
새싹 인공지능 응용sw 개발자 양성 교육 프로그램 나예진 강사님 수업 정리 글입니다. (나예진 강사님 이메일: nayejin11@gmail.com)
목차
1. 데이터크롤링
2. api를 활용한 데이터 크롤링
1. 데이터 크롤링
#api 통신을 할 때 사용하는 라이브러리
import requests
#가져온 페이지의 html을 파싱하는 라이브러리
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
#지정한 url로 페이지를 가져오는 요청을 생성함
res = requests.get(url) #네이버한테 허락을 받는 것
res.raise_for_status()
#요청을 통해 가져온 페이지를 BeautifulSoup로 파싱함
#lxml : html 및 xml 의 파싱을 간편하게 도와주는 라이브러리
soup = BeautifulSoup(res.text,"lxml") #res.txt에 해당하는 것만 가져올꺼야
#BeautifylSoup의 객체의 자료형 출력
print(type(soup))
>> <class 'bs4.BeautifulSoup'>
BeautifulSoup
soup = BeautifulSoup(res.text, "lxml")데이터를 주어주고 "lxml"의 형식으로 저장한다.
soup이라는 객체를 생성, soup에서 필요한 정보를 가져오기 위해 사용
res.raise_for_status()
에러코드 해결방법, 에러가 났다는 걸 알려주는 코드. 만약 에러가 있다면 멈춰주고 에러를 알려준다.
#html문서의 head 태그에 해당하는 내용 출력
print(soup.head)
>><head>
<meta content="IE=edge,chrome=1" http-equiv="X-UA-Compatible"/>
<meta content="text/html; charset=utf-8" http-equiv="Content-type"/>
<title>네이버 웹툰 > 요일별 웹툰 > 전체웹툰</title>
<meta content="네이버 웹툰" property="og:title"/>
<meta content="https://ssl.pstatic.net/static/comic/images/og_tag_v2.png" property="og:image"/>
<meta content="매일매일 새로운 재미, 네이버 웹툰." property="og:description"/>
<meta content="https://comic.naver.com/webtoon/weekday" property="og:url"/>
<meta content="article" property="og:type"/>
<meta content="네이버 웹툰" property="og:article:author"/>
<meta content="https://comic.naver.com" property="og:article:author:url"/>
<link href="https://ssl.pstatic.net/static/comic/favicon/webtoon_favicon_32x32.ico" rel="shortcut icon" type="image/x-icon"/>
<link href="/css/comic/comic_20221109182113.css" rel="stylesheet" style="text/css"/>
<!-- comicWeekdayJsFile -->
<script charset="utf-8" src="/aggregate/javascript/release/comic_weekday_20221109182113.js" type="text/javascript"></script>
<script type="text/javascript">
//<![CDATA[
var g_ssc = "comic.webtoon";
var ccsrv = "cc.naver.com";
//]]>
</script>
<script src="/aggregate/javascript/release/comic_gnb_20221109182113.js" type="text/javascript"></script>
</head>
#html문서의 'body' 태그에 해당하는 내용 출력
print("-------soup.body-------")
print(soup.body)
#html문서의 'title'태그에 해당하는 내용 출력
print("-------soup.title-------")
print(soup.title)
