
1. SQL과 NOSQL의 차이
(1) SQL (관계형 DB)
SQL(Structured Query Language)을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색을 할 수 있다. 데이터들의 관계를 정의하고 분석하는데 최적화 되어 있다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.
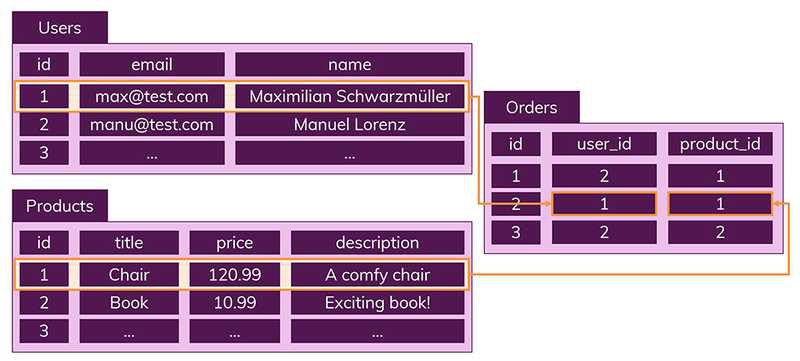
또한, 데이터의 중복을 피하기 위해 '관계'를 이용한다.
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
다만, 강한 스키마로 인해 정형화된 데이터만 저장할 수 있다. 탐색의 속도를 올리기 위해서는 인덱스를 걸어야 한다. 결론적으로, 저장할 수 있는 데이터 양에 한계를 가진다.
(2) NOSQL
Not Only SQL이라는 뜻으로, SQL만을 사용하지 않는 DBMS를 뜻한다.
단순한 데이터를 대량으로 저장하고 탐색하는 데 용이하며 인덱스를 걸지 않아도 된다. 페타바이트 급의 데이터를 저장할 수 있다.
스키마도 없고, 관계도 없다. 여기서는 레코드를 Documents라고 한다.

SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능하다.
NOSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가할 수 있다.
(NOSQL에는 조인이라는 개념이 존재하지 않는다.)
장접
- 스키마가 없어서 유연하다. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가 가능하다.
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장된다. 데이터 읽어오는 속도 빠르다.
- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청이 처리 가능하다.
단점
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있다.
