[AWS] RDS, Aurora, & ElasticCache
참고 자료
- https://www.udemy.com/course/best-aws-certified-solutions-architect-associate/
- https://www.udemy.com/course/best-aws-certified-developer-associate/
1. RDS
- RDS: 관계형 데이터베이스 서비스(Relational Database Service)의 약자.
- SQL을 쿼리 언어로 사용하는 데이터베이스용 관리형 데이터베이스 서비스.
- AWS에서 관리되는 클라우드 상의 데이터베이스를 생성할 수 있도록 해줌.
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Aurora (AWS Proprietary database)
❔ Advantage over using RDS versus deploying DB on EC2
- RDS는 관리형 서비스이며, AWS는 데이터베이스 뿐만 아니라 다양한 서비스를 제공함.
- 프로비저닝, 기본 운영체제 패치 자동화
- 지속적인 백업과 특정 타임스탬프로의 복원 (특정 시점 복원)
- 모니터링 대시보드
- 읽기 성능 향상을 위한 읽기 전용 복제본
- 재해 복구를 위한 다중 AZ 설정
- 유지 관리 기간에 업그레이드 가능
- 수직 및 수평 스케일링 기능
- EBS(gp2 또는 io1)로 지원되는 스토리지
- 한 가지 단점은, RDS 인스턴스에 SSH로 접속할 수 없음.
⏫️ RDS – Storage Auto Scaling
- Helps you increase storage on your RDS DB instance dynamically
- 데이터베이스 스토리지가 부족해지고, RDS 스토리지 Auto Scaling 기능이 활성화되어 있으면 RDS가 이를 감지하여 자동으로 스토리지를 확장해 줌.
- 데이터베이스 스토리지를 수동으로 스케일링하는 작업을 피할 수 있음.
- 최대 스토리지 임계값(스토리지의 최대 제한)을 설정해야 함.
- 다음의 경우에 자동으로 스토리지를 수정함.
- 스토리지의 남은 공간이 10% 미만인 경우
- 스토리지 부족 상태가 5분 이상 지속
- 마지막 수정 이후 6시간이 지난 경우
- 워크로드를 예측할 수 없는 애플리케이션에서 유용함.
- 모든 RDS 데이터베이스 엔진 (MariaDB, MySQL, PostgreSQL, SQL Server, Oracle)을 지원.
🗂️ RDS Read Replicas for read scalability
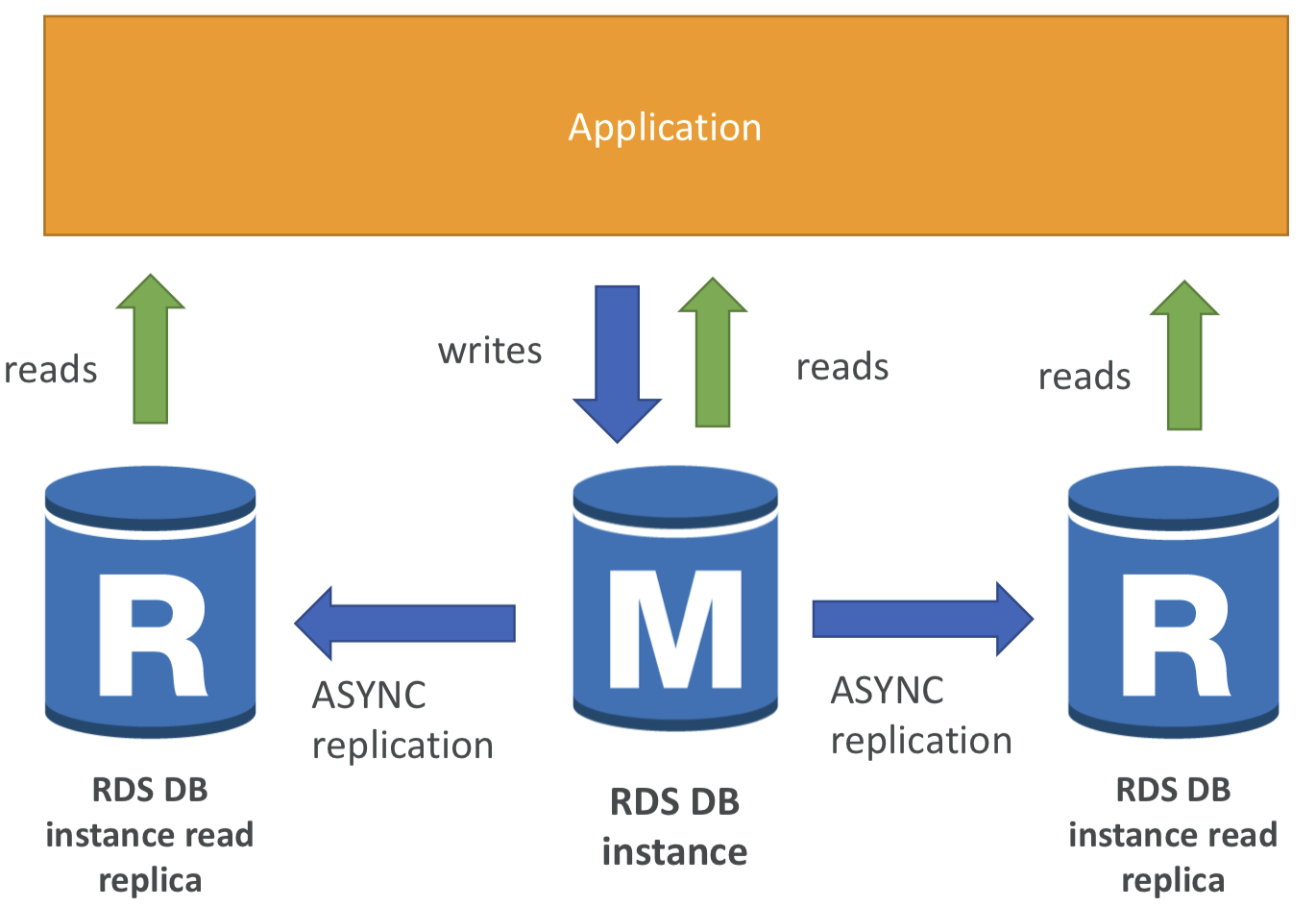
- 읽기 전용 복제본을 최대 15개까지 생성 가능.
- 동일한 가용 영역 또는 가용 영역이나 리전을 걸쳐 생성 가능.
- 복제는 비동기 방식으로 진행됨. 즉, 읽기가 일관적으로 유지됨.
- 복제본은 자체 데이터베이스로 승격될 수 있음.
- 읽기 전용 복제본을 사용하려는 경우에는 주요 애플리케이션은 모든 연결을 업데이트 해야하며 이를 통해 RDS 클러스터 상의 읽기 전용 복제본 전체 목록을 활용할 수 있음.
Use Cases
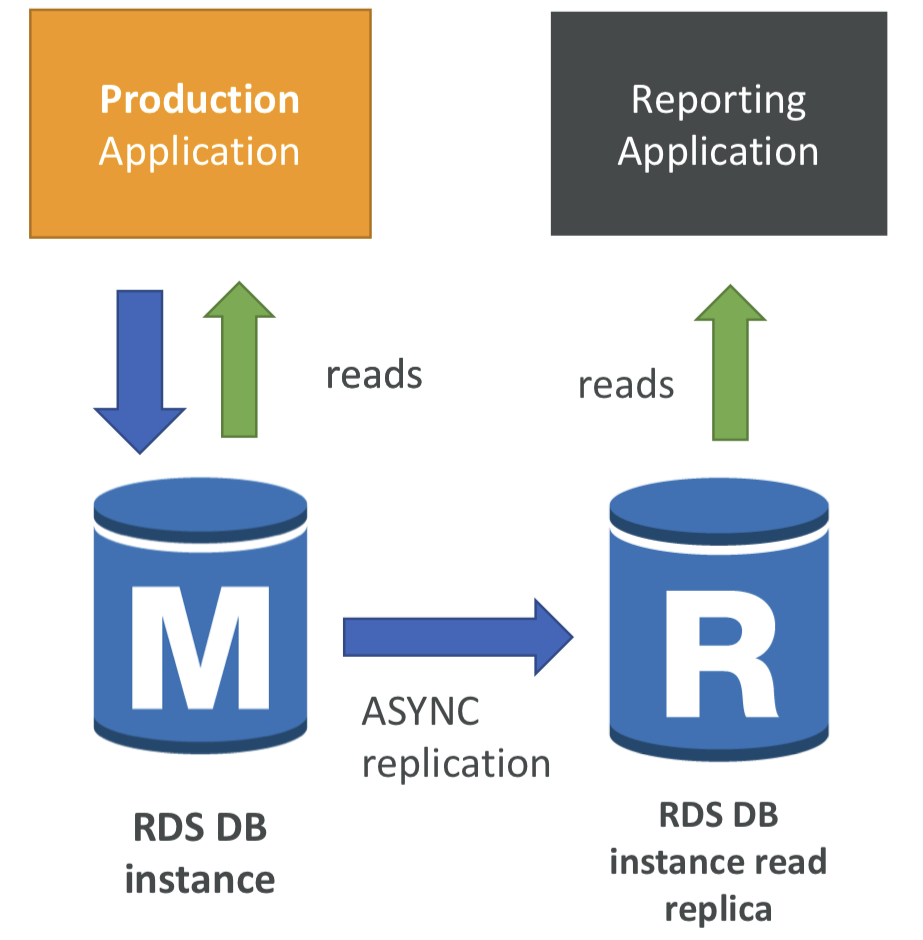
정상적인 작업 부하를 처리하는 프로덕션 데이터베이스가 있다고 가정. 데이터를 기반으로 몇 가지 보고와 분석을 실시하고자 함. 새로운 작업 부하를 처리하기 위해 읽기 전용 복제본을 생성.
