tacotron2
Eebedding, Encoder
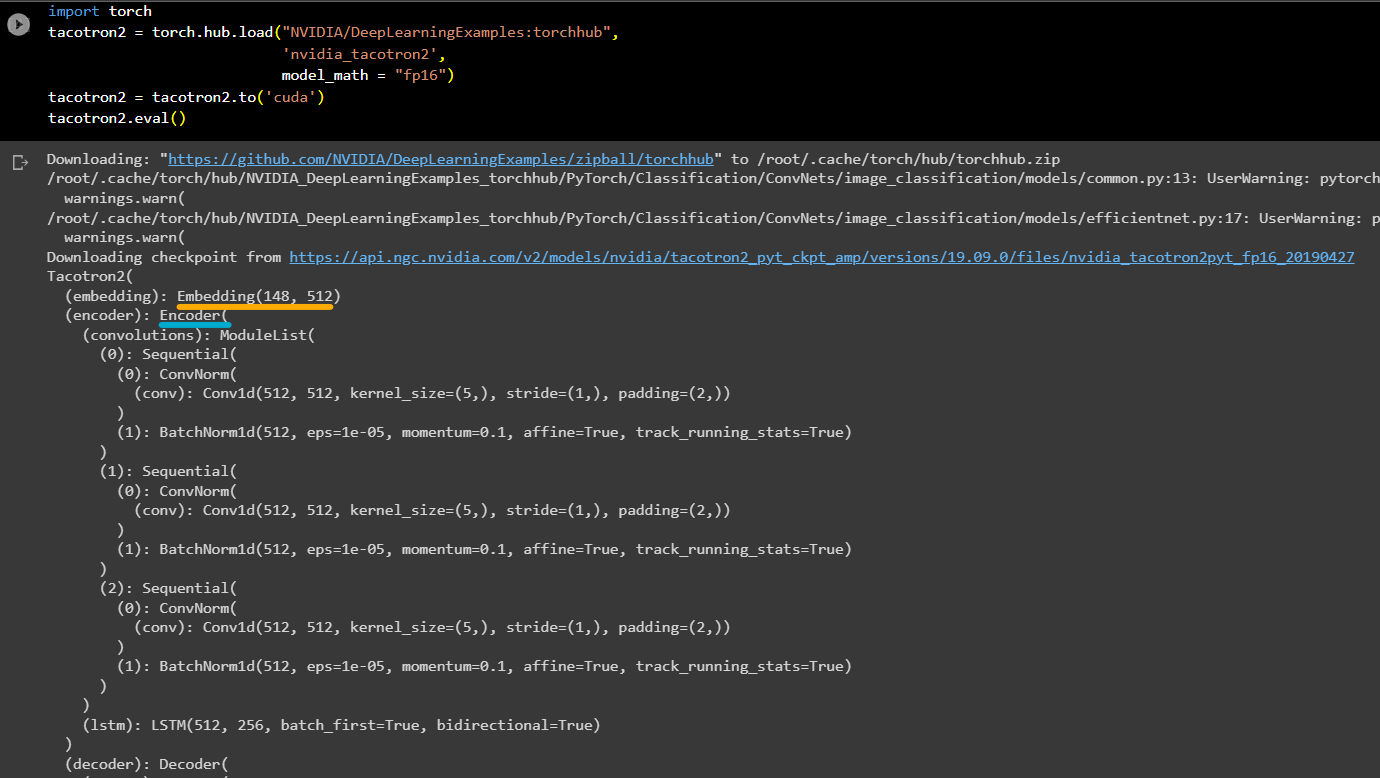
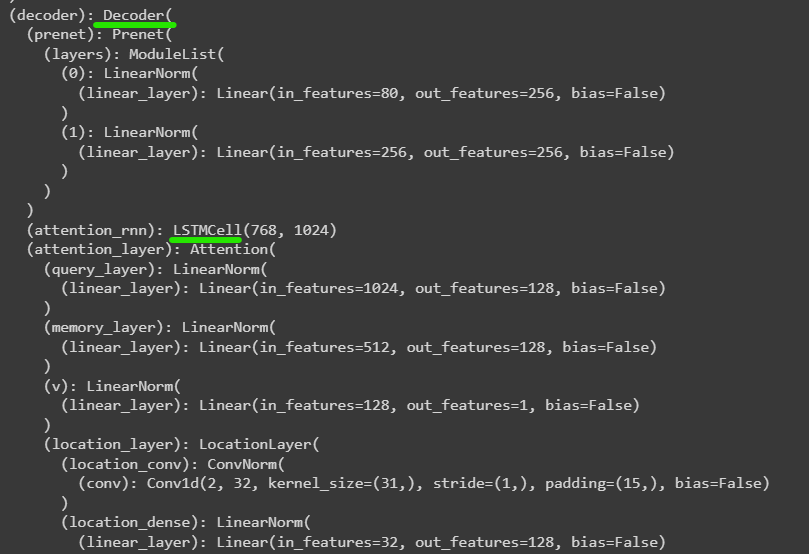
Decoder
LSTM 사용
import os, IPython, matplotlib
import matplotlib.pyplot as plt
import requests, torch, torchaudiomatplotlib.rcParams["figure.figsize"] = [16.0, 4.8]
torch.random.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
devicedevice(type='cuda')SPEECH_URL = "https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
SPEECH_URL'https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav'SPEECH_FILE = "_assets/speech.wav"if not os.path.exists(SPEECH_FILE):
os.makedirs("_assets", exist_ok=True)
with open(SPEECH_FILE, "wb") as file:
file.write(requests.get(SPEECH_URL).content)bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
bundle.sample_rate, bundle.get_labels()(16000,
('-',
'|',
'E',
'T',
'A',
'O',
'N',
'I',
'H',
'S',
'R',
'D',
'L',
'U',
'M',
'W',
'C',
'F',
'G',
'Y',
'P',
'B',
'V',
'K',
"'",
'X',
'J',
'Q',
'Z'))model = bundle.get_model().to(device)Downloading: "https://download.pytorch.org/torchaudio/models/wav2vec2_fairseq_base_ls960_asr_ls960.pth" to /root/.cache/torch/hub/checkpoints/wav2vec2_fairseq_base_ls960_asr_ls960.pth
0%| | 0.00/360M [00:00<?, ?B/s]modelWav2Vec2Model(
(feature_extractor): FeatureExtractor(
(conv_layers): ModuleList(
(0): ConvLayerBlock(
(layer_norm): GroupNorm(512, 512, eps=1e-05, affine=True)
(conv): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)
)
(1): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(2): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(3): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(4): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(5): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
)
(6): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
)
)
)
(encoder): Encoder(
(feature_projection): FeatureProjection(
(layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(projection): Linear(in_features=512, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(pos_conv_embed): ConvolutionalPositionalEmbedding(
(conv): Conv1d(768, 768, kernel_size=(128,), stride=(1,), padding=(64,), groups=16)생략
wave_form, sr = torchaudio.load(SPEECH_FILE)
wave_form = wave_form.to(device)sr, bundle.sample_rate(16000, 16000)with torch.inference_mode():
