import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as plt
from preprocess import *def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.legend([string],'val_'+string)DATA_IN_PATH = 'data_in/'
DATA_OUT_PATH = 'data_out/'
TRAIN_INPUTS = 'train_inputs.npy'
TRAIN_OUTPUTS = 'train_outputs.npy'
TRAIN_TARGETS = 'train_targets.npy'
DATA_CONFIGS = 'data_config.json'tf.random.set_seed(1234)index_inputs = np.load(open(DATA_IN_PATH+TRAIN_INPUTS,'rb'))
index_outputs = np.load(open(DATA_IN_PATH+TRAIN_OUTPUTS,'rb'))
index_targets = np.load(open(DATA_IN_PATH+TRAIN_TARGETS,'rb'))
prepro_configs = json.load(open(DATA_IN_PATH+DATA_CONFIGS,'r'))print(len(index_inputs), len(index_outputs), len(index_targets))100 100 100MODEL_NAME = 'seq2seq'
BATCH_SIZE = 2
MAX_SEQUENCE = 25
EPOCH = 50
UNITS = 1024
EMBEDDING_DIM = 256
VALIDATION_SPLIT = 0.1
prepro_configs.keys()dict_keys(['char2idx', 'idx2char', 'vocab_size', 'pad_symbol', 'std_symbol', 'end_symbol', 'unk_symbol'])char2idx = prepro_configs["char2idx"]
idx2char = prepro_configs["idx2char"]
std_index = prepro_configs["std_symbol"]
end_index = prepro_configs["end_symbol"]
vocab_size = prepro_configs["vocab_size"]class Encoder(tf.keras.layers.Layer): #상속, 307p
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz ):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding_dim = embedding_dim
self.vocab_size = vocab_size
self.embedding = tf.keras.layers.Embedding(self.vocab_size, self.embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units, return_sequences=True, return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self, inp): #rnn할 때도 은닉층은 0으로 시작
return tf.zeros((tf.shape(inp)[0], self.enc_units))
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units) #value
self.W2 = tf.keras.layers.Dense(units) #Query
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
hidden_with_time_axis = tf.expand_dims(query, 1)
score = self.V(tf.nn.tanh(self.W1(values) + self.W2(hidden_with_time_axis)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weightsclass Decoder(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim #한 단어는 이정도 임베딩이 필요해
self.dec_units = dec_units
self.batch_sz = batch_sz
self.embedding = tf.keras.layers.Embedding(self.vocab_size, self.embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units, return_sequences=True, return_state=True,
recurrent_initializer='glorot_uniform') #GRU앞에는 유닛개수 , return_sequences=True 해야 같이 묶임
self.fc = tf.keras.layers.Dense(self.vocab_size)
self.attention = BahdanauAttention(self.dec_units) #니가 신경써야 할 것은 몇 개야
def call(self, x, hidden, enc_output):
context_vector, attention_weights = self.attention(hidden, enc_output) #attention은 2가지(context_vector, attention_weights)를 내보내 준다,
x = self.embedding(x)
tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1) #context_vector = attention, x = 나, tf.expand_dims =차원 맞추기
output, state = self.gru(x)
output = tf.reshape(output, (-1, output.shape[2])) #차원 맞추기
x = self.fc(output)
return x, state, attention_weights optimizer = tf.keras.optimizers.Adam() #단어 뭘 선택할 것이냐
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name="accuracy")
def loss(real,pred):
mask = tf.math.logical_not(tf.math.equal(real,0))
loss_ = loss_object(real,pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
def accuracy(real,pred):
mask = tf.math.logical_not(tf.math.equal(real,0))
mask = tf.expand_dims(tf.cast(mask,dtype=pred.dtype),axis=-1)
pred *= mask
acc = train_accuracy(real,pred)
return tf.reduce_mean(acc)
mask는 한 문장에서 한 단어를 '마스킹테이프'한 것 처럼
SparseCategoricalCrossEntropy을 그냥 쓰는 것이 아니라 mask를 적용해서 사용
일반rnn에서 mask를 사용하지 않으면 횡설수설하게 된다.
seq2seq는 횡설수설 안 하는 편인 이유는 mask를사용해서이다.