- 데이터 중복을 계속 업데이트 해야 한다.
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야 한다. (SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능하다.)
(3) NoSql의 종류
저장 방식에 따라 여러 종류로 분류해볼 수 있다.
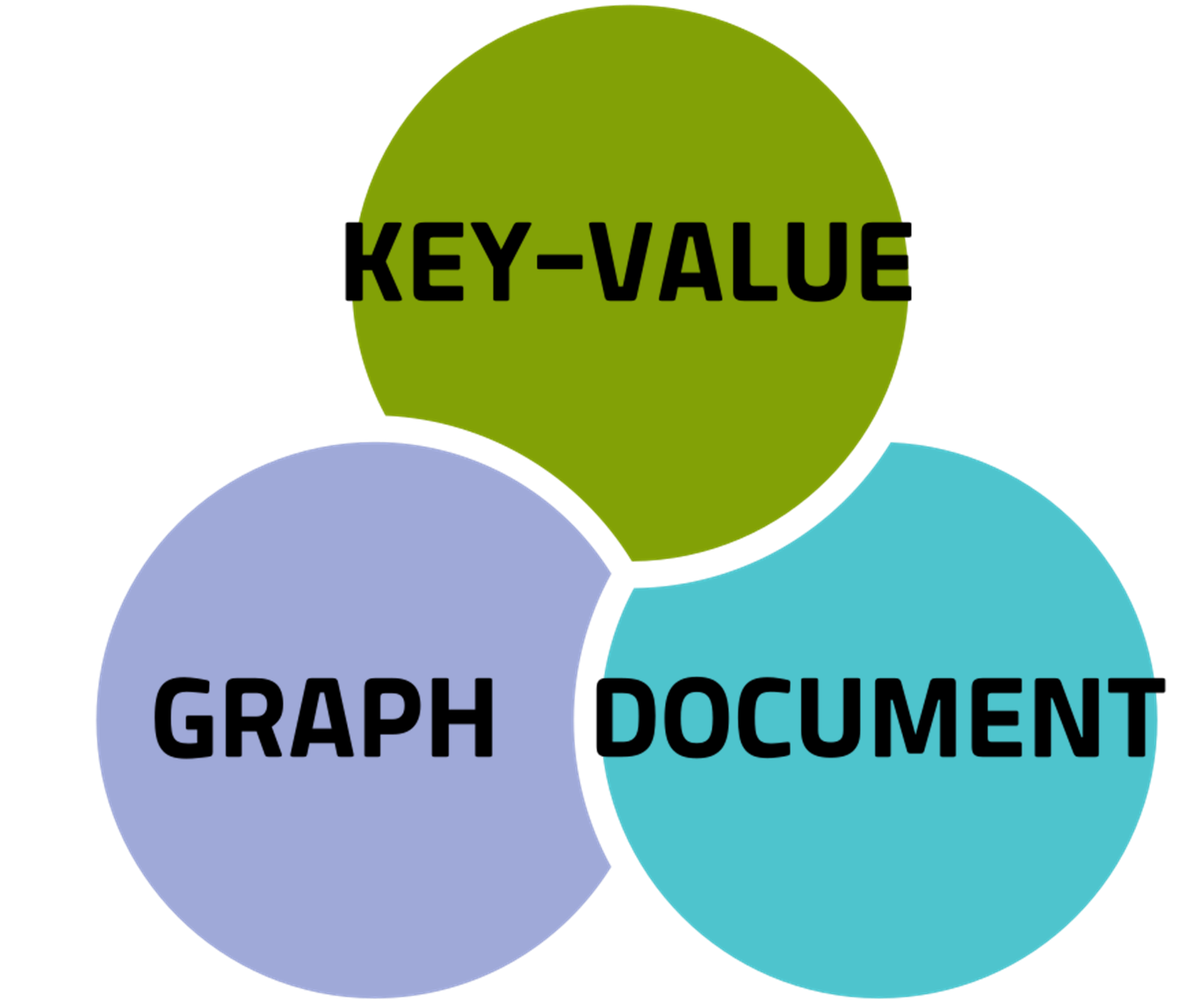
- 서로 연관된 그래프 형식의 데이터를 저장할 수 있는 Graph Store
- Row가 아닌 Column 위주로 데이터를 저장하는 Column Store
- 비정형 대량 데이터를 저장하기 위한 Document Store
- 메모리 기반으로 빠르게 데이터를 읽어올 수 있는 Key-Value Store
(4) 결론
RDBMS 대신 왜 NOSQL을 쓰는가?
NoSQL은 스키마가 약하다(혹은 없다). 따라서 Join 등 복잡한 쿼리는 불가능하지만,
데이터를 단순히 저장하고 읽는 데에 RDBMS보다 훨씬 빠르다. 또한, 많은 데이터를 저장하는 데 목적을 두고 있기에 분산 처리를 하는 것이 중요하다. 대부분의 NoSQL은 분산처리기능을 포함하고 있기에 유용하다.
데이터가 어떤 상황에서 NOSQL을 쓰는 것이 적합한가?
NoSQL은 단순 읽기/쓰기만 빠르기 때문에 수정이 자주 일어나지 않는 데이터에 적합하다. 또한 정형화되어 있지 않은 상태인 비정형 데이터에 적합하다.
2. Redis
(1) 레디스
레디스는 세계에서 가장 인기있는 Key-Value Store 중 하나이다.
Remote Dictionary Server의 약자로, 원격 Dictinary 자료구조 서버라는 뜻이다. Key로 올 수 있는 자료형은 기본적으로 String이지만, Value는 다양한 타입을 지원한다.
보통 데이터베이스는 하드 디스크나 SSD에 저장한다. 하지만 Redis는 메모리(RAM)에 저장해서 디스크 스캐닝이 필요없어 매우 빠르다. 캐싱도 가능해 실시간 채팅에 적합하며 세션 공유를 위해 세션 클러스터링에도 활용된다. 캐싱이라고 하긴 하지만, 다양한 영속성(디스크에 백업) 옵션을 제공한다.
