새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
연기 탐지 모델
데이터셋 다운로드
!pwd/content!git clone https://github.com/ultralytics/yolov5
%cd yolov5
!pip install -qr requirements.txtCloning into 'yolov5'...
remote: Enumerating objects: 14740, done.[K
remote: Counting objects: 100% (85/85), done.[K
remote: Compressing objects: 100% (47/47), done.[K
remote: Total 14740 (delta 53), reused 66 (delta 38), pack-reused 14655[K
Receiving objects: 100% (14740/14740), 13.83 MiB | 18.66 MiB/s, done.
Resolving deltas: 100% (10136/10136), done.
/content/yolov5
[K |████████████████████████████████| 182 kB 28.3 MB/s
[K |████████████████████████████████| 62 kB 1.6 MB/s
[K |████████████████████████████████| 1.6 MB 67.3 MB/s
[?25h%mkdir /content/yolov5/smoke
%cd /content/yolov5/smoke
!curl -L "https://public.roboflow.com/ds/GunKrpRfuA?key=mf3GDXaik6" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip/content/yolov5/smoke
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 901 100 901 0 0 1113 0 --:--:-- --:--:-- --:--:-- 1115
100 27.6M 100 27.6M 0 0 7071k 0 0:00:04 0:00:04 --:--:-- 9472k
Archive: roboflow.zip
extracting: test/images/ck0rqdyeq4kxa08633xv2wqe1_jpeg.rf.30df6babe258cdc1d5a4e042262665e4.jpg
extracting: test/images/ck0qd918zic840701hnezgpgy_jpeg.rf.30de65aa3639b8a113db71a11bc2726c.jpg
extracting: test/images/ck0kfjen48qhj0701wjkosmel_jpeg.rf.49b365cc7135deee1332e6657401abc5.jpg 생략
#파일 생성
from glob import glob
train_img_list = glob('/content/yolov5/smoke/train/images/*.jpg')
test_img_list = glob('/content/yolov5/smoke/test/images/*.jpg')
valid_img_list = glob('/content/yolov5/smoke/valid/images/*.jpg')
len(train_img_list), len(test_img_list), len(valid_img_list)
(516, 74, 147)with open('/content/yolov5/smoke/train.txt','w') as f:
f.write('\n'.join(train_img_list)+'\n') #이미지목록은 한 줄에 이미지 하나씩, \n:줄바꿈
with open('/content/yolov5/smoke/test.txt','w') as f:
f.write('\n'.join(test_img_list)+'\n')
with open('/content/yolov5/smoke/valid.txt','w') as f:
f.write('\n'.join(valid_img_list)+'\n')
#test.txt에 있는 경로는 절대경로로 되어 있음
#/content/yolov5/smoke/test/images/ck0ujkl8y85nx0a4678ht59jh_jpeg.rf.b637ddfa23b935bf48c28df4f7d93665.jpg#파일수정
from IPython.core.magic import register_line_cell_magic
@register_line_cell_magic
def writetemplate(line,cell):
with open(line,'w') as f:
f.write(cell.format(**globals()))%cat /content/yolov5/smoke/data.yamltrain: ../train/images
val: ../valid/images
nc: 1
names: ['smoke']%%writetemplate /content/yolov5/smoke/data.yaml
train: ./smoke/train/images
test: ./smoke/test/images
val: ./smoke/valid/images
nc: 1 #클래스 1개, 클래스는 레이블링할 때 정한다.
names: ['smoke']%cat /content/yolov5/smoke/data.yaml #변경내용 확인train: ./smoke/train/images
test: ./smoke/test/images
val: ./smoke/valid/images
nc: 1 #클래스 1개, 클래스는 레이블링할 때 정한다.
