[AWS] Integration & Messaging: SQS, SNS, Kinesis, Active MQ
참고 자료
https://www.udemy.com/course/best-aws-certified-solutions-architect-associate/
Section Introdcution
애플리케이션을 여러 개 배포하면 이들은 필연적으로 서로 통신해야할 필요가 있다. 이 통신은 두 가지 패턴으로 나뉜다.
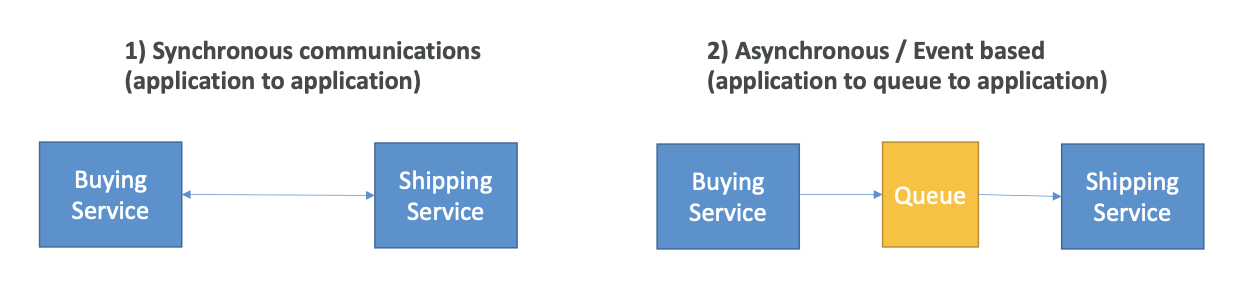
애플리케이션 간의 동기적인 통신은 트래픽의 갑작스러운 증가가 발생할 경우 문제가 될 수 있다. 예를 들어 평소에는 10개의 동영상을 인코딩 하던 서비스에서 갑자기 1000개의 비디오를 인코딩하는 경우, 인코딩 서비스가 압도될 것이고 운용이 정지될 것이다.
이런 경우, 애플리케이션을 분리(decouple)하고, 아래의 서비스를 이용하는 것이 좋다.
- SQS: 대기열 모델 사용
- SNS: pub/sub 모델
- Kinesis: 실시간 스트리밍을 하고 대용량 데이터를 다루는 경우
이러한 서비스들은 애플리케이션과 독립적으로 서비스를 확장할 수 있다.
1. Amazon SQS
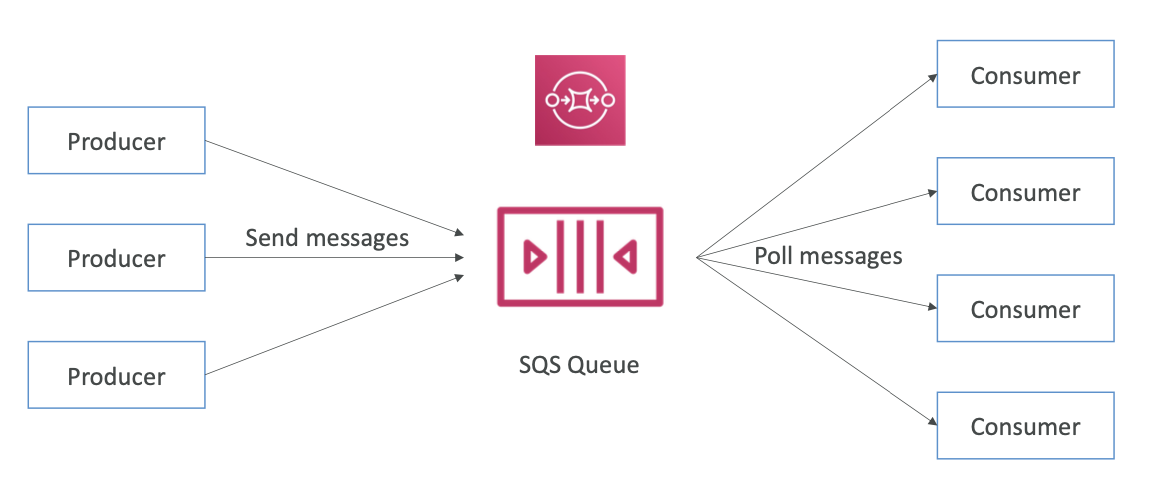
대기열 서비스는 생산자와 소비자 사이를 분리하는 버퍼 역할을 한다.
🧐 Standard Queue
- AWS의 첫 번째 서비스 중 하나. 가장 오래된 서비스라고 할 수 있음.
- 완전 관리형 서비스. 애플리케이션을 분리하는데 사용됨.
- Attributes:
- 무제한 처리량, 대기열에 저장 가능한 메시지 수의 제한이 없음
- 메시지 보존 기간의 기본 값은 4일, 최대 기간은 14일
- 지연 시간이 짧음 (<10 ms on publish and receive)
- 전송되는 메시지는 256 KB 로 제한됨
- 중복 메시지가 발생할 수 있음 (at least once delivery, occasionally)
- Can have out of order messages (best effort ordering)
Producing Messages
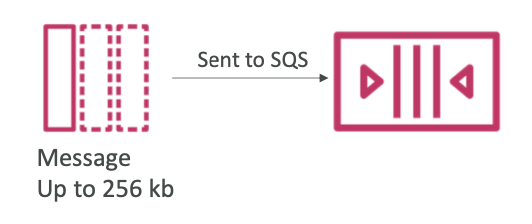
- SDK를 사용하여 SQS에 메시지를 생성 (SendMessage API)
- 메세지는 소비자가 해당 메시지를 읽고 삭제할 때까지 SQS 대기열에 유지
- 메시지 보존 기간: 기본 값은 4일이며 최대 14일까지 설정 가능
- 예시: send an order to be processed
- Order id
- Customer id
- 필요한 모든 속성 (주소 등)
- SQS standard: 무제한 처리량을 제공함
Consuming Messages
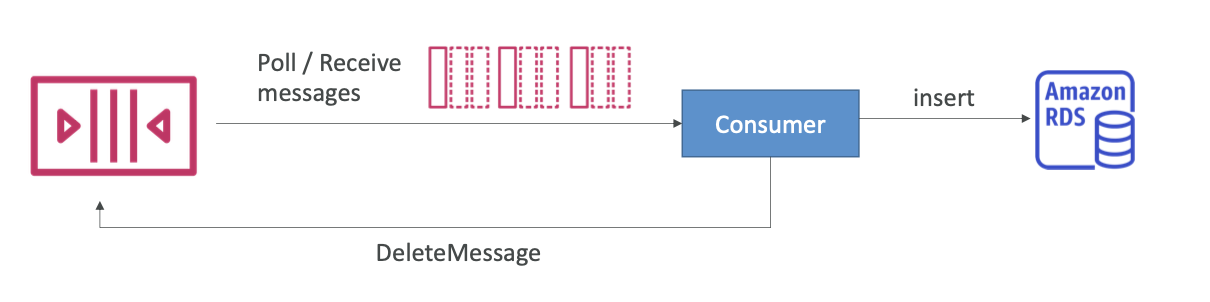
- 소비자 (EC2 인스턴스, 서버, 또는 AWS Lambda에서 실행)
- 메시지를 가져오기 위해 SQS를 폴링 (한 번에 최대 10개의 메시지 수신)
- 메시지를 처리 (ex. 메시지를 RDS 데이터베이스에 삽입).
- DeleteMessage API를 사용하여 메시지를 삭제
Multiple EC2 Instances Consumers
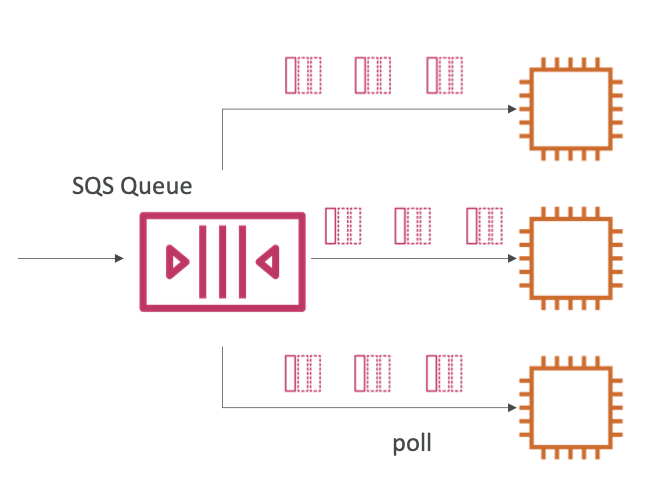
- 소비자들은 메시지를 병렬로 수신하고 처리함
- 최소 한 번의 전송 보장
- 각 소비자는 poll 함수를 호출하여 다른 메시지 세트를 수신하게 됨. 만일 메시지가 소비자에 의해 충분히 빠르게 처리되지 않으면 다른 소비자가 수신하게 됨. 따라서 적어도 한 번은 전송이 됨.
