프로세스 주소공간
-
프로세스 주소 공간은 일반적으로 코드, 데이터, 스택으로 나뉘어짐
-
각각 프로그램 소스 코드 저장, 전역 변수 저장, 함수,지역 변수 저장의 역할을 함
-
이런식으로 최대한 데이터를 공유하여 메모리 사용량을 줄일 수 있음, 이는 프로세스에서 다뤘는데 좀 더 자세히 다룬다면 먼저 구조를 자세히 보면
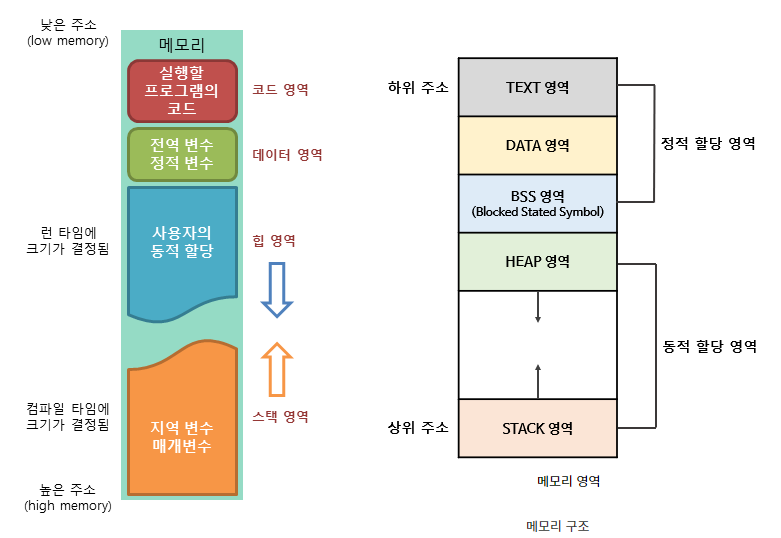
Code 영역(Text)
-
실행하는 프로그램의 소스코드가 들어가는 부분, 실행할 프로그램의 코드가 저장되는 영역임
-
코드영역은 실행 파일을 구성하는 명령어들이 올라가는 메모리 영역으로 함수, 제어문, 상수 등이 지정됨
-
컴파일 타임에 결정되고 중간에 코드를 바꿀 수 없게 Read-Only로 지정됨
Data 영역
-
프로그램의 전역 변수와 정적(static) 변수가 저장되는 영역, 프로그램이 구동되는 동안 항상 접근 가능한 변수가 저장되는 영역임
-
전역변수, static 값을 참조한 코드는 컴파일하고 나면 Data 영역의 주소값을 가르키도록 바뀜
-
데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸함
-
실행 중도에 전역변수가 변경 될 수도 있으니, 이 영역은 Read-Write로 지정됨
-
초기화 된 데이터는 Data영역에, 초기화 되지 않은 데이터는 BSS 영역에 저장됨
Stack 영역
-
함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역임
-
Stack은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸함
-
원시타입의 데이터가 값과 함께 할당됨
-
Heap 영역에 생성된 Object 타입의 데이터 참조값이 할당됨
-
메모리의 높은 주소에서 낮은 주소의 방향으로 할당됨
-
컴파일 타임에 크기가 결정되기 때문에 무한히 할당 할 수 없음, 재귀함수가 너무 깊게 호출되거나 함수가 지역변수를 너무 많이 가지고 있어 stack 영역을 초과하면 stack overflow 에러가 발생함
Heap 영역
-
런타임에 크기가 결정되는 메모리 영역임
-
사용자에 의해 메모리 공간이 동적으로 할당되고 해제됨
-
참조형의 데이터의 값이 저장됨
-
Heap은 메모리의 낮은 주소에서 높은 주소의 방향으로 할당됨
-
Heap과 Stack은 같은 공간을 공유함, Heap이 메모리 위쪽 주소부터 할당되면 Stack은 아래쪽부터 할당되는 식임, 그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 Heap Overflow, Stack Overflow라고 함
Data 영역과 BSS 영역을 구분하는 이유는?
BSS는 초기화 되지 않는 데이터를 할당하는 영역이고 초기화 된 데이터는 Data 영역에 할당함
이는 초기화되지 않는 변수는 프로그램이 실행될 때 영역을 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요가 없고 초기화가 되는 변수는 그 값도 프로그램에 저장하고 있어야 하기 때문임
그래서 BSS 영역 변수들이 많아져도 프로그램의 실행코드 사이즈를 늘리지 않음
