
ArrayList & LinkedList
List 자료형을 구현하는 데에는 세 가지 방법이 있을 수 있다.
1. Array로 List 구현
2. Pointer로 LinkedList 구현
3. ArrayList로 구현 <- JAVA를 사용할 때, 컬렉션을 쓰면 구현 가능한 구조이다.
핵심은? 연결에 있다
연결되도록 구현해야 한다!
-> 포인터로 연결하던지/배열로 연속되게 넣어두던지Array
source: https://www.geeksforgeeks.org/linked-list-vs-array/
- 장점: 구현이 간단하고 속도가 빠르다.
- 단점: 리스트의 크기가 고정된다. 배열의 특성상 동적으로 크기를 늘리거나 줄일 수 없다(배열 크기를 넘어가면 더 큰 배열을 생성하여 배열을 복사하는 방식으로 구현할 수도 있긴 하다). 리스트의 중간에 새로운 데이터를 삽입하거나 삭제하기 위해서는 기존의 데이터들을 이동해야 한다.
LinkedList
source: https://www.geeksforgeeks.org/linked-list-vs-array/
- 장점: 크기가 제한되지 않고, 중간에서 쉽게 삽입하거나 삭제할 수 있어 유연하다.
- 단점: 구현이 복잡하고, 임의의 항목(i번째 항목)을 추출할 때에는 배열을 이용하는 방법보다 시간이 많이 걸린다.
ArrayList
List<String> list = new ArrayList<>();
- List 인터페이스 구현 클래스(
in JAVA)- 컬렉션 프레임워크에서 가장 많이 사용되는 컬렉션 클래스(
in JAVA)- 일반 배열과 인덱스로 객체를 관리한다는 점이 비슷
- 배열은 생성할 때 크기가 고정되나, ArrayList는 저장 용량(capacity)을 초과한 객체들이 들어오면 자동으로 저장 용량이 늘어남
- 기존의 Vector를 개선한 것으로 Vector와 구현원리와 기능적인 측면에서 동일
- Vector보다는 ArrayList를 사용할 것(Vector는 호환성을 위해 남겨둠)(
in JAVA)
(1) 데이터의 검색/삽입/삭제 시 성능 비교
다음은 임의의 위치에 데이터를 삽입/삭제/조회할 때의 성능을 비교한 것이다. 삽입/삭제 시의 성능은 임의의 위치를 찾는 시간을 제외하고 그 이후에 작업하는 시간만을 계산한 것이다.
| ArrayList | LinkedList | |
|---|---|---|
| 삽입 | O(n) | O(1) |
| 삭제 | O(n) | O(1) |
| 조회 | O(1) | O(n) |
(2) Array 기반으로 List 구현
초기에 할당한 array의 크기보다 더 많은 값이 들어오게 되면 오류를 반환한다.
C
#define MAX_LIST_SIZE 100 // 리스트 최대 크기
typedef int element;
typedef struct {
element array[MAX_LIST_SIZE]; // 배열 정의
int size; // 현재 리스트에 저장된 항목들의 개수
} ArrayListType;
// 오류 처리 함수
void error(char* message) {
fprintf(stderr, "%s\n", message);
exit(1);
}
// 리스트 초기화 함수
void init(ArrayListType* L) {
L->size = 0;
}
// 리스트가 비어있으면 1 반환
// 그렇지 않으면 0 반환
int is_empty(ArrayListType* L) {
return L->size == 0;
}
// 리스트가 가득 차 있으면 1 반환
// 그렇지 않으면 0 반환
int is_full(ArrayListType* L) {
return L->size == MAX_LIST_SIZE;
}
// 특정 위치의 원소값 반환
element get_entry(ArrayListType* L, int pos) {
if (pos < 0 || pos >= L->size)
error("위치 오류");
return L->array[pos];
}
// 리스트 출력
void print_list(ArrayListType* L) {
for (int i = 0; i < L->size; i++)
printf("%d->", L->array[i]);
printf("\n");
}
// 리스트의 맨 끝에 항목을 추가
// 리스트에 빈 공간이 없으면 오류 발생
void insert_last(ArrayListType* L, element item) {
if (L->size >= MAX_LIST_SIZE)
error("리스트 오버플로우");
L->array[L->size++] = item;
}
// 리스트의 임의의 pos 위치에 새로운 항목 추가
void insert(ArrayListType* L, int pos, element item) {
if (!is_full(L) && (pos >= 0) && (pos <= L->size)) {
for (int i = (L->size - 1); i >= pos; i--)
L->array[i + 1] = L->array[i];
L->array[pos] = item;
L->size++;
}
}
// 리스트의 임의의 pos 위치에 있는 항목 삭제
element delete(ArrayListType* L, int pos) {
element item;
if (pos < 0 || pos >= L->size)
error("위치 오류");
item = L->array[pos];
for (int i = pos; i < (L->size - 1); i++)
L->array[i] = L->array[i + 1];
L->size--;
return item;
}(3) ArrayList 기반으로 List 구현
위 (2)의 구현에서 리스트 오버플로우가 발생했을 때, 에러를 출력하는 대신 배열을 동적으로 할당하는 방식을 사용하면 ArrayList를 구현할 수 있다. 다만 이 방식보다는 java의 ArrayList를 사용하면 더욱 감각적인 코드를 구현할 수 있다.