- 최선의 노력으로 메시지 순서 보장 (Best-effort message ordering)
- 소비자들은 메시지를 처리한 후에 삭제해야 함
- 처리량을 향상시키기 위해 소비자를 추가하고 수평 확장을 할 수 있음
SQS with Auto Scaling Group (ASG)
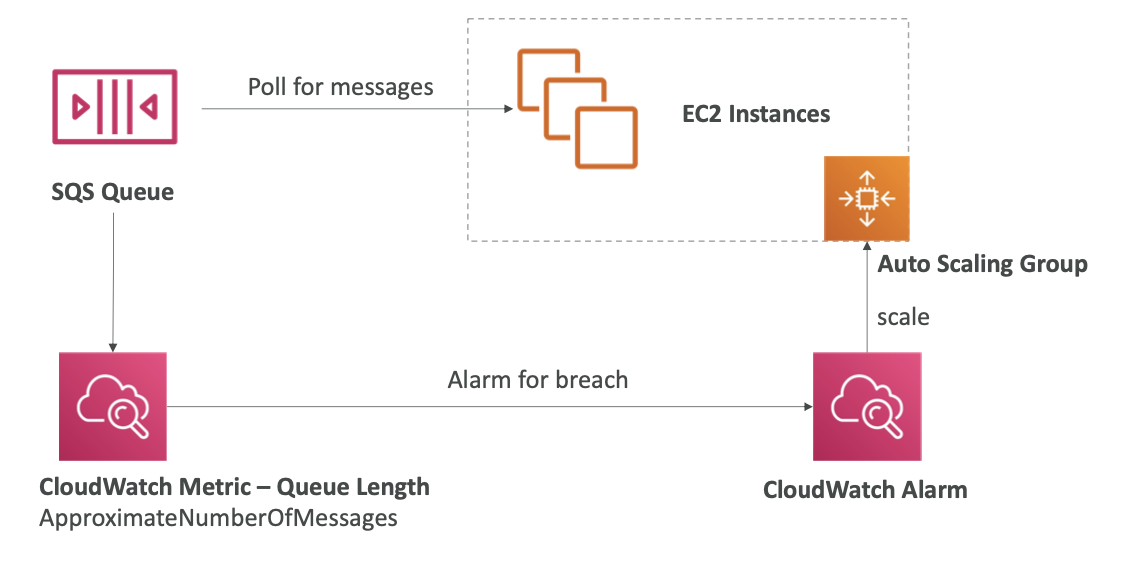
- 소비자가 ASG 내부에서 EC2 인스턴스를 실행하고, SQS 대기열에서 메시지를 폴링함.
- ASG는 일종의 Metric에 따라 확장되어야 하는데, 이때 사용하는 Metric은 대기열의 길이임 (ApproximateNumberOfMessages).
- 경보를 설정할 수 있는데, 대기열의 길이가 특정 수준을 넘어가면 CloudWatch Alarm을 설정하면 됨. 이 경보는 오토 스케일링 그룹의 용량을 X만큼 증가시키는데 그러면 더 많은 메시지가 SQS 대기열에 있게 됨.
- 예를 들어 웹사이트에 오더가 폭주해서 오토 스케일링 그룹이 더 많은 EC2 인스턴스를 제공하면 메시지들을 더 높은 처리량으로 처리할 수 있게 됨.
SQS to decouple between application tiers
SQS는 애플리케이션 계층 간에 분리를 위해 사용됨.
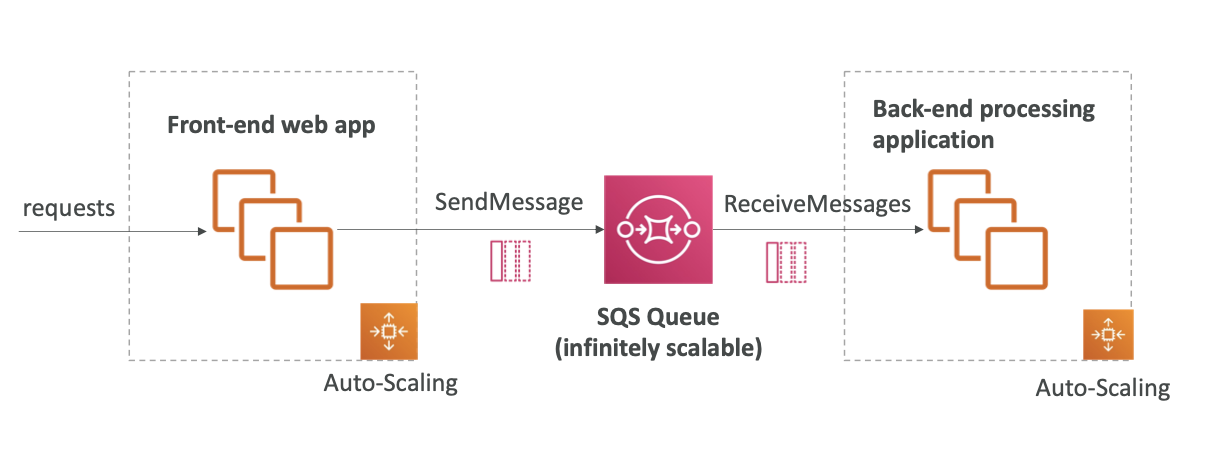
예를 들어, 비디오를 처리하는 애플리케이션이 있다고 가정하자. 프론트엔드라는 큰 애플리케이션이 있는데 프론트엔드가 요청을 받고 비디오가 처리되어야 할 때 프론트엔드가 처리를 한 후 S3 버킷에 삽입한다. 하지만 처리 시간이 매우 오래 걸릴 수 있고, 프론트엔드에서 이를 처리하면 웹사이트의 속도가 느려질 수 있다.
대신 애플리케이션을 분리하여 파일 처리 요청과 실제 파일 처리가 서로 다른 애플리케이션에서 발생할 수 있도록 할 수 있다. 파일 처리 요청을 받을 때마다 SQS 대기열로 메시지를 전송하면 된다. 그러면 처리 요청을 할 때 해당 파일은 SQS 대기열에 있게 되고, 자체 오토 스케일링 그룹에 속할 백엔드 처리 애플리케이션이라는 두 번째 처리 계층을 생성할 수 있다.
이 애플리케이션이 메시지를 수신하고 비디오를 처리하고 S3 버킷에 이를 삽입할 것이다.
이 아키텍처에서 볼 수 있듯이 그에 따라 프론트엔드를 확장할 수 있고 그에 따라 백엔드도 확장할 수 있지만 독립적으로 확장할 수도 있다.
Security
Encryption:
- 전송 중 데이터의 암호화는 HTTPS API 사용
- 정지 상태 (at-rest) 데이터의 암호화는 KMS 키 사용
- 클라이언트가 직접 암호화/복호화를 수행하려는 경우 클라이언트 측 암호화를 사용
Access Controls:
- IAM 정책을 사용하여 SQS API에 대한 액세스를 규제
SQS Access Policies (similar to S3 bucket policies):
- SQS 대기열에 대한 교차 계정 액세스를 수행하는 경우에 유용
- 다른 서비스 (SNS, S3 등)가 SQS 대기열에 쓸 수 있도록 허용하는 데 유용
⏳ Message Visibility Timeout
- 소비자가 메시지를 폴링하면 그 메시지는 다른 소비자에게는 보이지 않게 됨
- 기본적으로 "메시지 가시성 시간 제한 초과"는 30초
- 즉 메시지는 처리되기 까지 30초의 시간을 갖게 됨
- 메시지 가시성 시간 제한이 초과되면 메시지는 SQS에서 "가시" 상태가 됨
- 즉 가시성 시간 제한 기간 내에서는 메시지는 다른 소비자에게 보이지 않고, 가시성 시간 제한이 초과되고 메시지가 삭제되지 않았다면 메시지는 대기열에 다시 넣어짐.
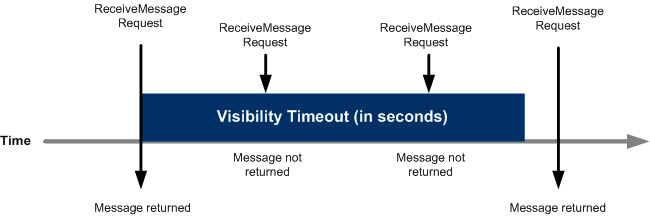
- 메시지가 가시성 시간 제한 내에 처리되지 않으면 메시지는 두 번 처리될 수도 있음
- 소비자는 ChangeMessageVisibility라는 API를 호출하여 더 많은 시간을 얻을 수 있음
- 가시성 시간 제한이 너무 길 경우 (시간 단위), 소비자가 충돌했을 때 이 메시지가 다시 나타날 때까지 (SQS 대기열에 보일 때까지) 몇 시간이 걸릴 수 있음
- 가시성 시간 제한이 너무 짧을 경우 (초 단위), 처리할 시간이 충분하지 않으면 다른 소비자가 메시지를 여러 번 읽고 해당 요청이 여러 번 처리될 수 있음
🫸 Long Polling
- 소비자가 대기열에서 메시지를 요청할 때 대기열에 메시지가 없다면 메시기자 도착할 때까지 "대기"할 수 있다.
- 이를 긴 폴링(Long Polling)이라고 한다.
- 긴 폴링은 SQS로의 API 호출 수를 줄이고, 애플리케이션의 효율성을 향상시키며, 응답 지연 시간을 감소시킨다.
