
신경망 학습
-
학습이란?
신경망에서 입력신호의 총합을 도출 할 시 가중치를 일일히 사람이 설정해 주워 모델을 완성하는 것은 한계가 있다. 따라서, 훈련데이터로부터 가중치 매개변수릐 최적값을 찾는 것을 학습이라 말한다. -
이미지를 벡터로 변환 할 시에는 사람이 적합한 특징을 설계하여 학습은 기계가 스스로 하도록 해 주워야 한다.
-
과도한 하나의 데이터 셋에 대하여만 학습은 그 데이터 셋에대하여만 최적화가 되어 오버피팅(overfitting)현상이 일어날 수 있다.
손실함수
- 손실함수란 신경망 성능의 나쁨을 나타내는 지표로써 학습의 기준으로써 사용이 된다.
- 왜 정확도를 지표로 삼지 않고 손실 함수를 지표로 삼는가?
- 정확도를 기준으로 지표를 삼으면 함수 자체가 이어져 있지 않은 계단함수로써 표현이 되기 때문에 학습이 잘 이뤄지지 않는다.
(가령, 100개의 데이터 셋이 존재하고 50개가 올바르게 인식이 된다면 정확도는 50%이고 값을 바꾸면 50.1%, 50.2%같은 정확도로 판단이 되어지지 않고 임계값을 기준으로 51%, 49%같은 정확도가 도출된다.)
따라서, 손실함수는 연속적인 변화를 나타낼 수 있음으로 손실함수로써 지표를 삼게 된다.
- 정확도를 기준으로 지표를 삼으면 함수 자체가 이어져 있지 않은 계단함수로써 표현이 되기 때문에 학습이 잘 이뤄지지 않는다.
- 손실함수의 종류는 오차제곱합, 교차 엔트로피 오차가 존재한다.
- 오차제곱합
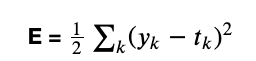
- y는 신경망의 출력값, t는 정답 레이블, k는 데이터의 차원 수
예측값과 실측값의 차이를 구하여 손실에 대한 정도를 구함 - W에 대한 2차원 함수로써 표현이 되고 그래프로써 W변수가 하나이고 W변수가 여러개면 그릇모양으로써 최소값이 하나가 되는형태이다.
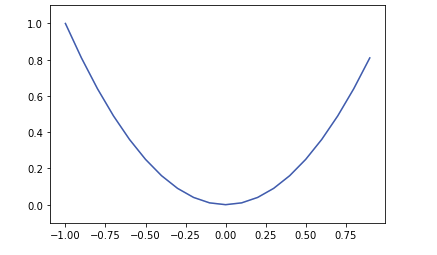
- y는 신경망의 출력값, t는 정답 레이블, k는 데이터의 차원 수
- 교차 엔트로피 오차
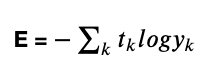
- y는 신경망의 출력값, t는 정답 레이블, k는 데이터의 차원 수
- 정답 레이블만 1이므로 정답 레이블에 대하여 확률의 log값을 판단한다
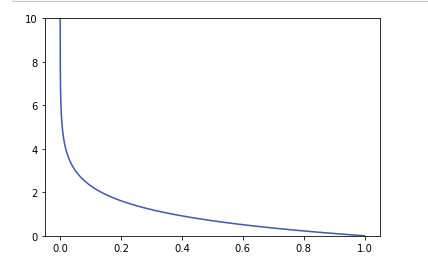
- -log그래프로써 1값에 가까울 수록 0값에 가까워 지는 것을 볼 수 있다 .
- 코드로써 구현을 할 때, y값에 0이 들어가게 되면 'inf'값 즉, 무한대 값이 나와 계산이 진행이 됨으로 y값에 아주 작은 수를 더하여(예: 1e-6의 수) 계산을 진행 하도록 한다.
- 미니배치 학습
방대한 학습 데이터를 전부 조사하여 일일히 손실함수를 게산하는 것은 현실적이지 않음으로 데이터 일부를 추려 전체의 근사치로 이용한다.(일부만 골라 학습을 수행)
- 오차제곱합
미분
- 수치 미분
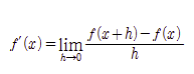
- 전방 차분
def func(f,x):
h = 10e-50
return (f(x + h) - f(x)) / h이렇게 구현을 하게 되면 h가 아무리 작은 수라도 오차가 생길 수 있다.
- 수치 미분의 오차를 줄이기 위해 중심차분(중앙차분)을 사용
def func(f,x):
h = 10e-50
return (f(x + h) - f(x - h)) / h- 편미분
변수가 여럿인 함수에 대한 미분
하나의 변수에 대한 변화를 판단(나머지 변수는 상수로 취급)
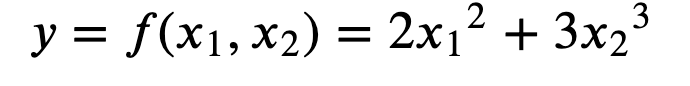
- x1에 대한 y의 변화
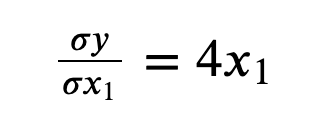
- x2에 대한 y의 변화
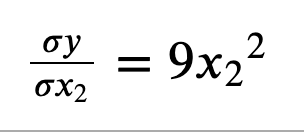
- x1에 대한 y의 변화
경사하강법
-
손실 함수가 최소값이 될 때의 매개변수 값을 찾는 것이 학습
-
손실함수를 찾기 위하여 경사 하강법을 이용한다.
