동영상 원본 : https://youtu.be/zduSFxRajkE?si=qR88n9wmarjPcAWA
colab 원본 : https://colab.research.google.com/dri...
게시글 내 모든 이미지와 코드의 출처는 위 영상과 colab 주소에 있습니다:)
이전 포스팅에서는 인코딩과 디코딩 등 토크나이저가 실제로 구축되고 사용되는 과정에 대해 다루었는데요, 이번 포스팅에는 영상의 약 1시간 43분부터 마지막까지의 내용을 다뤄보겠습니다. 토크나이저를 다루기 위한 핵심적인 내용은 이미 영상에서 다 다루었지만, 후반부에서 부가적으로 설명해주는 내용이 흥미로워서 정리해보려고 합니다.
How to set the vocab
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
# better init, not covered in the original GPT video, but important, will cover in followup video
self.apply(self._init_weights)카파씨 선생님의 이전 강의(GPT from scratch)에서 다뤘던 gpt 코드를 보면, vocab_size는 모델의 첫 레이어로 들어가고 lm_head에 마지막 출력 차원으로 나오기도 합니다. vocab_size는 token_embedding_table이라는 2차원의 array에서 row의 개수를 나타냅니다. Vocab의 element들인 각 토큰들은 하나의 벡터이며, 이 토큰들은 훈련에서 back propagation을 하는 데에 사용됩니다. 즉 vocab의 요소들인 토큰의 개수가 늘어날수록 transformer가 훈련해야하는 array가 커지는 것이죠.
마지막 레이어인 lm_head는 logit값을 생성하는 구간입니다. 출력 Sequence에서 다음 토큰의 확률을 나타내는 구간이죠. 마찬가지로 vocab의 요소들인 토큰의 개수가 늘어날수록 logit에서 생성해야 하는 확률값이 많아집니다. 모든 토큰들이 lm_head 레이어인 Linear layer에서 dot product 연산을 수행해야 하기 때문이죠.
즉, 토큰의 개수가 늘어날수록 vocab size가 커지고 이는 훈련시 계산량이 늘어날 뿐만 아니라 중요한 정보를 덜 훈련하게 될 수도 있습니다. 그렇지만 너무 많은 토큰들을 merge시켜서 vocab size를 줄여버린다면, 모델이 언어를 학습하기에는 정보가 충분하지 않을 수도 있습니다. 그래서 모델이 학습하기에 적당한 vocab size를 구축하는게 중요하다고 강조합니다.
How to train new tokens
이미 훈련된 모델을 가지고 fine-tuning을 수행할 때 종종 새로운 토큰을 모델에 추가하기도 하는데요, 이럴 때 모델이 새 토큰들을 잘 학습할 수 있도록 하는 여러 기법들이 있습니다. 이 예시로 강의에서는 Learning to Compress Prompts with Gist Tokens라는 페이퍼를 소개해줍니다. 이 논문은 데이터 전체를 학습하기에는 너무 거대한 long prompt들을 모델에 학습시키기 위해서, long prompt들로 생성되는 새로운 토큰들만 모델을 distillation한 뒤에 훈련시켰습니다. 모델을 전부 freeze 시킨 뒤에 새로운 토큰들의 embedding만 훈련시켜서 long prompt를 그대로 모델에 훈련시키는게 아니라 몇 개의 새로운 토큰들만 학습하도록 만든 것이죠. 이렇게 방법을 적용해도 데이터를 전부 학습시킨 경우와 비슷한 성능을 달성할 수 있었다고 합니다.
Multimodal tokenization
그렇다면 텍스트가 아닌 다른 도메인 생성 모델에서는 어떻게 tokenization이 일어날까요? 프롬프트로 영상을 만들어내는 OpenAI의 Sora에서는 모델 훈련 시 visual patches들이 LLM에서의 text token과 같은 역할을 한다고 설명합니다.
Wrap-up
영상의 마지막 파트에서는 강의에서 다뤘던 내용들을 처음부터 다시 짚어보면서 강의에서 강조하고 싶었던 내용을 다시 이야기합니다. 마지막 파트만 봐도 강의 전체에서 다룬 웬만한 내용들을 확인할 수 있지만, 강의를 다 들은 전제로 뒷 내용을 다루기 때문에 개인적으로는 처음부터 쭉 보고 해당 파트를 시청하는 걸 추천드립니다.

강의 후반부에서는 ChatGPT를 통해 LLM 모델이 할 수 없는 기능들을 보여주는데요, 예를 들면 하나의 토큰으로 구성된 .DefaultCellStyle 토큰에서 “l”이 포함된 개수를 맞추지 못하거나,

단어를 거꾸로 뒤집어 spell하는 작업을 수행할 수 없습니다.
