들어가며
LLM 도메인에 대해서 제대로 알아가기 시작하는 동안 가장 어려웠던 부분 중 하나는 내가 따라가지 못한 사이에 너무 많은 용어가 등장했다는 것이다. 내가 알던 딥러닝 모델의 훈련 방식은 그저 Pre-training과 Fine-tuning 정도였고 그 안에서 네트워크 구조를 바꾸거나 하이퍼 파라미터 조정을 하는 정도였는데, LLM을 훈련하는 방법은 두 가지로만 끝나지 않는다는 것이다. 막 Coursera 강의를 들었을 때에는 ‘와 나 이제 좀 알겠어!’라는 생각이 들었었는데, 몇 주 지났다고 또 까먹었다. 그래서 이번 포스팅은 강의를 복습할 겸 다양한 LLM 훈련 방법들을 개괄적으로 다뤄보려고 한다.
LLM에서 사용하는 다양한 훈련 기법들
Instruction fine-tuning
Instruction fine-tuning이란 말 그대로 구체적인 지시를 모델에게 훈련시키는 방법이다. 프롬프트 엔지니어링만으로 모델에게 원하는 task를 지시할 수 없을 때 사용한다. Prompt와 Completion pair를 여러 개 학습시켜서, 특정 task를 잘 수행하도록 학습시키는 것이다. 모델의 모든 파라미터를 변경하는 Full Fine-tuning 방법으로 진행한다. (관련 강의)
PEFT(Parameter-Efficient Fine-Tuning)
PEFT는 fine-tuning 시에 모델의 모든 파라미터들을 튜닝하지 않고, 몇 개의 일부(small subset) 파라미터들만 fine-tuning을 진행하는 기법이다. 다른 파라미터들은 고정시켜두고 일부 파라미터만 튜닝하기 때문에 모델이 새로운 학습을 진행할 때에 이전에 학습한 task를 잊어버리는 catastrophic forgetting 문제가 발생할 확률이 줄어들 수 있다. 일부의 파라미터만 조정하여 QA, Summarize, Generate PEFT 등 다양한 task에 맞는 모델로 학습할 수 있다.
PEFT Method는 크게 세 가지 방식(Selective, Reparameterization(LoRA), Additive)이 있다. Selective는 LLM 파라미터에서 subset을 고르는 방식이고, Reparameterization은 low-rank representation을 이용하여 파라미터를 변경하는 방식이고, Additive는 모델에 layer나 파라미터를 추가하는 방식이다. Additive 방식에는 prompt tuning 기법이 있는데, 이 기법은 흔히 알려진 prompt engineering과는 다른 기법이다(관련 강의). Prompt tuning에서는 프롬프트에 훈련 token개수를 늘리는 방법이 있다. 이렇게 늘린 token들을 soft prompt라고 부르는데, task에 맞게 soft prompt만 변경할 수 있는 강점이 있다.
 이미지 출처 - LLM 강의
이미지 출처 - LLM 강의
Huggingface의 transformers 라이브러리를 사용해서 진행하려고 한다면, 모델을 로드한 뒤에 get_peft_model 메소드를 활용해 peft_config로 모델을 감싼 뒤 다른 훈련과 동일하게 Trainer class를 사용해 훈련을 진행하면 된다. (출처)
from transformers import AutoModelForSeq2SeqLM
from peft import LoraConfig, TaskType, get_peft_model
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/mt0-large")
model = get_peft_model(model, peft_config)
trainer = Trainer(...)
trainer.train()peft config를 감싼 모델은 모델에서 훈련 가능한 파라미터가 몇 개인지 print_trainable_parameters() 메소드로 확인할 수 있다.