names: ['smoke']### 모델 구성
#이미지파일의 목록리스트가 필요
```python
import yaml
with open('/content/yolov5/smoke/data.yaml','r') as stream:
num_classes = str(yaml.safe_load(stream)['nc'])num_classes'1'%cat /content/yolov5/models/yolov5s.yaml# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]%%writetemplate /content/yolov5/models/custom_yolov5s.yaml
# Parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]%cat /content/yolov5/models/custom_yolov5s.yaml# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]학습(Training)
img: 입력 이미지 크기 정의batch: 배치 크기 결정epochs: 학습 기간 개수 정의data: yaml 파일 경로cfg: 모델 구성 지정weights: 가중치에 대한 경로 지정name: 결과 이름nosave: 최종 체크포인트만 저장cache: 빠른 학습을 위한 이미지 캐시
!pwd/content/yolov5/smoke%cd .. /content/yolov5%%time
!python train.py --img 640 --batch 32 --epochs 100 \
--data ./smoke/data.yaml --cfg ./models/custom_yolov5s.yaml \
--name smoke_result --cache[34m[1mtrain: [0mweights=yolov5s.pt, cfg=./models/custom_yolov5s.yaml, data=./smoke/data.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=100, batch_size=32, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=smoke_result, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
[34m[1mgithub: [0mup to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v7.0-42-g5545ff3 Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
[34m[1mhyperparameters: [0mlr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
[34m[1mClearML: [0mrun 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML
[34m[1mComet: [0mrun 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
[34m[1mTensorBoard: [0mStart with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
100% 755k/755k [00:00<00:00, 165MB/s]
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 262MB/s]
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
custom_YOLOv5s summary: 214 layers, 7022326 parameters, 7022326 gradients, 15.9 GFLOPs
Transferred 342/349 items from yolov5s.pt
[34m[1mAMP: [0mchecks passed ✅
[34m[1moptimizer:[0m SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
[34m[1malbumentations: [0mBlur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
[34m[1mtrain: [0mScanning /content/yolov5/smoke/train/labels... 516 images, 0 backgrounds, 0 corrupt: 100% 516/516 [00:00<00:00, 2141.21it/s]
[34m[1mtrain: [0mNew cache created: /content/yolov5/smoke/train/labels.cache
[34m[1mtrain: [0mCaching images (0.4GB ram): 100% 516/516 [00:01<00:00, 266.35it/s]
[34m[1mval: [0mScanning /content/yolov5/smoke/valid/labels... 147 images, 0 backgrounds, 0 corrupt: 100% 147/147 [00:00<00:00, 1025.94it/s]
[34m[1mval: [0mNew cache created: /content/yolov5/smoke/valid/labels.cache