- 대기 시간은 1초부터 20초 사이로 설정할 수 있다. (20 sec preferable)
- 긴 폴링은 짧은 폴링에 비해 선호된다.
- 긴 폴링은 대기열 수준에서, 혹은 WaitTimeSeconds를 사용하여 API 수준에서 활성화할 수 있음
👆 FIFO Queue
- FIFO = First In First Out (ordering of messages in the queue)

- 처리량에 제한이 있음: 배치 처리 없이는 초당 300개의 메시지 처리, 배치 처리를 사용하면 초당 3,000개의 메시지 처리 가능
- 중복 메시지를 제거하여 정확히 한 번만 전송 가능
- 소비자에 의해 메시지는 순서대로 처리됨
⏫️ SQS with Auto Scaling Group (ASG)
If the load is too big, some transactions may be lost
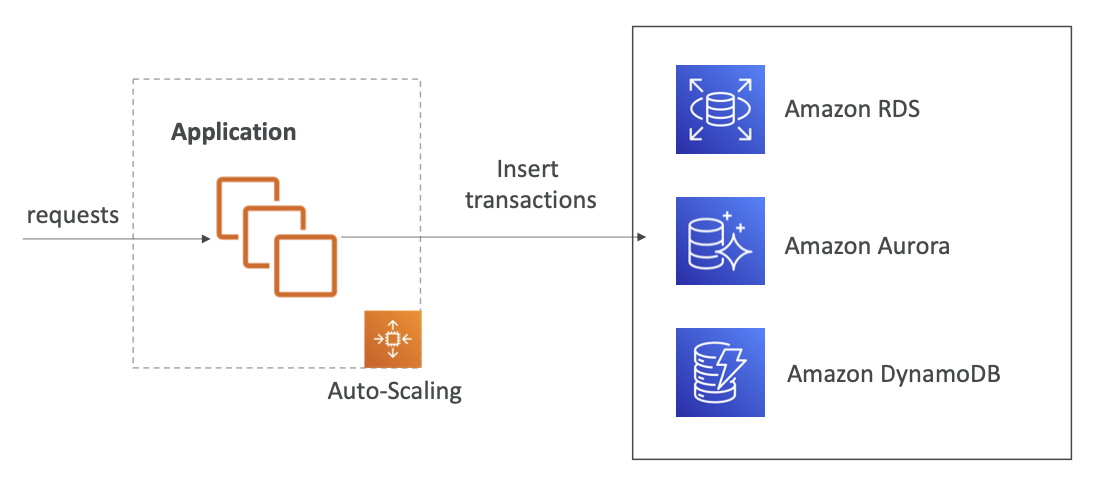
애플리케이션이 주문 즉 요청을 처리할텐데 데이터베이스가 오버로드 되는 등의 모종의 이유로 특정 트랜잭션에 오류가 발생한다면 해당 고객 트랜잭션은 유실될 수 있다.
이때 쓰기 대상 데이터베이스에서 SQS를 버퍼로 사용할 수 있다.
SQS as a buffer to database writes
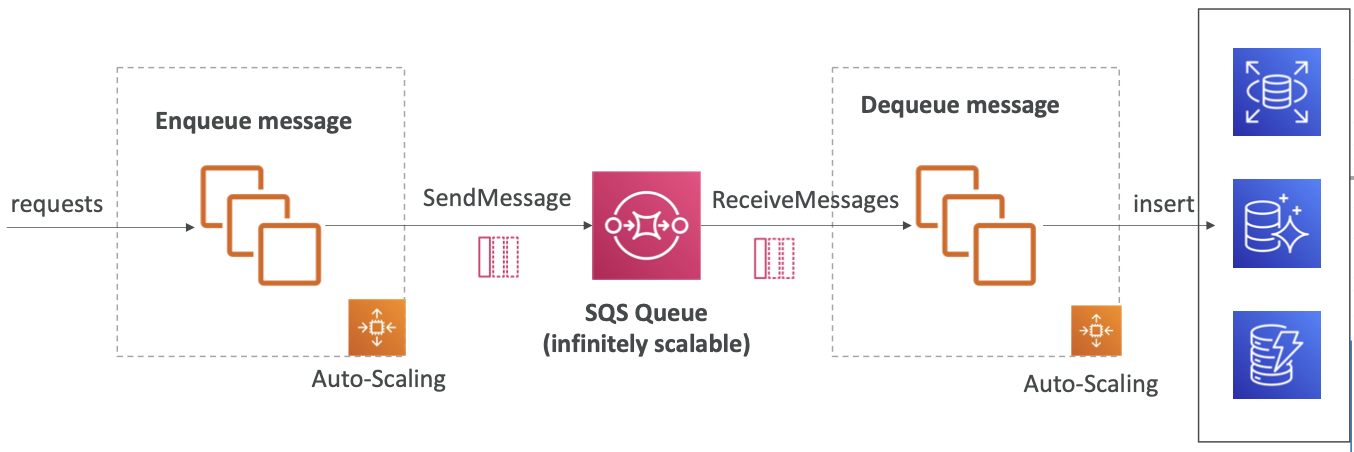
DB에 바로 요청을 쓰는 대신, 애플리케이션이 요청, 즉 트랜잭션을 SQS 대기열에 먼저 쓰는 방법이 있다. 이렇게 하면 처리량 문제가 발생하지 않난다.
따라서 애플리케이션에 요청이 전송되고, 이 요청은 메시지로 대기열에 넣어지는데, 이는 곧 모든 트랜잭션, 즉 모든 요청이 SQS 대기열에 메시지로서 전달된다는 뜻이다.
이렇게 하면 유실되는 요청이 없을 것이고 요청은 지속적으로 SQS 대기열에 저장될 것이다.
SQS to decouple between application tiers
2. Amazon SNS
메시지 하나를 여러 수신자에게 보낸다고 가정해보자.
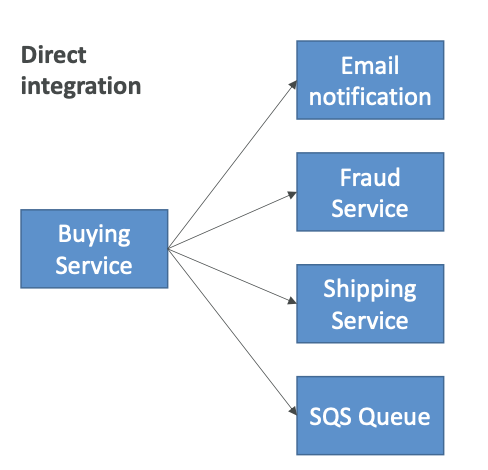
이런 경우 직접 통합 (Direct integration)을 쓸 수 있는데, 구매 서비스 애플리케이션을 예로 들자면 이메일 알림을 보내고 사기 탐지 서비스, 배송 서비스, SQS 대기열에도 메시지를 보낼 수 있다. 하지만 통합을 생성하고 작성해야하므로 번거로울 수 있다.
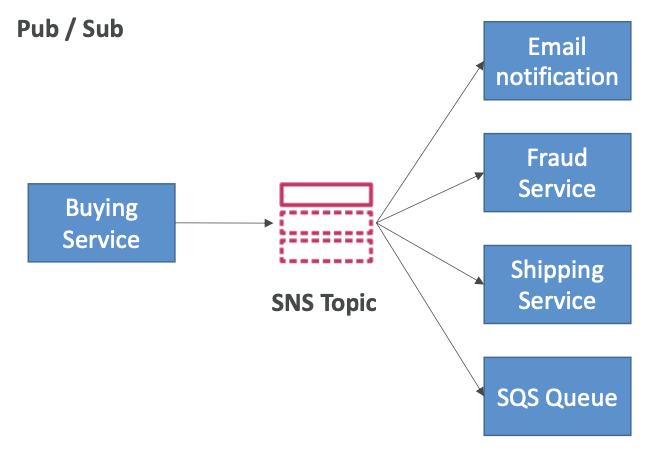
대신 Pub/Sub (게시/구독)이라는 것을 사용할 수 있는데, 이를 통해 구매 서비스가 메시지를 SNS 주제(Topic)로 전송할 수 있다. 해당 주제에는 많은 구독자가 있으며, 각 구독자는 SNS 주제에서 해당 메시지를 수신하고 이를 보관할 수 있다.
- Amazon SNS에서 "이벤트 생산자"는 한 주제에만 메시지를 보낸다.
- "이벤트 수신자(구독자)"는 해당 주제와 관련한 SNS 알림을 받으려는 사람이고, 원하는 만큼 생성할 수 있다.
- 주제에 대한 각 구독자는 모든 메시지를 수신한다. (참고: 메시지 필터링을 위한 기능도 있음)
- 주제당 최대 12,500,000개의 구독이 가능하다.
- 주제의 수는 100,000개로 제한된다.