model.print_trainable_parameters()
# >> output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282RLHF(Reinforcement Learning from Human Feedback)
RLHF는 다른 용어들에 비해 상대적으로 많이 알려진 방식이고, 검색하면 좋은 설명이 많이 나오기 때문에(사실 이 거대한 파이프라인을 간단하게 설명할 자신이 없다) 생략하였다. (관련 강의) (관련 블로그 포스트)
DPO(Direct Preference Optimization)
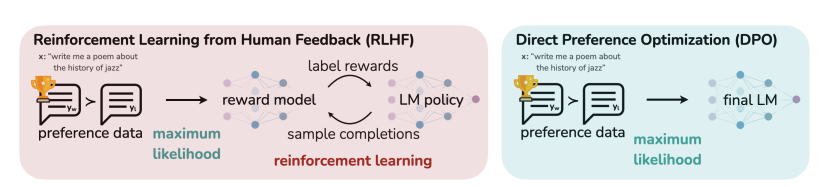
RLHF의 가장 큰 단점은 ‘복잡하다’는 것이다. RLHF 기법을 사용하려면 실제 학습이 되는 생성모델, 리워드 모델, critic 모델, 레퍼런스 모델까지 총 4개의 모델이 필요하다(출처). 안 그래도 거대한 LLM모델에 훨씬 더 많은 비용과 시간을 필요로 하는 것이다. 이러한 이유로 복잡하고 무거운 RLHF를 대체하기 위한 방법론이 몇 가지 등장했는데, 그 중 하나가 DPO이다. DPO는 리워드 모델을 사용하지 않고, RLHF에서 리워드 모델을 학습하는 데에 사용했던 선호도 데이터를 모델 학습에 직접 사용하는 방법이다. DPO 이외에도 RRHF, SLiC-HF, Rejection Sampling Fine-tuning 라는 방법이 있는데, 스캐터랩 블로그 포스트에서 진행한 실험에서는 RLHF를 대체할 수 있는 네 가지의 방법론 중 Rejection Sampling이 가장 안정적이고 성능이 좋았다고 한다. 최근에 업스테이지가 공개한 SOLAR-10.7B가 merge 기법과 DPO 방식을 사용하여 LLM을 구축하였다. DPO 기법도 Huggingfac의 DPOTrainer를 사용하면 바로 적용해볼 수 있다.
DAPT(Domain Adaptive Pre-Training), TAPT(Task Adaptive Pre-Training)
특정 domain(분야 혹은 언어도 될 수 있다)이나 task에 맞는 모델을 만들기 위해 fine-tuning이 아닌 pre-training을 이어서 한다는 뜻의 continual learning 기법이다(논문). 간단하게 말하면 특정 domain(분야나 언어)이나 task에 맞는 데이터셋을 추가로 학습시키는 것이다. Fine-tuning이랑 뭐가 다른지 많이 헷갈렸는데, 간단하게 말하면 pre-training과 동일한 훈련 방식으로 데이터셋을 추가로 학습시키는 방식을 DAPT와 TAPT라고 부르는 것이다. Pre-training과 fine-tuning의 훈련 레이어가 달랐던 BERT를 NLP에서 주로 사용하던 시기에 데이터를 추가해서 pretraining을 더 해야 목적에 맞는 모델을 만들 수 있다고 주장한 논문이었는데, 최근 LLM을 목적에 맞게 훈련하는 데에 많이 언급되는 것 같다. LLM 분야에서 모델의 파라미터를 키워 거대해지는 것보다, 적절한 데이터를 추가로 훈련하는 것이 더 효과적이라는 연구가 입증되면서(DAPT 저자의 선견지명이었을까…?) 자주 사용하는 것 같다.
마치며
기존 딥러닝 기반의 모델보다 훨씬 거대한 파라미터를 가진 LLM이 등장하면서, from-scratch로 모델을 훈련하지 않고도 원하는 모델을 효과적으로 구축할 수 있는 다양한 훈련 기법들이 등장할 수 있게 되었다. 각 용어들은 각자 독립된 포스트로 작성할 만한 주제였는데 하나의 포스트로 적다 보니 깊게 다루진 못하였다. RAG(Retrieval-Augmented Generation)까지도 설명하려고 했지만 RAG를 훈련 기법으로 묶기 모호하기도 했고 내용을 더 추가하면 너무 번잡해질 것 같아서 보류하였다. 꾸준하게 정리해서 다음 포스트로 이어나가보려고 한다.