읽기 전용 복제본은 SELECT(=읽기) 명령문에만 사용. (INSERT, UPDATE, DELETE는 제외)
Network Cost
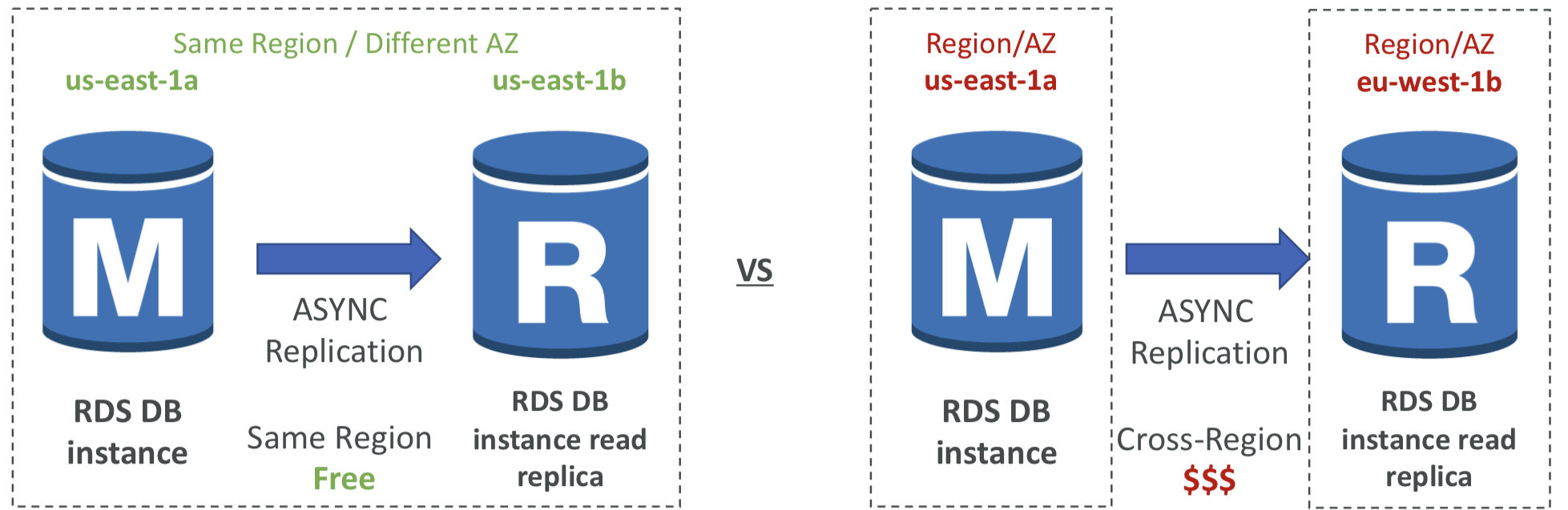
AWS에서는 데이터가 한 AZ에서 다른 AZ로 이동할 때 네트워크 비용이 발생한다. 하지만, 동일한 리전 내에서의 RDS 읽기 전용 복제본에 대해서는 해당 비용을 지불하지 않는다.
📍 RDS Multi AZ (Disaster Recovery)
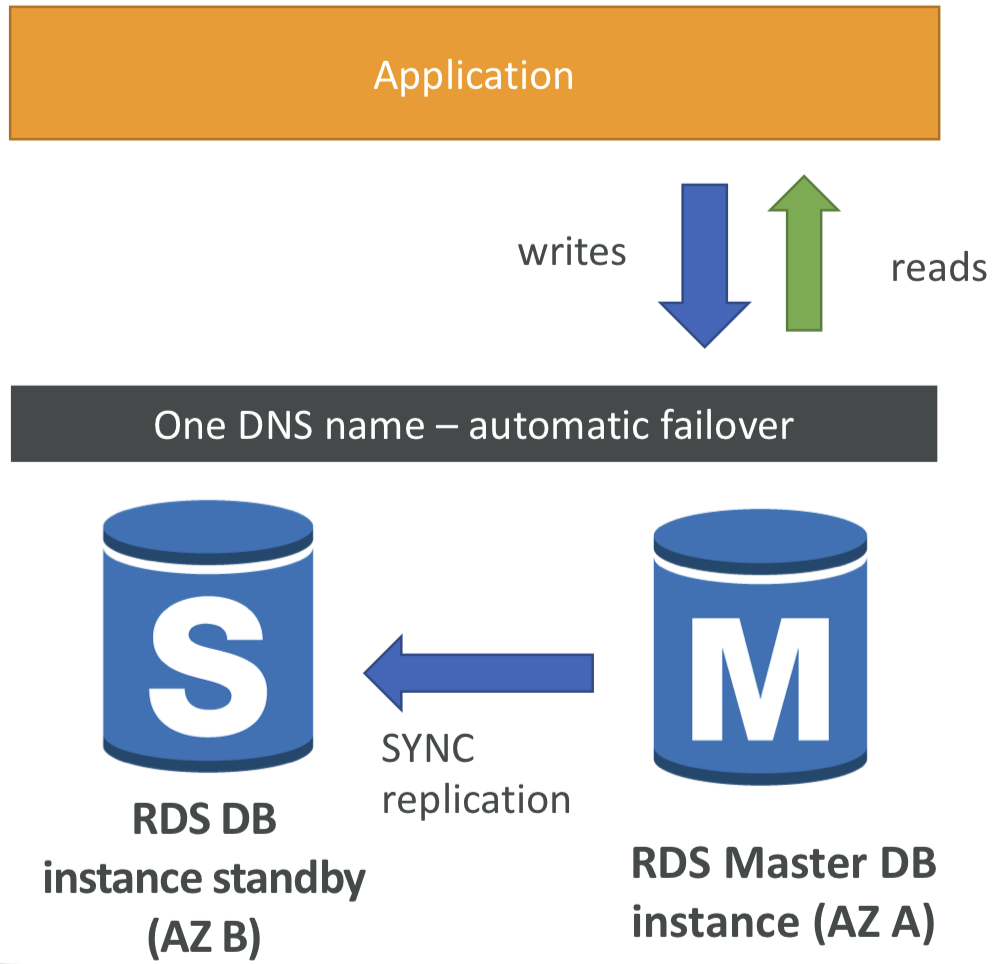
- 동기식 복제
- 하나의 DNS 이름 - automatic app failover to stanby
- 가용성 향상
- AZ 손실, 네트워크 손실, 인스턴스 또는 스토리지 장애 발생 시 페일오버 - 스탠바이 데이터베이스가 새로운 마스터가 될 수 있도록 함.
- 애플리케이션에 수동으로 조치를 취할 필요가 없음.
- 스케일링에는 사용되지 않음.
참고: 읽기 전용 복제본은 재해 복구(DR)을 위해 다중 AZ로 설정될 수 있음.
🪄 RDS – From Single-AZ to Multi-AZ
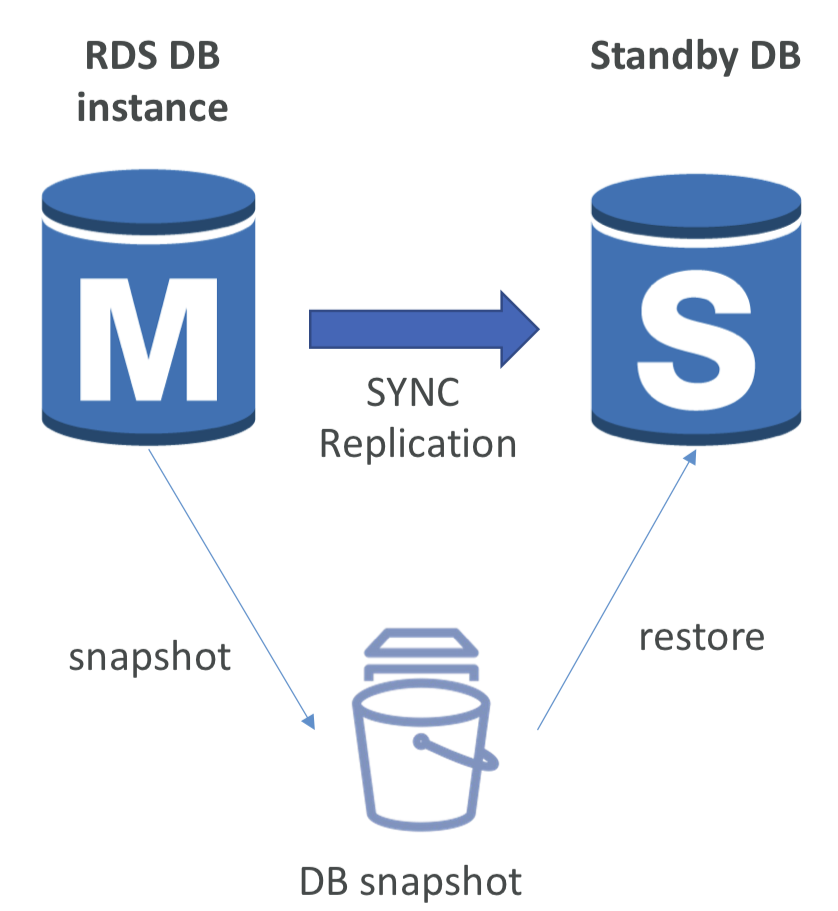
- 다운타임이 없는 운영 (DB를 중지할 필요 없음)
- 데이터베이스에 대해 "수정"을 클릭하고 활성화시키기만 하면 됨.
- 내부적으로는 다음이 수행됨.
- 기본 데이터베이스의 RDS가 자동으로 스냅샷 생성
- 이 스냅샷에서 새로운 DB가 새로운 가용 영역에 복원됨
- 두 개의 데이터베이스 간에 동기화가 설정
🏷️ RDS Custom
- Oracle & Microsoft SQL Server DatabaseOS: RDS Custom 덕분에 데이터베이스 사용자 지정 기능에 액세스할 수 있음
- RDS: AWS에서의 데이터베이스 설정, 운영 및 확장을 자동화
- Custom: 기저 데이터베이스와 운영 체제에 액세스할 수 있음
- 내부 설정 구성 (Configure setting)
- 패치 설치
- 네이티브 기능 활성화
- SSH 또는 SSM 세션 관리자를 통해 RDS 뒤에 있는 기저 EC2 인스턴스에 액세스 가능
- 사용자 지정 설정을 사용하려면 RDS가 수시로 자동화, 유지 관리 또는 스케일링과 같은 작업을 수행하지 않도록 자동화를 꺼두는 것이 좋음
- 기저 EC2 인스턴스에 액세스가 가능하므로 문제가 쉽게 발생할 수 있기 때문에 데이터베이스 스냅샷을 만들어두는 것이 권장됨.