class seq2seq(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, dec_units, batch_sz, end_token_idx=2):
super(seq2seq, self).__init__()
self.end_token_idx = end_token_idx
self.encoder = Encoder(vocab_size, embedding_dim, enc_units, batch_sz)
self.decoder = Decoder(vocab_size, embedding_dim, dec_units, batch_sz)
def call(self, x): #입력을 하면 예측해라
inp, tar = x
enc_hidden = self.encoder.initialize_hidden_state(inp) #학습시작, 학습할 때는 input과 target이 있다.
enc_output, enc_hidden = self.encoder(inp, enc_hidden)# inp = 질문, enc_hidden = 초기값
dec_hidden = enc_hidden
predict_tokens = []
for t in range(0, tar.shape[1]): #tar.shape[1] = 한 문장의 길이
dec_input = tf.dtypes.cast(tf.expand_dims(tar[:, t],1), tf.float32) #float32 타입으로 통일하겠다
predictions, dec_hidden, dummy = self.decoder(dec_input, dec_hidden, enc_output)
predictions = tf.dtypes.cast(predictions, tf.float32)
predict_tokens.append(predictions) #출력을 모으자
return tf.stack(predict_tokens, axis=1) #최종적으로 '나는 너를 사랑해' 출력, tf.stack = 차원 맞추기
def inference(self, x): #입력하면 학습해라,
inp = x
enc_hidden = self.encoder.initialize_hidden_state(inp)
enc_output, enc_hidden = self.encoder(inp, enc_hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([char2idx[std_index]], 1)
predict_tokens = []
for t in range(0, MAX_SEQUENCE):
predictions, dec_hidden, dummy = self.decoder(dec_input, dec_hidden, enc_output)
predict_token = tf.argmax(predictions[0]) #나와있는 값들이 원핫인코딩형태라서 argmax를 사용해서 어떤 단어인지 추림
if predict_token == self.end_token_idx: #end가 검출되면 그만해
break
predict_tokens.append()
dec_input = tf.dtype.cast(tf.expand_dims([predict_token], 0), tf.float32)# predict_token에서 나온 것 차원을 바꿔라
return tf.stack(predict_tokens, axis=0).numpy()
inference함수는 call함수와 유사하다
decoder할 때 start를 줘야 한다.
start = 최초 decoder = dec_input
char2idx[std_indx] = 숫자로 바꿔줘
rnn을 계속 공급하기 = for문
dec_hidden = 나는 너를 사랑해
처음에 enc_output로 들어온다. 처음 시작할 때는 디코더에는 참고할 정보는 오직 인코더의 정보뿐이다.
점점 나는 너를 사랑해는 바뀐다.
model = seq2seq(vocab_size, EMBEDDING_DIM, BATCH_SIZE, char2idx[end_index])
model.compile(loss=loss,
optimizer = tf.keras.optimizers.Adam(1e-3), metrics = [accuracy] )PATH = DATA_OUT_PATH + MODEL_NAME
if not (os.path.isdir(PATH)):
os.makedirs(os.path.join(PATH))
checkpoint_path = DATA_OUT_PATH + MODEL_NAME + './weights.h5'
cp_callback = ModelCheckpoint(checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=True)
es_callback = EarlyStopping(monitor='val_accuracy', min_delta=0.001, patience=10) #monitor='val_accuracy' 진전이 있는 지
history = model.fit([index_inputs, index_outputs], index_targets, batch_size= BATCH_SIZE, epochs=2,
validation_split= VALIDATION_SPLIT, callbacks=[cp_callback, es_callback])Epoch 1/2
WARNING:tensorflow:Gradients do not exist for variables ['seq2seq_2/encoder_2/embedding_4/embeddings:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/kernel:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/recurrent_kernel:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_9/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_9/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_10/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_10/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_11/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_11/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss`argument?
WARNING:tensorflow:Gradients do not exist for variables ['seq2seq_2/encoder_2/embedding_4/embeddings:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/kernel:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/recurrent_kernel:0', 'seq2seq_2/encoder_2/gru_4/gru_cell_4/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_9/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_9/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_10/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_10/bias:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_11/kernel:0', 'seq2seq_2/decoder_2/bahdanau_attention_2/dense_11/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss`argument?