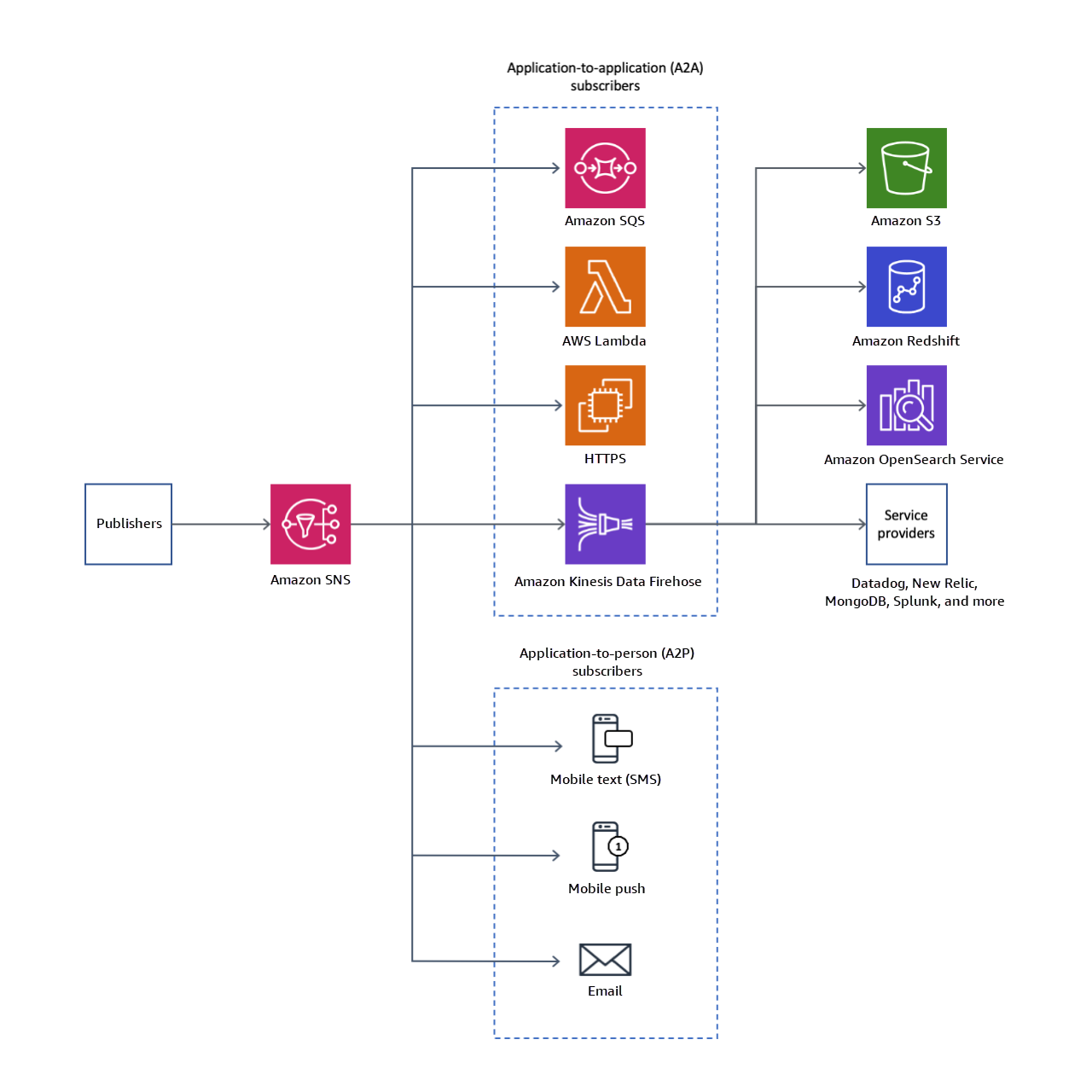
- SNS에서 구독자에게 게시할 수 있는 것은
- SNS에서 직접 이메일을 보낼 수 있고
- SMS 및 모바일 알림을 보낼 수도
- 지정된 HTTP 또는 HTTPS 엔드포인트로 직접 데이터를 보낼 수도 있음
- SQS와 같은 특정 AWS 서비스와 통합하여 메시지를 대기열로 직접 보낼 수도
- 메시지를 수신한 후 함수가 코드를 수행하도록 Lambda에 보내거나, Firehose를 통해 데이터를 Amazon S3나 Redshift로 보낼 수도 있음
- SNS는 다양한 AWS 서비스에서 데이터를 직접 수신하기도 한다. AWS에서 알림이 발생하면 아래와 같은 서비스가 지정된 SNS 주제로 알림을 보낸다는 것을 기억할 것.
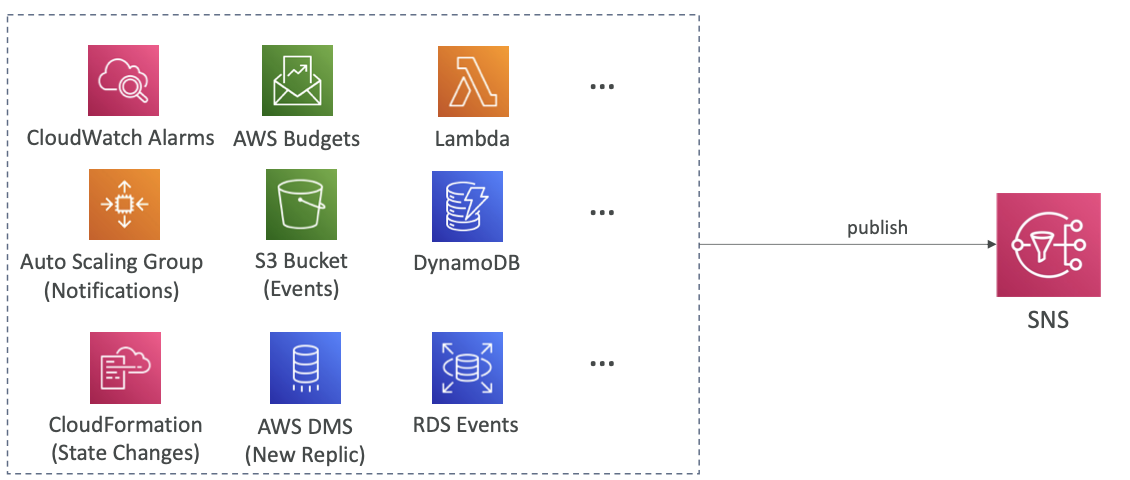
❓ How to publish
- Topic Publish (using the SDK)
- 주제 생성
- 하나 또는 여러 개의 구독 생성
- SNS에 주제 게시
- Direct Publish (for mobile apps SDK)
- 플랫폼 애플리케이션 생성
- 플랫폼 엔드포인트 생성
- 플랫폼 엔드포인트에 게시
- 수신 가능 대상은 Google GCM, Apple APNS, Amazon ADM 등이 있음
🔒 Security
SQS와 동일하다.
- Encryption:
- 전송 중에 HTTPS API를 사용하여 암호화
- KMS 키를 사용한 저장 데이터 암호화
- 클라이언트가 직접 암호화/복호화를 수행하려면 클라이언트 측 암호화
- Access Contorls: : IAM 정책을 사용하여 SNS API 액세스를 제어
- SNS Access Policies (similar to S3 bucket policies):
- SNS 주제에 교차 계정 액세스에 유용
- 다른 서비스(S3 등)가 SNS 주제에 쓸 수 있도록 허용하는데 유용
🪭 SNS + SQS: Fan Out
메시지를 여러 SQS 대기열에 보내고 싶은데 모든 SQS 대기열에 개별적으로 메시지를 보내면 문제가 발생할 수 있다. 예를 들면 애플리케이션이 중간에 비정상적으로 종료될 수 있고, 전송에 실패하거나 SQS 대기열이 더 추가될 수 있다. 이런 경우 팬아웃 패턴을 사용하게 된다.
일단 SNS 주제에 메시지를 전송한 후 원하는 수의 SQS 대기열이 이 SNS 주제를 구독하게 하는 것이다. 이 대기열들은 구독자로서 SNS로 들어오는 모든 메시지를 받게 된다. 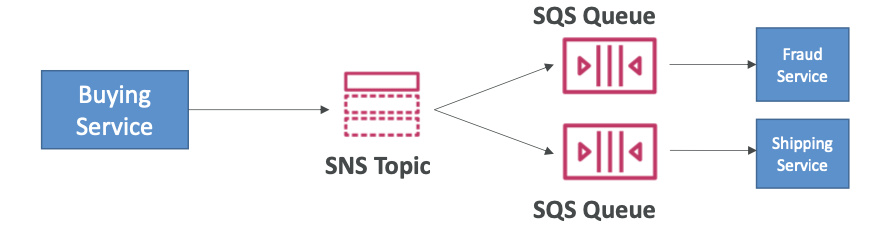
예를 들어, 구매 서비스가 있고 두 개의 SQS 대기열로 메시지를 보낸다고 가정해보자. 이때 직접 보내는 대신 메시지를 하나의 SNS 주제로 보내고 대기열들이 이 SNS 주제를 구독하여 사기 탐지 서비스나 배송 서비스가 각자의 SQS 대기열에서 모든 메시지를 읽어들이게 하는 것이다.