- RDS vs RDS Custom
- RDS: AWS가 데이터베이스 및 OS 전체를 관리
- RDS Custom: Oracle과 Microsoft SQL Server에서만 사용 가능, 기저 운영 체제와 데이터베이스에 대한 관리자 권한 전체를 가짐.
2. Aurora
- Aurora는 AWS 고유 기술로 오픈 소스는 아님.
- Postgres와 MySQL이 호환됨.
- Aurora는 "AWS 클라우드 최적화"되었으며, RDS의 MySQL에 비해 5배 높은 성능이고, RDS의 Postgres에 비해 3배 높은 성능.
- Aurora 스토리지는 자동으로 10GB 단위로 증가하며, 최대 128TB까지 확장할 수 있음.
- Aurora는 최대 15개의 복제본을 가질 수 있으며, 복제 과정은 MySQL보다 빠름 (10ms 미만의 복제 지연).
- 페일오버(Failover)는 즉시 이루어지고 가용성이 높음.
- 비용은 RDS에 비해 약 20% 정도 높지만 스케일링 측면에서 훨씬 효율적임.
🔖 Aurora High Availability and Read Scaling
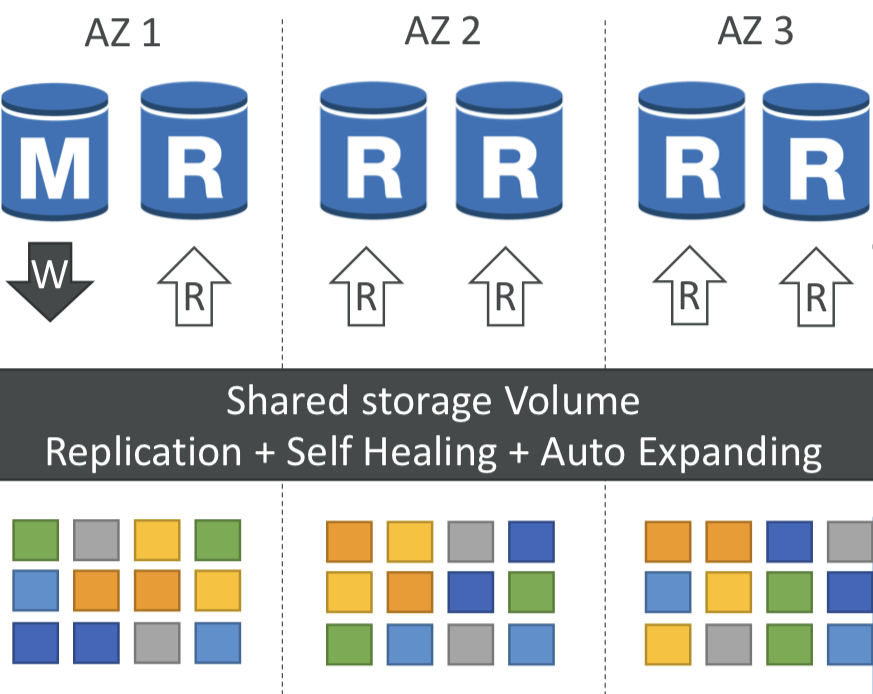
- 3개의 가용영역에 걸쳐 6개의 데이터 복사본을 저장.
- 쓰기 작업을 위해서는 6개의 사본 중 4개만 있으면 됨. (즉, AZ 하나가 작동하지 않아도 괜찮음.)
- 읽기 작업을 위해서는 6개의 사본 중 3개만 있으면 됨. (즉, 읽기 가용성이 높음.)
- 백엔드에서 P2P(peer-to-peer) 복제를 통한 자가 복구 진행.
- 단일 볼륨에 의존하지 않고 수 백 개의 볼륨 사용함.
- 하나의 Aurora 인스턴스가 쓰기 작업을 수행함. (master)
- 마스터의 자동 장애 조치(failover)는 30초 이내에 이루어짐.
- 마스터 외에 읽기를 제공하는 읽기 전용 복제본을 15개까지 둘 수 있음.
- Cross Region 복제 지원
마스터는 하나, 복제본은 여러 개, 스토리지 복제, 작은 블록 단위로 자가 복구 또는 확장이 일어남.
📚 Aurora DB Cluster
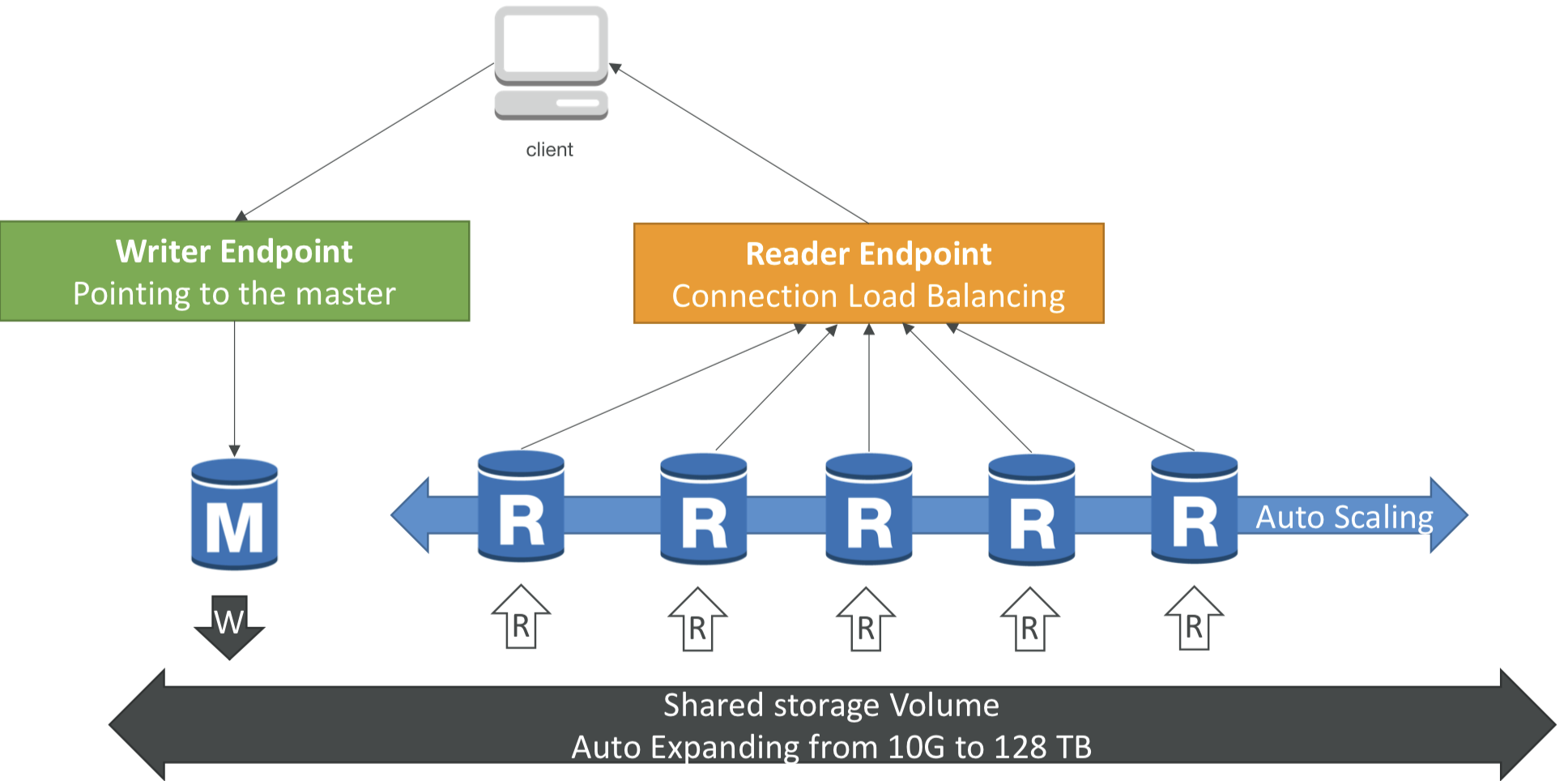
- writer endpoint
- reader endpoint
- 자동 스케일링, 자동 확장되는 공유 스토리지 볼륨
- 로드 밸런싱이 statement level이 아니라 connection level에서 일어난다는 사실을 기억하기!
