들어가며
안녕하세요. 오늘은 LLM을 추론하는 방법론을 제시한 논문을 리뷰해보도록 하겠습니다. 논문에서 제시하는 프레임워크인 SELF-DISCOVER는 이름 그대로 주어진 작업(task)에 대해서 스스로 추론 방식을 찾아내도록 구성한 구조인데요. GPT-4와 PaLM 2 모델에 적용해보았을 때 기존에 잘 알려진 추론 방식인 Chain of Thought (CoT)보다 더 나은 성능을 보였고 여러 번의 추론이 필요하지만 높은 성능을 기록하는 CoT-Self-Consistency 방식보다는 더 좋은 성능을 달성하면서도 추론 계산량도 훨씬 줄였다고 합니다. 논문의 abstract를 보고 도대체 어떤 방식으로 추론 과정을 구조화했는지 궁금해질 수 밖에 없었는데요, 한 번 자세히 살펴보도록 하겠습니다.
논문 요약
서론
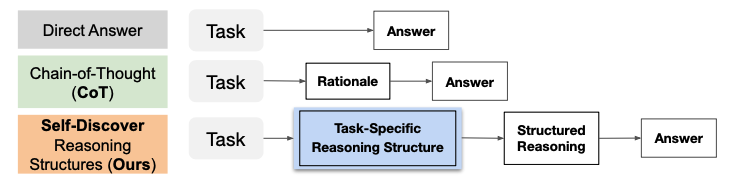
LLM의 가장 큰 능력 중 하나는 추론(reasoning)을 통해 복잡한 문제를 해결할 수 있다는 점인데요, 다만 항상 문제를 맞출 수도 없고 오히려 틀린 답을 맞다고 이야기하는 할루시네이션 등이 LLM의 문제점으로 지적되고 있었습니다. 이러한 이유로 LLM으로 복잡한 문제를 더 정확하게 해결할 수 있는 여러 prompting 방법론이 제시되고 있었는데요. 대표적인 방법론으로 Chain of Thought (CoT)가 있었습니다. CoT는 간단하게 이야기하면 prompting에 입력하는 예제에 대해서 답만 제시하는 것보다, 풀이과정까지 함께 제시하여 LLM이 주어진 문제에 대해서 더 정확하게 추론하도록 돕는 방법론입니다.
 이미지 출처 : 논문 원문
이미지 출처 : 논문 원문
CoT는 인간이 문제를 step-by-step으로 나누어 해결하는 방법을 닮았습니다. 대표적인 CoT를 제외하고도 인간이 문제를 해결하는 과정에서 착안한 여러 prompting 방법론이 제시되어 왔는데요, 하지만 각 방법론들은 주어진 작업을 처리하는 과정에서 그저 하나의 개별적인 추론 방식(atomic reasoning module)으로 고정되어 prompting을 진행하기 때문에 한계가 존재할 수 밖에 없었습니다. 그래서 해당 논문은 주어진 작업에 알맞는 여러 atomic reasoning module을 찾아 조합할 수 있는 SELF-DISCOVER 방식을 제안했습니다. SELF-DISCOVER는 인간이 문제를 해결할 때 추론 프로그램이 동작하는 방식에 착안했다고 합니다. 이러한 방법을 사용하면 여러 개의 reasoning modules를 함께 사용할 수 있고, 단 3번의 추론만으로도 복잡한 문제의 추론 방식을 도출해낼 수 있고, 무엇보다 추론 과정을 조합하기 때문에 추론 과정이 설명 가능한 방식으로 표현된다는 장점이 있다고 설명합니다.