features, dummy = model.extract_features(wave_form)fig, ax = plt.subplots(len(features), 1, figsize=(16, 4.3*len(features)))
for i, feature in enumerate(features):
ax[i].imshow(feature[0].cpu())
ax[i].set_title(f"feature from transformer layer {i}")
ax[i].set_xlabel("feature dimension")
ax[i].set_ylabel("feature (time-axis)")
plt.tight_layout()
plt.show()Output hidden; open in https://colab.research.google.com to view.with torch.inference_mode():
emission, dummy = model(wave_form)print(bundle.get_labels())('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')plt.imshow(emission[0].cpu().T)
plt.title("class result")
plt.xlabel("Frame(time-axis)")
plt.ylabel("class")
plt.show()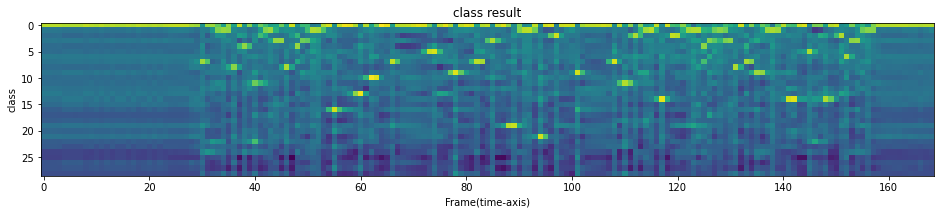
#transscript만들기
i had that curiousity beside me at this moment
len("i had that curiousity beside me at this moment")46class GreedyCTCDecoder(torch.nn.Module):
def __init__(self, labels, blank=0):
super().__init__()
self.labels = labels
self.blank = blank
def forward(self, emission: torch.Tensor) -> str:
indices = torch.argmax(emission, dim=-1)
indices = torch.unique_consecutive(indices, dim=-1)
indices = [i for i in indices if i != self.blank]decoder = GreedyCTCDecoder(labels=bundle.get_labels())decoder(emission[0])%%bash
pip install librosa scipy unidecode inflect %%bash
apt-get update
apt-get install -y libsndfile1import torch
tacotron2 = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
'nvidia_tacotron2',
model_math = "fp16")
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()waveglow = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
'nvidia_waveglow',
model_math = "fp16")
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()Using cache found in /root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub
Downloading checkpoint from https://api.ngc.nvidia.com/v2/models/nvidia/waveglow_ckpt_amp/versions/19.09.0/files/nvidia_waveglowpyt_fp16_20190427# text = "hello everyone, Let's take this in peace"
text = "hello"utils = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
'nvidia_tts_utils')
sequence, lengths = utils.prepare_input_sequence([text])
sequenceUsing cache found in /root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/SpeechSynthesis/Tacotron2/tacotron2/text/__init__.py:74: SyntaxWarning: "is not" with a literal. Did you mean "!="?