#html문서의 'title'태그에 해당하는 내용 출력
print("-------soup.title.name-------")
print(soup.title.name)
#html문서의 'title'태그에 해당하는 내용 출력
print("-------soup.title.stirng-------")
print(soup.title.string)
enumerate
#enumerate() 함수는 기본적으로 for문 및 반복문들의 실행시 (인덱스, 원소) 형식으로 이루어진 튜플을 만들어줌
for test in enumerate(webtoons):
print(test)
#a태그를 가져온 리스트중 title만 뽑아와서 새로 리스트 화
webtoonRankList1 = [(str(idx), webtoon.get("title")) for (idx, webtoon) in enumerate(webtoons, start=1)]
print(webtoonRankList1)
#a태그를 가져온 리스트중 title만 뽑아와서 새로 리스트 화
webtoonRankList = []
for (idx, webtoon) in enumerate(webtoons, start=1):
title = webtoon.get("title")
print(f"#{str(idx)} : {title}")
data = [str(idx), title]
webtoonRankList.append(data)
print(webtoonRankList)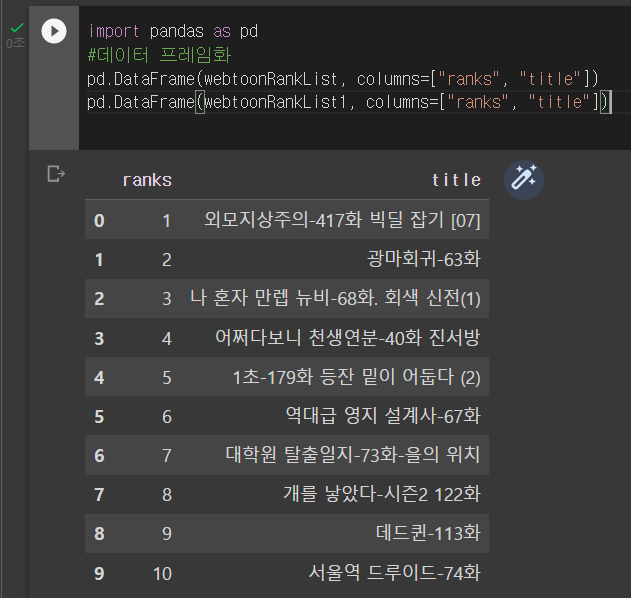
요일별 전체웹툰 크롤링
url2 = "https://comic.naver.com/webtoon/weekday"
#지정한 url로 페이지를 가져오는 요청을 생성함
res2 = requests.get(url2)
res2.raise_for_status()
#요청을 통해 가져온 페이지를 BeautifulSOup로 파싱함
soup2 = BeautifulSoup(res2.text,"lxml")
#div태그 중에 class명이 list_area daily_all 인 html요소들을 가져옴
webtoonByDayClass = soup2.find("div", attrs = {"class":"list_area daily_all"})
print("-------webtoonByDay-------")
print(webtoonByDayClass)
#가져온 html요소들 중 img태그를 가져옴 (a태그는 두개가 있어서 반값이 들어감)
webtoonByDaylmg = webtoonByDayClass.find_all('img')
print("-------webtoonByDayA-------")
print(webtoonByDaylmg)
#a태그를 가져온 리스트중 title만 뽑아와서 새로 리스트 화
webtoonByDayList = []
for (idx, webtoon) in enumerate(webtoonByDaylmg, start=1):
title = webtoon.get("title")
#혹시나 title이 없는 경우에는 아래의 내용을 실행하지 않기위함.
if title == None:
continue
print(f"#{str(idx)}:{title}")
data = [str(idx), title]
webtoonByDayList.append(data)
print(webtoonByDayList)
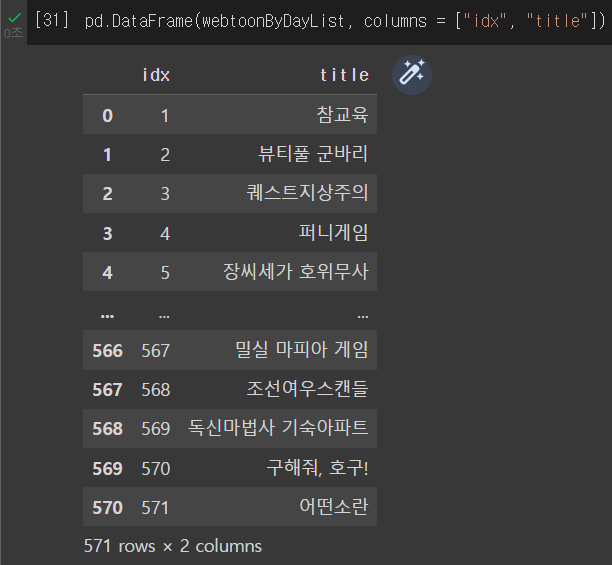
섬네일링크가져오기 + 요일 태깅
#요일까지 가져오기 위해서는 다른 col_inner라는 태그안의 h4태그의 text를 가져와야 함
webtoonByDayCol = webtoonByDayClass.find_all("div", attrs = {"class" : "col_inner"})
print(webtoonByDayCol)
webtoonByDayListWithImg = []
i = 1
for (idx, webtoon) in enumerate(webtoonByDayCol, start=1):
#가져온 html 태그 중 h4 태그의test를 가져옴
h4 = webtoon.find("h4").text
#가져온 html 태그 중 img 태그를 모두 가져와서 리스트 화
imgs = webtoon.find_all("img")
print(h4)
print(imgs)
#리스트 화 된 img태그들을 반복문을 통해 정제
for img in imgs:
title = img.get("title")
#img태그 중 src요소에 섬네일 주소가 담겨있음.