-
경사하강법이란?
기울기를 이용하여 함수의 최소값을 찾는 것 - 해당 방법을 사용하기 위해서는 그래프의 최소값이 유일해야 한다!
복수의 최소값이 존재 할 경우 기울기가 0이 되는 지점이 최소값이 아닐 수 있기 때문이다.
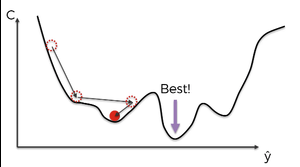
출처 https://librewiki.net/wiki/%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95
이 그래프를 보게 되면 기울기가 0이 되는 부분이 최솟값이 아닐 수 있기 때문이다.
-
오차제곱합에서 W변수가 하나일 경우를 보게 되면 W에 대한 2차원 그래프이고 기울기가 0인 지점이 최솟값을 가지게 된다.
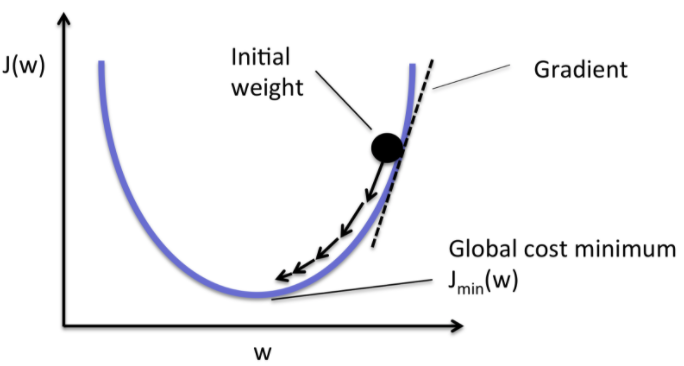
출처
https://hackernoon.com/gradient-descent-aynk-7cbe95a778da -
f = w1^2 +w2^2를 그래프로 그려보면 다음과 같고 하나의 최소값을 가지는 것을 볼 수 있다.
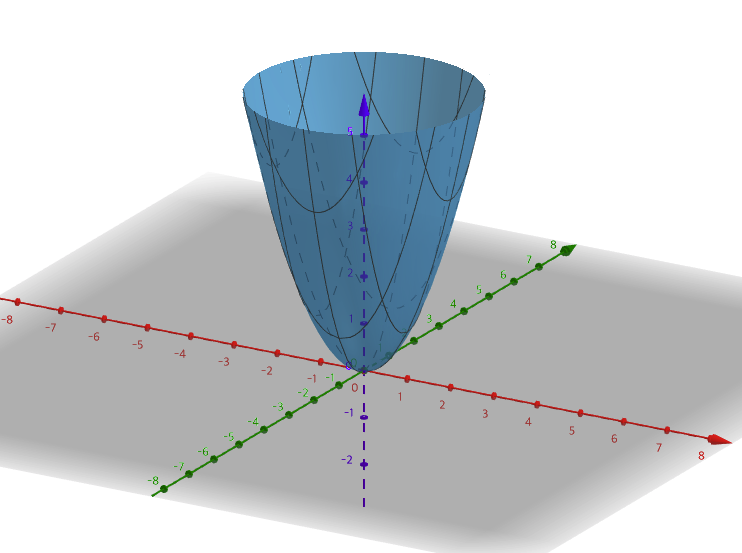
-
이러한 경사법을 이용하여 매개변수를 조정하여 학습을 하게 되는데 수식은 다음과 같다.
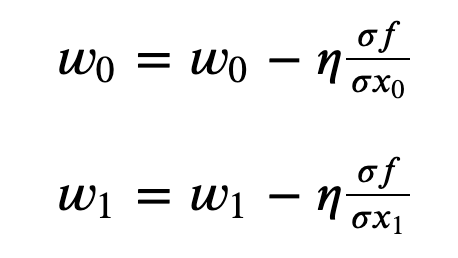
- (η는 learning rate로써 얼마만큼 값을 이동 시킬지에 대한 수치이다.)
- 편미분의 값에 따라 값을 조정해 나아가는 것을 확인 할 수 있다.
-
Learning Rate
- 하이퍼파라미터(hyper parameter)라고도 한다.
- 값이 너무 크면 큰 값으로 발산하고 반대로 너무 작으면 갱신을 할 때 많은 연산이 필요함으로 적절한 값 설정이 중요하다.
Reference
https://bhsmath.tistory.com/172
사이토 고키(齋藤 康毅), 『Deep Learning from Scratch』, 개앞맵시, 한빛미디어(2017), p107-p146