45/45 [==============================] - ETA: 0s - loss: 1.8898 - accuracy: 0.0391
Epoch 1: val_accuracy improved from -inf to 0.04000, saving model to data_out/seq2seq.\weights.h5
45/45 [==============================] - 196s 3s/step - loss: 1.8898 - accuracy: 0.0391 - val_loss: 1.5449 - val_accuracy: 0.0400
Epoch 2/2
45/45 [==============================] - ETA: 0s - loss: 1.3381 - accuracy: 0.0404
Epoch 2: val_accuracy did not improve from 0.04000
45/45 [==============================] - 99s 2s/step - loss: 1.3381 - accuracy: 0.0404 - val_loss: 1.2790 - val_accuracy: 0.0400model.load_weights(os.path.join(DATA_OUT_PATH, MODEL_NAME, "weights.h5"))query = "남자친구 승진 선물로 뭐가 좋을까?"
test_index_inputs = enc_processing([query], char2idx)
test_index_inputspredict_token = model.inference(test_index_inputs)
print("". join([idx2char[t] for f in predict_token]))인코더
rnn은 병렬구조
rnn은 앞에가 나와야 뒤에 것이 나올 수 있다.
rnn의 문제 '나는 너를 사랑해' 한 번에 학습 못 함.
rnn 단어의 순서 기억. rnn을 걷어내면 순서 상관쓰지 않겠다.
s2s 디코더부분도 '나는' 나와야 '나는 너를' 나온다.
교재 340p
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i, 짝수
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1, 홀수
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)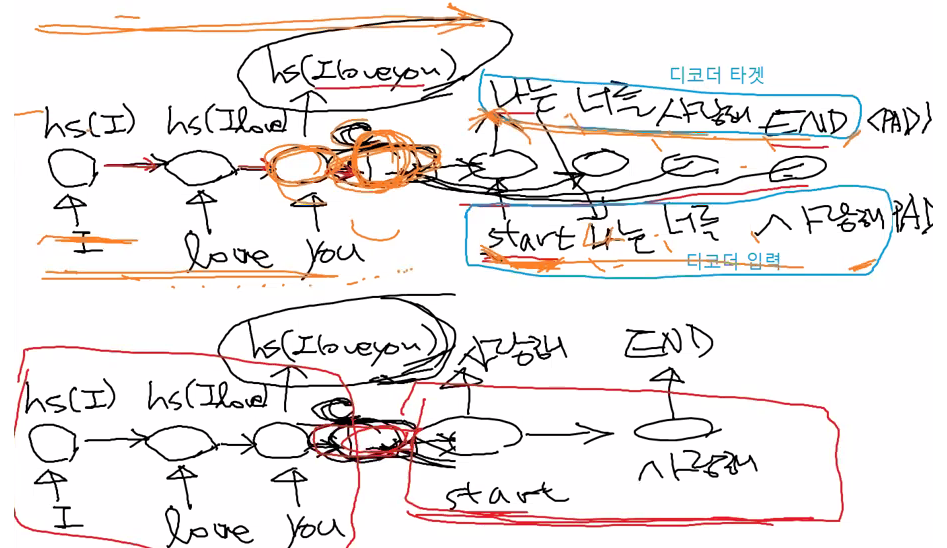
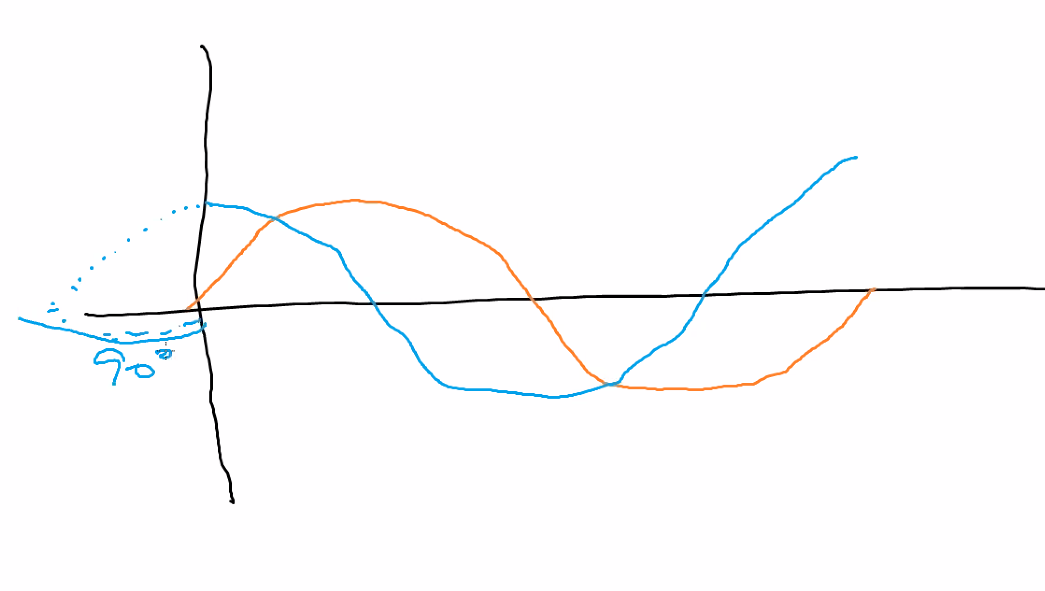
sin, cos는 90도 차이라서 본질적으로 같다.
