안녕하세요 오랜만에 인사드립니다ㅎㅎ 이번에 SW마에스트로 13기 과정이 끝나면서 본격적으로 투다 서비스 관리를 시작했습니다. 이전 서버의 경우 DB 서버와 API 서버가 한 서버에서 운영되어 DB 혹은 API 서버 각각의 스펙을 조정하는 측면에서 불편한 부분이 있었고, 이전 DB에서 최적화가 되어 있지 않은 부분이 있어 겸사겸사 데이터 마이그레이션 작업을 진행했습니다.
우선 기존 DB를 명세했던 aquerytool에서 유료화를 진행하여 이전에 기록해놓은 명세 내용을 확인할 수가 없었습니다ㅠㅠ 그래서 erdcloud에서 새롭게 명세 작업을 시작했습니다,,ㅎㅎ 투다 DB를 관리한 지 시간이 좀 지나서 오랜만에 복기도 할 겸 쿼리를 통해 가져오지 않고 하나하나 입력하면서 노가다를 진행했네요,,ㅎㅎ 기존 명세에 빠져 있었던 FK, UK 설정과 ID 컬럼의 int 타입을 bigint로 변경하는 등의 소소한 작업들도 같이 진행했습니다.
저는 기존 방식인 EC2에 DB를 설치하는 방식이 아니라 RDS로 데이터를 이전하려고 합니다. 기존 방식의 경우 데이터 백업, 모니터링 및 이중화 작업 등을 진행할 때 좀 번거로운 감이 있었는데 RDS에서는 이런 부분은 간편하게 제공해준다는 장점이 있어서 선택하게 되었습니다. (하지만 그만큼 비싸다는 함정이,,ㅎㅎ)
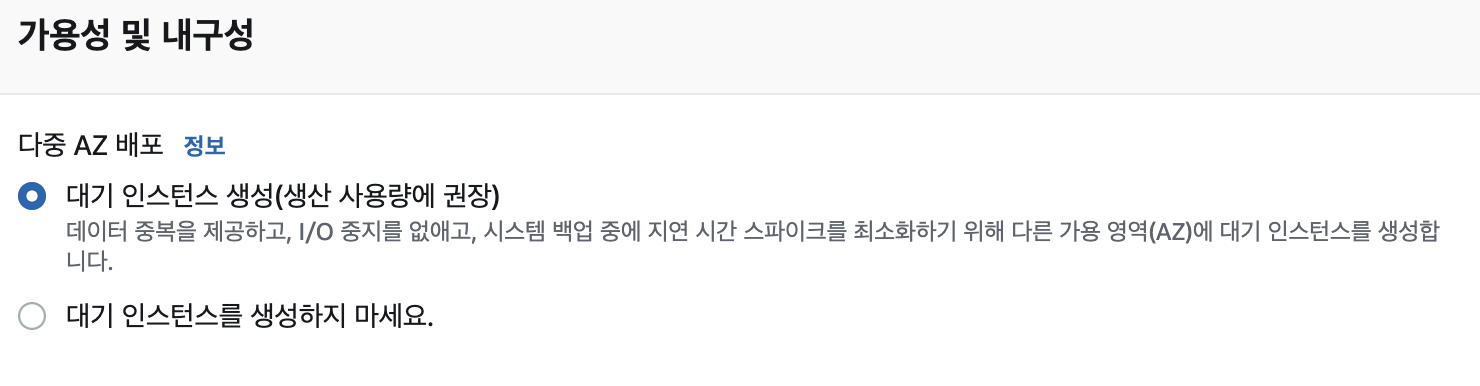
이번에 마이그레이션 작업을 진행하면서 다중 AZ에 대해서 조금 더 알게 되었는데요, RDS는 다중 AZ를 통해 DB를 자동으로 이중화해주는 기능을 제공하고 있습니다. 따라서 DB에 장애가 발생하거나 DB 수정 사항이 생겨 DB를 재부팅할 경우 이중화된 DB로 리다이렉팅하여 서비스 이용이 중지되지 않는다는 장점이 있습니다. 하지만 이중화한 DB의 개수만큼 비용이 배로 지불되니 신중하게 선택하시면 됩니다ㅎㅎ 그리고 서비스 운영 중에 다중 AZ 옵션을 활성화할 경우 단기적으로 쿼리 성능 등에 퍼포먼스 저하가 발생할수도 있다고 하니 이 부분도 고려해서 진행하시면 될 것 같습니다.