🔍 Features of Aurora
- 자동 장애 조치(failover)
- 백업 및 복구
- 격리 및 보안
- 산업 규정 준수
- 버튼 한 번으로 확장 가능 (push-button scaling)
- 제로 다운타임 자동 패치 설치
- 고급 모니터링
- 정기적인 유지 보수
- Backtrack(백트랙): 백업을 사용하지 않고 언제든 데이터 복원 가능
⏫️ Aurora Replicas - Auto Scaling
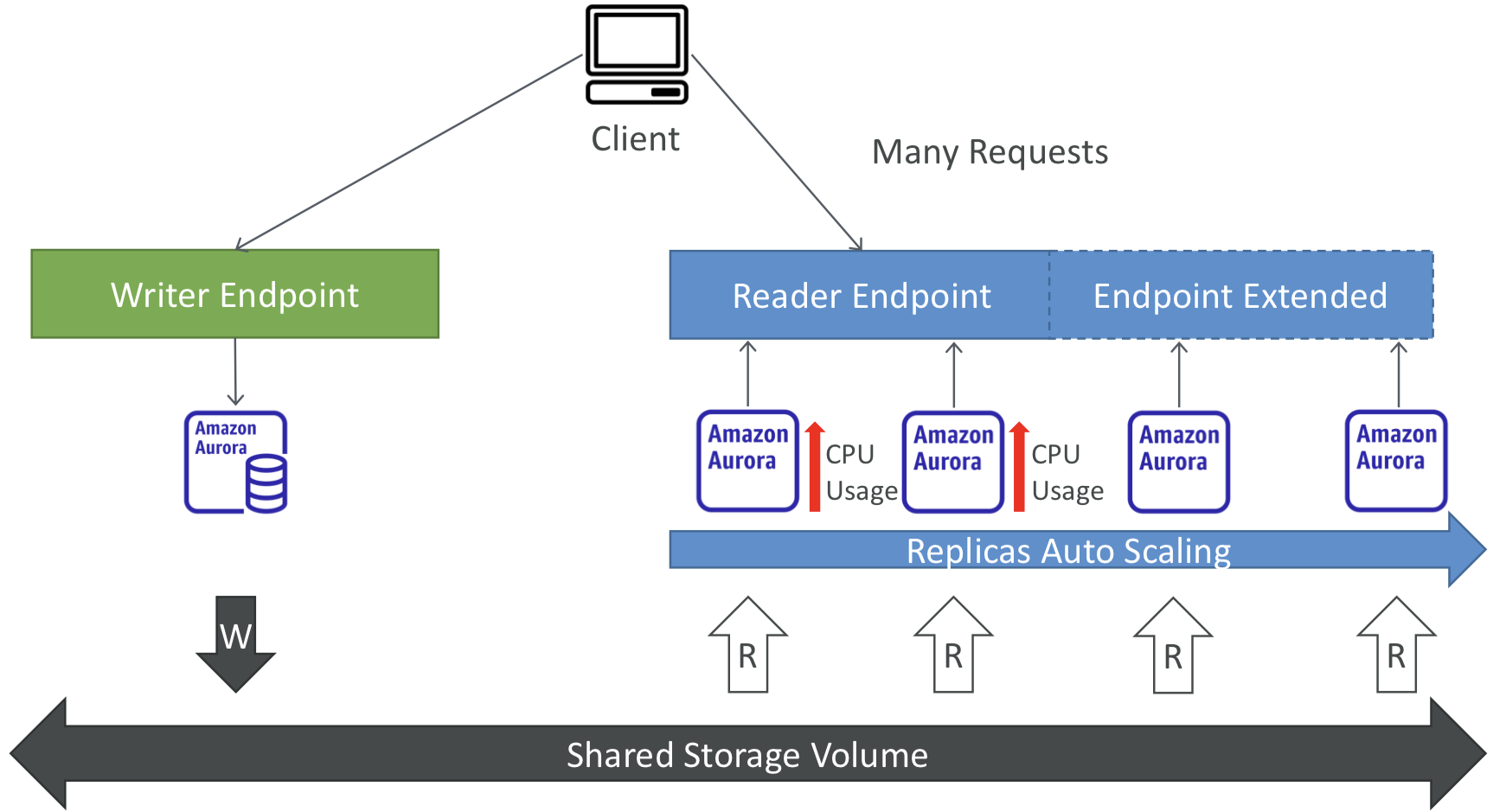
🪧 Aurora – Custom Endpoints
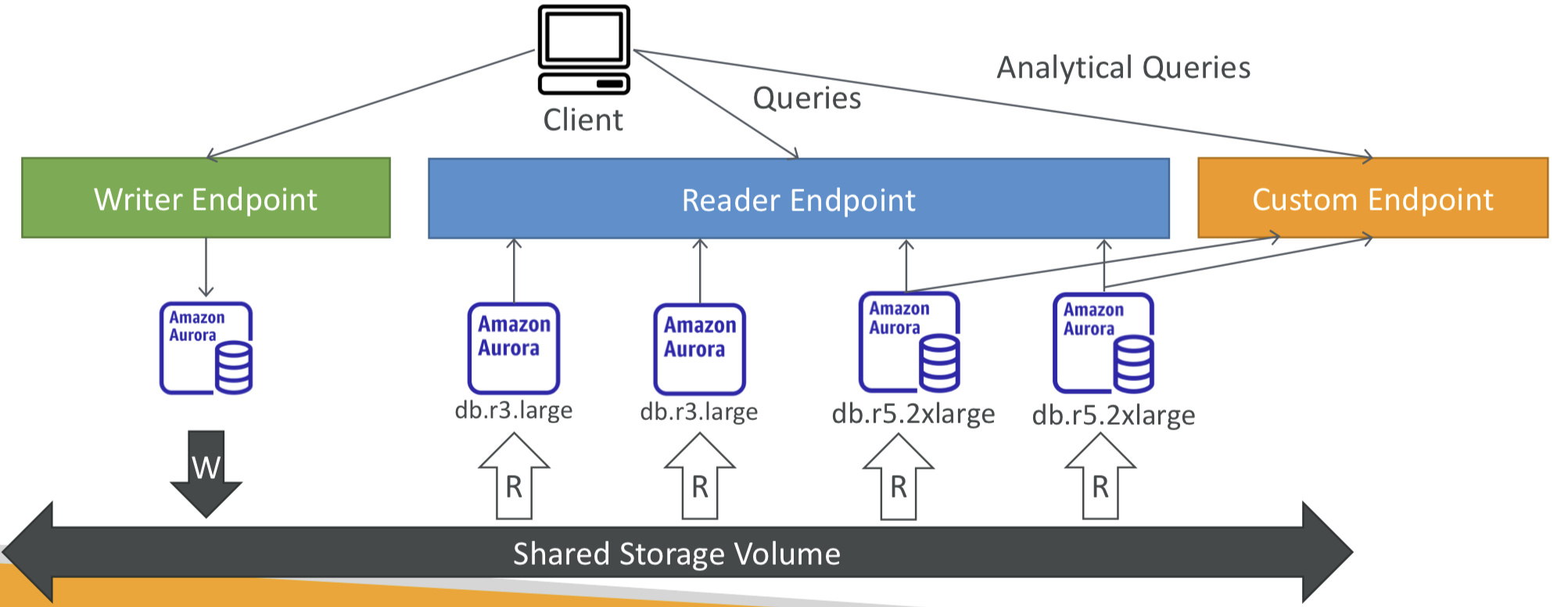
- 일부 Aurora 인스턴스를 사용자 지정 엔드포인트로 정의할 수 있음.
- ex. 특정 복사본에서 분석 쿼리를 실행.
- 사용자 지정 엔드포인트를 정의한 후에는 일반적으로 Reader 엔드포인트는 사용되지 않음.
❌ Aurora Serverless
- 실제 사용량이 기반하여 자동으로 데이터베이스 인스턴스화 및 자동 스케일링이 이루어짐.
- 비정기적, 간헐적, 또는 예측할 수 없는 워크로드에 적합함.
- 용량 계획이 필요하지 않음.
- 초당 결제로 인해 더 경제적일 수 있음.
🔗 Aurora Multi-Master
- 쓰기 노드의 즉각적 장애 조치(failover)가 필요한 경우. (쓰기 노드에 높은 가용성을 갖추고자 할 때)
- Aurora 클러스터의 모든 노드에서 읽기 및 쓰기를 수행.
- 읽기 전용 복제본을 새로운 마스터로 승격하는 것과는 다르다.
🌐 Global Aurora
Aurora Cross Region Read Replicas
- 재해 복구에 유용
- 간단하게 구성 가능
Aurora Global Database (recommended)
- 하나의 기본 리전 (읽기 / 쓰기 모두 가능)
- 최대 5개의 읽기 전용 리전. 복제 지연이 1초 미만.
- 각 보조 리전당 최대 16개의 읽기 전용 복사본 생성 가능
- 지연 시간을 줄이는 데 도움됨.
- 재해 복구 목적으로 다른 리전을 승격하는데 필요한 복구 시간 목표(RTO)는 1분 미만.
- 리전에 걸쳐 데이터를 복제하는데 걸리는 시간은 평균 1초 미만!!
🤖 Aurora Machine Learning
- ML 기반 예측을 SQL 인터페이스로 애플리케이션에 적용하는 것.
- Aurora와 다양한 AWS 머신 러닝 서비스 간에 쉽고 최적화된 방식으로 안전하게 통합할 수 있음.
- 지원되는 서비스:
- Amazon SageMaker (모든 ML 모델과 함께 사용)
- Amazon Comprehend (감정 분석에 사용)
- Aurora ML를 위해 머신 러닝 경험은 필요하지 않음.
- 사용 사례: 사기 감지, 광고 타게팅, 감정 분석, 제품 추천 등
🗃️ Backups
RDS Backups
자동 백업
- 매일 자동으로 데이터베이스 유지 관리 시간에 데이터베이스 전체 백업
- 매 5분마다 트랜잭션 로그 백업
- 가장 오래된 백업부터 5분 전 백업까지 어느 시점으로도 복원 가능
- 자동 백업 보유 기간은 1일부터 35일까지 설정 가능. 이 기능을 비활성화하면 0으로 설정하면 됨.
수동 DB 스냅샷
- 사용자가 수동으로 트리거해야 함
- 원하는 기간 동안 백업을 보존함
팁: 중지된 RDS 데이터베이스에서도 여전히 스토리지 비용이 발생한다. 따라서 오랜 기간 중지할 계획이 있다면 스냅샷을 생성하고 원본 데이터베이스는 삭제한 뒤 DB가 필요할 때에 스냅샷을 복원하는 것이 좋다.
Aurora Backups
자동 백업
- 1일부터 35일까지 (비활성화 불가능)
- 지정 시간 복구 기능 - 정해진 시간 범위 내의 어느 시점으로도 복구 가능
수동 DB 스냅샷
- 사용자가 수동으로 트리거
- 원하는 기간동안 백업 보유 가능
🗄️ RDS & Aurora Restore options
- RDS / Aurora 백업 또는 스냅샷을 새로운 데이터베이스로 복원할 수 있음.
- S3에서 MySQL RDS DB 복원
- 온프레미스 DB의 백업을 생성
- 객체 스토리지인 Amazon S3에 저장
- MySQL을 실행하는 새로운 RDS 인스턴스로 백업 파일 복원
- S3에서 MySQL Aurora 클러스터 복원
- 온프레미스 DB의 백업 생성 - Percona XtraBackup 소프트웨어 사용
- 백업 파일을 Amazon S3에 저장
- MySQL을 실행하는 새로운 Aurora 클러스터로 백업 파일 복원
📑 Aurora Database Cloning
- 기존 데이터베이스로부터 새로운 Aurora DB 클러스터 생성
- 스냅샷 및 복원보다 빠름
- 새 DB 클러스터는 원래 클러스터와 동일한 클러스터 볼륨과 데이터를 사용하며, 데이터 업데이트가 끝나면 변경된다.
