사진을 클릭하면 PDF 정리본 다운로드 링크로 이어집니다.

🧐 마스터 정리
- 점화식이 의 형태이면, , , 의 크기에 따라 을 다음과 같이 표현할 수 있다.
(단, , 대신 으로 주어져도 동일하게 계산함.)
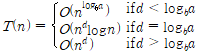
🧐 3.3 선택(Selection) 문제(숫자 찾기 문제)
선택문제 vs 선택정렬
선택문제 = 이진탐색 + 퀵 정렬 선택정렬 = 최솟값을 왼쪽에 고정해나감
-
개의 숫자들 중에서 번째로 작은 숫자를 찾는 문제(입력 숫자들이 각각 다르다고 가정)
최소 숫자를 번 찾음. 단, 최소 숫자를 찾은 뒤에는 입력에서 그 숫자를 제거함.
숫자들을 오름차순으로 정렬하고 번째 숫자를 찾음.⇒ 그러나 위의 알고리즘들은 각각 최악의 경우 과 의 시간 복잡도를 갖는다. 효율적인 해결 방법이 없을까?
-
이진탐색 아이디어를 기반으로 퀵 정렬에서와 같이 을 선택하여 분할하는 방법을 적용해보자.
-
이때, 알고리즘은 문제가 2개의 부분 문제로 분할되나, 그중에 1개의 부분 문제는 고려할 필요가 없다.
-
부분 문제의 크기가 일정하지 않은 크기로 감소하는 형태의 분할 정복 알고리즘이다.
-
👩🏻💻 C 코드로 표현해본다면?
int partition(int list[], int left, int right)
{
int pivot, temp, low, high;
pivot = list[left];
low = left;
high = right + 1;
do
{
do
low++;
while(list[low] < pivot);
do
high--;
while(list[high] > pivot);
if(low < high)
SWAP(list[low], list[high], temp);
} while(low < high);
SWAP(list[left], list[high], temp);
return high;
}
int findKth(int list[], int left, int right, int k)
{
int p = partition(list, left, right);
int s = (p - 1) - left + 1;
if(k <= s)
return findKth(list, left, p - 1, k);
else if(k == s + 1)
return list[p];
else
return findKth(list, p + 1, right, k - s - 1);
}-
Selection 알고리즘은 분할 정복 알고리즘이기도 하지만 랜덤(random) 알고리즘이기도 하다.
- 선택 알고리즘의 line1에서 을 랜덤하게 정하기 때문이다.
- 이 입력을 너무 한쪽으로 치우치게 분할하면 알고리즘의 수행 시간이 길어진다.
- 치우치게 분할될 확률은 동전을 던질 때 한쪽 면이 나오는 확률과 동일하다.
-
good/bad 분할의 정의
-
분할된 두 그룹 중의 하나의 크기가 입력 크기의 과 같거나 그보다 크게 분할하면 bad 분할이라고 정의해보자. (좋은 분할은 그 반대임.)
- 이때 good 분할이 되는 을 선택할 확률과 bad 분할이 되는 을 선택할 확률은 각각 로 동일하다.
- 을 랜덤하게 정했을 때 good 분할이 될 확률이 이다.
- 평균 회 연속으로 랜덤하게 을 정하면 good 분할을 할 수 있다.
- good 분할만 연속하여 이루어졌을 때만의 시간 복잡도를 구하여, 그 값에 를 곱하면 평균 경우 시간 복잡도를 얻는다.
- 입력 크기가 에서부터 배로 연속적으로 감소되고, 크기가 일 때는 더 이상 분할할 수 없다.
⇒
⇒
-
-
선택 알고리즘과 이진탐색
-
유사성
- 이진탐색은 분할 과정을 진행하면서 범위를 씩 좁혀가며 찾고자하는 숫자 탐색
- 선택 알고리즘은 으로 분할하여 범위를 좁혀가며 찾고자하는 숫자 탐색
-
공통점
- 부분 문제들을 취합하는 과정 필요 없음.
-
- 선택 알고리즘은 데이터 분석을 위한 중앙값(median)을 찾는 데 활용됨.
🧐 3.4 최근접 점의 쌍 찾기
- 2차원 평면상의 개의 점이 입력으로 주어질 때, 가장 가까운 한 쌍의 점을 찾는 문제
👨🏻🔬 무차별 대입 알고리즘(brute force)
모든 점에 대하여 각각의 두 점 사이의 거리를 계산하여 가장 가까운 점의 쌍을 찾는다.