 이미지 출처 : 논문 원문
이미지 출처 : 논문 원문
Self-Discovering Reasoning Structures for Problem-Solving
 이미지 출처 : 논문 원문
이미지 출처 : 논문 원문
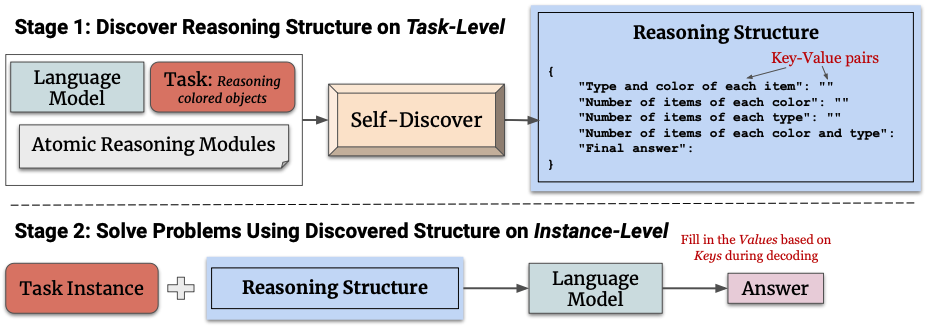
Self-Discovering Reasoning Structures는 크게 세 단계로 진행합니다. 인간이 문제에 직면했을 때 과거의 경험을 기반으로 필요한 지식이나 능력을 찾는 것처럼, 이 방법론도 주어진 task에 필요한 여러 지식이나 능력을 찾는 과정부터 시작합니다. 그리고는 찾은 능력이나 지식을 연결하여 주어진 task에 적용합니다. 이러한 과정에서 세 개의 meta-prompts를 가이드로 활용하여 추론합니다. 추론 구조는 JSON 포맷을 활용하여 구축합니다. 추론은 크게task-level과 instance-level로 나누고, task-level은 select, adapt, implement로 총 세 단계로 나누어집니다.
 이미지 출처 :
이미지 출처 : 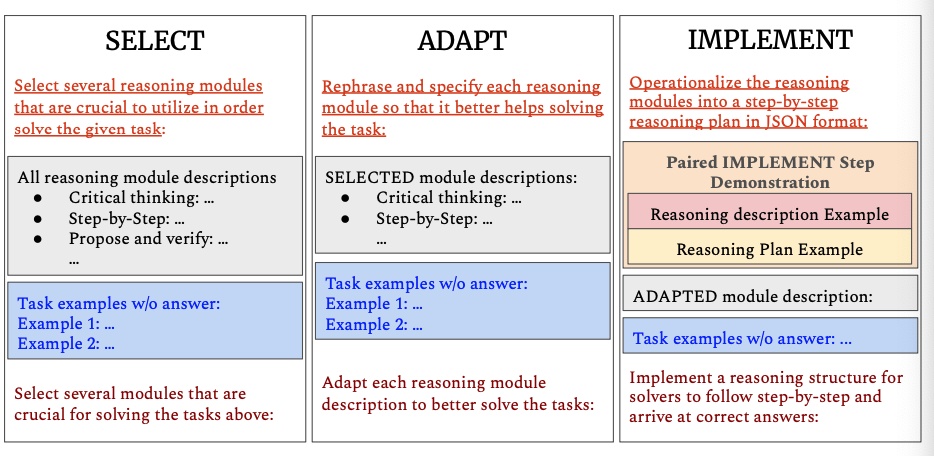 이미지 출처 :
이미지 출처 : stage 1-1 : SELECT
Select 단계는 글자 그대로 문제를 해결하기 위해 필요한 reasoning modules를 LLM이 선택하도록 추론하는 과정입니다. SELF-DISCOVER는 task example에 필요한 modules를 가이드로 제시합니다. ‘소설 작성 시에는 “creative thinking”이 필요할 것이다’ 같은 메타 프롬프트, reasoning module에 대한 raw set, 라벨이 없는 task example 몇 개를 제시하여 모델이 reasoning modules를 선택하도록 합니다. 논문에서는 총 29개의 reasoning modules를 제시하고 있습니다(논문 13p.).