[34m[1mval: [0mCaching images (0.1GB ram): 100% 147/147 [00:01<00:00, 104.59it/s]
[34m[1mAutoAnchor: [0m4.72 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train/smoke_result/labels.jpg...
Image sizes 640 train, 640 val
Using 2 dataloader workers
Logging results to [1mruns/train/smoke_result[0m
Starting training for 100 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/99 7.32G 0.112 0.02681 0 5 640: 100% 17/17 [00:10<00:00, 1.68it/s]
Class Images Instances P R mAP50 mAP50-95: 100% 3/3 [00:02<00:00, 1.08it/s]
all 147 147 0.00093 0.279 0.00127 0.000343
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
1/99 8.34G 0.09122 0.02224 0 7 640: 100% 17/17 [00:06<00:00, 2.51it/s]
Class Images Instances P R mAP50 mAP50-95: 100% 3/3 [00:01<00:00, 1.94it/s]
all 147 147 0.00134 0.401 0.00116 0.000298
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
2/99 8.34G 0.07568 0.02194 0 7 640: 100% 17/17 [00:07<00:00, 2.38it/s]
Class Images Instances P R mAP50 mAP50-95: 100% 3/3 [00:01<00:00, 2.14it/s]
all 147 147 0.00268 0.803 0.0291 0.00676 중략
%load_ext tensorboard
%tensorboard --logdir runs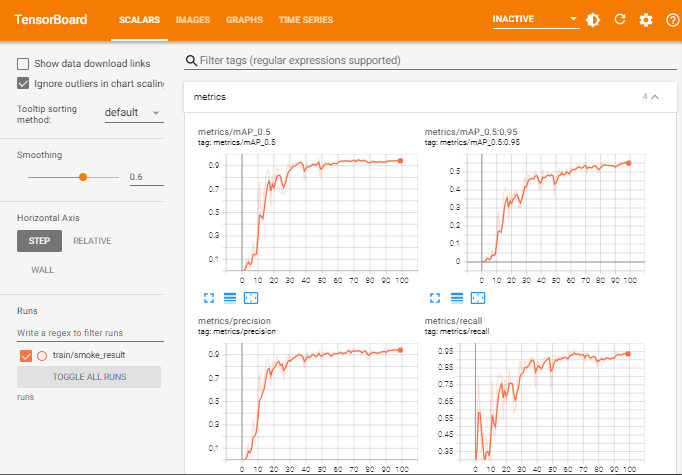
!ls /content/yolov5/runs/train/smoke_results/ls: cannot access '/content/yolov5/runs/train/smoke_results/': No such file or directoryfrom IPython.display import Image
Image(filename='/content/yolov5/runs/train/smoke_result/results.png',width=1000)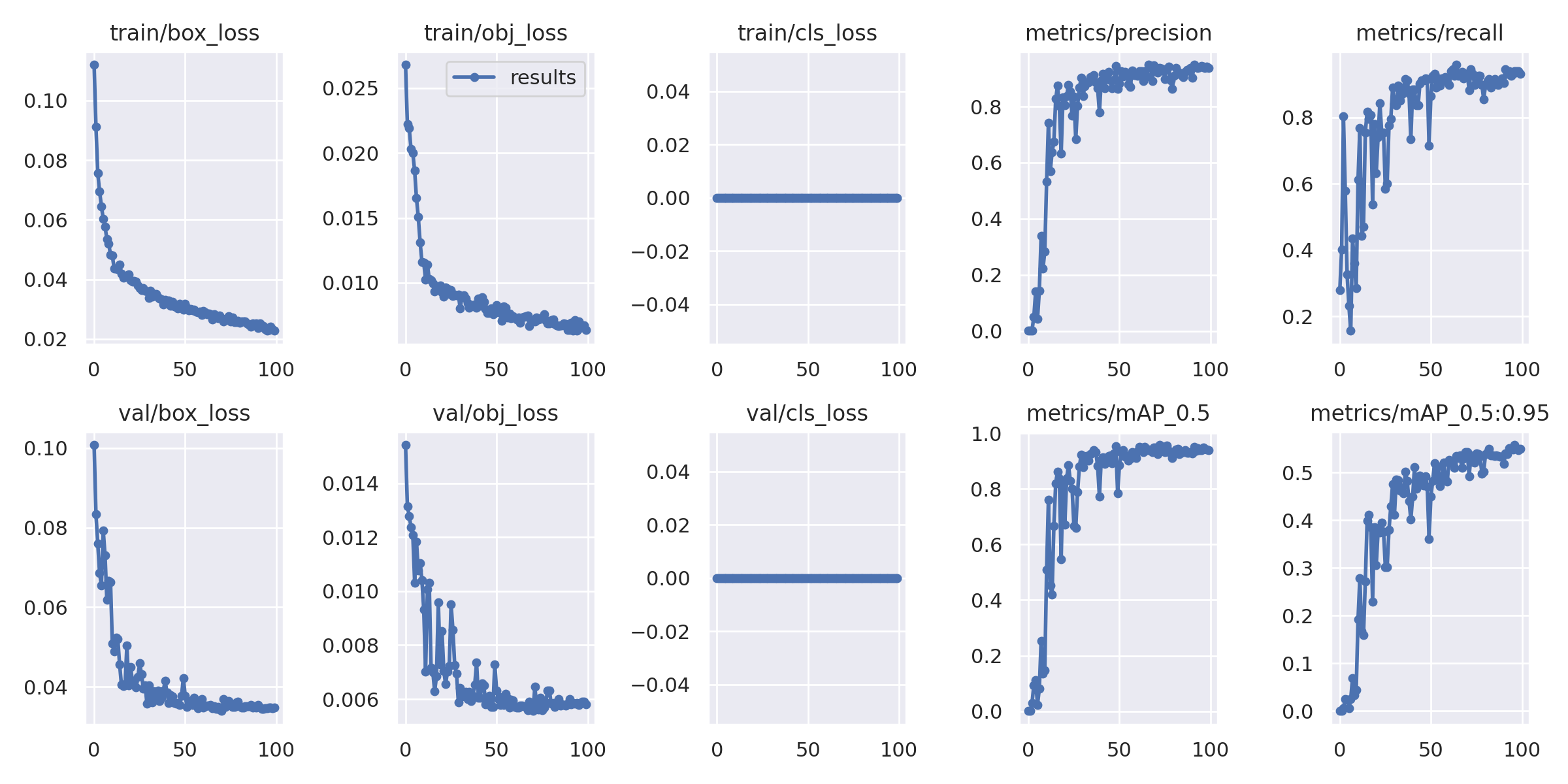
Image(filename='/content/yolov5/runs/train/smoke_result/train_batch0.jpg',width=1000)
Image(filename='/content/yolov5/runs/train/smoke_result/val_batch0_labels.jpg',width=1000)
검증(Validation)
!python val.py --weights runs/train/smoke_result/weights/best.pt --data ./smoke/data.yaml --img 640 --iou 0.65 --half[34m[1mval: [0mdata=./smoke/data.yaml, weights=['runs/train/smoke_result/weights/best.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
YOLOv5 🚀 v7.0-42-g5545ff3 Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
custom_YOLOv5s summary: 157 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
[34m[1mval: [0mScanning /content/yolov5/smoke/valid/labels.cache... 147 images, 0 backgrounds, 0 corrupt: 100% 147/147 [00:00<?, ?it/s]
Class Images Instances P R mAP50 mAP50-95: 100% 5/5 [00:03<00:00, 1.39it/s]
all 147 147 0.944 0.939 0.948 0.557
Speed: 0.2ms pre-process, 4.8ms inference, 1.9ms NMS per image at shape (32, 3, 640, 640)
Results saved to [1mruns/val/exp[0m!python val.py --weights runs/train/smoke_result/weights/best.pt --data ./smoke/data.yaml --img 640 --task test[34m[1mval: [0mdata=./smoke/data.yaml, weights=['runs/train/smoke_result/weights/best.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=test, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val, name=exp, exist_ok=False, half=False, dnn=False