JAVA
// E는 제너릭
List<E> arrayList = new ArrayList<E>();
// 생성 시 용량을 설정할 수도 있음
List<E> arrayList = new ArrayList<E>(2000);
// data 삽입
arrayList.add("A");
// 인덱스를 활용하여 위치를 지정한 데이터 삽입
arrayList.add(1, "B");
// 크기 얻기
int size = arrayList.size();
// 임의의 인덱스의 객체 가져오기
String tmp = arrayList.get(1);
// 임의의 인덱스의 객체 삭제
arrayList.remove(1);
// 인덱스 1의 객체 변경
arrayList.set(1, "K");
// 특정 객체 찾기
// 존재하면 true를 return
boolean findOrNot = arrayList.contains("K");
// 리스트가 비어있는지 확인
// 비어있으면 true를 return
boolean isEmptyOrNot = arrayList.isEmpty();
// 리스트 비우기
arrayList.clear();(4) Pointer 기반으로 LinkedList 구현
동적 할당과 pointer를 기반으로 구현한 단순 연결 리스트이다. 각 함수의 기능은 다음과 같다.

C
typedef int element;
typedef struct ListNode {
element data;
struct ListNode* link;
} ListNode;
// 오류 처리 함수
void error(char* message) {
fprintf(stderr, " % s\n", message);
exit(1);
}
ListNode* insert_first(ListNode* head, int value) {
ListNode* p = (ListNode*)malloc(sizeof(ListNode));
p->data = value;
p->link = head; // 헤드 포인터 값 복사
head = p; // 헤드 포인터 변경
return head; // 변경된 헤드 포인터 반환
}
ListNode* insert(ListNode* head, ListNode* pre, int value) {
ListNode* p = (ListNode*)malloc(sizeof(ListNode));
p->data = value;
p->link = pre->link;
pre->link = p;
return head;
}
ListNode* delete_first(ListNode* head) {
ListNode* removed;
if (head == NULL)
return NULL;
removed = head;
head = removed->link;
free(removed);
return head;
}
ListNode* delete(ListNode* head, ListNode* pre) {
ListNode* removed;
removed = pre->link;
pre->link = removed->link;
free(removed);
return head;
}
void print_list(ListNode* head) {
for (ListNode* p = head; p != NULL; p = p->link)
printf("%d->", p->data);
printf("NULL\n");
}(5) LinkedList에 대해 더 알아보자면?
LinkedList?
하나의 노드를 데이터 필드와 링크 필드로 나누어, 다음 노드가 기억된 공간의 주소를 이전 노드의 링크 필드에 기억시키는 방식으로 모든 노드들을 하나의 리스트로 연결한다. 논리적 데이터 순서와 물리적 데이터 순서가 동일하지 않기 때문에 이러한 방식이 필요한 것이다. 다시 말해, 노드 배열이 기억장치의 번지와 일치하지 않는 리스트가 바로 LinkedList이다. 각 노드는 기억 장소에서 서로 이웃해 있지 않아도 되기 때문에 기억 공간을 효율적으로 활용할 수 있다.
삽입과 삭제가 쉽도록 고안된 자료구조라서, 중간 노드의 삽입과 삭제가 용이하다. 새로운 노드가 필요하면 동적 할당을 사용하면 된다.
장점
- 노드를 연속적으로 저장하지 않아도 된다. 각 노드는 메모리의 유용 공간의 위치에 관계없이 저장 가능하다.
- 노드 삽입과 삭제가 쉽다.
- fragmentation이 발생하지 않아 전체 기억 공간의 사용 효율성이 좋다.
- 여러 개의 리스트를 한 개의 리스트로 쉽게 결합할 수 있다.
단점
- 포인터 저장을 위한 기억장소가 요구되므로 메모리 공간을 많이 사용하여 기록 밀도가 배열 구조보다 낮다.
- 임의 요소의 값을 수정하는 연산에는 탐색 시간이 필요하다.
- i번째 데이터에 접근하기 위해 앞에서부터 순차 검색을 해야 한다.
- 알고리즘 구현이 복잡하고, 오류가 나기 쉽다.
종류
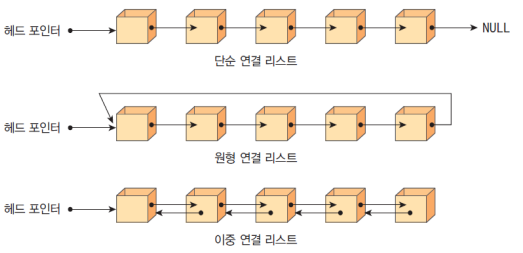
- 단순 연결 리스트
하나의 방향으로만 연결되어 있는 연결 리스트, 체인(chain)이라고 한다. 마지막 노드의 링크 값은 NULL. 거꾸로 갈 수 있는 방법이 없다. - 원형 연결 리스트
단순 연결 리스트와 유사하나 마지막 노드의 링크가 첫 번째 노드를 가리킨다. - 이중 연결 리스트
각 노드마다 2개의 링크가 존재하는데, 하나는 앞 노드, 하나는 뒷 노드를 가리킨다.