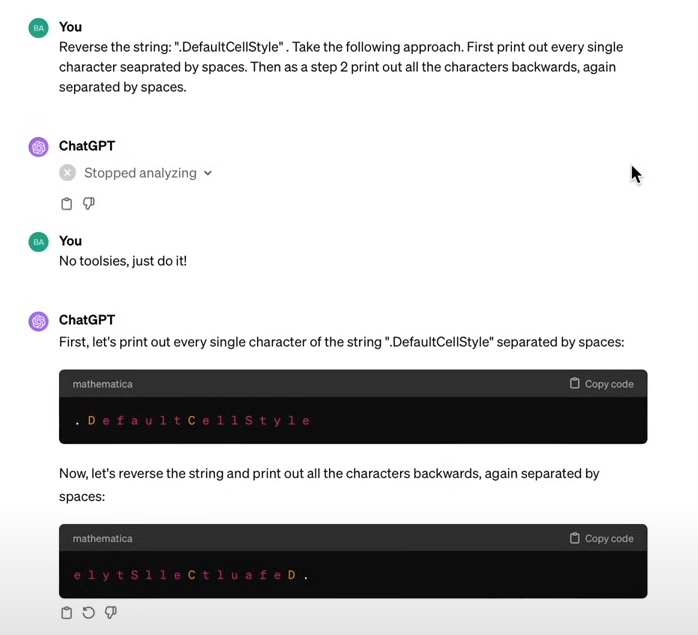
하지만 단어를 한 글자씩 쪼개고 뒤집으라고 하면 잘 수행하는 걸 확인할 수 있습니다. 왜냐하면 글자를 쪼개는 과정에서 하나의 토큰이었던 .DefaultCellStyle이 각 글자마다의 토큰으로 변환되기 때문이죠.
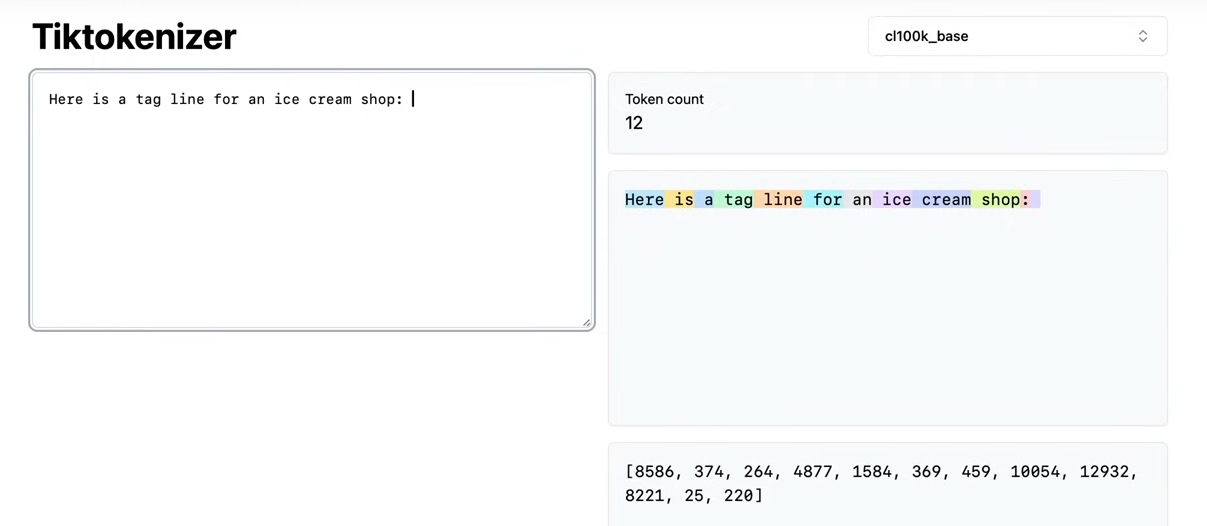
그리고 강의에서는 OpenAI의 Playground에서 text를 생성할 때 공백 문자로 끝난 prompt를 입력하면 출력 성능이 안 좋아질 수 있다는 경고 메세지를 주는 걸 보여주었는데요. 이는 토큰들(사진의 단어들 예시)에 공백 문자가 prefix로 붙어있기 때문에 공백 문자를 추가해서 프롬프트를 입력한다면 모델이 마지막 단어가 아닌 220이라는 공백 문자 다음에 오는 토큰을 예측하게 되는 문제가 발생할 수 있다고 지적합니다.
solidgoldmagickarp
강의에서는 tokenization과 관련해서 재밌는 블로그 글도 소개해 주는데요. 블로그의 저자는 token embedding cluster들에서 solidgoldmagickarp와 같은 이상한 단어의 연쇄가 존재한다는 사실을 발견했습니다. 이런 이상한 연쇄들에 대해서 GPT한테 무슨 의미인지 물어보았는데, 아예 모른다고 하거나 이상한 이야기를 하거나 다른 단어를 이야기하는 등의 고장난 답변을 이야기했다고 합니다. 이런 단어들은 다름이 아니고 reddit의 username들이었다고 합니다. 각 username과 그들과 관련된 게시물들이 함께 묶여 tokenization이 진행되었지만, 모델의 학습 데이터에는 username이 들어가지 않아서 GPT가 해당 단어들을 이해하지 못하고 이상한 답변을 뱉게 만든 것입니다. 이런 문제들은 security나 safety issue에서 문제를 일으킬 수 있다고도 지적합니다.
마치며
작성하다보니 2시간 길이의 영상을 3개의 게시물로 나누어 업로드하게 되었네요. 강의를 한 번만 보고 마무리했다면 이해하지 못하고 넘어갈 부분이 많았는데, 중요한 부분은 빠짐 없이 게시물에서 다뤄보고 싶어서 다시 보다 보니 저도 다시 짚고 넘어갈 수 있는 부분이 많았습니다. 제 포스팅이 강의 영상을 보거나 tokenization 공부할 때 조금이라도 도움이 되길 바랍니다!