- 데이터베이스 복제는 매우 빠르고 비용 면에서 효율적
- 프로덕션(production) 데이터베이스에 영향을 주지 않고 스테이징(staging) 데이터베이스를 생성하는데 유용함
🔒 RDS & Aurora Security
- At-rest encryption
- AWS KMS를 사용하여 데이터베이스 마스터 및 복제본 암호화 - 이는 데이터베이스를 처음 실행할 때 정의됨.
- 마스터가 암호화되지 않은 경우 읽기 복제본을 암호화할 수 없음.
- 암호화되지 않은 기존 데이터베이스를 암호화하려면 DB 스냅샷을 통해 암호화된 DB 형태로 데이터베이스 스냅샷을 복원해야 함.
- In-flight encryption: 기본적으로 TLS 사용 가능. 클라이언트는 AWS TLS 루트 인증서 사용해야 함.
- IAM 인증:사용자 이름/암호 대신 IAM Role을 사용하여 DB에 연결 가능.
- 보안 그룹:RDS/AUrora DB에 대한 네트워크 액세스 제어
- SSH 액세스 불가능 (RDS Custom 제외)
- 감사 로그 활성화 - CloudWatch Logs로 전송하여 장기간 보관 가능.
🚧 Amazon RDS Proxy
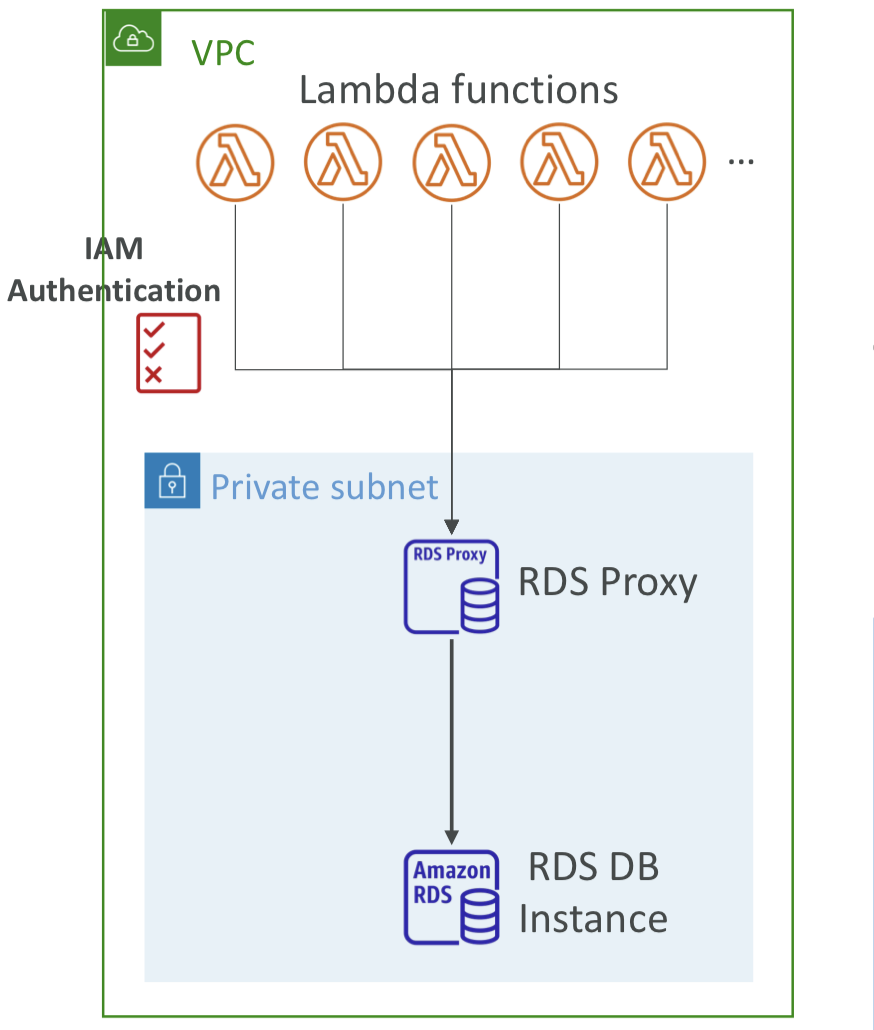
- Fully managed database proxy for RDS
- 애플리케이션이 데이터베이스 내에서 데이터베이스 연결 풀을 형성하고 공유할 수 있음. (애플리케이션을 RDS DB 인스턴스에 일일이 연결하는 대신 프록시에 연결하면 프록시가 하나의 풀에 연결을 모아서 RDS DB 인스턴스로 연결함)
- 데이터베이스 리소스에 가해지는 부하를 줄이고 (ex. CPU, RAM), 데이터베이스에 개방된 연결과 타임아웃을 최소화하여 데이터베이스의 효율성을 향상
- RDS 프록시는 완전한 서버리스로 오토 스케일링이 가능해 용량을 관리할 필요가 없고 가용성이 높음. 다중 AZ도 지원.
- RDS와 Aurora의 장애 조치 시간을 66%까지 줄일 수 있음
- RDS (MySQL, PostgreSQL, MariaDB, MS SQL Server) 및 Aurora (MySQL, PostgreSQL)를 지원