2. Queue & Stack
(1) Queue란?
선형 큐
- 선입선출(FIFO)
- 삽입과 삭제가 다른 곳에서 이루어짐(삽입-큐의 맨 뒤/삭제-큐의 맨 앞)
원형 큐
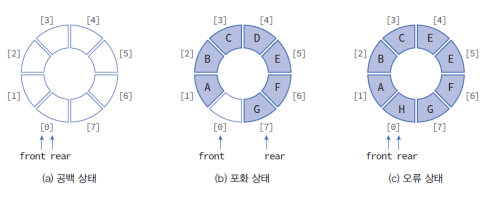
- 큐를 순환적으로 구현
- 하나의 자리를 비워 놓고 구현하는 것이 일반적인데, 이렇게 하면 공백 상태(front == rear)와 포화 상태(front%M == (rear+1)%M)를 구분하기 쉬움. (추가적인 변수를 사용하여 count하면 한 자리를 비워 놓지 않아도 되긴 함)
구현
배열로 선형 큐를 구현하는 경우에는 문제점이 있다.
- front와 rear의 값이 계속 증가만 하기 때문에 언젠가는 배열의 끝에 도달하며, 배열의 앞부분이 비어 있더라도 더 이상 사용하지 못하게 된다.
- 따라서 주기적으로 모든 요소들을 왼쪽으로 이동시켜야 한다.
해결 방법은?
- 원형 큐로 구현
- 연결 리스트로 구현
(2) Stack이란?
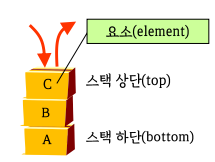
- 후입선출(LIFO)
- 입출력은 맨 위에서만 일어나고, 중간에서는 데이터를 넣거나 삭제할 수 없음
구현
- 배열을 이용하는 방법
- 간단하고 성능이 우수함
- 스택 크기가 고정되는 약점이 있음
- 연결 리스트를 이용하는 방법
- 구현 방법이 복잡함
- 스택의 크기를 필요에 따라 가변적으로 할당할 수 있음
(3) Deque이란?
DEQUE == Double-Ended QUEUE
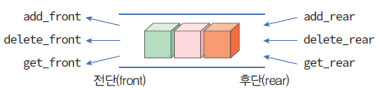
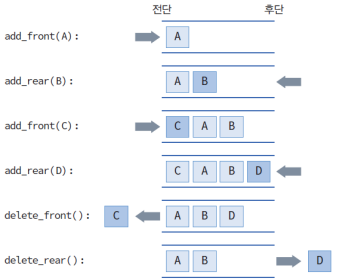
- 큐의 전단과 후단에서 모두 삽입과 삭제가 가능한 큐
- 스택과 큐의 연산들을 모두 가지고 있음
- 원형 큐를 확장하면 덱을 쉽게 구현할 수 있음
3. Linked Stack & Linkd Queue
(1) Linked Stack
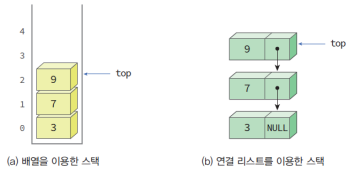
- 장점: 크기 제한이 없고, 동적 메모리만 할당할 수 있으면 스택에 새로운 요소를 삽입할 수 있다.
- 단점: 동적 메모리 할당이나 해제를 해야 하므로 삽입이나 삭제 시간이 더 필요하다.
데이터 삽입은 LinkedList에서 맨 앞에 데이터를 삽입하는 것과 동일하나, 헤드 포인터를 top이라는 이름으로 부르는 것이 낫다.
데이터 삭제는 top이 가리키는 노드를 연결 해제하고 동적 메모리 해제하면 된다.
공백 상태는 LinkedList와 마찬가지로 top 포인터가 NULL인 경우이다.
(2) Linked Queue
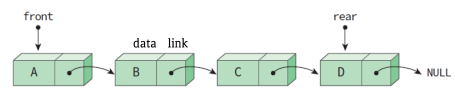
- 장점: 크기 제한이 없다.
- 단점: 배열로 구현한 큐에 비해 코드가 복잡하며, 링크 필드 때문에 메모리 공간을 더 많이 사용한다.
LinkedList에 2개의 포인터를 추가한 것과 같이 구현하면 된다. 큐의 특성을 살려, front 포인터에서는 삭제하고 rear 포인터에서는 삽입하면 된다.
참고
https://velog.io/@gillog/%EB%B0%B0%EC%97%B4-%EB%A6%AC%EC%8A%A4%ED%8A%B8Array-List