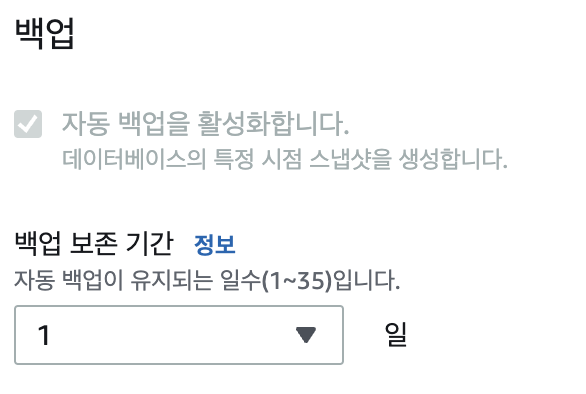
DB를 새로 만들면서 백업 기능도 같이 활성화하였습니다. 기존 방식에서는 백업 파일을 별도로 만들고 스케줄러를 통해 백업 파일을 유지하였는데 RDS에서는 생성 시 옵션으로 선택할 수 있어 좀 더 편리한 것 같습니다.
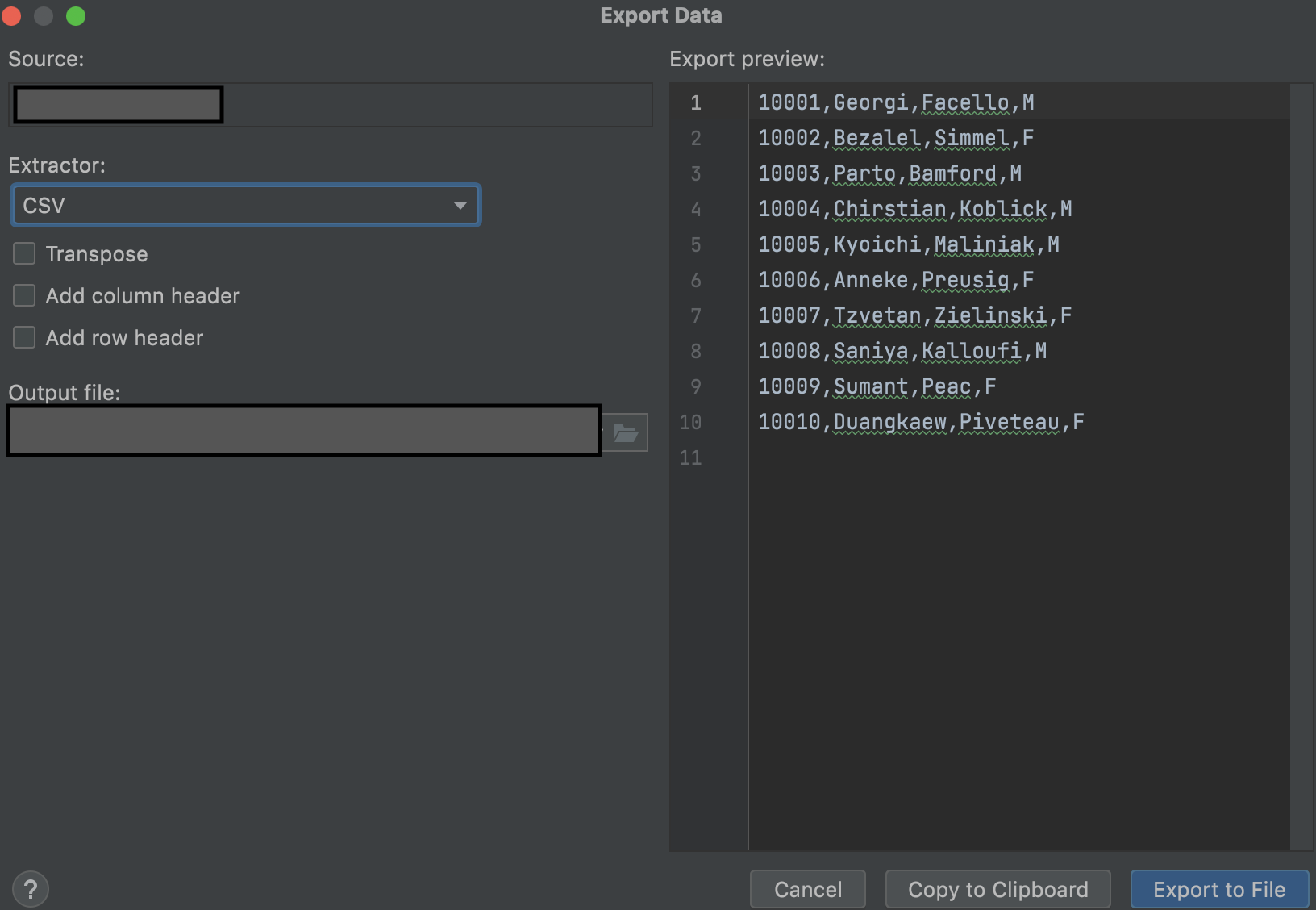
생성된 DB에 앞서 명세했던 테이블들을 추가한 후 본격적으로 데이터를 넣을 준비를 진행했습니다. 우선 본 서버에 있는 데이터를 가져오는 작업부터 진행했습니다. 저같은 경우 DB IDE로 Datagrip을 사용하는데 본 서버의 데이터를 쉽게 csv 파일로 export할 수 있습니다. 하지만 사용자들이 많이 사용하고 있다 보니 사용자들이 많이 사용하지 않는 새벽 시간에 잠시 DB를 멈추고 작업을 진행했는데 스케줄러를 통해 원하는 시간에 csv 파일을 export하는 방법을 몰라 근 일주일 간 낮밤이 바뀐 올빼미 생활을 진행했네요,,ㅠㅠ 이 부분도 추후 계속 공부하면서 알아봐야 할 것 같습니다.
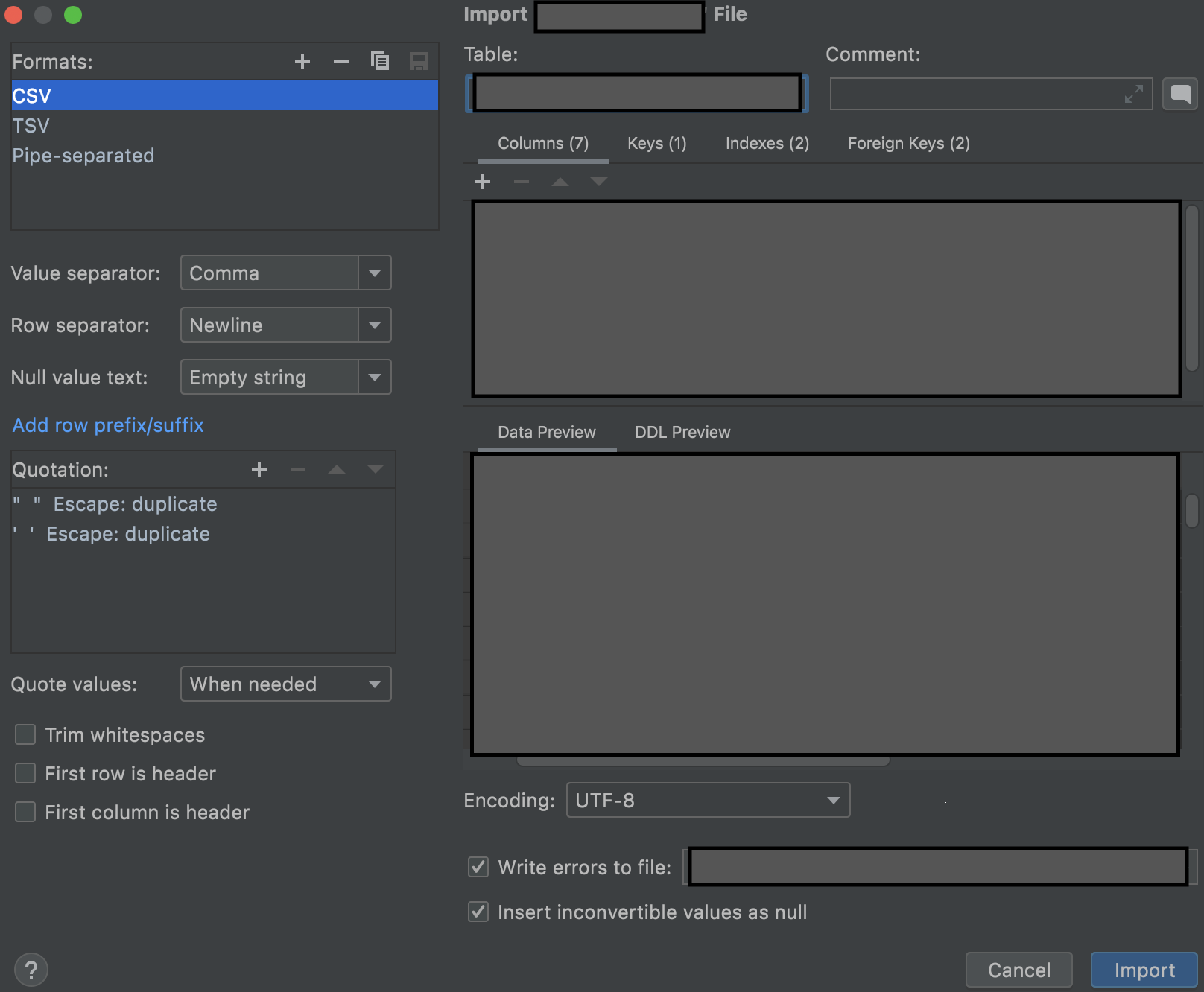