(2) 레디스 vs 해쉬맵
둘 다 key-value 기반이고, 메모리 베이스며, 원하는 value를 원하는 표현방식으로 넣을 수 있다. 그럼 왜 레디스를 써야할까?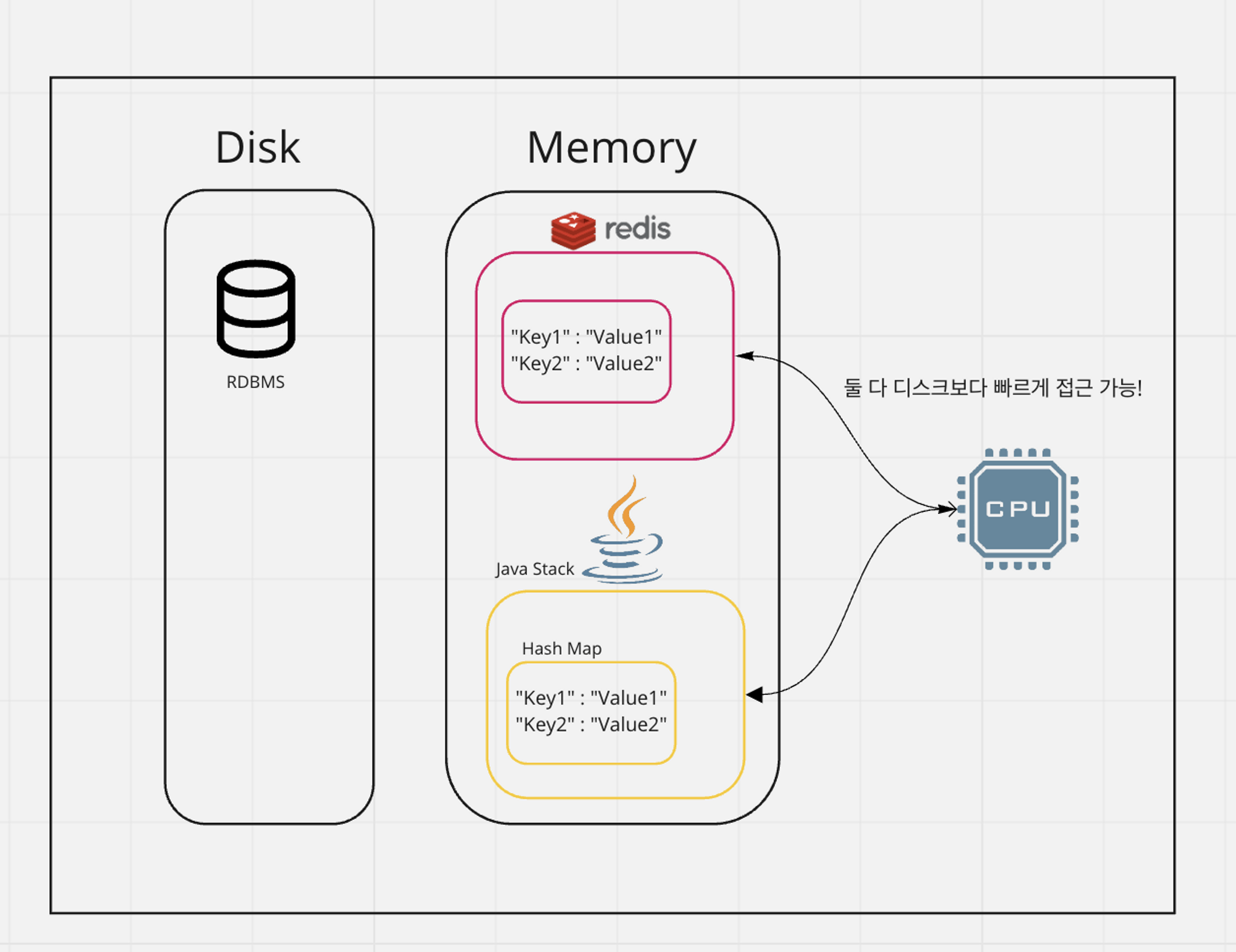
서버가 1대 있다는 가정에선 Redis의 장점이 크게 보이지 않지만, 분산 환경을 대입하면 장점이 보인다.