YOLOv5 🚀 v7.0-42-g5545ff3 Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
custom_YOLOv5s summary: 157 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
[34m[1mtest: [0mScanning /content/yolov5/smoke/test/labels... 74 images, 0 backgrounds, 0 corrupt: 100% 74/74 [00:00<00:00, 342.83it/s]
[34m[1mtest: [0mNew cache created: /content/yolov5/smoke/test/labels.cache
Class Images Instances P R mAP50 mAP50-95: 100% 3/3 [00:02<00:00, 1.38it/s]
all 74 74 0.852 0.932 0.939 0.547
Speed: 0.2ms pre-process, 7.1ms inference, 2.6ms NMS per image at shape (32, 3, 640, 640)
Results saved to [1mruns/val/exp2[0m추론(Inference)
%ls runs/train/smoke_result/weightsbest.pt last.pt!python detect.py --weights runs/train/smoke_result/weights/best.pt --img 640 --conf 0.4 --source ./smoke/test/images[34m[1mdetect: [0mweights=['runs/train/smoke_result/weights/best.pt'], source=./smoke/test/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.4, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-42-g5545ff3 Python-3.8.16 torch-1.13.0+cu116 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
custom_YOLOv5s summary: 157 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
image 1/74 /content/yolov5/smoke/test/images/ck0kcoc8ik6ni0848clxs0vif_jpeg.rf.8b4629777ffe1d349cc970ee8af59eac.jpg: 480x640 1 smoke, 12.8ms
image 2/74 /content/yolov5/smoke/test/images/ck0kd4afx8g470701watkwxut_jpeg.rf.bb5a1f2c2b04be20c948fd3c5cec33ff.jpg: 480x640 1 smoke, 10.1ms
image 3/74 /content/yolov5/smoke/test/images/ck0kdhymna0b10721v4wntit8_jpeg.rf.a08e34d04fb672ce6cf8e94e810ec81d.jpg: 480x640 1 smoke, 10.0ms
image 4/74 /content/yolov5/smoke/test/images/ck0kepbs9kdym0848hgpcf3y9_jpeg.rf.d0a63becb54a83b6b026f4b38a42933b.jpg: 480x640 1 smoke, 10.0ms 중략import glob
import random
from IPython.display import Image, display
image_name = random.choice(glob.glob('/content/yolov5/runs/detect/exp/*.jpg'))
display(Image(filename=image_name))
모델 내보내기
from google.colab import drive
drive.mount('/content/drive')Mounted at /content/drive%cp /content/yolov5/runs/train/smoke_result/weights/best.pt '/content/drive/MyDrive/Colab Notebooks/sesac_deeplerning/model/18_yolov5_smokeDetectron2
- 페이스북 인공지능 연구소(FAIR)에서 개발한 객체 세그멘테이션 프레임워크
- 페이스북에서 개발한 DensePose, Mask R-CNN 등을 Detectron2에서 제공
- 손쉽게 다양한 사물들을 탐지하고 세그먼테이션하여, 객체의 유형, 크기, 위치 등을 자동으로 얻을 수 있음
Detectron2 설치
- Tutorial: https://detectron2.readthedocs.io/tutorials/install.html
