" 형식으로 나타내고 각각의 프로퍼티를 "&" 기호로 연결하는 방식으로 데이터를 표현한다. URL의 query 부분에서 사용하는 방식과 비슷하다.
...
<body>
<div id="signup">
<p id="title">CodeitShopping</p>
<form action="/upload" method="get" enctype="application/x-www-urlencoded">
<div>
<div><span class="label">email</span></div>
<input class="input" type="text" id="email" name="email">
</div>
<div>
<div><span class="label">password</span></div>
<input class="input" type="password" id="password" name="password">
</div>
<div>
<div><span class="label">nickname</span></div>
<input class="input" type="text" id="nickname" name="nickname">
</div>
<div>
<input id="submit-btn" type="submit" value="Sign Up">
</div>
</form>
</div>
</body>
...form 태그의 method라는 속성에 get, enctype이라는 속성에 application/x-www-form-urlencoded를 적으면, 이 form 태그가 request를 보낼 때, request의 메소드를 GET으로 설정하고, 사용자가 입력한 데이터를, URL의 쿼리 부분에 application/x-www/urlencoded 타입으로 넣는다. enctype 속성을 설정을 안 해도 기본적으로 application/x-www/urlencoded 타입을 사용한다.

회원 가입 버튼을 누르면 나타나는 주소창 이미지이다. 이렇게 form 태그는 바로 사용자의 입력값을 URL의 query 부분에 application/x-www-form-urlencoded 타입으로 나타낸 URL로 request를 보내는 것이다.
그런데 빨간색으로 표시된 부분을 보면 작성하지 않았던 이상한 퍼센트(%) 기호와 숫자들이 보인다.
| 입력했던 실제 글자 | 표시된 내용 |
|---|---|
| @ | %40 |
| ! | %21 |
| 공백 | + |
아래와 같은 특수 문자들이 각자 자신의 원래 용도가 아닌 다른 용도로 사용되는 경우 Percent Encoding을 해줘야 한다.
| : | / | ? | # | [ | ] | @ | ! | $ | & | ' | ... | ''(공백) |
| %3A | %2F | %3F | %23 | %5B | %5D | %40 | %21 | %24 | %26 | %27 | ... | %20 또는 + |
(2-2) multipart/form-data
이제까지 살펴본 Content-Type 값들은, 하나의(Single) 데이터의 타입을 나타내는 값들이었다. text/html, video/mp4, application/json 등 모두 데이터 하나의 타입을 나타냈다. multipart(여러 개의 파트)라는 단어에서도 유추할 수 있듯이 이 값은 여러 종류의 데이터를 하나로 합친 데이터를 의미하는 타입이다.
게시판에 게시글을 올릴 때, 글의 제목과 내용을 적고, 이미지 파일이나 영상 파일을 첨부하기도 한다. 이때 게시글을 업로드 할 때 파일들의 내용도 request에 함께 담겨서 가야하는데 이때 Content-Type의 값이 multipart/form-data가 된다.
11. 그 밖에 알아야 할 내용들
(1) Ajax
Ajax는 웹 브라우저가 현재 페이지를 그대로 유지한 채로 Server에 request를 보내고 response를 받아서, 새로운 페이지를 로드하지 않고도 변화를 줄 수 있게 해주는 기술이다.
Ajax는 Asynchronous JavaScript And XML의 줄임말이다. 이는 자바스크립트를 사용해서 비동기적으로(=사용자가 보고 있는 현재 화면에 영향을 미치지 않고 별도로 백그라운드에서 작업을 처리한다는 뜻) request를 보내고 response를 받는데 기반이 되는 기술들의 집합을 의미한다. 마지막에 XML이 쓰인 것은 Ajax라는 용어가 생겨난 당시에 XML이 가장 많은 인기를 누리던 타입이었기 때문이다.
Ajax 원리를 이해하기 위해서 구글 맽(Google Map) 같은 웹 서비스를 생각해보면 이해하기 쉬울 것이다.
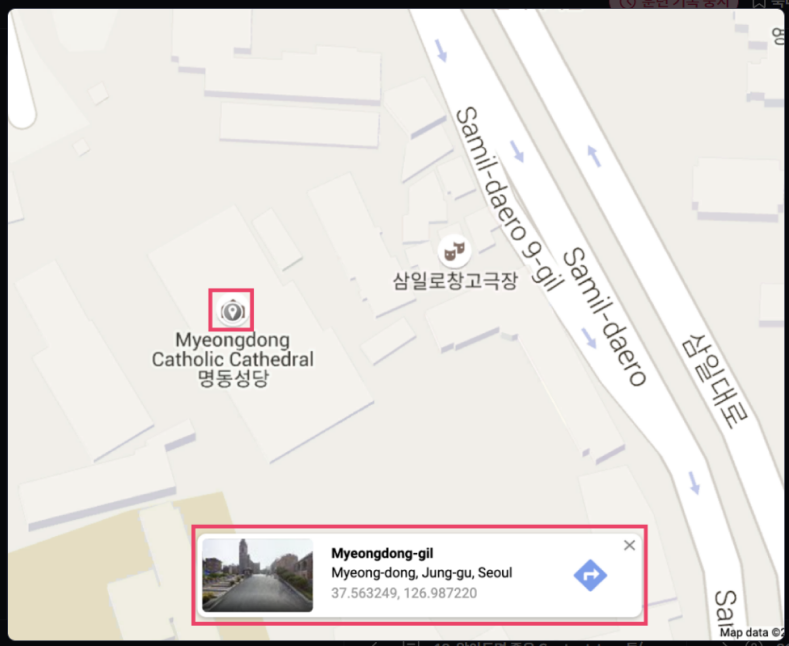
현재 웹 페이지는 그대로 유지되고, 단지 그 밑에 명동 성당에 관한 간단한 정보창이 떠오른다. 이것이 가능한 이유는 웹 브라우저가, 사용자가 보고 있는 현재 페이지를 방해하지 않고 별도로 Server로 request를 보내고, response를 받아왔기 때문이다. Ajax 기술 덕분에 구글 맵처럼 부드러운 UX(User Experience, 사용자 경험)를 제공하는 수많은 웹 서비스들을 사용할 수 있게 된 것이다.