유저 요청이 크게 늘어나 서버를 몇 대 증설하였지만, 동일한 해쉬맵 데이터를 참조해야할 상황이 있다고 가정하자. 이 때 원격 프로세스간에 동일한 해쉬맵 데이터를 참조해야 할 때, 분산환경에선 원격 프로세스간 데이터를 동기화 하기 어렵다.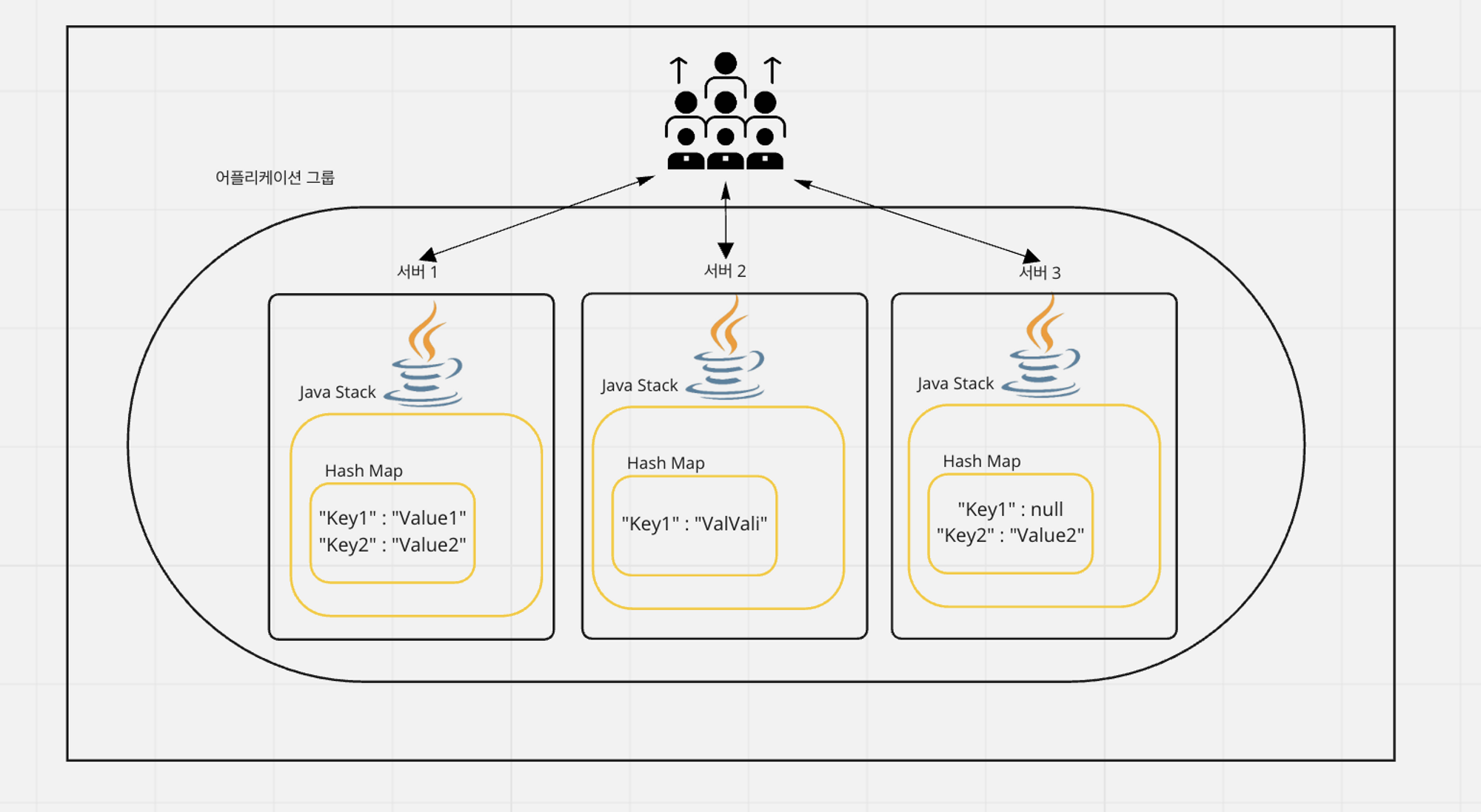
이 때 별도의 레디스 서버를 구성하고, 해당 레디스에서 값을 꺼내 쓴다면 메모리 