제가 가장 시행착오를 많이 겪었던 부분이 바로 가져온 csv 파일을 DB에 추가하는 작업이었습니다,,ㅎㅎ 가장 처음에는 Datagrip에서 제공하는 import 기능을 사용했는데 현재 테이블 당 최대 5,000,000개 이상의 데이터가 존재해서 데이터 추가 속도가 너무 느릴 뿐더러, 데이터 추가 중 오류가 발생했을 때 실행 속도가 현저히 줄어드는 문제 떄문에 정상적으로 작업을 진행하기 너무 어려웠습니다.

그래서 저는 Load data infile을 이용하여 csv 파일을 좀 더 빠르게 읽도록 진행했습니다. 하지만 이 과정에서도 문제가 발생했는데, csv 파일을 기존 DB 서버에 저장하는 것이 아니라 로컬로 가져와 저장했기 때문에 local 옵션을 활성화했었는데, 데이터가 정상적으로 추가가 되지 않는 문제가 발생했습니다.

MariaDB 공식 문서를 확인해보니 local로 실행할 때는 replace 대신 ignore 또는 아무 옵션도 활성화시키지 않은 상태로 진행하라고 합니다. 서버가 실행 도중에 파일 전송을 막을 수 없어서 replace 옵션이 활성화되지 않는다고 하네요.

하지만 여전히 오류가 발생했습니다. 쿼리 실행은 정상적으로 동작했지만 1265 Data truncated for column 'column_name' at row 1 오류가 발생했습니다. 이 부분의 원인이 무엇일까 계속 살펴보던 중..

DB에 다음과 같이 데이터가 밀려서 저장되있는 것을 발견했습니다,, 그래서 원인이 뭘까 하고 csv 파일을 다시 확인해봤는데,,

