무민님의 10분 테코톡 Process vs Thread 영상을 보고 정리한 글 입니다.
JVM의 탄생 배경
<태초에 문제가 있었다?>
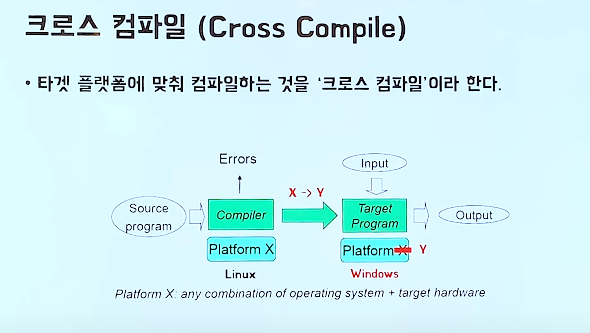
-C/C++은 컴파일 플랫폼과 타겟 플랫폼이 다를 경우, 프로그램이 동작하지 않는다.
ex) Linux에서 컴파일해서 나온 프로그램은 Window에서 동작하지 않음
이를 타겟 플랫폼에 맞춰 컴파일 하는 Cross Compile을 통해 해결하였음.
<JVM은 문제를 근본적으로 해결!>
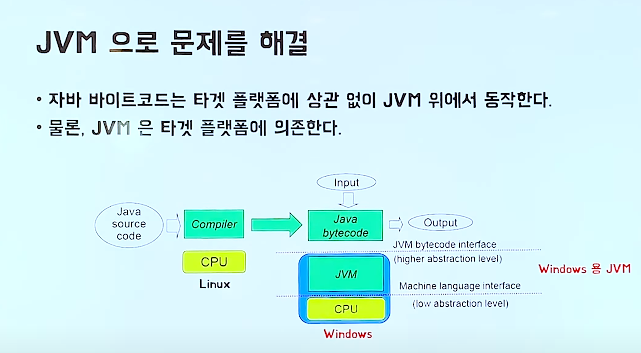
-자바 bytecode는 타겟 플랫폼에 상관 없이 JVM 위에서 동작한다.
-물론, JVM은 타겟 플랫폼에 의존한다.
무슨소리인가?
간단하게, Linux에서 JVM을 통해 컴파일한 Java byteCode는 다른 어떤 플랫폼에서도 해당 플랫폼에 맞는 JVM만 설치되어 있다면 동작이 가능하다!
<왜 굳이 JVM을 사용하는가?>
Q) C/C++도 Cross Compile을 통해 배포하면 되는데 굳이 JVM을?
-> 네트워크가 발전하면서 다양한 기종의 디바이스에서 사용할 수 있는 프로그램이 필요해졌음
하지만 Cross Compile로는 플랫폼마다 컴파일을 해줘야 하므로 한계가 있음.
<JVM의 구조>
<.Runtime Data Areas>
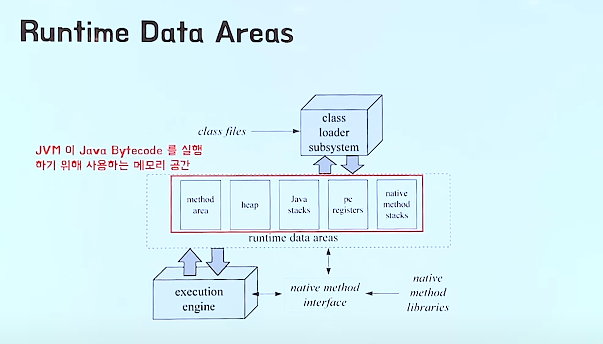
공유자원
-JVM이 Java Bytecode를 실행하기 위해 사용하는 메모리 공간
method area , heap-> 모든 스레드가 공유하는 자원
method area: 클래스에 있는 정보들을 파싱해서 저장하는 영역(변수, 메소드, 정적변수...)
heap: 프로그램을 실행하면서 생성한 모든 객체 인스턴스를 저장하는 영역
스레드 자원
Java stacks,pc register, native method stacks-> 스레드마다 존재함
PC(Program Counter): 각 스레드는 메소드를 항상 실행하고 있는데 이때, 몇번째 줄을 실행해야 하는지 나타냄
Stack: 스택은 스레드 별로 1개만 존재하고, 스택 프레임은 메서드가 호출될 때마다 생성됨.
<왜 JVM은 연산의 피연산자를 저장할 때 레지스터를 쓰지 않고 Stack을 썼는가?>
-자바는 다기종의 디바이스에서 균일하게 동작하는 것이 목표였는데, 디바이스마다 레지스터의 수는 모두 다르기 때문에 가늠이 불가능해짐 -> 이는 구현에 관여하게 되는 것이므로 추상화를 위해 Stack을 사용하였다.
흠.. 사실 Stack과 Heap에 대한 이야기는 별로 없었던 것 같다.