- Detectron2: https://dl.fbaipublicfiles.com/detectron2/wheels/cu102/torch1.9/index.html
!pip install pyyaml==5.3.1
!pip install torch==1.9.0+cu102 torchvision==0.10.0+cu102 -f https://download.pytorch.org/whl/torch_stable.html
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu102/torch1.9/index.html
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting pyyaml==5.3.1
Downloading PyYAML-5.3.1.tar.gz (269 kB)
[K |████████████████████████████████| 269 kB 26.5 MB/s 생략
import torch,torchvision
print(torch.__version__,torch.cuda.is_available())1.9.0+cu102 Trueimport detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
import numpy as np
import os,json,cv2,random #detectron2이 json파일로 레이블링 되어있음
from google.colab.patches import cv2_imshow
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog,DatasetCatalog
사전 모델
{kind=link}
!wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
im = cv2.imread('./input.jpg')
cv2_imshow(im)
- Config 파일: COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml
cfg = get_cfg() #InstanceSegmentation : 사람이면 사람, 말이면 말, mask_rcnn : model
cfg.merge_from_file(model_zoo.get_config_file('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml'))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST=0.5 #임곗값
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml') #cfg.MODEL.WEIGHTS :모델에 학습된 가중치
predictor = DefaultPredictor(cfg)
outputs = predictor(im)model_final_f10217.pkl: 178MB [00:30, 5.85MB/s]
/usr/local/lib/python3.8/dist-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /pytorch/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)print(outputs['instances'].pred_classes) #15,0,25,24 class 검출됨
print(outputs['instances'].pred_boxes) #[126.6035, 244.8977, 459.8291, 480.0000] = 17tensor([17, 0, 0, 0, 0, 0, 0, 0, 25, 0, 25, 25, 0, 0, 24],
device='cuda:0')
Boxes(tensor([[126.6035, 244.8977, 459.8291, 480.0000],
[251.1083, 157.8127, 338.9731, 413.6379],
[114.8496, 268.6864, 148.2352, 398.8111],
[ 0.8217, 281.0327, 78.6072, 478.4210],
[ 49.3954, 274.1229, 80.1545, 342.9808],
[561.2248, 271.5816, 596.2755, 385.2552],
[385.9072, 270.3125, 413.7130, 304.0397],
[515.9295, 278.3744, 562.2792, 389.3802],
[335.2409, 251.9167, 414.7491, 275.9375],
[350.9300, 269.2060, 386.0984, 297.9081],
[331.6292, 230.9996, 393.2759, 257.2009],
[510.7349, 263.2656, 570.9865, 295.9194],
[409.0841, 271.8646, 460.5582, 356.8722],
[506.8767, 283.3257, 529.9403, 324.0392],
[594.5663, 283.4820, 609.0577, 311.4124]], device='cuda:0'))v = Visualizer(im[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2) #[:,:,::-1] : 반전(bgr)
out = v.draw_instance_predictions(outputs['instances'].to('cpu'))