thumbnail = img.get("src")
if title == None:
continue
print(f"#{str(i)}: {h4}, {title}, {thumbnail}")
data = [str(i), h4, title, thumbnail]
i += 1
webtoonByDayListWithImg.append(data)2. api를 활용한 데이터 크롤링
import os
import sys
import urllib.request
import json
client_id = " AwTbYio0d6px2I0XM3X8"
client_secret = "boMwE6PrO_"json: 블로그 검색은 검색 API를 사용해 네이버 검색의 블로그 검색 결과를 반환하는 RESTful API입니다. 블로그 검색 결과를 XML 형식 또는 JSON 형식으로 반환합니다.
Python
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)api를 통해 검새결과 가져오기
api 기본설명
api(application programmin interface)
응용 프포그램에서 사용할 수 있도록,
운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
import os
import sys
import urllib.request
#검색키워드
searchText = input("검색키워드 :")
query = urllib.parse.quote(searchText)
#출력건수(최대-100건)
display = input("검색 갯수(최대 100건) :")
#url에 요청 변수들 중 필수 변수는 반드시 넣어주어야 하며, 이외의 변수는 선택사항임
url = "https://openapi.naver.com/v1/search/blog"
query = f"?query={query}&display={display}&start=1&sort=sim"
#query = f"?query={query}&display={display}&start={start}&sort={sort}"
#url과 query를 연결해 요청을 생성
request = urllib.request.Request(url+query)
#네이버 api를 활용하기 위해 key값들을 요청 헤더에 추가
request.add_header("X-Naver-client-Id", client_id)
request.add_header("X-Naver-client-Secret", client_secret)
#위에서 생성한 요청에 대한 응답을 받아옴
response = urllib.request.urlopen(request)
print("getcode : ", response.getcode())
print("geturl : ", response.geturl())
#http의 응답코드를 가져옴
rescode = response.getcode()
#200인 경우 제대로된 응답을 가져온 경우
if(rescode==200):
response_body = response.read()
body = response_body.decode("utf-8")
print("body", body)
else:
print("Error Code:" + rescode)
#String형태로 return된 body값을 다루기 편리하도록 json형태로 변환
data = json.loads(body)
data
#json은 dictionary 자료형과 비슷하다고 생각하면 되며, dictionary처럼 key값으로 value값을 불러올 수 있음
print("lastBuildDate : ", data["lastBuildDate"])
print("total : ", data["total"])
print("start : ", data["start"])
print("display : ", data["display"])
print("items : ", data["items"])
#필요한 부분은 items에 딕셔너리의 리스트 형태로 존재하는 것을 알 수 있음
data["items"]
#제목만 따로 뽑아 리스트화 시킴
#</b>, <b> 제거
#제목만 따로 뽑아 리스트화 시킴
titleList = [i["title"] for i in data["items"]]
print("1: ", titleList)
#제목만 따로 뽑아 리스트화 시킴
titleList = [i["title"] for i in data["items"]]
print("1", titleList)
#문장 내의 불필요한 문자 제거1
titleList = [i["title"].replace("<b>","") for i in data["items"]]
print("2: ",titleList)
#문장 내의 불필요한 문자 제거2
titleList = [i["title"].replace("<b>","").replace("<b>", "") for i in data["items"]]
print("3: ",titleList)
#링크만 따로 뽑아 리스트화 시킴
linkList = [i["link"] for i in data["items"]]
print(linkList)
#제목, 블로그링크, 본문내용 dataframe으로 만들기 행 = series
import pandas as pd
df = pd.DataFrame({'제목':titleList, '링크':listList})
df공공데이터 분석
from google.colab import drive
drive.mount('/content/drive')
#라이브러리를 불러옵니다.
import pandas as pd- 데이터 불러오기
csv = ,로 구분된 데이터
#다운로드 받은 데이터 중 일부를 열어봅니다.
temp = pd.read_csv("/content/drive/MyDrive/파이썬기초/소상공인시장진흥공단_상가(상권)정보_인천_202209.csv",encoding='utf-8')
temp
#분석에 필요한 column을 고릅니다.
data = temp[['상호명', '지점명', '상권업종대분류명', '상권업종중분류명', '시도명', '시군구명', '행정동명']]
data
temp.info()
data.info()
#메모리 낭비를 막기 위해 필요없는 변수는 제거합니다.