⇒
한 쌍의 거리 계산은
시간 복잡도:
👩🏻💻 C 코드로 표현해본다면?
void closetPairIter (Point p[])
{
double dMin = 10000000.0, d;
int iMin, jMin;
for (int i = 0; i < N - 1; i++)
{
for (int j = i + 1; j < N; j++)
{
d = dist (p[i], p[j]);
if (d < dMin)
{
dMin = d;
iMin = i;
jMin = j;
}
}
}
printf ("[%d %d] [%d %d] %.2f\n", p[iMin].x, p[iMin].y, p[jMin].x, p[jMin].y, dMin);
}👨🏻🔬 분할 정복 알고리즘
개의 점을 로 분할하여 각각의 부분 문제에서 최근접 점의 쌍을 찾고, 개의 부분해 중에서 짧은 거리를 가진 점의 쌍을 찾는다.
중간 영역 안에 있는 점들 중에 더 근접한 점의 쌍이 있는지 확인해야 한다.⇒ 시간 복잡도:
좌표를 기준으로 입력의 점들을 미리 정렬시켜 놓으면, 으로 향상이 가능하다.
👩🏻💻 의사코드로 표현해본다면?
Alg ClosestPair(S)
input array S sorted by value of x
output distance of closest pair
1. if(i <= 3) return closest distance
2. divide S -> S_L, S_R
3. CP_L = ClosestPair(S_L)
4. CP_R = ClosestPair(S_R)
5. d = min{dist(CP_L), dist(CP_R)}, get CP_C
6. return min{CP_L, CP_C, CP_R}👩🏻💻 C 코드로 표현해본다면?
double DMZCheck(Point p[], int left, int right, double d)
{
insertionSortY(p);
for(int i = left; i <= right; ++i)
{
for(int j = i+1; j <= right; j++)
{
if(p[j].y - p[i].y > d)
break;
double tmp = dist(p[i], p[j]);
d = d < tmp ? d : tmp;
}
}
return d;
}
double closestPairRecur(Point p[], int left, int right)
{
int size = right - left + 1;
double min;
if(size == 2)
return dist(p[left], p[right]);
else if(size == 3){
double a = dist(p[left], p[left + 1]);
double b = dist(p[left + 1], p[left + 2]);
double c = dist(p[left + 2], p[left + 3]);
return min(a, b, c);
}
else
{
int mid = (left + right) / 2;
double a =
closestPairRecur(p, left, mid);
double b =
closestPairRecur(p, mid + 1, right);
min(a, b);
return DMZCheck(p, left, right, min);
}
}🧐 3.5. 분할 정복 적용에 있어 주의할 점
-
분할 정복이 부적절한 경우
-
입력이 분할될 때마다 분할된 부분 문제의 입력 크기의 합이 분할되기 전의 입력 크기보다 커지는 경우
피보나치 문제 (분할대신 반복으로 풀 것)
-
취합(정복) 과정이 복잡한 경우
- 기하에 관련된 다수의 문제들이 효율적인 분할 정복 알고리즘으로 해결되는데, 이는 기하 문제들의 특성상 취합 과정이 문제 해결에 잘 부합하기 때문이다.
-
💡 요약
분할 정복(Divide-and-Conquer)
주어진 문제의 입력을 분할하여 문제를 해결(정복)하는 방식의 알고리즘이다.
합병 정렬(Merge Sort)
n개의 입력을 개씩 개의 부분 문제로 분할하고, 각각의 부분 문제를 순환적으로 합병 정렬한 후 합병하여 정렬(정복)하는 방식의 알고리즘이다. 시간 복잡도는 , 공간 복잡도는 이다.
퀵 정렬(Quick Sort)
을 기준으로 작은 숫자들은 왼편, 큰 숫자들은 오른편에 위치하도록 분할한다. 분할된 부분 문제들에 대해서 동일한 과정을 순환적으로 수행하여 정렬하는 알고리즘이다. 시간 복잡도는 최선의 경우 , 평균의 경우 , 최악의 경우 이다.
선택(Selection) 문제
번째 작은 수를 찾는 문제로, 입력에서 퀵정렬처럼 을 선택하여 분할한 후 번째 작은 수가 들어 있는 부분을 순환적으로 탐색한다. 시간 복잡도는 평균의 경우 이다.
최근접 점의 쌍(Closest Pair) 문제
개의 점들을 로 분할하여 각각의 부분 문제의 최근접 점의 쌍 중 작은 값을 구한다. 이 값이 중간 영역 안에 있는 점들보다 작은지 확인하여 최근접 점의 쌍을 찾는다. 분할 정복 방식을 채택하면, 향상 시의 시간 복잡도는 이다.
분할 정복을 적용하는 데 있어서 주의할 점
분할 전보다 분할 후에 입력 크기의 합이 커지면 분할 정복이 부적절한 경우이다. 또한 취합(정복) 과정이 간단한 지를 살펴보아야 한다.