cv2_imshow(out.get_image()[:,:,::-1])
커스텀 데이터셋 학습
데이터셋 준비
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip balloon_dataset.zip # inflating: balloon/train/via_region_data.json : 답지--2022-12-20 06:48:33-- https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
Resolving github.com (github.com)... 20.205.243.166
Connecting to github.com (github.com)|20.205.243.166|:443... connected.
HTTP request sent, awaiting response... 302 Found 생략from detectron2.structures import BoxMode
#json파일이랑 이미지랑 합쳐서 같이 볼 수 있게끔
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir,'via_region_data.json') #os.path.join : 전체 경로 만들기
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = [] #비어있는 리스트
for idx , v in enumerate(imgs_anns.values()): #imgs_anns안에 있는 values , 딕셔너리안에 값만 뽑고 싶으면 values {'fileref'~}
record = {}
filename = os.path.join(img_dir,v['filename'])
height,width = cv2.imread(filename).shape[:2] #.shape[] : ( 넓이(행), 높이(열), 채널)
record['file_name'] = filename
record['image_id'] = idx
record['height'] = height
record['width'] = width
annos = v['regions']
objs = []
for _,anno in annos.items(): #key, value값을 묶어서 튜플로 출력한다.
anno = anno['shape_attributes']
px = anno['all_points_x']
py = anno['all_points_y']
poly = [(x+0.5,y+0.5) for x,y in zip(px,py)] #같은 거 끼리 튜플로 묶음 : zip
poly = [ p for x in poly for p in x]
obj = {
'bbox':[np.min(px),np.min(py),np.max(px),np.max(py)],
'bbox_mode':BoxMode.XYXY_ABS,
'segmentation':[poly],
'category_id':0,
}
objs.append(obj)
record['annotations'] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in ['train','val']:
DatasetCatalog.register('balloon_'+ d,lambda d=d:get_balloon_dicts('balloon/'+d))
MetadataCatalog.get('balloon_'+d).set(thing_classes=['balloon'])
balloon_metadata = MetadataCatalog.get('balloon_train')dataset_dicts = get_balloon_dicts('balloon/train')
for d in random.sample(dataset_dicts,2):
img = cv2.imread(d['file_name'])
visualizer = Visualizer(img,metadata=balloon_metadata,scale=0.5)
out = visualizer.draw_dataset_dict(d)
cv2_imshow(out.get_image()) 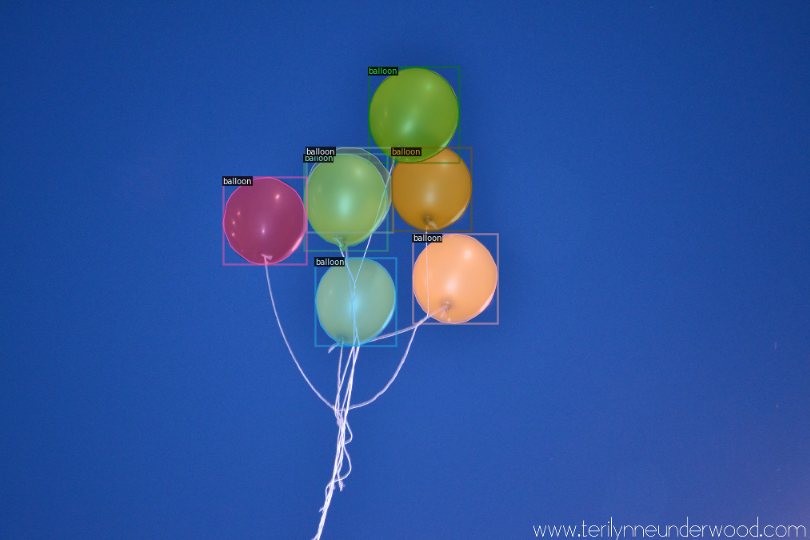

학습
- Config 파일: COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml
from detectron2.engine import DefaultTrainer
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml'))
cfg.DATASETS.TRAIN = ('balloon_train',) #튜플은 ()안에 들어가는 값이 1개라면 뒤에 , 적어줘야 함
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKER = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml')
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
cfg.SOLVER.MAX_ITER = 300
cfg.SOLVER.STEPS = []
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1