기반 데이터 구조의 빠른 응답성을 확보함과 동시에 데이터 불일치 문제를 해결할 수 있다.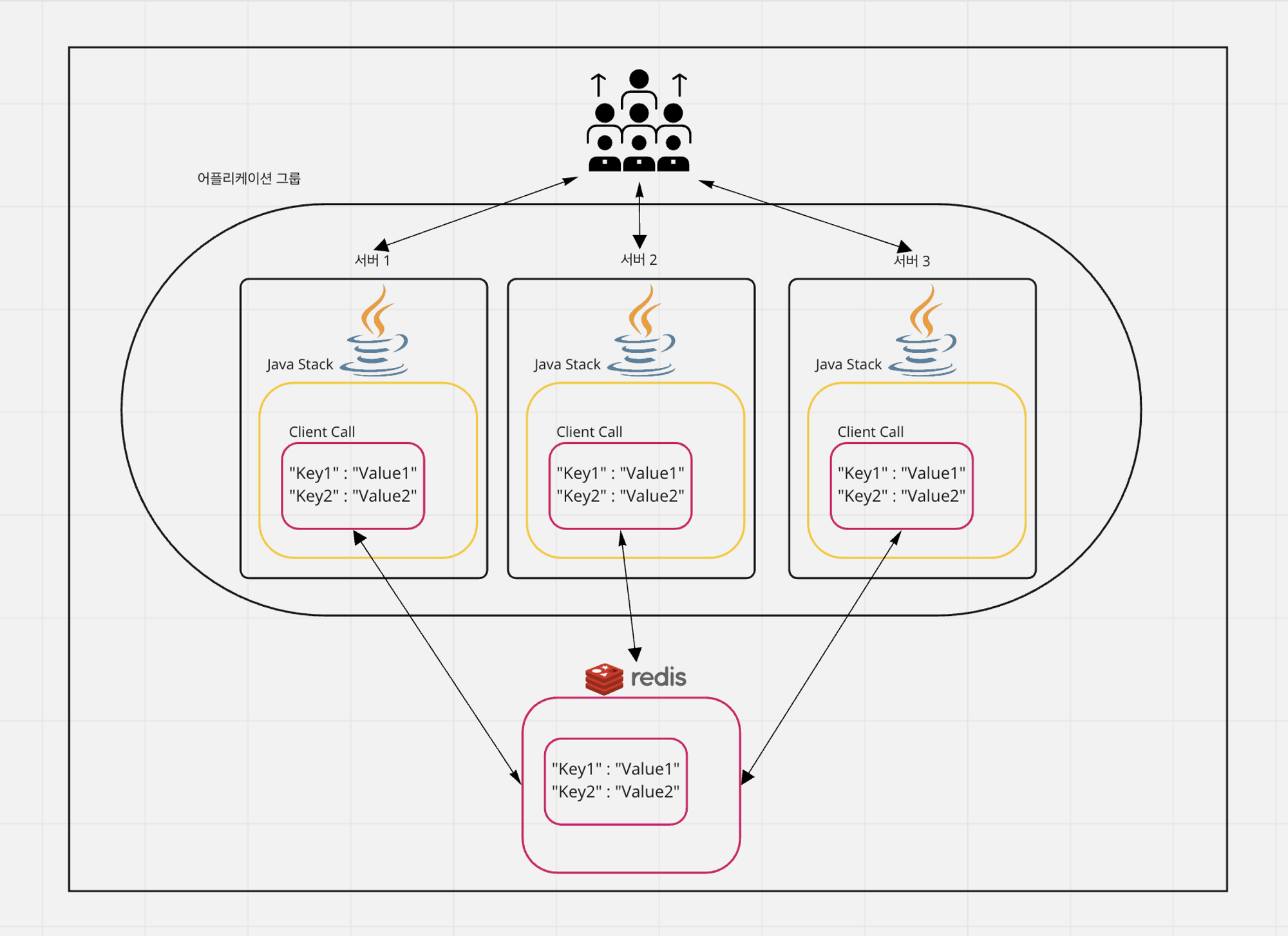
물론 위에서 언급했듯이 어플리케이션을 종료하면 휘발되어 사라지는 해쉬맵과 달리, 레디스는 영속성 옵션을 제공하기도 한다. 영속성 외에도 범용 프로그래밍 언어인 Java에서 다루기 까다로운 여러 기능도 DBMS로써 갖추고 있다.