- SNS에서 한 번 푸시하면 구독하는 모든 SQS 대기열에서 수신
- 완전히 분리된 모델이며 데이터도 손실되지 않음
- SQS로 작업을 재시도할 수 있을 뿐만 아니라 데이터 지속성, 지연 처리도 수행할 수 있음
- 시간이 지남에 따라 SNS 주제를 구독하도록 더 많은 SQS 대기열을 추가할 수 있음
- 이를 위해서는 SQS 액세스 정책이 SNS 쓰기 작업을 할 수 있도록 허용해야 함
- 리전 간 전달 가능 - 다른 리전의 SQS 대기열과 함께 작동함
Application: S3 Events to multiple queues
이벤트 세 개를 여러 대기열에 넣는 경우
- S3 이벤트 규칙에 제한 조건이 있다. 객체 생성과 같은 이벤트 유형과 images/와 같은 접두사 조합이 동일하다면 S3 규칙은 한 가지여야 한다.
- 만약 여러 대기열에 동일한 S3 이벤트 알림을 보내고 싶다면 팬아웃 패턴을 사용해야 한다.
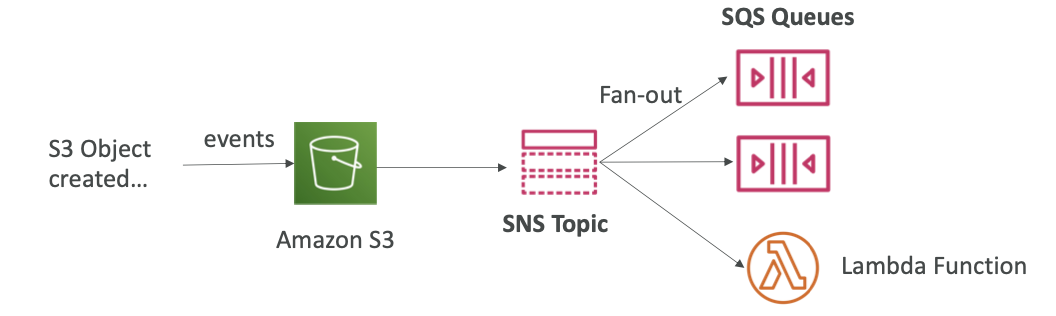
S3 객체를 생성하여 S3 버킷에 이벤트를 생성하고, 이 이벤트를 SNS 주제로 전송한 후 팬아웃 패턴으로 많은 SQS 대기열이 SNS 주제를 구독하게 한다. 또한 다른 유형의 애플리케이션, 이메일, Lambda 함수 등도 구독할 수 있다.
팬아웃 패턴을 통해 Amazon S3에서 발생하는 이벤트의 메시지가 여러 다른 목적지에 도달할 수 있게 된다.
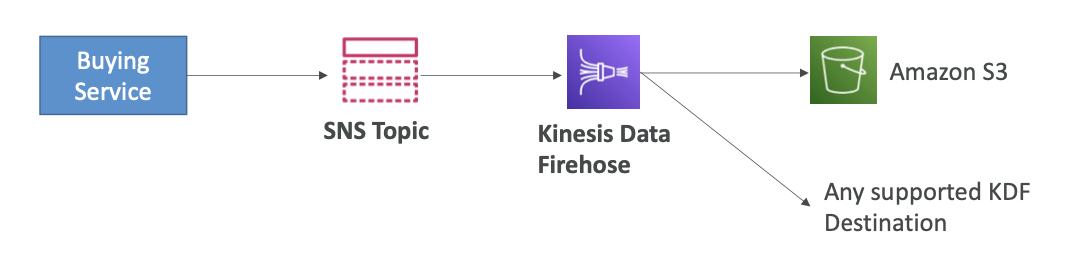
Application: SNS to Amazon S3 through Kinesis Data Firehose
- SNS는 Kinesis로 메시지를 보낼 수 있으므로 다음과 같은 솔루션 아키텍처를 구성할 수 있다.
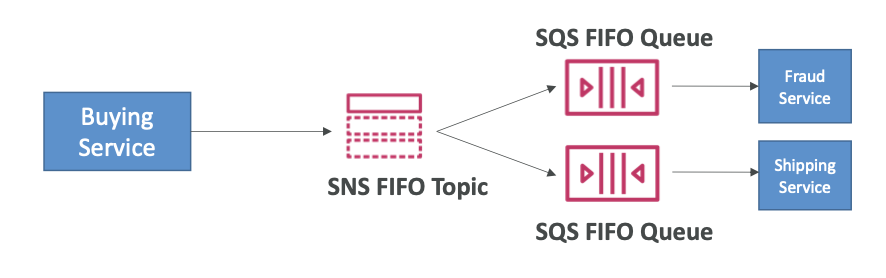
👆 FIFO Topic
- FIFO = First In First Out (ordering of messages in the topic)
- SQS FIFO 특징과 유사하다.
- 메시지 그룹 ID에 따른 순서 지정 (동일한 그룹에 속한 모든 메시지는 순서가 지정됨)
- 중복 제거 ID를 활용하거나 내용을 비교하여 중복 데이터 제거
- SQS FIFO 대기열만 구독자로 설정할 수 있음
- 제한된 처리량 (SQS FIFO와 동일한 처리량)
SNS FIFO + SQS FIFO: Fan Out
- 팬아웃, 순서 지정, 중복 제거 기능이 필요한 경우 SNS FIFO와 SQS FIFO를 조합하여 원하는 기능을 구현할 수 있다.
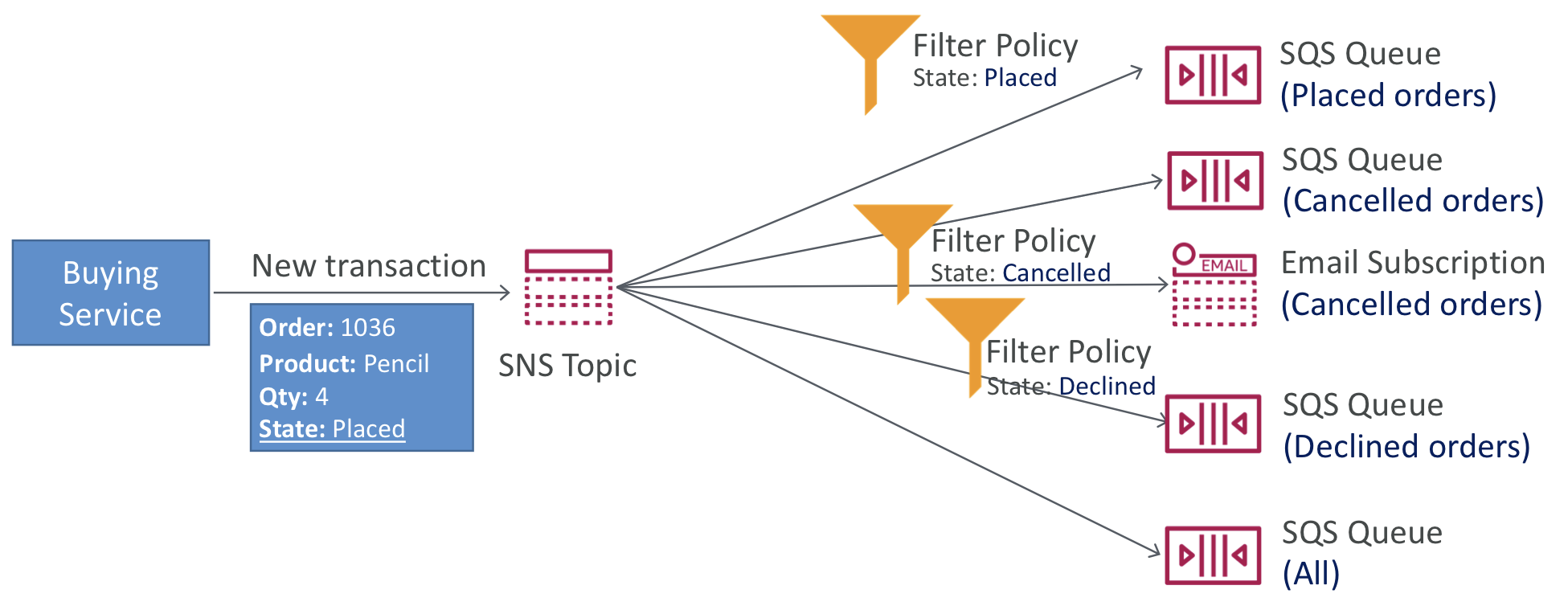
Message Filtering
- SNS 주제의 구독으로 전송되는 메시지를 필터링하기 위해 JSON 정책을 사용
- 구독에 필터 정책이 없는 경우, 해당 구독은 모든 메시지를 수신
3. Amazon Kinesis
- Kinesis를 활용하면 실시간 스트리밍 데이터를 쉽게 수집하고 처리하여 분석할 수 있다.
- 애플리케이션 로그, 메트릭, 웹사이트 클릭 스트림, IoT 원격 측정 데이터 등의 실시간 데이터를 수집한다.