- 애플리케이션의 코드를 변경하지 않아도 됨
- DB에 대한 IAM 인증을 강제함으로써 IAM 인증을 통해서만 RDS DB 인스턴스에 연결할 수 있음. 이때 자격 증명은 AWS Secrets Manager에 안전하게 저장됨.
- RDS 프록시는 퍼블릭 액세스가 절대 불가능함. (VPC에서만 접근 가능)
3. ElastiCache
- RDS와 동일한 방식으로 관계형 데이터베이스를 관리할 수 있음
- ElastiCache는 Redis 또는 Memcached와 같은 캐시 기술을 관리할 수 있도록 함.
- Cache: 매우 높은 성능과 낮은 지연 시간을 가진 인메모리 데이터베이스
- 읽기 집약적인 워크로드에서 데이터베이스의 부하를 줄이는데 도움
- 애플리케이션을 stateless로 만드는데 도움이 됨
- AWS는 OS 유지 관리/패치, 최적화, 설정, 구성, 모니터링, 장애 복구 및 백업을 처리
- ElastiCache를 사용하는 것은 애플리케이션 코드 변경이 많이 필요
⚙️ ElastiCache Solution Architecture
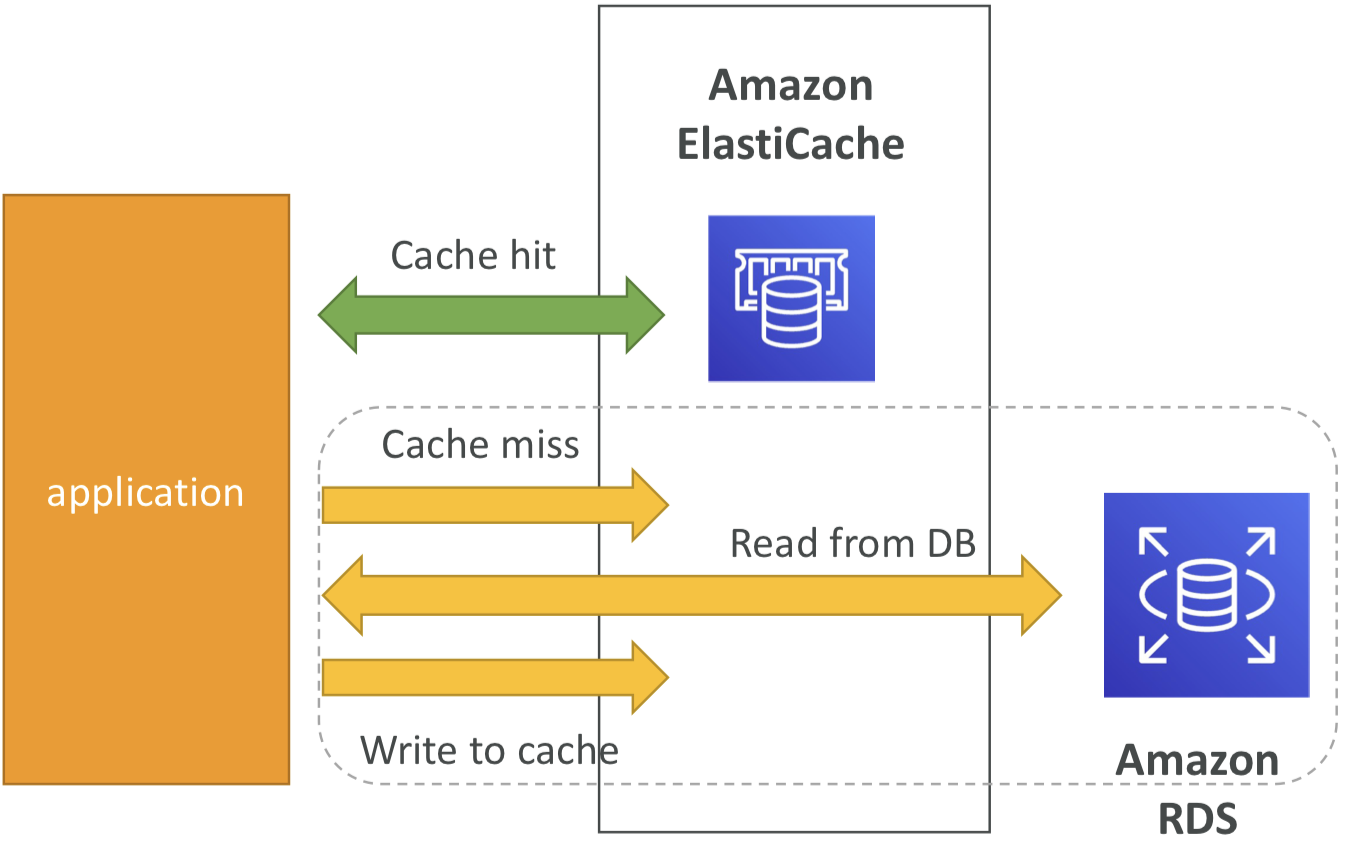
DB Cache
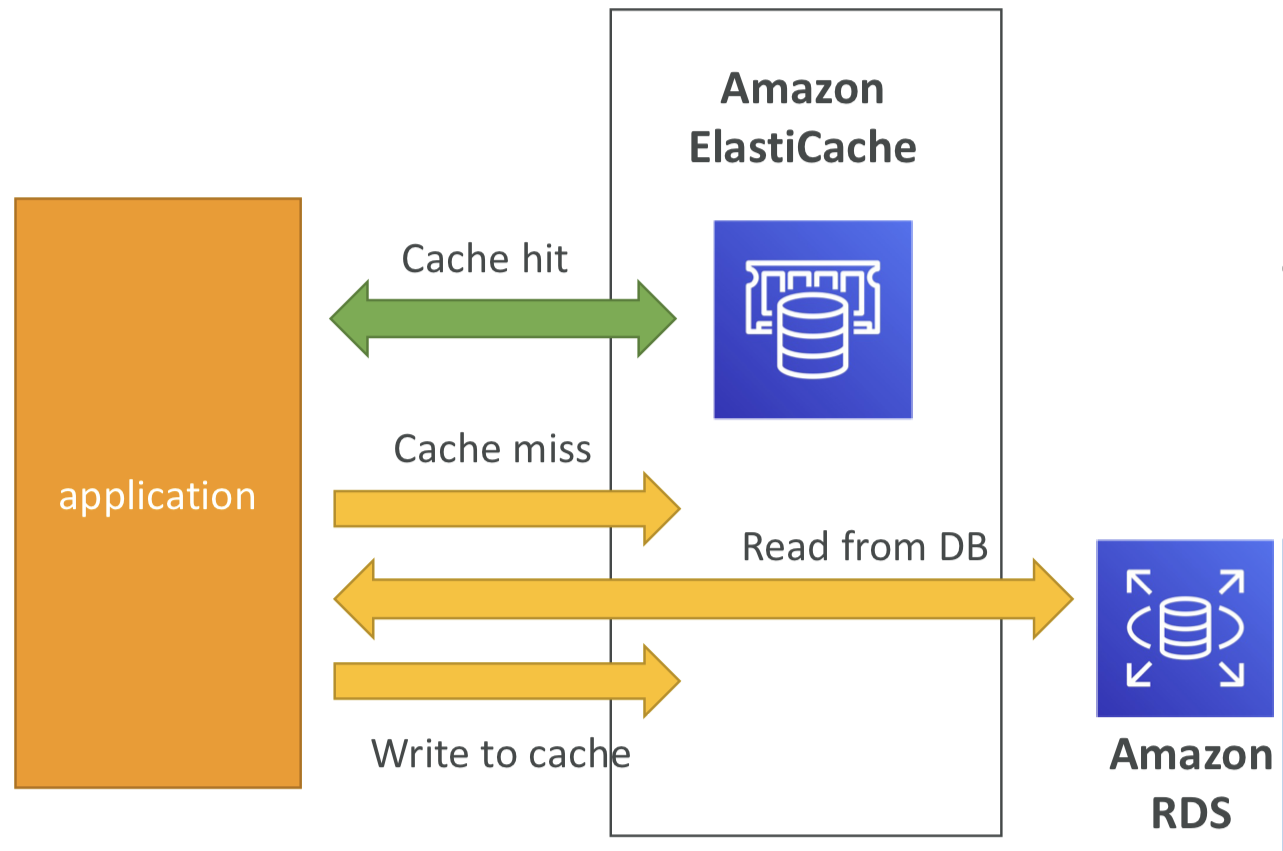
- 애플리케이션은 ElastiCache에 쿼리를 보내고, ElastiCache에 데이터가 없는 경우 RDS에서 가져와 ElastiCache에 저장.
- RDS의 부하를 완화하는 데 도움
- 캐시는 가장 최신 데이터만 사용되도록 만료 전략(invalidation strategy)을 가져야 함
User Session Store
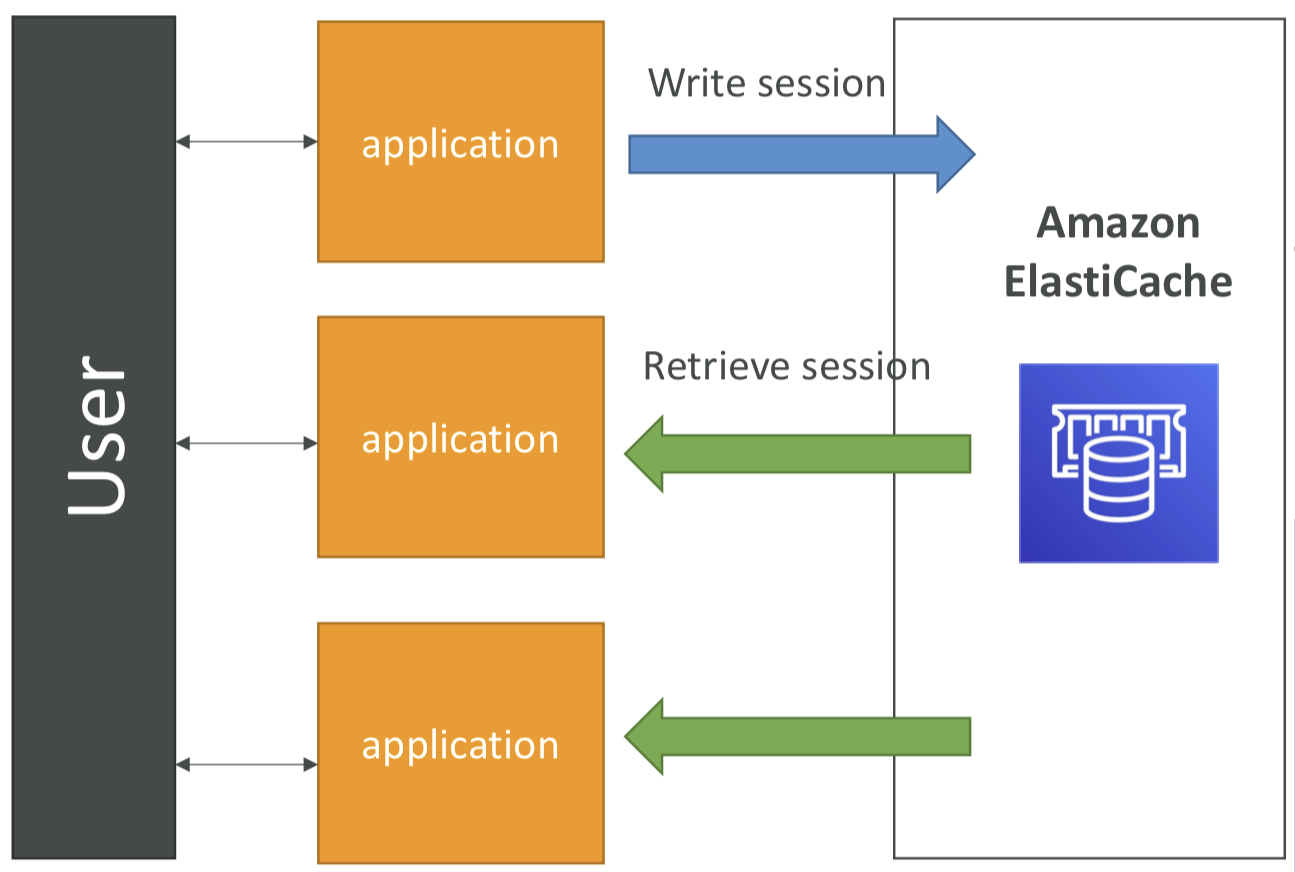
사용자가 애플리케이션 중 하나에 로그인하면 애플리케이션은 세션 데이터를 ElastiCache에 기록한다. 사용자가 이후 애플리케이션의 다른 인스턴스로 리디렉션 되면 애플리케이션은 ElastiCache에서 직접 세션 캐시를 검색하고 사용자는 계속 로그인한 상태로 한번 더 로그인할 필요가 없음.