return s in _symbol_to_id and s is not '_' and s is not '~'
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/SpeechSynthesis/Tacotron2/tacotron2/text/__init__.py:74: SyntaxWarning: "is not" with a literal. Did you mean "!="?
return s in _symbol_to_id and s is not '_' and s is not '~'
tensor([[45, 42, 49, 49, 52]], device='cuda:0')tensor([[45, 42, 49, 49, 52]], device='cuda:0')
h = 45
e = 42
l = 49
l = 49
0 = 52
text = "hello e v e r y" #빈칸도 중요하다text1 = "hello everyone, Let's take this in peace" #빈칸도 중요하다
text2 = "i love eunjin, i love jisoo"
text = "kong doo sundubu muk go sip dada"
utils = torch.hub.load("NVIDIA/DeepLearningExamples:torchhub",
'nvidia_tts_utils')
sequences, lengths = utils.prepare_input_sequence([text])
sequencesUsing cache found in /root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub
tensor([[48, 52, 51, 44, 11, 41, 52, 52, 11, 56, 58, 51, 41, 58, 39, 58, 11, 50,
58, 48, 11, 44, 52, 11, 56, 46, 53, 11, 41, 38, 41, 38]],
device='cuda:0')with torch.no_grad():
mel, dummy, dummy = tacotron2.infer(sequences, lengths) #dummy = 안 쓰겠다.
audio = waveglow.infer(mel)
audio_result = audio[0].data.cpu().numpy()
sr = 22050 #sampling rate
from IPython.display import Audio
Audio(audio_result, rate=sr)!pip install transformers datasets jiwerfrom transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import soundfile as sf
import torch
from jiwer import werprocessor = Wav2Vec2Processor.from_pretrained('kresnik/wav2vec2-large-xlsr-korean')
model = Wav2Vec2ForCTC.from_pretrained('kresnik/wav2vec2-large-xlsr-korean').to('cuda')
ds = load_dataset('kresnik/zeroth_korean', 'clean')Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Downloading builder script: 0%| | 0.00/4.59k [00:00<?, ?B/s]
Downloading and preparing dataset zeroth_korean/clean to /root/.cache/huggingface/datasets/kresnik___zeroth_korean/clean/1.0.1/e5d146fc495c84b4b1471118f43a266048059e6a0ccd6c0e23b34322b1d6d379...
Downloading data: 0%| | 0.00/10.3G [00:00<?, ?B/s]
WARNING:datasets.download.download_manager:Computing checksums of downloaded files. They can be used for integrity verification. You can disable this by passing ignore_verifications=True to load_dataset
Computing checksums: 100%|##########| 1/1 [00:54<00:00, 54.05s/it]
Generating train split: 0 examples [00:00, ? examples/s]
Generating test split: 0 examples [00:00, ? examples/s]
Dataset zeroth_korean downloaded and prepared to /root/.cache/huggingface/datasets/kresnik___zeroth_korean/clean/1.0.1/e5d146fc495c84b4b1471118f43a266048059e6a0ccd6c0e23b34322b1d6d379. Subsequent calls will reuse this data.
0%| | 0/2 [00:00<?, ?it/s]test_ds = ds["test"]type(test_ds)datasets.arrow_dataset.Datasetdef map_to_array(batch):
speech, sr = sf.read(batch["file"])
batch["speech"] = speech
return batchtest_ds = test_ds.map(map_to_array) 0%| | 0/457 [00:00<?, ?ex/s]def map_to_pred(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
inputs_values = inputs.input_values.to("cuda")
with torch.no_grad():
logits = model(inputs_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = test_ds.map(map_to_pred, batched=True, batch_size=16)
0%| | 0/29 [00:00<?, ?ba/s]print("WER:",wer(result['text'], result['transcription']))WER: 0.048034934497816595flask
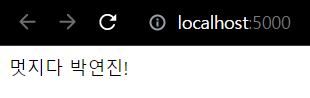
!pip install flaskfrom flask import Flaskapp = Flask(__name__)
@app.route("/")
def anyname():
return "멋지다 박연진!"
@app.route("/app1")
def app1():
return "스튜어디스 혜정입니다"
@app.route("/app2")
def app2():
return "기상캐스터 박연진입니다"
app.run(host="localhost", port=5000)- 같은 와이파이를 공유한 다른 사람이 접속하려면
app.run(host="본인ip주소", port=5000)- 본인 ip주소 확인방법
명령 프롬프트에서 ipconfig 입력 -> 무선 LAN 어댑터 Wi-Fi
화면출력



DL 공부중
🐧