문장은 하나인데 cos, sin을 나눠서 사용하는 이뉴는 본질적으로 같기 때문이다. 하나만 쓰면 파동이? 똑같아서? 헷갈리니까?
cos, sin 둘 다 무한이다.cos, sin 합쳐서 삼각함수라고 한다.
좌우 shift가 용이하다. -> 라벨링할 때 문제되지 않는다.
absolute index
"나는1 너를2 사랑한다3"
"말하자면1 나는2 너를3 사랑한다는4 말이야5"relative index
" 나는1 너를2 사랑한다3"
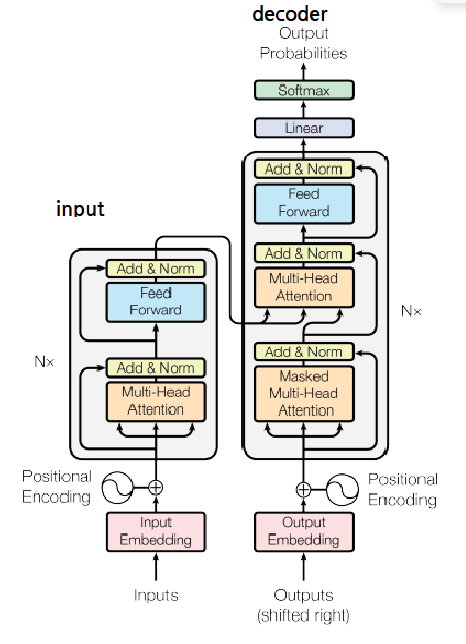
"말하자면-1 나는1 너를2 사랑한다는3 말이야4"트랜스포머 모델