os.makedirs(cfg.OUTPUT_DIR,exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()[12/20 07:06:57 d2.engine.defaults]: Model:
GeneralizedRCNN(
(backbone): FPN(
(fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 생략
%load_ext tensorboard
%tensorboard --logdir output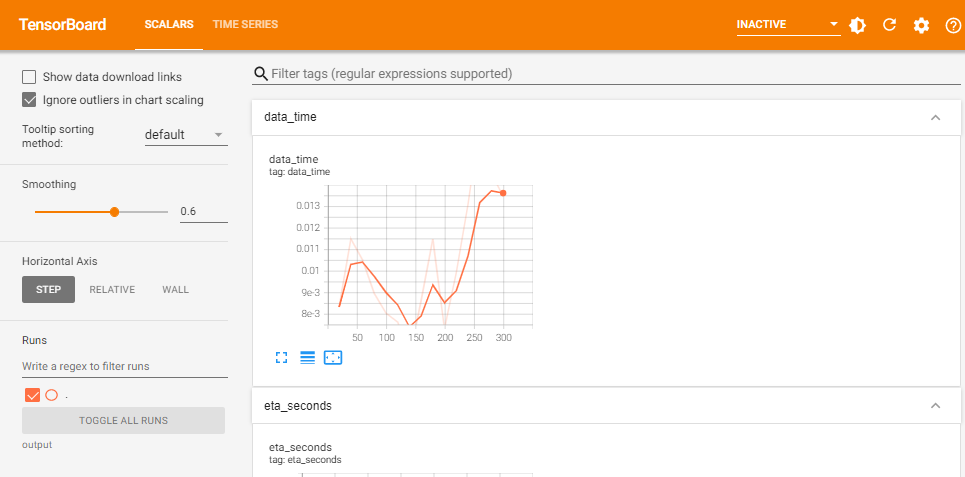
추론 및 평가
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR,'model_final.pth')
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
predictor = DefaultPredictor(cfg)from detectron2.utils.visualizer import ColorMode #detect만 컬러로 남기고 나머지는 그레이스케일처리
dataset_dicts = get_balloon_dicts('balloon/val')
for d in random.sample(dataset_dicts,3):
img = cv2.imread(d['file_name'])
outputs = predictor(img)
visualizer = Visualizer(img,
metadata=balloon_metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW)
out = visualizer.draw_instance_predictions(outputs['instances'].to('cpu'))
cv2_imshow(out.get_image())


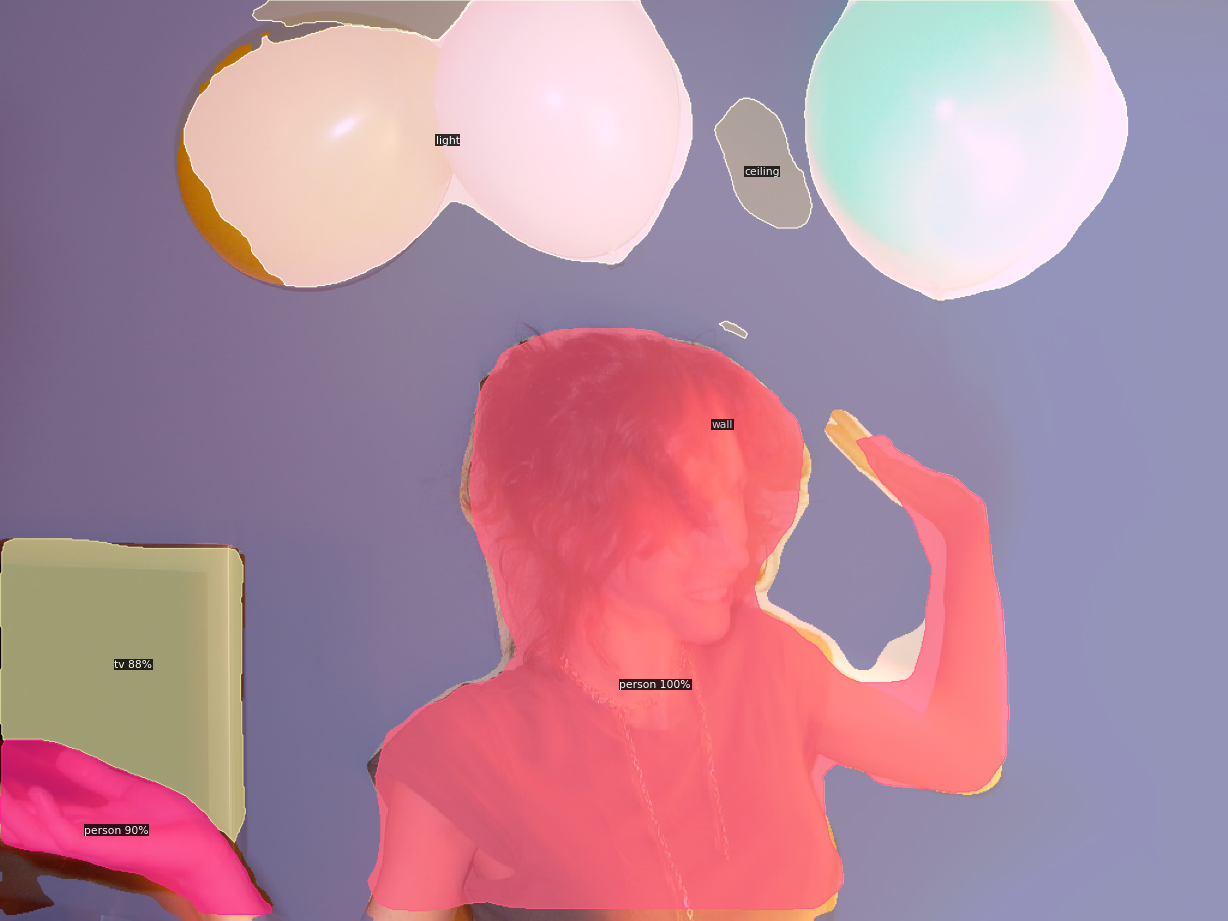
다른 타입 적용
- Config 파일: COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml'))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml')
predictor = DefaultPredictor(cfg)
outputs = predictor(img)
v = Visualizer(img[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
out = v.draw_instance_predictions(outputs['instances'].to('cpu'))
cv2_imshow(out.get_image()[:,:,::-1])model_final_a6e10b.pkl: 237MB [00:26, 8.81MB/s] 
- Config 파일: COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file('COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml'))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url('COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml')
predictor = DefaultPredictor(cfg)
panoptic_seg,segments_info = predictor(img)['panoptic_seg']
v = Visualizer(img[:,:,::-1],MetadataCatalog.get(cfg.DATASETS.TRAIN[0]),scale=1.2)
out = v.draw_panoptic_seg_predictions(panoptic_seg.to('cpu'),segments_info)
cv2_imshow(out.get_image()[:,:,::-1])model_final_cafdb1.pkl: 261MB [00:39, 6.54MB/s] 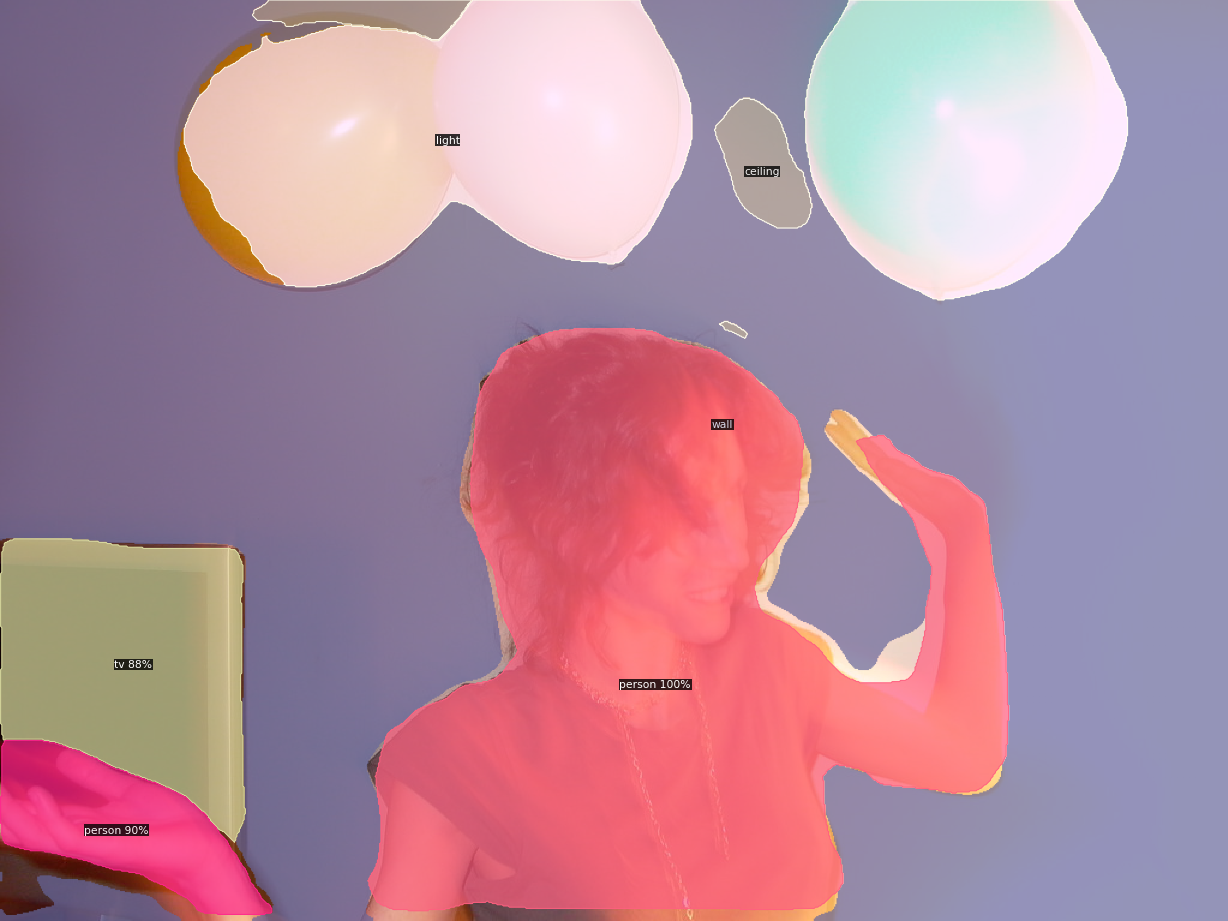
비디오 파일 적용
from IPython.display import YouTubeVideo, display
video = YouTubeVideo('ll8TgCZ0plk',width=600)
display(video)!ffmpeg -i "/content/drive/MyDrive/Colab Notebooks/sesac_deeplearning/video.mp4" -t 00:00:06 -c:v copy video-clip.mp4ffmpeg version 3.4.11-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 7 (Ubuntu 7.5.0-3ubuntu1~18.04)