- Kinesis Data Streams: 데이터 스트림을 캡처, 처리 및 저장
- Kinesis Data Firehose: 데이터 스트림을 AWS 데이터 저장소로 로드
- Kinesis Data Analytics: SQL 또는 Apache Flink를 사용하여 데이터 스트림을 분석
- Kinesis Video Streams: 비디오 스트림을 캡처, 처리 및 저장
📈 Kinesis Data Streams
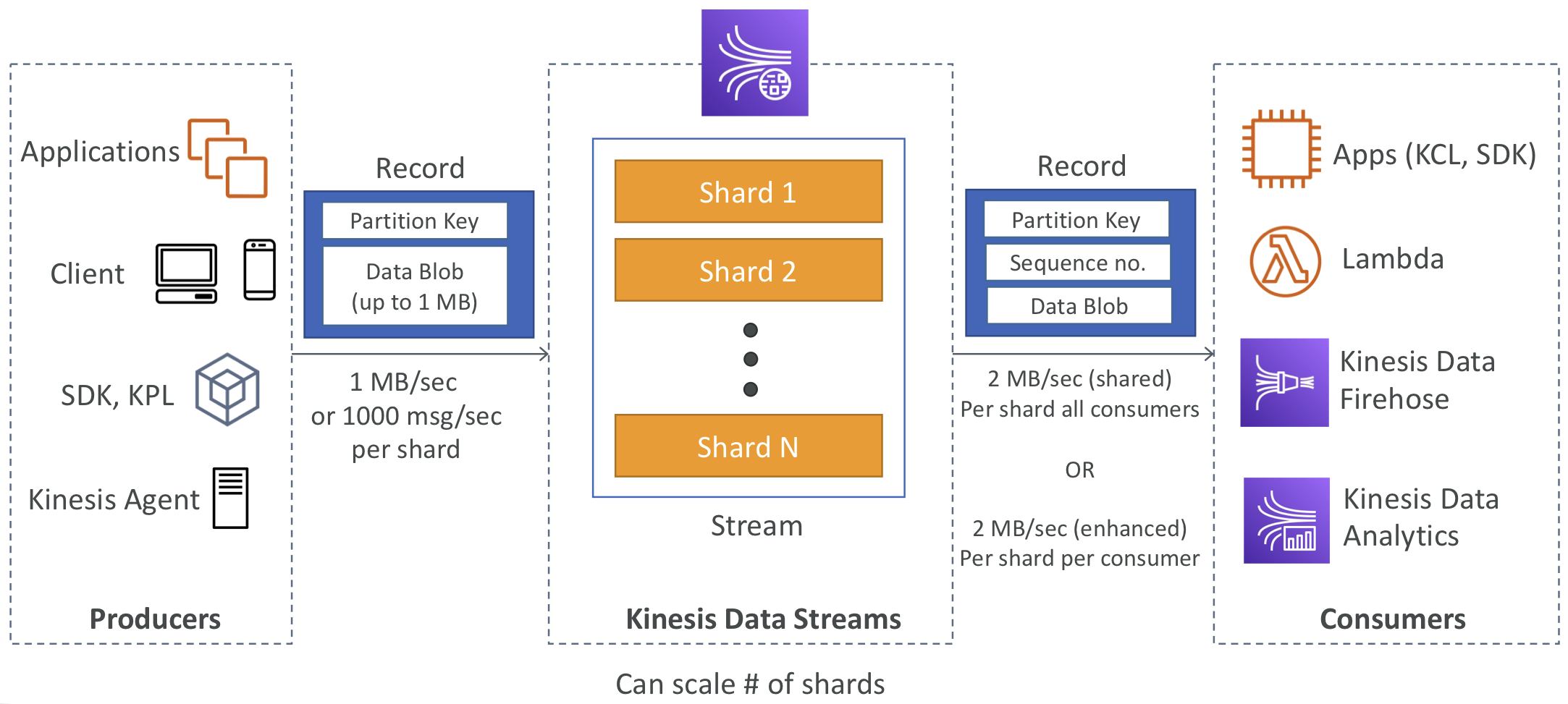
- 보존 기간은 1일부터 365일 사이로 설정할 수 있음
- 데이터를 재처리하거나 확인할 수 있음
- Kinesis로 데이터가 삽입된 후에는 삭제할 수 없음 (불변성)
- 동일한 파티션을 공유하는 데이터는 동일한 샤드로 전송됨 (순서 보장). 키를 기반으로 데이터를 정렬할 수 있음
- 생산자: AWS SDK, Kinesis Producer Library (KPL), Kinesis Agent
- 소비자:
- 직접 작성: Kinesis Client Library (KCL), AWS SDK
- 관리형: AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics
Capacity Modes
-
Provisioned mode:
- 사전에 프로비저닝할 샤드 수를 정하고 수동으로 또는 API를 사용하여 스케일 조정
- 각 샤드당 1MB/s 로 레코드를 받아들임 (또는 초당 1000개의 레코드)
- 출력량의 경우 각 샤드당 2MB/s (일반적인 소비 유형 또는 향상된 팬아웃 방식에 적용)
- 샤드를 프로비저닝할 때마다 시간당 비용이 부과됨
-
On-demand mode:
- 용량을 사전에 프로비저닝하거나 관리할 필요 없음
- 기본적으로는 1초당 4MB/s의 처리량 또는 초당 4000개의 레코드를 처리
- 지난 30일간의 관측된 최대 처리량에 기반하여 자동으로 스케일 조정
- 시간당 스트림당 송수신 데이터양(GB 단위)에 따라 비용 부과
Security
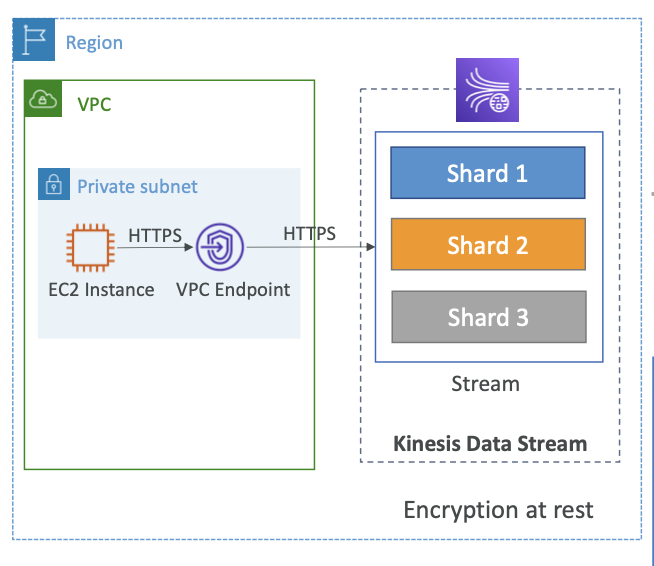
- IAM 정책을 사용하여 액세스 및 권한 부여 제어
- HTTPS 엔드포인트를 통한 전송 중 데이터 암호화
- KMS를 사용하여 데이터 정지 상태에서의 암호화
- 클라이언트 측에서 데이터의 암호화/복호화 구현 가능 (더 어려움)
- VPC 내에서 액세스하기 위해 Kinesis에 대한 VPC 엔드포인트 사용 가능
- 모든 API 요청은 CloudTrail을 사용하여 모니터링 가능
🚿 Kinesis Data Firehose
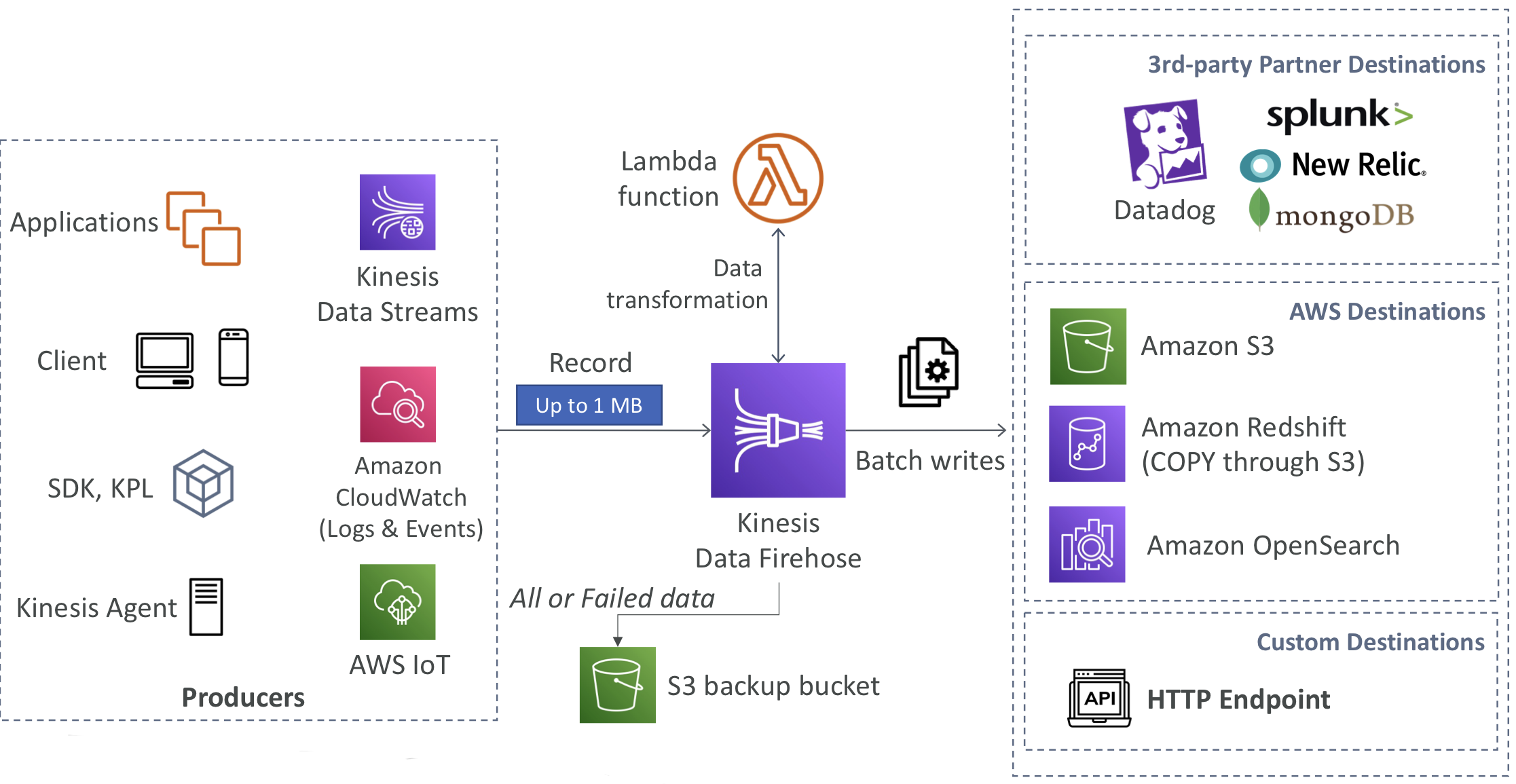
- 완전 관리형 서비스로, 관리 작업이 필요하지 않으며 자동 스케일링 및 서버리스 기능 제공
- AWS: Redshift / Amazon S3 / OpenSearch와 통합