TTL 설정 → 일정 시간이 지나면 데이터 삭제, 용량이 작은 메모리의 효율적 관리
분산 데이터 저장소 구성 → Redis Cluster 등 분산환경에서 안정적인 데이터 관리 가능
보안체계 → 악성 스크립트 공격으로 부터 안전 보장, TLS 지원3. Transaction
(1) 트랜잭션
트랜잭션은 데이터베이스의 상태를 변화시키기 위해 수행하는 작업 단위를 뜻한다. 상태를 변화시킨다는 건 SQL 질의어를 통해 DB에 접근한다는 의미이다.
유의할 점은, 작업 단위를 통틀어 하나의 트랜잭션이라고 부른다는 점이다. 만약 사용자 A가 사용자 B에게 만원을 송금한다고 할 때, 작업 단위는 출금(UPDATE) + 입급(UPDATE)를 의미한다. 두 쿼리 모두 성공해야 트랜잭션이 완료되는 것이며, 하나라도 실패한다면 모든 작업을 취소하고 이전 상태로 roll back 하는 것이 특징이다.
(2) 트랜잭션의 특성
위의 예시에서 알 수 있듯이, 트랜잭션은 독특한 성질이 몇 가지 있다.
원자성
트랜잭션이 데이터베이스에 모두 반영되거나, 전혀 반영되지 않아야 한다. 일부만 반영되는 건 없다.
하나의 트랜잭션 처리가 비정상적으로 종료되어 트랜잭션 원자성이 깨진 경우에는, last consistent state로 roll back한다.
일관성
트랜잭션 작업 처리 결과는 항상 일관성이 있어야 한다.
독립성
둘 이상의 트랜잭션이 동시에 병행 실행되고 있을 때, 어떤 트랜잭션도 다른 트랜잭션 연산에 끼어들 수 없다.
지속성
트랜잭션이 성공적으로 완료되었으면, 결과는 영구적으로 반영되어야 한다.
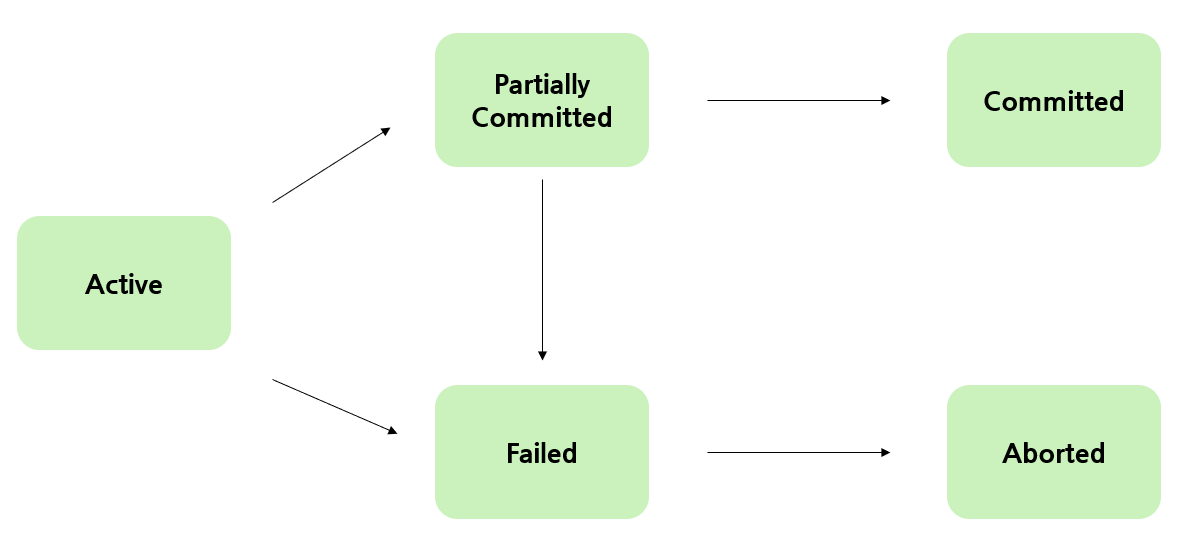
(3) Transaction Status
Active(활동 상태)
트랜잭션이 현재 연산을 수행 중인 상태
Partially Committed(부분 완료 상태)
마지막 연산이 실행된 직후의 상태이며, 연산은 모두 처리되었지만 데이터베이스에는 반영되지 않은 상태
Committed(완료 상태)
트랜잭션이 성공적으로 수행되어 커밋한 상태
Failed(실패 상태)
트랜잭션 도중 장애가 발생하여 중단된 상태
Aborted(철회 상태)
트랜잭션 수행에 실패하여 롤백한 상태
(4) 트랜잭션 관리 전략(DBMS)
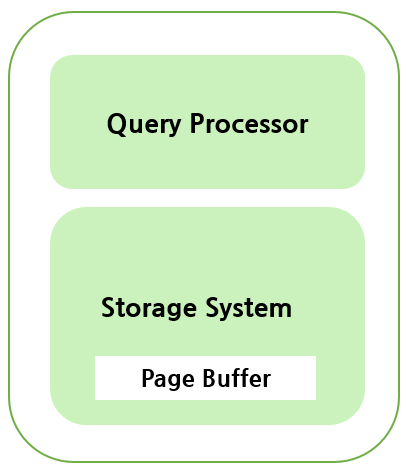
DBMS의 구조