셀프 어텐션
문장에서 각 단어끼리 얼마나 관계가 있는지 계산해서 반영하는 방법
어텐션 스코어 구하는 방법은 텍스트 유사도 구하는 방식과 유사
1. softmax 함수를 가지고 어텐션 스코어를 확률 값으로 표현
2. 어텐션 스코어와 각 단어벡터와 상수곱 연산
3. 상수곱을 한 단어벡터들에 대해서 더한다.
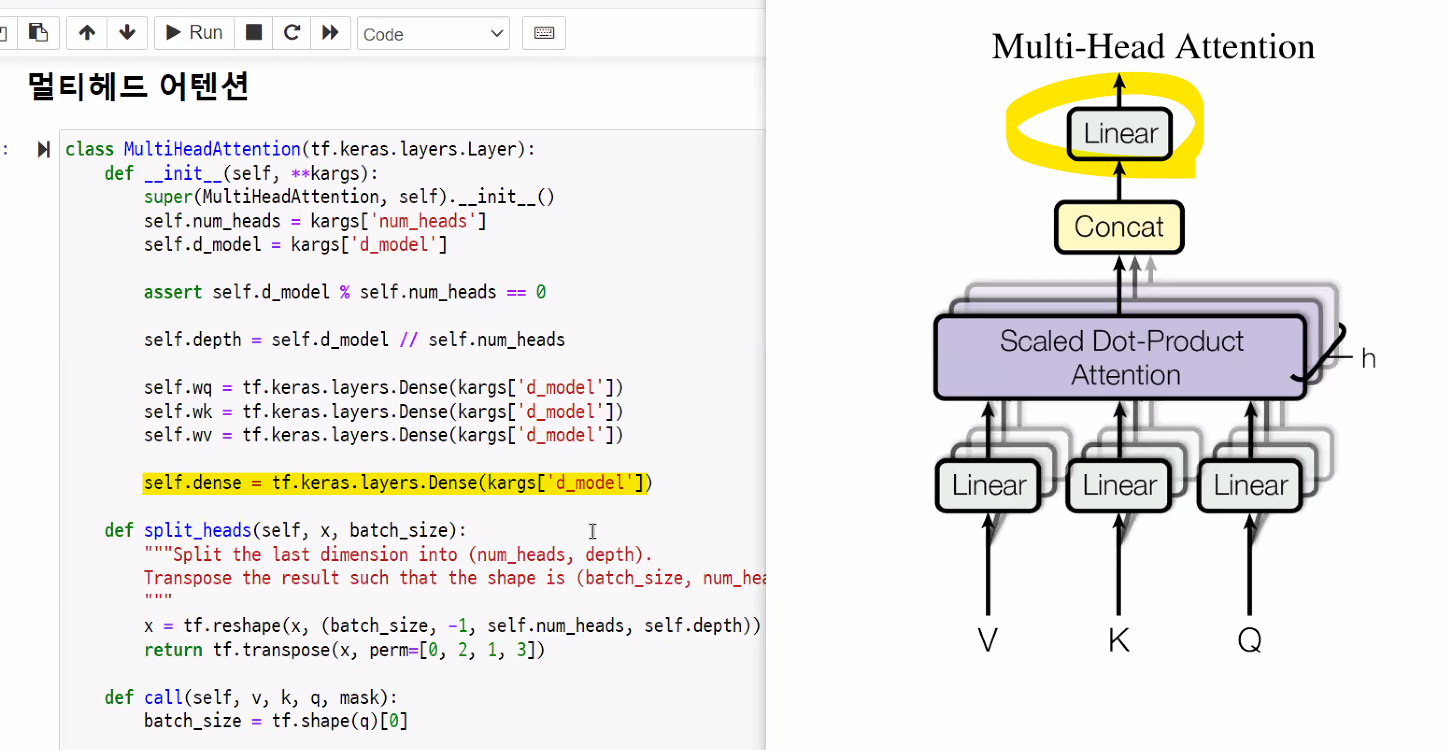
멀티헤드 어텐션
인코더 레이어
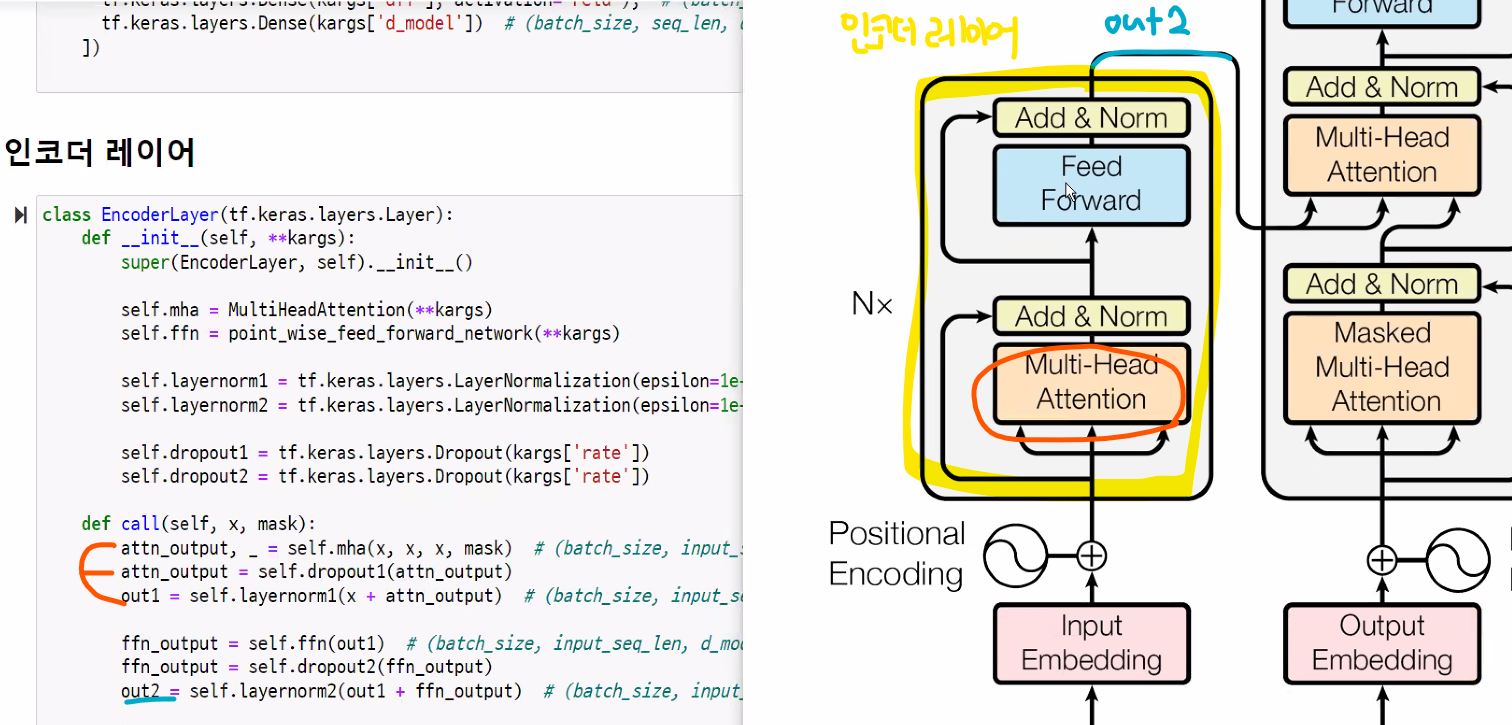
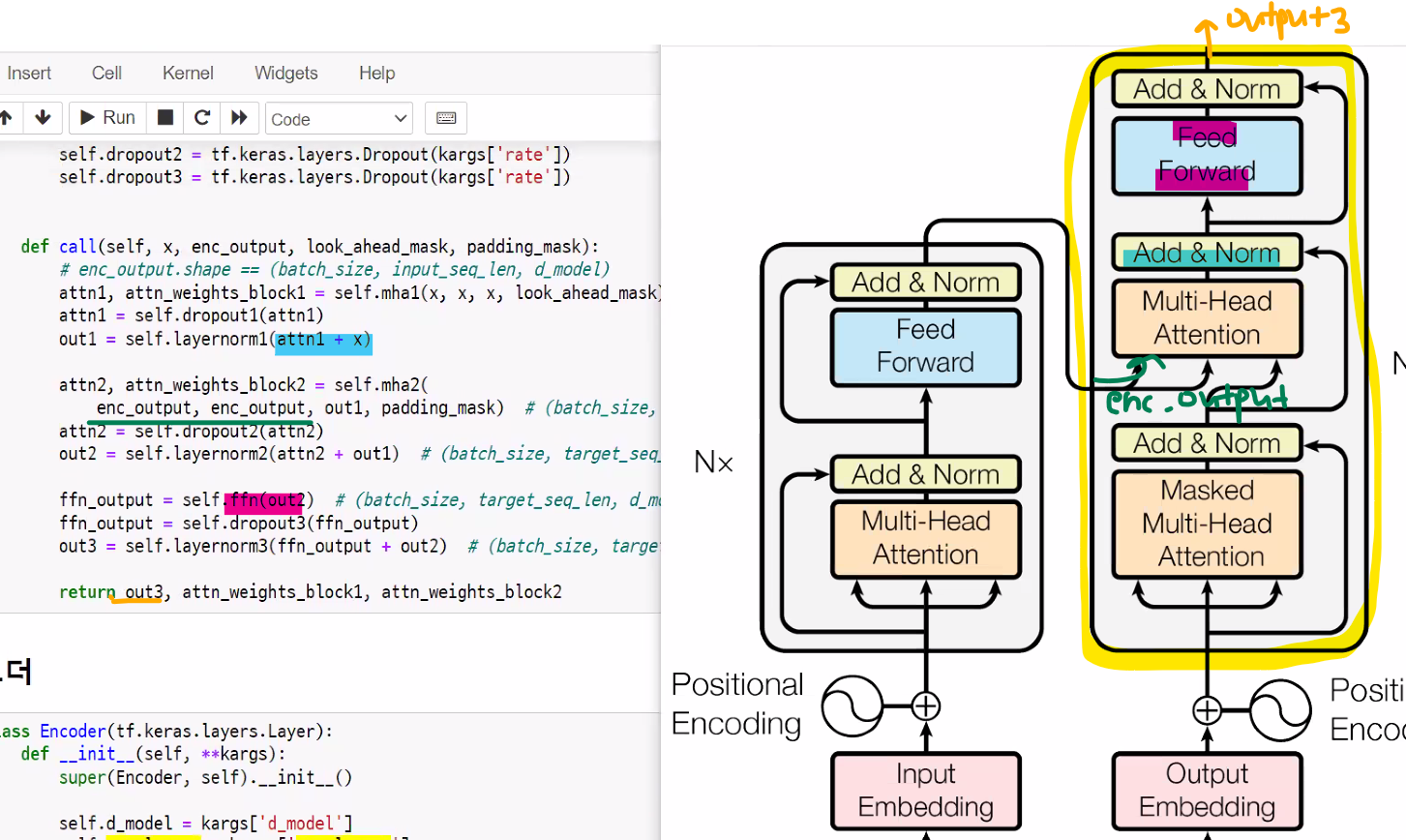