자바스크립트에서는 XMLHttpRequest라고 하는 객체를 통해 Ajax 통신을 할 수 있다.
const xhr = new XMLHttpRequest();
xhr.open('GET', 'https://learn.codeit.kr/api/members');
xhr.onload = function () {
console.log(xhr.response);
};
xhr.onerror = function () {
alert('Error!');
};
xhr.send();예전에는 XMLHttpRequest라고 하는 생성자 함수로 객체를 생성하였지만, 요즘에는 굳이 그렇게 하지 않아도 된다.
첫 번째 이유는 XMLHttpRequest 객체 이후에 등장한 함수, fetch 함수를 사용해서 Ajax 통신을 할 수 있기 때문이다. fetch 함수는 XMLHttpRequest 객체를 사용할 때에 비해 좀 더 짧고 간단한 코드로 Ajax 통신을 할 수 있게 해주는 함수이다.
두 번째 이유는 XMLHttpRequest을 기반으로 더 쓰기 편하게 만들어진 axios라는 패키지가 존재하기 때문이다.
// Ajax 통신 X
<a href="https://learn.codeit.kr/api/main">메인 화면으로 가기</a>
// Ajax 통신 O
// (위 예시를 단순화한 코드입니다)
function getLocationInfo(latitude, longitude) {
fetch('https://map.google.com/location/info?lat=latitude&lng=longitude')
.then((response) => response.text())
.then((result) => { /* 사용자 화면에 해당 위치 관련 정보 띄워주기 */ });
}(2) GET, POST, PUT, DELETE 이외의 메소드들
(1) PATCH
PATCH 메소드는 기존의 데이터를 수정할 때 사용하는 메소드이다. PUT은 기존 데이터를 아예 새로운 데이터로 덮어씀으로써 수정하려고 할 때 사용하는 메소드이고, PATCH는 새 데이터로 기존 데이터의 일부를 수정하려고 할 때 쓰는 메소드이다.
{
"id": 3,
"name": "Michael",
"age": 25
}
// ---------------------------- //
{
"age": 30
}
// ---------------------------- //
{
"id": 3,
"name": "Michael",
"age": 30
}PATCH 메소드를 사용하면 request에 가운데와 같은 데이터를 바디에 담아서 보내게 되면 맨 아래 데이터처럼 age 속성만 갱신되게 된다. 즉, 바디에 수정할 프로퍼티의 데이터만 넣어줘도 된다. 하지만 PUT 메소드를 사용하려면 원하는 새 데이터의 온전한 모습 전체를 바디에 담아서 보내줘야 한다. 결국 데이터를 수정하는 메소드 중에서 PUT은 덮어쓰기, PATCH는 일부 수정을 의미한다고 생각하면 될 것이다.
(2) HEAD
HEAD 메소드는 GET 메소드와 동일하다. 대신 GET request를 보냈을 때 받았을 response에서 바디 부분은 제외하고, 딱 헤드 부분만 받는다는 점이 다르다.
웹 브라우저가 Server로부터 용량이 엄청 큰 영상 파일을 받고자 하는 상황이 있다고 가정하자. 이때 파일의 용량만 조사하기 위해서 HEAD 메소드가 담긴 request를 보내볼 수 있다. URL로 HEAD 메소드가 설정된 request를 보내면 그 response는 바디는 없고 헤드만 있을 것이다. 대신 이때 Content-length와 같이 컨텐츠 용량을 나타내는 헤더가 있어서 파일의 용량 정보는 알게 될 수도 있다. 그럼 이 용량을 사용자에게 보여주고 그래도 영화 파일을 시청할 건지 물어보는 코드를 작성할 수 있을 것이다. 이처럼 실제 데이터가 아니라 데이터에 관한 정보만 얻으려고 하는 상황 등에 HEAD 메소드가 활용된다.
(3) 웹 통신 말고 다른 통신도 있다.
사실 하나의 컴퓨터와 다른 컴퓨터가 통신하는 공간에는 웹만 있는 것은 아니다. 이전 웹의 특징에는 'HTTP, HTTPS와 같은 프로토콜을 사용하여 통신한다'는 것이 있었다.
하지만 HTTP, HTTPS 이외에도, FTP, SSH, TCP, UDP, IP, Ethernet 등 정말 다양한 종류의 프로토콜이 있다.

우리가 배운 HTTP는 보통, 그 밑에 TCP(Transmission Control Protocol), 그 밑에 IP(Internet Protocol), 그 밑에 Ethernet이라는 프로토콜을 기반으로 동작하고 있다. 즉 HTTP나 HTTPS 프로토콜을 기반으로 한 통신은 그 하위 프로토콜을 기반으로 이루어지는 것이다. 위로갈수록 고수준 프로토콜, 아래로 갈수록 저수준 프로토콜이라고 한다. 백엔드 개발자의 경우에는 서비스의 사용자 수가 늘어나서 request 수가 늘어날수록 HTTP 아래에 있는 프로토콜에 대해서도 어느 정도 알고 있어야 각종 성능 문제 등을 해결할 수 있다.