데이터베이스 시스템은 보통 비휘발성 저장 장치인 디스크에 데이터를 저장하며, 전체 데이터베이스의 일부분을 메인 메모리에 유지한다. DBMS는 데이터를 고정 길이인 페이지(page)에 저장하며, 디스크에서 페이지 단위로 입출력이 이루어진다. 메인 메모리에 유지하는 페이지를 관리하는 모듈을 페이지 버퍼 관리자라고 부른다. DBMS는 크게 Query Processor와 Storage System으로 나눌 수 있다.
여기서 버퍼 관리 정책이 트랜잭션 관리에 있어 매우 중요한 결정을 내린다. 실제로 버퍼 관리 정책에 따라 트랜잭션의 UNDO 복구와 REDO 복구가 요구되거나 그렇지 않게 된다.
UNDO 복구
트랜잭션 수행 중에 수정된 페이지들이 버퍼 관리자의 버퍼 교체 알고리즘에 따라 디스크에 입력될 수 있다. 아직 완료되지 않은 트랜잭션이 수정한 페이지도 디스크에 입력될 수 있는데, 만약 해당 트랜잭션이 정상적으로 종료될 수 없는 경우에는 변경된 페이지들이 전부 원상 복구 되어야 한다. 이러한 복구를 UNDO라고 한다. 수정된 페이지를 디스크에 쓰는 시점을 기준으로 UNDO는 아래와 같은 두 정책으로 나눠어진다.
- STEAL: 수정된 페이지를 언제든지 디스크에 쓸 수 있는 정책
- ¬STEAL: 수정된 페이지를 트랜잭션 종료 시점(EOT)까지 버퍼에 유지하며 디스크에 쓰지 않는 정책
¬STEAL 정책을 사용한다면 UNDO 오퍼레이션이 비교적 단순해지지만(메모리 버퍼에 대해서만 이루어지면 됨) 이 정책은 매우 큰 크기의 메모리 버퍼가 필요하다는 문제를 갖고 있다. 따라서 거의 모든 DBMS가 STEAL 정책을 채택하는데, 이 정책은 UNDO 로깅과 복구를 수반하게 된다.
REDO 복구
REDO 복구는 UNDO 복구의 반대 개념으로, 이미 수행 중이거나 완료된 트랜잭션의 변경 연산을 다시 반복하는 복구 방법이다. REDO 복구도 마찬가지로 버퍼 관리 정책에 영향을 받는데, 트랜잭션이 종료되는 시점에 해당 트랜잭션이 수정한 페이지를 디스크에도 반영할 것인지 여부로 두 가지 정책을 구분한다.
- FORCE: 수정했던 모든 페이지를 트랜잭션 커밋 시점에 디스크에 반영하는 정책
- ¬FORCE: 수정했던 페이지를 트랜잭션 커밋 시점에 디스크에 반영하지 않는 정책
FORCE 정책을 따르면 커밋 시 디스크 상의 DB에 변경 사항이 모두 반영되므로 REDO 복구가 필요없게 된다. ¬FORCE 정책에서는 어떤 일을 했었는지에 대한 로그는 남겨서 변경 사항을 추적한다. ¬FORCE 정책을 따른다면 디스크 상의 DB에 변경 사항이 반영되어 있지 않을 수 있기에 반드시 REDO 복구 필요하다. 거의 모든 DBMS가 채택하는 정책은 ¬FORCE 정책이다.