stage 1-2 : ADAPT
Module을 선택했다면 LLM 추론을 사용하여 각 module에 대해 주제에 맞는 rephrase를 진행합니다. “break the problem into subproblems” 를 “calculate each arithmetic operation in order”로 바꾸는 방식으로 선택한 module들을 주어진 task에 맞게 구체화하는 과정입니다. 이 단계에서도 가이드를 위한 메타 프롬프트와 SELECT의 아웃풋과 task들이 들어갑니다.
stage 1-3 : IMPLEMENT
ADAPT를 진행했다면 각 modules들을 하나의 implemented reasoning structure로 변환합니다. IMPLEMENT에서는 자연어로 된 설명을 reasoning structure로 잘 변환하기 위해 인간이 작성한 reasoning structure를 함께 제시합니다.
stage 2 : Tackle Tasks Using Discovered Structures
Stage 1의 세 단계를 거치고 나면 task에 맞는 reasoning structure를 구축할 수 있습니다. 그러면 이제 reasoning structure를 사용해서 한 번의 추론으로 복잡한 문제를 해결할 수 있는 추론을 진행할 수 있습니다.
실험 결과
 이미지 출처 : 논문 원문
이미지 출처 : 논문 원문
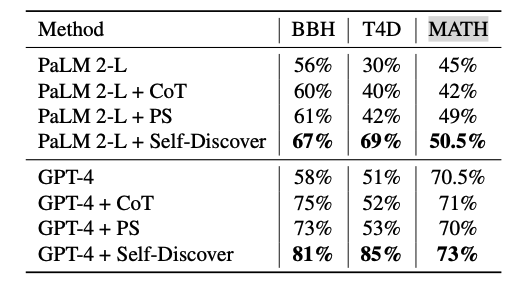
모든 실험 결과를 전부 설명하기엔 장황해질 것 같아 실험 결과만 간단하게 요약해보겠습니다. 실험에서는 diverse reasoning benchmarks를 활용하여 prompt 방법론을 비교하였는데요. BIG-Bench Hard (BBH), T4D, MATH라는 벤치마크를 사용하여 비교한 결과 다른 방법론보다 높은 성능을 달성하였습니다. 특히 영화 추천, 스포츠 이해 등 ‘diverse world knowledge’능력을 필요로 하는 task에 가장 좋은 성능을 보였습니다. 또 비슷한 정확도를 보인 CoT-Self-Consistency의 추론 횟수에 비해 단 한 번의 추론으로도 더 나은 성능을 보였습니다.
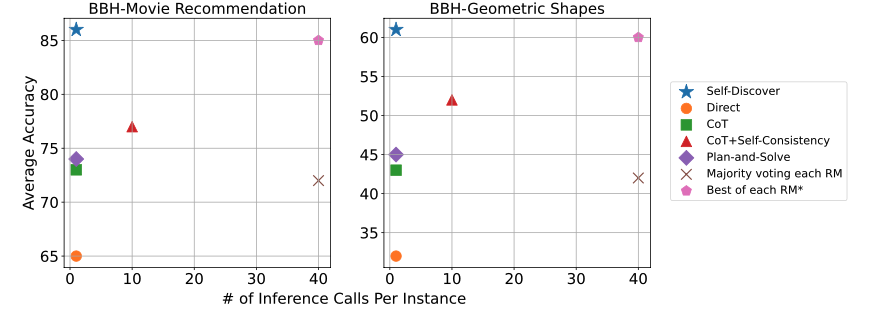 이미지 출처 : 논문 원문
이미지 출처 : 논문 원문
마치며
현실적으로 모델 자체를 customizing하기 어려운 LLM을 사용하여 원하는 task를 보다 빠르고 정확하게 해결할 수 있는 방법론이 많이 연구되고 있는데요, 인간의 추론 방식에서 착안하고 그렇게 개발한 방법론이 좋은 성능을 달성하고 있는 연구 결과들이 흥미롭습니다. 앞으로 어떤 방향으로 프롬프트 엔지니어링이 발전해 나갈지 기대가 됩니다.