del temp- 데이터 구경하기
#set 언제 쓰나요? 중복되어 있지 않은 그 고유한 값을 뽑을 때 !
set(data["상권업종대분류명"])
>>{'관광/여가/오락', '부동산', '생활서비스', '소매', '숙박', '스포츠', '음식', '학문/교육'}
#카페만 뽑아냅니다.
df_coffee = data[data["상권업종중분류명"] == "커피점/카페"]
#index를 다시 세팅합니다.
df_coffee.index = range(len(df_coffee))
print("인천 전국 커피 전문점 점포 수 : ", len(df_coffee))
df_coffee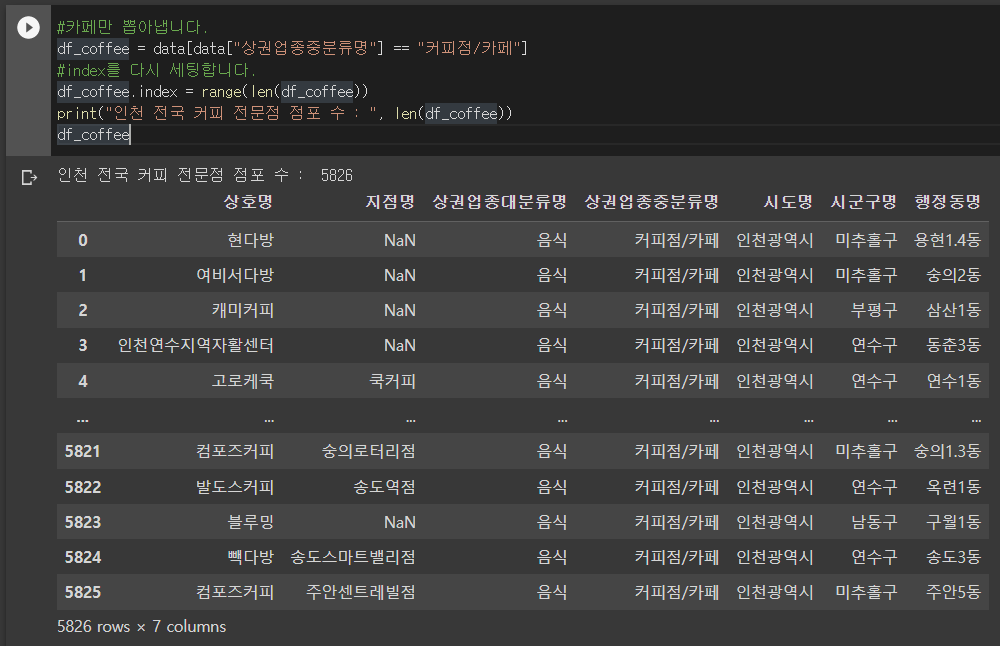
스타벅스
df_coffee_star = data[data["상호명"] == "스타벅스"]
df_coffee_star
df_coffee_star.index = range(len(df_coffee_star))
print("스타벅스 점포 수 : ", len(df_coffee_star))
df_coffee_star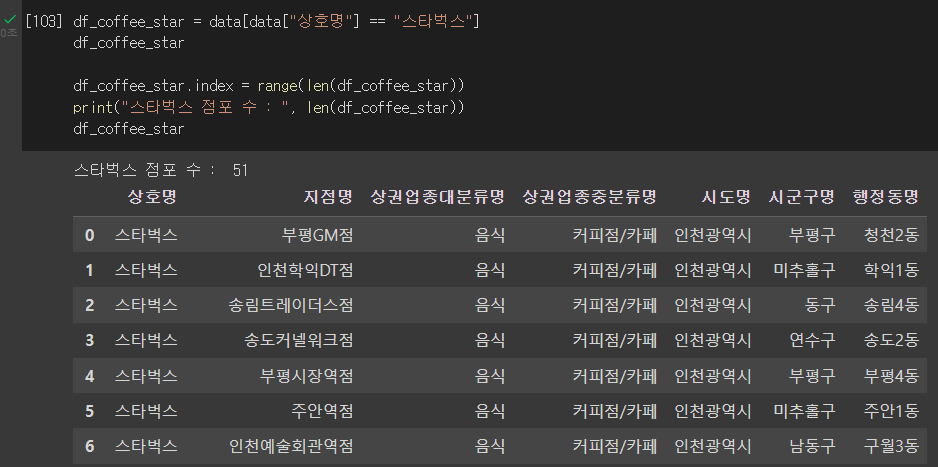

DL 공부중