configuration: --prefix=/usr --extra-version=0ubuntu0.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --enable-gpl --disable-stripping --enable-avresample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librubberband --enable-librsvg --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzmq --enable-libzvbi --enable-omx --enable-openal --enable-opengl --enable-sdl2 --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libopencv --enable-libx264 --enable-shared
libavutil 55. 78.100 / 55. 78.100
libavcodec 57.107.100 / 57.107.100
libavformat 57. 83.100 / 57. 83.100
libavdevice 57. 10.100 / 57. 10.100
libavfilter 6.107.100 / 6.107.100
libavresample 3. 7. 0 / 3. 7. 0
libswscale 4. 8.100 / 4. 8.100
libswresample 2. 9.100 / 2. 9.100
libpostproc 54. 7.100 / 54. 7.100
[1;31m/content/drive/MyDrive/Colab Notebooks/sesac_deeplearning/video.mp4: No such file or directory
[0m- detectron2 github: https://github.com/facebookresearch/detectron2
- detectron2 config file: detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml
- model weights: detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl
from google.colab import drive
drive.mount('/content/drive')Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).detectron2 github: https://github.com/facebookresearch/detectron2
detectron2 config file: detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml
model weights: detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl
!git clone https://github.com/facebookresearch/detectron2
%run detectron2/demo/demo.py \
--config-file detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml \
--video-input video-clip.mp4 \
--confidence-threshold 0.6 \
--output video-output.mkv \
--opts MODEL.WEIGHTS detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pklCloning into 'detectron2'...
remote: Enumerating objects: 14678, done.[K
remote: Counting objects: 100% (94/94), done.[K
remote: Compressing objects: 100% (71/71), done.[K
remote: Total 14678 (delta 36), reused 54 (delta 23), pack-reused 14584[K
Receiving objects: 100% (14678/14678), 6.02 MiB | 6.44 MiB/s, done.
Resolving deltas: 100% (10594/10594), done.
[12/20 07:35:49 detectron2]: Arguments: Namespace(confidence_threshold=0.6, config_file='detectron2/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml', input=None, opts=['MODEL.WEIGHTS', 'detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl'], output='video-output.mkv', video_input='video-clip.mp4', webcam=False)
[12/20 07:35:50 fvcore.common.checkpoint]: [Checkpointer] Loading from detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl ...
[12/20 07:35:50 fvcore.common.checkpoint]: Reading a file from 'Detectron2 Model Zoo'
95%|█████████▍| 36/38 [00:29<00:01, 1.20it/s]```python
#드라이브에 다운로드 받기
from google.colab import files
files.download('video-output.mkv')
DL 공부중