varchar 타입에 들어가있는 데이터들 중 '\' 문자가 가장 뒤에 있는 데이터, 즉 ',' 바로 앞에 '\'가 있게 되는 '\,' 과 같은 문자열이 csv 파싱을 방해해서 데이터가 밀린다는 사실을 알게 되었습니다,,ㅎㅎ (이 부분때문에 새벽에 밤새가면서 끙끙댔었는데, 찾았을 때 정말 너무 기뻤습니다,,ㅎㅎ)
이 부분을 해결하기 위해서 csv 파일에 있는 '\,' 문자열을 모두 ','로 치환한 후 해당 데이터들의 마지막에 '\'를 추가하는 방식으로 데이터를 수정하였습니다. 그러자 데이터가 정상적으로 추가되는 것을 확인하였고 약 15분 동안 데이터 추가 작업을 모두 완료했습니다.

마지막으로 이벤트 스케줄러를 생성하여 탈퇴 후 30일이 경과한 유저들의 데이터를 제거하는 작업을 진행하며 데이터 마이그레이션 작업을 마무리하였습니다. 한 가지 아쉬운 점은 마이그레이션 작업을 진행하면서 DB 생성 시 sysbench를 통해 DB 서버의 성능 및 부하 테스트를 진행하여 가장 적합한 스펙의 DB 서버를 구축하고 싶었는데, sysbench의 결과값을 분석하는 방법에 대해 잘 모르다보니 제가 예상한 결과와 다르게 나타났습니다,, 이 부분은 추후 더 많은 공부를 통해 sysbench를 활용한 서버 최적화 포스트로 다시 찾아뵙도록 하겠습니다. 긴 글 읽어주셔서 감사드립니다!