DBMS가 버퍼 관리 정책으로 STEAL과 ¬FORCE 정책을 채택하고 있기 때문에, UNDO, REDO 복구가 모두 필요해진다.
로그(Log)
로그는 데이터베이스의 모든 변경 작업을 기록한다. 로그는 덧붙이는 방식으로 기록되며, 각 로그 레코드는 고유 식별자를 가진다. 로그 레코드의 식별자를 LSN(Log Sequence Number) 또는 LSA(LOG Sequence Address)라고 부른다. 로그는 항상 덧붙이는 방식이기에 단조 증가하는 성질을 가진다. 로그 데이터는 기록할 내용의 종류에 따라 물리적/논리적 로깅으로 분류할 수 있고, 데이터베이스의 상태 변화를 기록하는지 변화를 야기한 전이를 기록하는지에 따라 State/Transition으로 분류할 수 있다.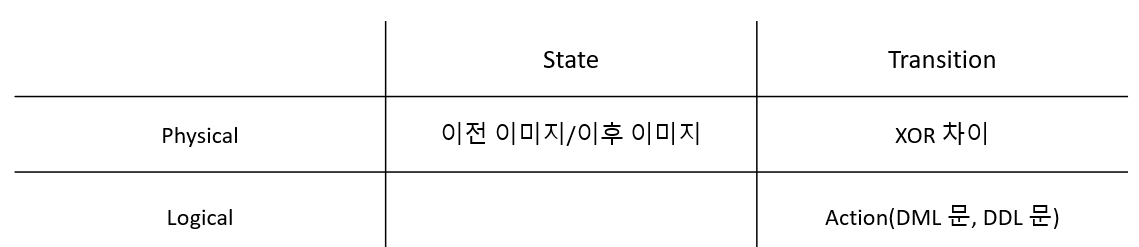
Physical State Logging
DBMS에서 가장 빈번하게 사용되는 로깅 방법으로, 로그 레코드에는 변경 이전 이미지와 이후 이미지가 모두 기록된다. UDON 복구 때는 이전 이미지로 현재 이미지를 대체하며, REDO 복구 때는 이후 이미지로 재반영하는 방식으로 복구된다.
Physical Transition Logging
이전/이후 이미지를 모두 기록하지 않고 XOR 차이점을 기록하는 방식으로 기록하는 방법이다. 복구 시점에서 로그 레코드에 기록된 XOR 이미지와 현재 레코드 이미지를 이용하여 UNDO, REDO 복구가 이루어진다.
Logical Transition Logging
Operation Logging이라고도 불리며, 어떤 일을 했는가를 기록하는 방식이다. 예를 들어, a = a + 1 연산을 기록할 때, 이전 값 0, 이후 값 1과 같이 물리적으로 기록할 수 있고, a = a + 1 연산 자체를 기록할 수도 있다. 논리적 로그에 대한 복구 작업은 로그 레코드에 기록된 오퍼레이션을 재수행하여 REDO 복구를 하거나, 역오퍼레이션으로 UNDO 복구를 하는 방식으로 진행된다. 이런 Logical Transition Logging은 각 로그 레코드의 크기를 줄여주는 장점도 있지만, 물리적으로 복구하기 힘든 자료 구조에 대한 로깅을 쉽게 해준다는 장점도 있다. 예를 들어, 인덱스 구조로 많이 사용되는 B+tree의 경우 split, merge와 같은 SMO(Structure Modification Operation)을 통해 데이터의 물리적인 위치가 변할 수 있기 때문에 물리적인 로깅 방식으로 복구하기 힘들지만, 논리적인 로깅 방식으로는 쉽게 복구 가능하다.
로그 작성 규칙
해당 업데이트가 데이터베이스에 반영되기 전에 관련된 UNDO 정보가 로그에 작성되어야 한다. 이 원칙을 WAL(Write Ahead Logging)이라고 부른다.
트랜잭션이 정삭적으로 종료 처리되기 되기 위해서는 REDO 정보가 로그에 작성되어야 한다. 따라서 복구를 하기 위해서는 커밋 시점 이전에 REDO 정보가 써져야 한다.
참고
https://www.oracle.com/kr/database/nosql/what-is-nosql/
https://sihyung92.oopy.io/database/redis/1#63454912-29f8-467a-9d3a-93e9be02ac35
https://velog.io/@rik963/Database-Transaction