ℹ️ Redis vs Memcached
Redis

- 자동 장애 조치(Auto-Failover)를 위한 Multi AZ
- 읽기 스케일링에 사용되며 가용성이 높은 읽기 전용 복제본
- AOF 지속성을 통한 데이터 내구성
- 백업 및 복원 기능
- 세트(Sets)와 정렬 세트(Sorted Sets)를 지원함
Memcached
- 데이터 파티셔닝(sharding)을 위한 다중 노드 사용
- 가용성이 높지 않고 복제도 발생하지 않음
- 지속적인 캐시가 아님
- 백업 및 복원 기능이 없음
- 멀티스레드 아키텍처
🔐 Cache Security
- ElatiCache의 모든 캐시는
- IAM 인증을 지원하지 않음
- ElastiCache에서 정의할 IAM 정책은 AWS API 수준의 보안에서만 사용
- Redis AUTH
- Redis 클러스터를 생성할 때 비밀번호나 토큰을 설정할 수 있음
- 캐시에 사용할 수 있는 보안 그룹에 대한 추가적인 수준의 보안
- 전송 중 암호화를 위해 SSL 보안을 지원할 수 있음
- Memcached
- 좀 더 높은 수준인 SASL 기반 인증을 지원
📇 Patterns for ElastiCache
- Lazy Loading: 모든 읽기 데이터를 캐시에 저장하며, 캐시 데이터는 오래된 상태(stale)가 될 수 있음
- Write Through: 데이터를 데이터베이스에 쓸 때 캐시에도 데이터를 추가하거나 업데이트 하여 캐시 데이터에 오래된 데이터가 없음
- Session Store: 임시 세션 데이터를 캐시에 저장 (TTL 기능 사용)
📄 Redis Use Case
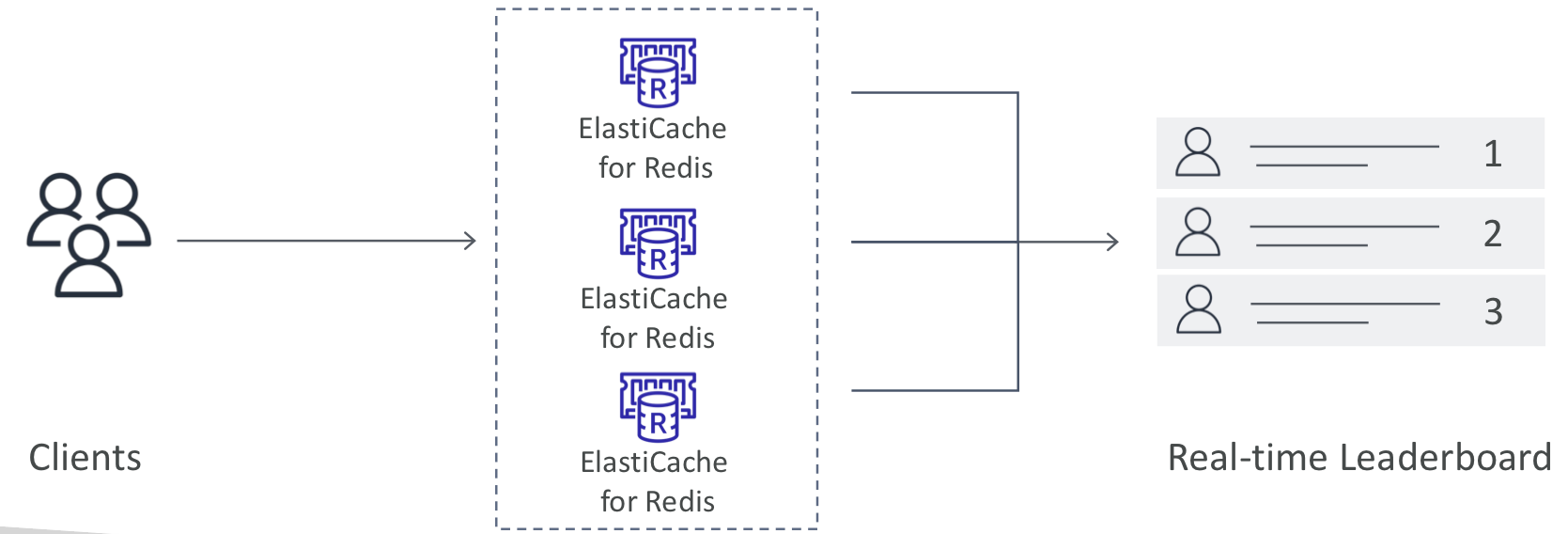
- 게임 리더보드 생성은 매우 복잡함.
- Redis의 Sorted sets는 고유성과 요소 순서를 모두 보장함.
- 새로운 요소가 추가될 때마다 실시간으로 순위가 매겨진 다음 올바른 순서로 추가됨.
✅ [DVA-C02] Caching Implementation Considerations
https://aws.amazon.com/ko/caching/best-practices/
- 데이터를 캐싱하는 것은 안전한가?
- 데이터가 최신 정보가 아닐 수 있으나, 최종적으로는 일관성을 유지한다.
- 캐싱이 데이터에 효과적인가?
- 패턴: 데이터 변경이 느리고 필요한 키가 적은 경우
- 안티 패턴: 데이터가 빠르게 바뀌고 데이터셋의 모든 키가 필요한 경우
- 데이터의 구조가 캐싱에 적합한가?
- 예시: 키-값 캐싱 또는 집계 결과의 캐싱
그렇다면 어떤 캐싱 설계 패턴이 가장 적합할까?
Lazy Loading / Cache-Aside / Lazy Population
- 장점
- 요청된 데이터만 캐시됨 (요청되지 않은 데이터는 캐시되지 않음)
- 노드 실패가 발생해도 치명적이지 않음 (캐시를 워밍하기 위한 대기 시간이 증가할 뿐)
- 단점
- 캐시 미스일 경우 3번의 네트워크 호출이 이뤄지며, 해당 요청에 대한 지연이 발생할 수 있음
- 오래된 데이터: 데이터는 데이터베이스에서 업데이트 되었지만 캐시에서는 오래된 상태일 수 있음
Lazy Loading / Cache-Aside / Lazy Population Python Pseudocode
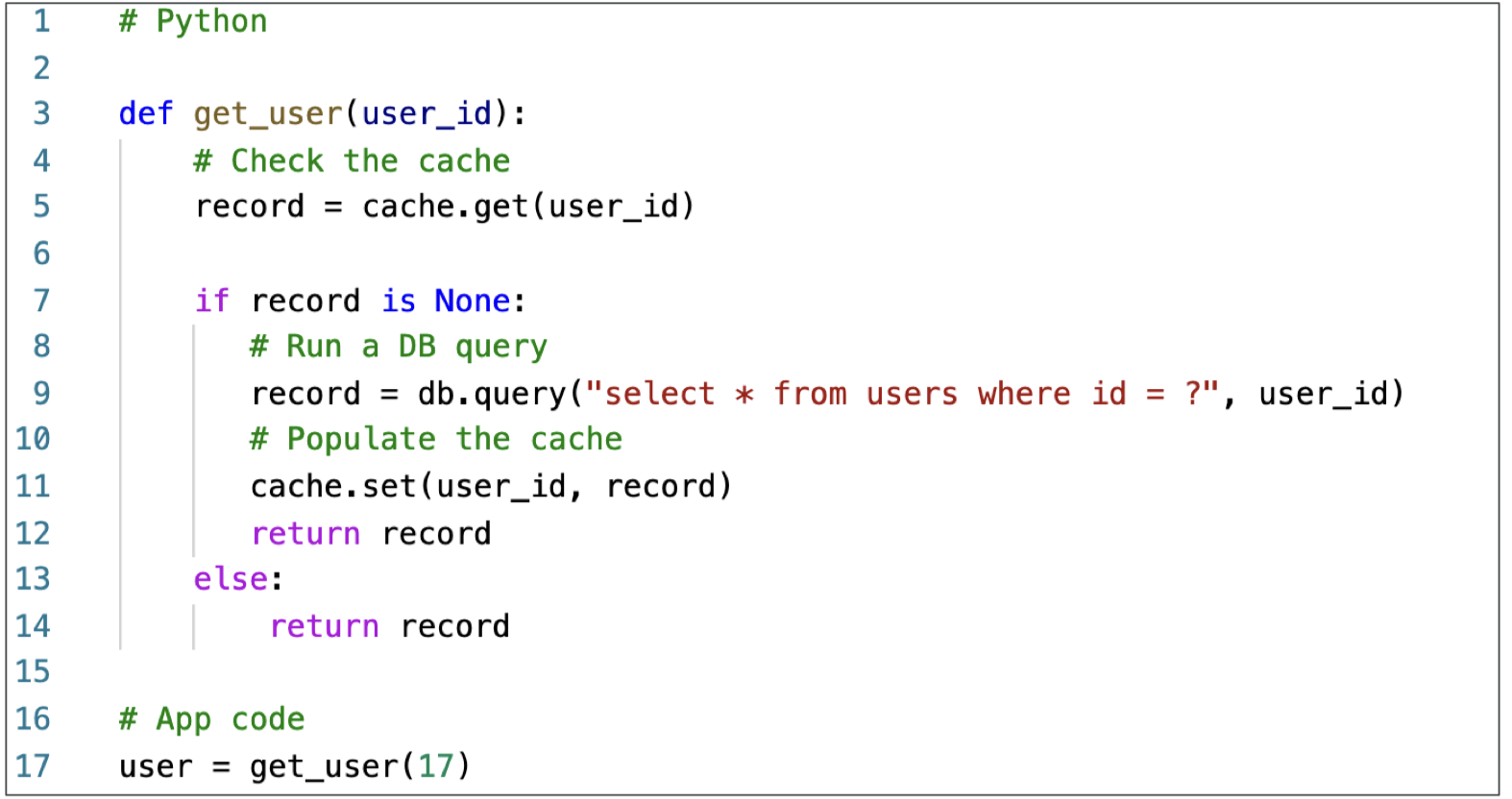
Write Through – Add or Update cache when database is updated
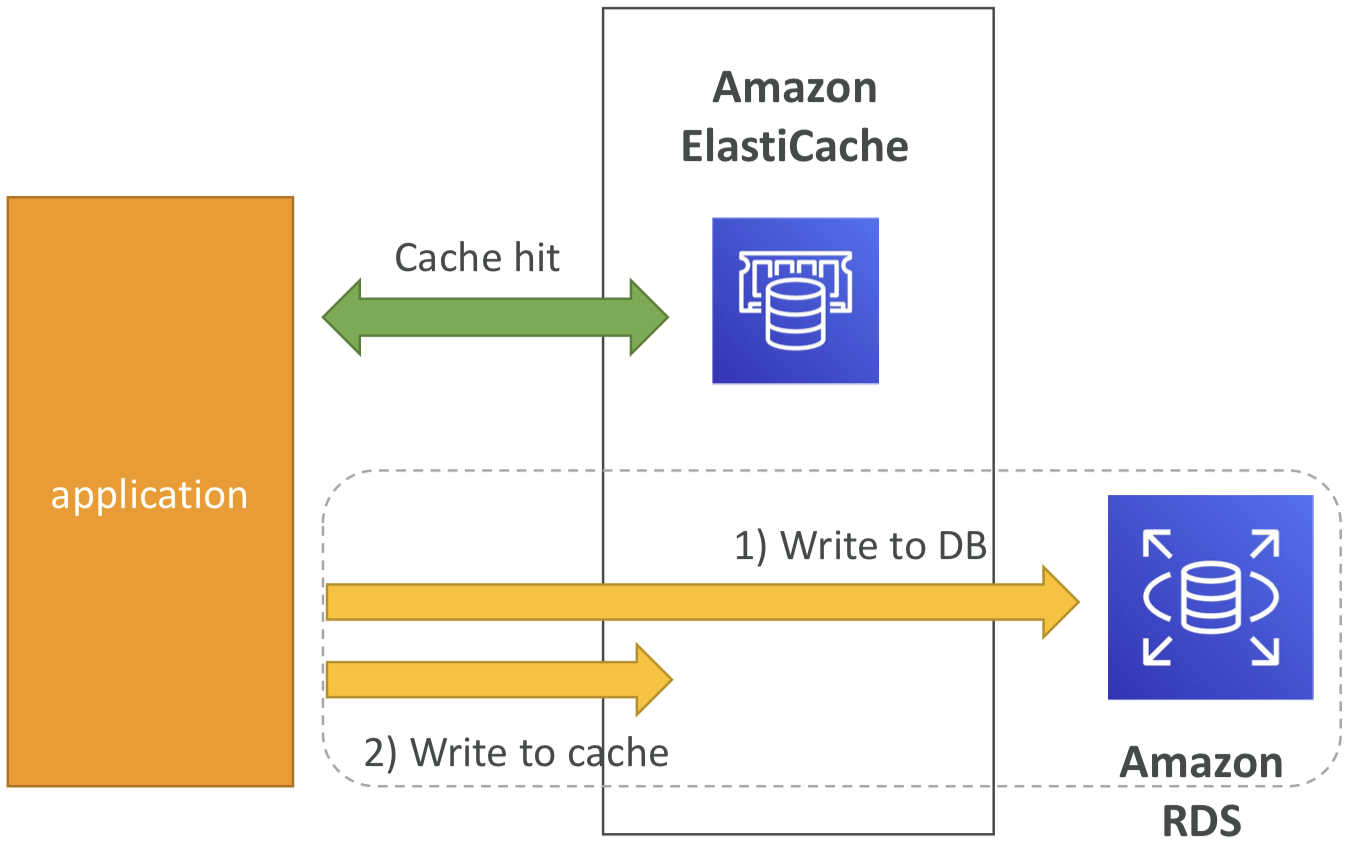
- 장점
- 캐시된 데이터는 절대로 오래된 상태가 아니며, 읽기가 빠르다
- 쓰기 패널티 vs 읽기 패널티
- 단점
- 데이터가 데이터베이스에 추가/업데이트 되기 전까지는 데이터가 없다. 이를 완화하기 위해 Lazy Loading 전략을 결합하여 구현할 수 있다.