- 서드파티 파트너: Splunk / MongoDB / DataDog / NewRelic 등과 통합
- 커스텀: HTTP 엔드포인트로 데이터 전송 가능
- Firehose를 통과하는 데이터에 대해서만 비용 지불
- 거의 실시간으로 데이터 처리
- 전체 배치가 아닌 경우 최소 60초의 지연 시간
- 또는 한 번에 적어도 1MB 이상의 데이터가 있을 때까지 기다려야 함
- 다양한 데이터 형식, 전환, 변환, 압축을 지원
- AWS Lambda를 사용하여 사용자 정의 데이터 변환 가능
- 실패한 데이터 또는 모든 데이터를 백업용 S3 버킷으로 전송할 수 있음
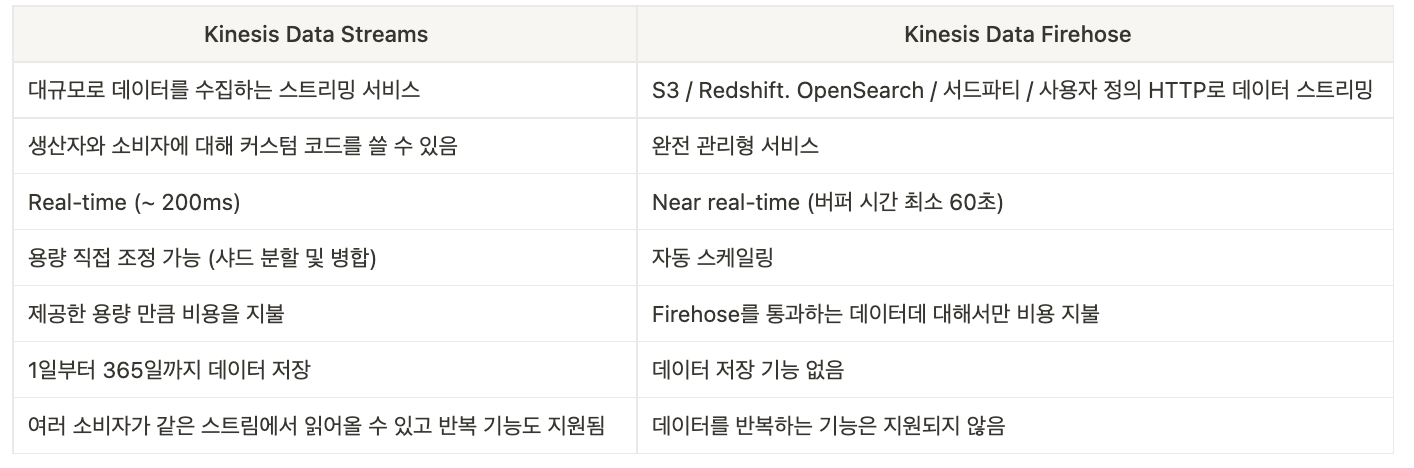
🤓 Kinesis Data Streams vs Firehose
1️⃣ Ordering data
Ordering data into Kinesis
도로에서 정기적으로 GPS 위치를 AWS로 보내는 100대의 트럭(truck_1, truck_2, ... truck_100)이 있다고 가정해보자. 각 트럭의 순서대로 데이터를 소비해서 트럭의 이동을 정확하게 추적하고 그 경로를 순서대로 확인하고자 할 때 어떻게 Kinesis로 데이터를 전달할까?
"truck_id"값을 "파티션 키"로 사용하여 데이터를 Kinesis로 보내면 된다. 동일한 파티션 키는 항상 동일한 샤드로 전송되므로 각 트럭의 데이터를 정확한 순서로 처리할 수 있다.
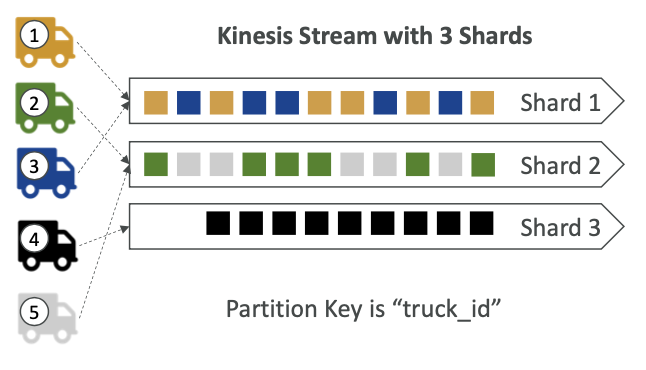
트럭1과 트럭3의 데이터는 항상 샤드 1에 정렬되고, 샤드 2에는 트럭2와 트럭5의 데이터가, 샤드 3에는 트럭4의 데이터만 전송된다.
트럭과 각각의 샤드 사이가 직접적으로 연결된 것은 아니다. Kinesis가 파티션 키를 해시해서 어느 샤드로 보낼지 결정하는 것이다. 다시 말해 안정된 파티션 키를 얻으면 바로 트럭이 그 데이터를 같은 샤드로 전달하고, 그러면 샤드 레벨에서 각 트럭의 순서에 따른 데이터를 얻을 수 있게 된다.
Ordering data into SQS
- SQS Standard에는 순서가 없다. 하지만 SQS FIFO라는 선입선출 방식이 있다.
- SQS FIFO의 그룹 ID를 사용하지 않으면 모든 메시지가 소비되는 방식은 보내진 순서에 따르며 소비자는 하나만 존재한다.

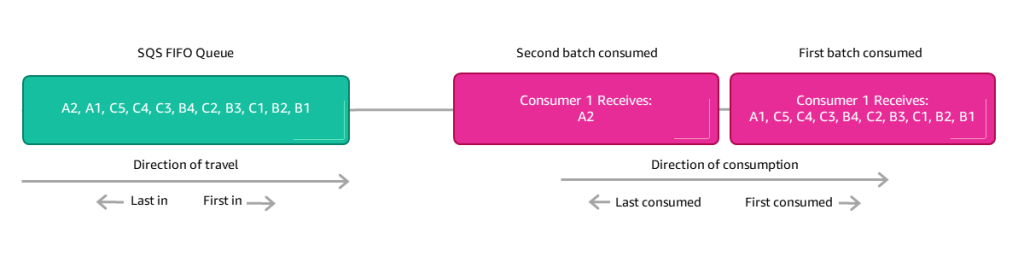
- 만약 소비자 숫자를 확장하고 서로 연관된 메시지를 그룹화하는 경우 그룹 ID를 사용할 수 있다. (Kinesis의 파티션 키와 비슷한 개념)
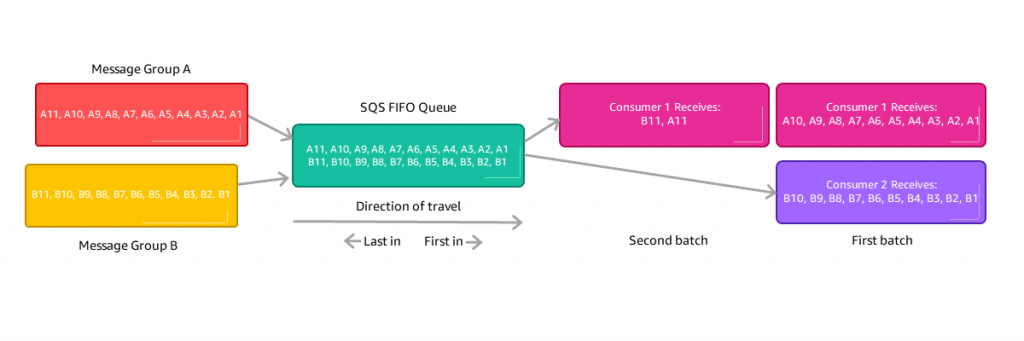
Kinesis vs SQS ordering
100대의 트럭, 5개의 Kinesis 샤드, 1개의 SQS FIFO를 가정해보자.