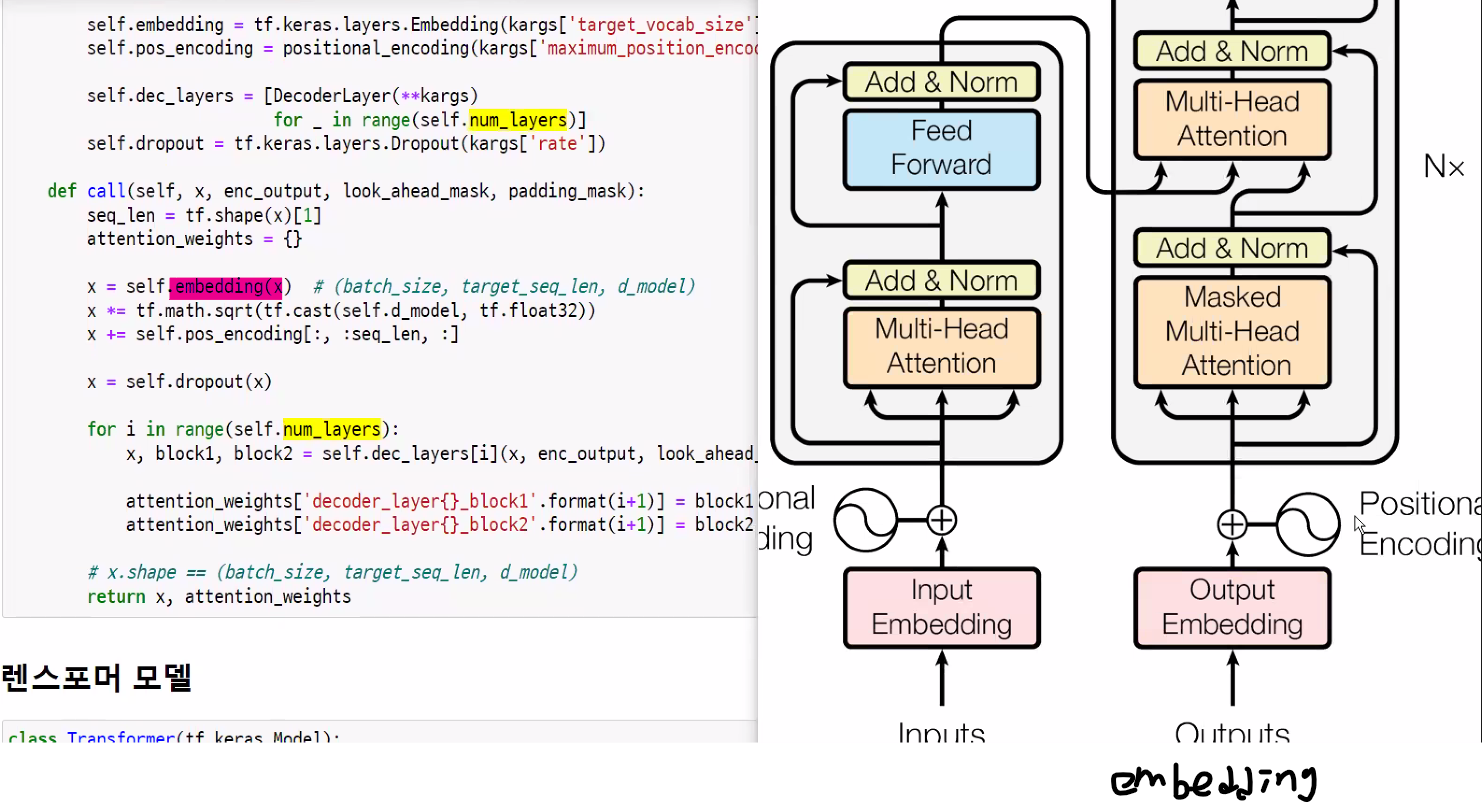
디코더 레이어
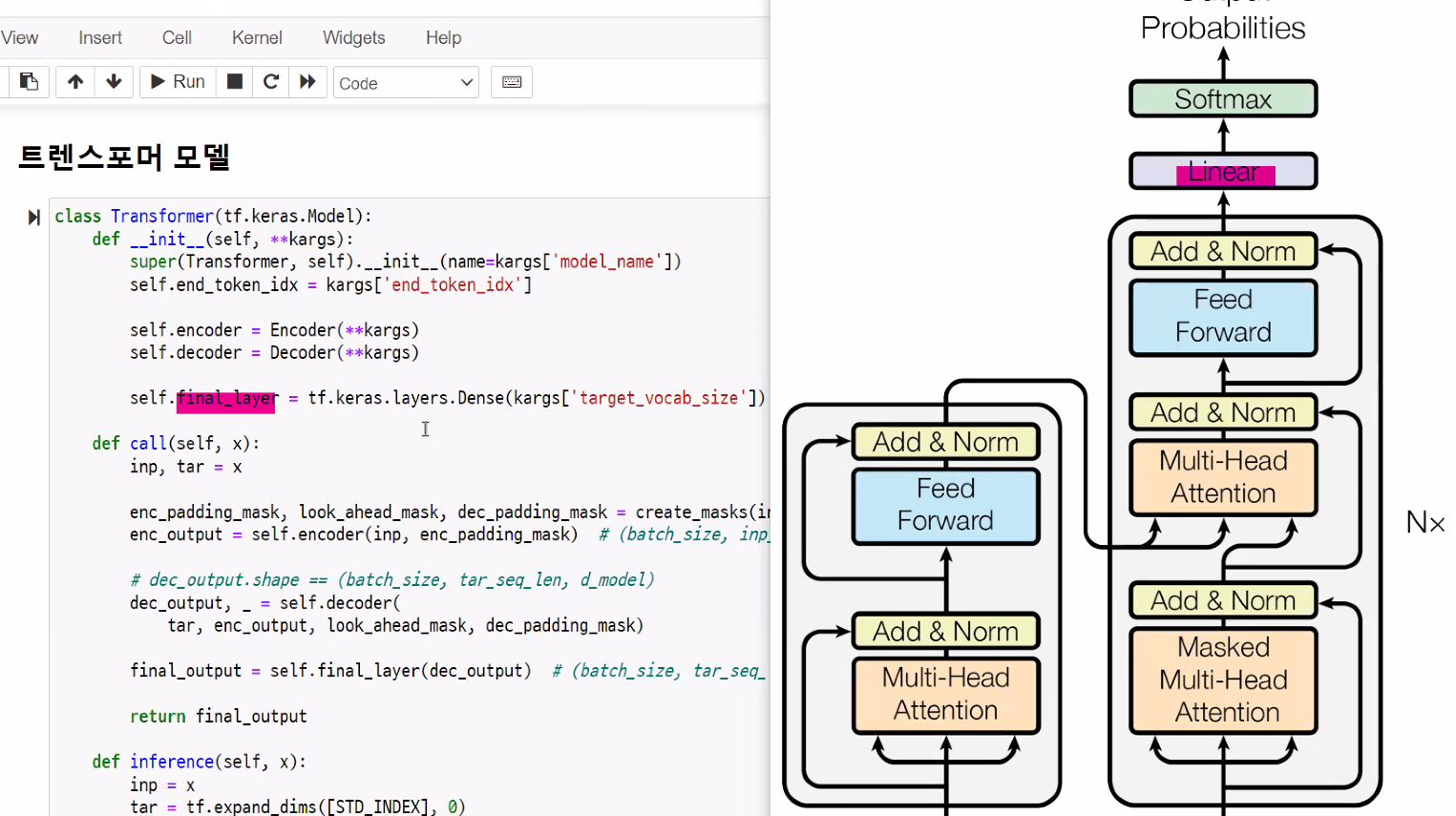
버트의 모델
트랜스포머 모델의 인코더 부분만 사용
gpt는 디코더 부분만 사용