- 캐시 이탈률(churn): 많은 데이터를 추가할 경우 많은 데이터가 읽히지 않을 수 있다.
Write-Through Python Pseudocode
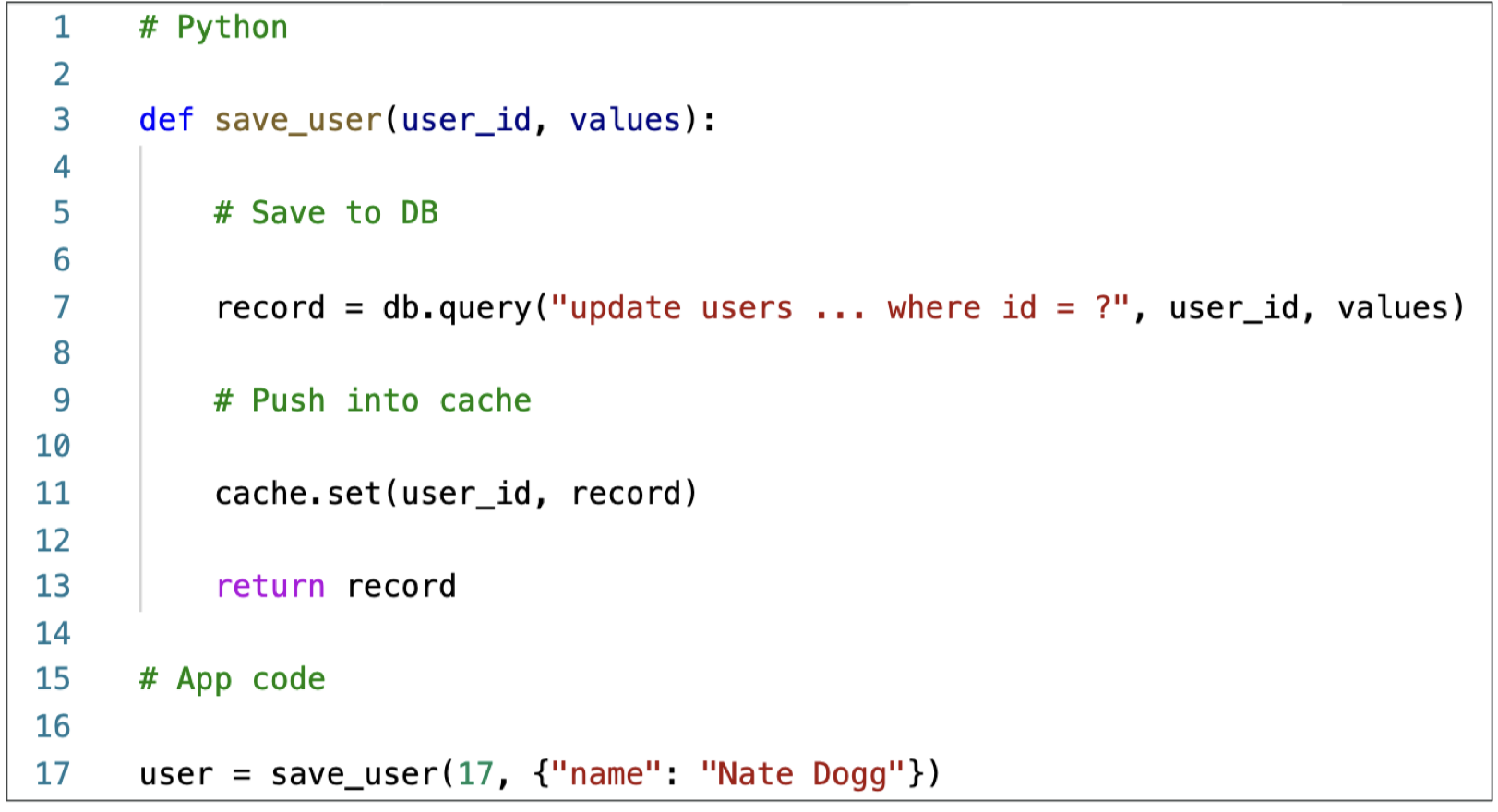
Cache Evictions and Time-to-live (TTL)
- 캐시 제거는 세 가지 방식으로 발생할 수 있다.
- 캐시에서 명시적으로 항목을 삭제한다.
- 메모리가 가득 찼을 때 가장 최근에 사용되지 않은 항목이 제거된다. (LRU, Least Recently Used)
- 타임 투 리브 (TTL)로 설정한다.
- TTL은 다양한 종류의 데이터에 유용하다
- 리더보드
- 댓글
- 활동 스트림
- TTL은 몇 초부터 몇 시간 또는 며칠까지 다양하다.
- 메모리가 항상 꽉 차서 너무 많은 제거가 발생하는 경우, 스케일 업 또는 스케일 아웃을 해야 한다.
Final words of wisdom
- Lazy Loading / Cache aside는 구현하기 쉽고 다양한 상황에서 기본으로 사용되며, 특히 읽기 측면에서 작동한다.
- Write-through는 일반적으로 Lazy Loading과 결합되어 이 최적화를 적용하는 쿼리나 워크로드를 대상으로 한다.
- TTL(Time-to-live) 설정은 일반적으로 좋은 아이디어다. Write-through를 사용하지 않을 때를 제외하고는 응용 프로그램에 적합한 값을 설정해야 한다.
- 필요한 데이터에만 캐싱을 적용해야 한다. (사용자 프로필, 블로그 등)
🆕 [DVA-C02] Amazon MemoryDB for Redis
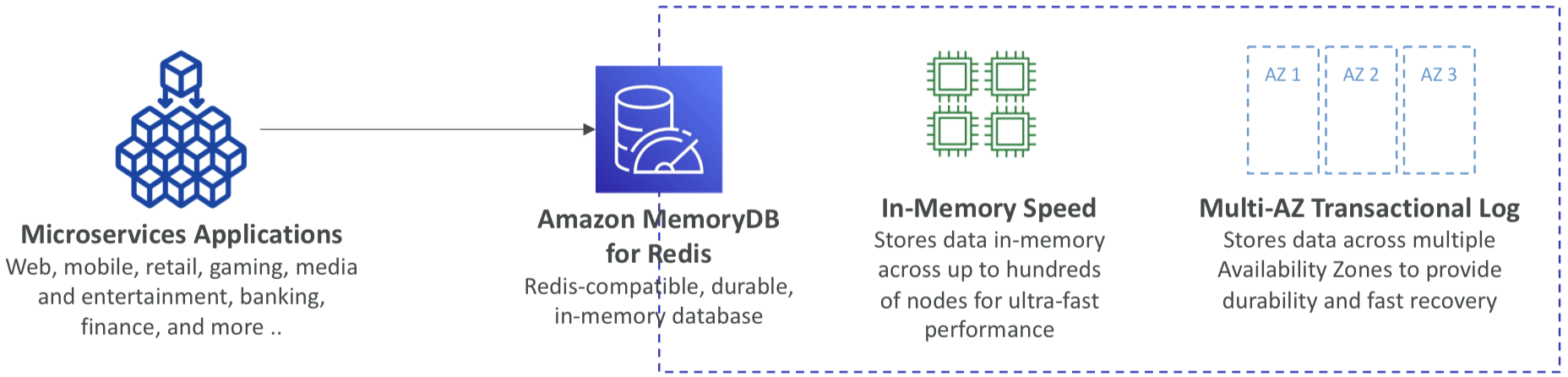
- Redis와 호환되고, 내구성이 뛰어난 인메모리 데이터베이스 서비스
- 초당 1억 6천만 건 이상의 초고속 성능
- 다중 AZ 트랜잭션 로그를 사용한 내구성 있는 인메모리 데이터 스토리지
- 10GB에서 100TB까지의 스토리지로 원활하게 확장 가능
- 사용 사례: 웹 및 모바일 앱, 온라인 게임, 미디어 스트리밍 등
+ List of Port numbers
중요한 포트:
- FTP: 21
- SSH: 22
- SFTP: 22 (SSH와 같음)
- HTTP: 80
- HTTPS: 443
vs RDS 데이터베이스 포트:
- PostgreSQL: 5432
- MySQL: 3306
- Oracle RDS: 1521
- MSSQL Server: 1433
- MariaDB: 3306 (MySQL과 같음)
- Aurora: 5432 (PostgreSQL와 호환될 경우) 또는 3306 (MySQL과 호환될 경우)