-
Kinesis Data Streams:
- 평균적으로 각 샤드당 20대의 트럭이 할당
- 각 샤드 내에서 트럭의 데이터는 순서대로 처리
- 병렬로 처리할 수 있는 최대 소비자 수는 5개
- 최대 5MB/s의 데이터를 수신할 수 있음
-
SQS FIFO:
- SQS FIFO 대기열이 하나만 있음
- 각 트럭은 고유한 그룹 ID를 가지며, 따라서 100개의 다른 그룹이 생성됨
- 100개의 그룹 ID로 인해 최대 100명의 소비자를 가질 수 있음
- 최대 메시지 처리 속도는 초당 300개의 메시지이며, 배치 처리를 사용할 경우 3000개의 메시지를 처리할 수 있음
경우에 따라 적절한 모델은 달라지며 SQS FIFO는 그룹 ID에 따른 동적 소비자 수를 원할 때 좋은 모델이다. Kinesis Data Streams를 사용하는 경우는 많은 데이터를 전송하고, 데이터 스트림에 샤드당 데이터를 정렬할 때 유용하다.
🤓 SQS vs SNS vs Kinesis
SQS
- 소비자가 SQS 대기열에서 메시지를 요청하여 데이터를 가져오는 (pull) 모델
- 데이터를 처리한 후 소비자가 대기열에서 삭제하여 다른 소비자가 읽을 수 없도록 함
- 소비자의 수에는 제한이 없음
- 관리형 서비스이기 때문에 처리량을 프로비저닝할 필요가 없음
- FIFO 대기열을 사용해야 순서를 보장할 수 있음
- 메시지에 지연 기능이 있음
SNS
- 게시/구독 모델로 다수의 구독자에게 데이터를 푸시하면 메시지의 복사본을 받게 됨
- SNS 주제별로 12,500,000 구독자를 가질 수 있음
- 데이터가 SNS에 전송되면 지속되지 않음 (제대로 전달되지 않으면 데이터를 잃을 수 있음)
- 100,000 개의 주제로 확장 가능함
- 처리량을 프로비저닝할 필요 없음
- SQS와 결합하여 팬아웃 아키텍처 패턴을 이용할 수 있음
- SNS FIFO 주제를 SQS FIFO 대기열과 결합할 수 있음
Kinesis
- Standard: 소비자가 Kinesis로부터 데이터를 가져옴 (pull). 샤드당 2 MB/s
- Enhanced-fan out: Kinesis가 소비자에게 데이터를 푸시함. 샤드 하나에 소비자당 2 MB/s
- Kinesis 데이터 스트림에서는 데이터가 지속되기 때문에 데이터를 다시 재생할 수 있음
- 실시간 빅데이터 분석, ETL 등에 사용됨
- X days 후에 데이터가 만료됨
- 프로비저닝 모드 혹은 온디맨드 용량 모드가 있음
4. Amazon MQ
- SQS, SNS는 AWS 고유한 프로토콜으로서 "클라우드 네이티브" 서비스이다. (각자 사용하는 API 세트가 따로 있음)
- 온프레미스에서 실행되는 전통적인 애플리케이션은 MQTT, AMQP, STOMP, Openwire, WSS 등의 오픈 프로토콜을 사용할 수 있다.
- 애플리케이션을 클라우드에 마이그레이션하는 경우에는, SQS와 SNS 프로토콜 혹은 API를 사용하도록 애플리케이션을 재구성하는 대신에 MQTT, AMQP와 같은 기존에 쓰던 프로토콜을 사용하고 싶을 때에는 Amazon MQ를 사용할 수 있다.
- Amazon MQ는 RabbitMQ, ActiveMQ를 위한 관리형 메시지 브로커 서비스이다.
- Amazon MQ는 SQS 및 SNS만큼 확장성이 크지 않다.
- Amazon MQ는 서버에서 실행되며, 장애 조치를 위해 Multi-AZ에서 실행할 수 있다.
- Amazon MQ에는 SQS와 유사한 대기열 기능 및 SNS와 유사한 주제 기능이 모두 제공된다.
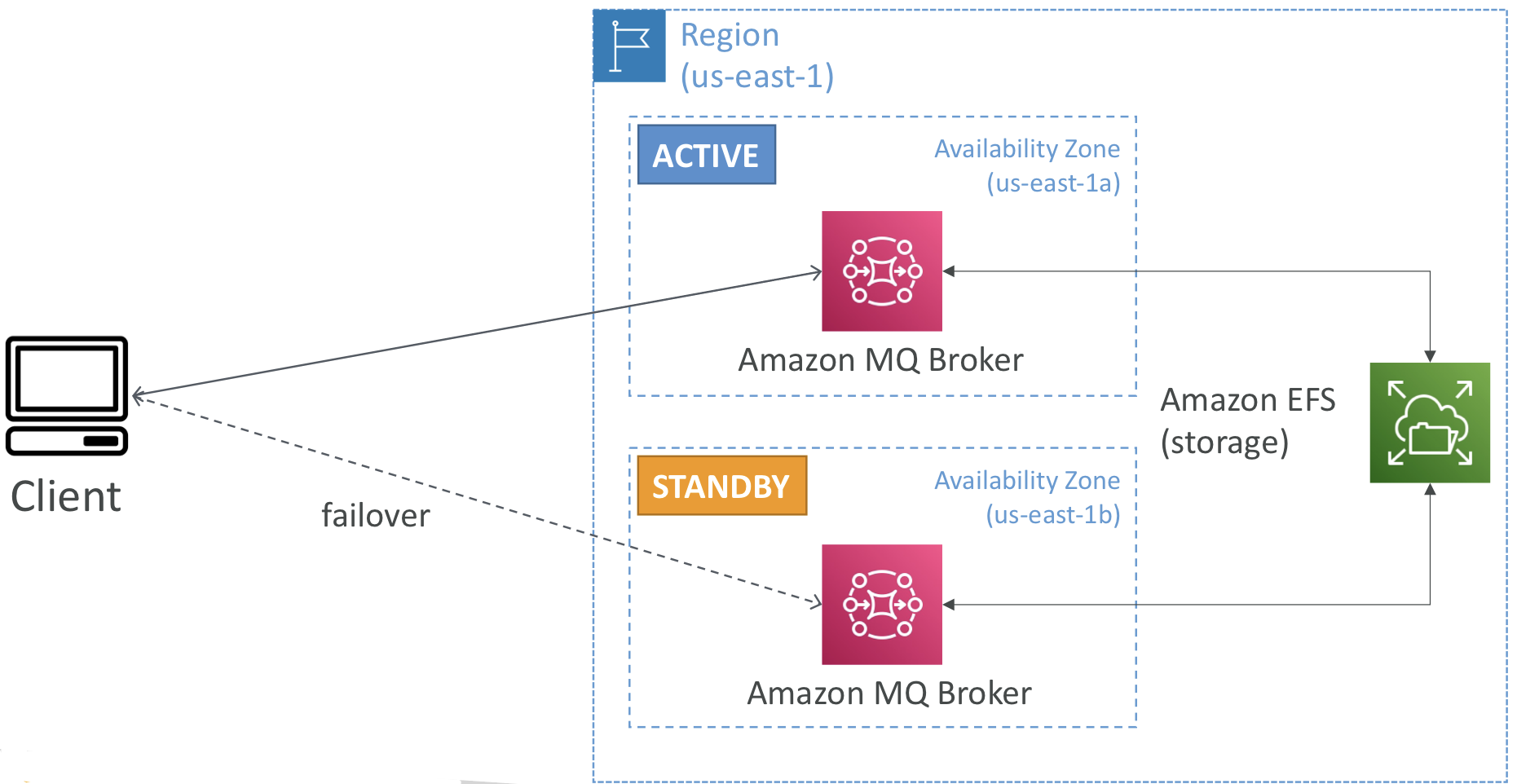
us-esat-1 리전에 us-east-1a, us-east-1b 두개의 가용 영역이 있다고 가정해보자. 영역 하나는 활성 상태, 다른 영역은 대기 상태이다.
두 영역에 각각 활성, 대기 상태인 Amazon MQ 브로커를 추가하고, 장애 조치를 위해 백엔드 스토리지에 Amazon EFS도 정의한다.
(EFS: 네트워크 파일 시스템. 다중 가용 영역에 마운트할 수 있음)
이렇게 설정하면 장애 조치가 일어날 때마다 대기 상태 영역 역시 Amazon EFS에 마운트되므로 첫 번째 활성 대기열과 동일한 데이터를 가질 수 있고 따라서 장애 조치도 올바르게 실행될 것이다.
클라이언트가 Amazon MQ 브로커와 통신해서 장애 조치가 실행되는 경우에도 Amazon EFS 덕분에 데이터가 저장된다.
