
이번 포스팅에서는 파이썬의 예외처리, 파일처리 로그처리에 대한 개념을 정리해보고 데이터를 다루는 여러가지 방법에 대하여 정리를 해 보았습니다.
파이썬의 예외처리
발생할 수 있는 예외를 사전에 처리하여 프로그램이 중지되지 않고 실행될 수 있도록 Handling이 가능
-
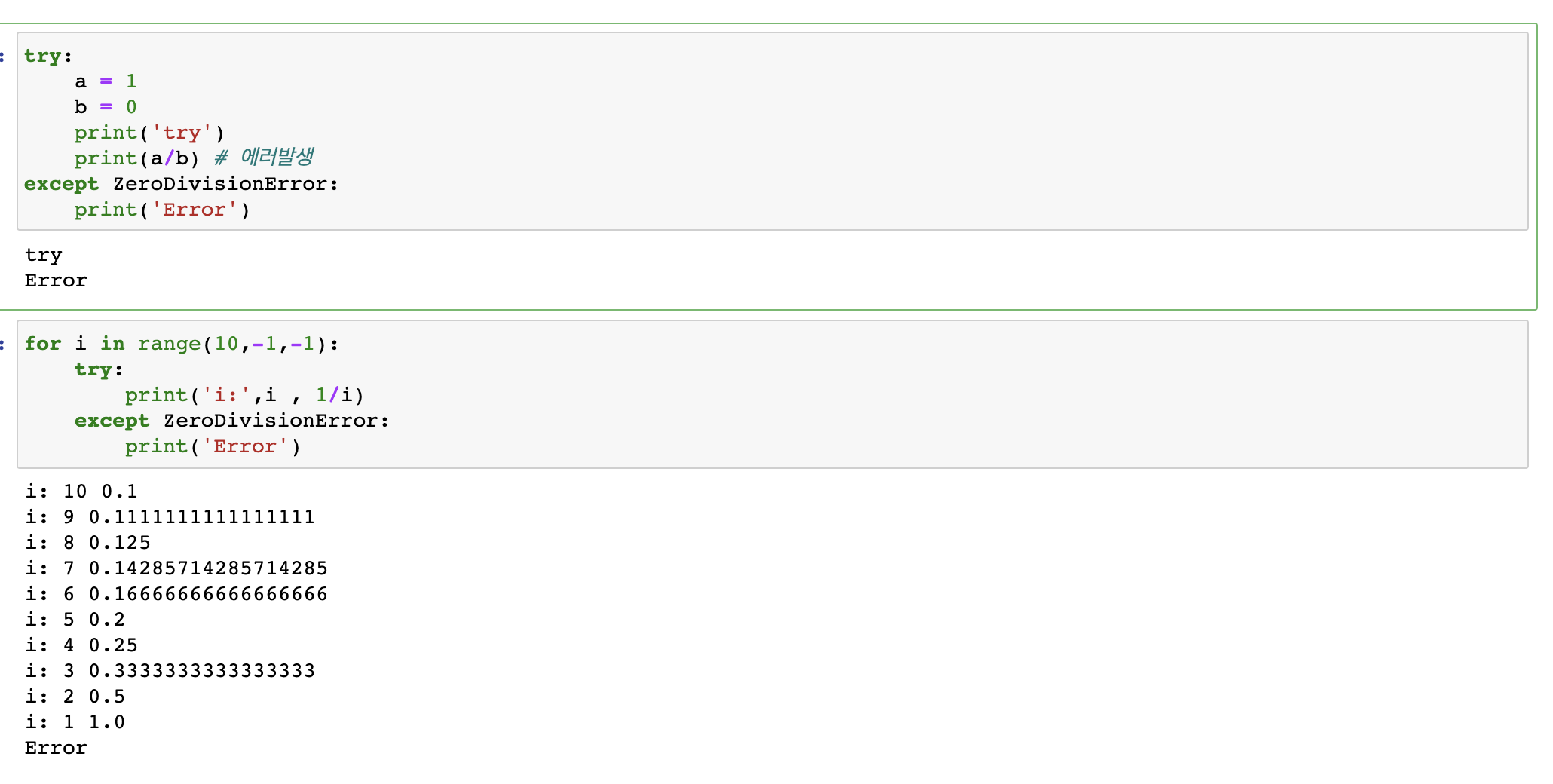
try ~ except구문
- try문을 수행하면서 에러가 발생 시 except문이 수행이 됨
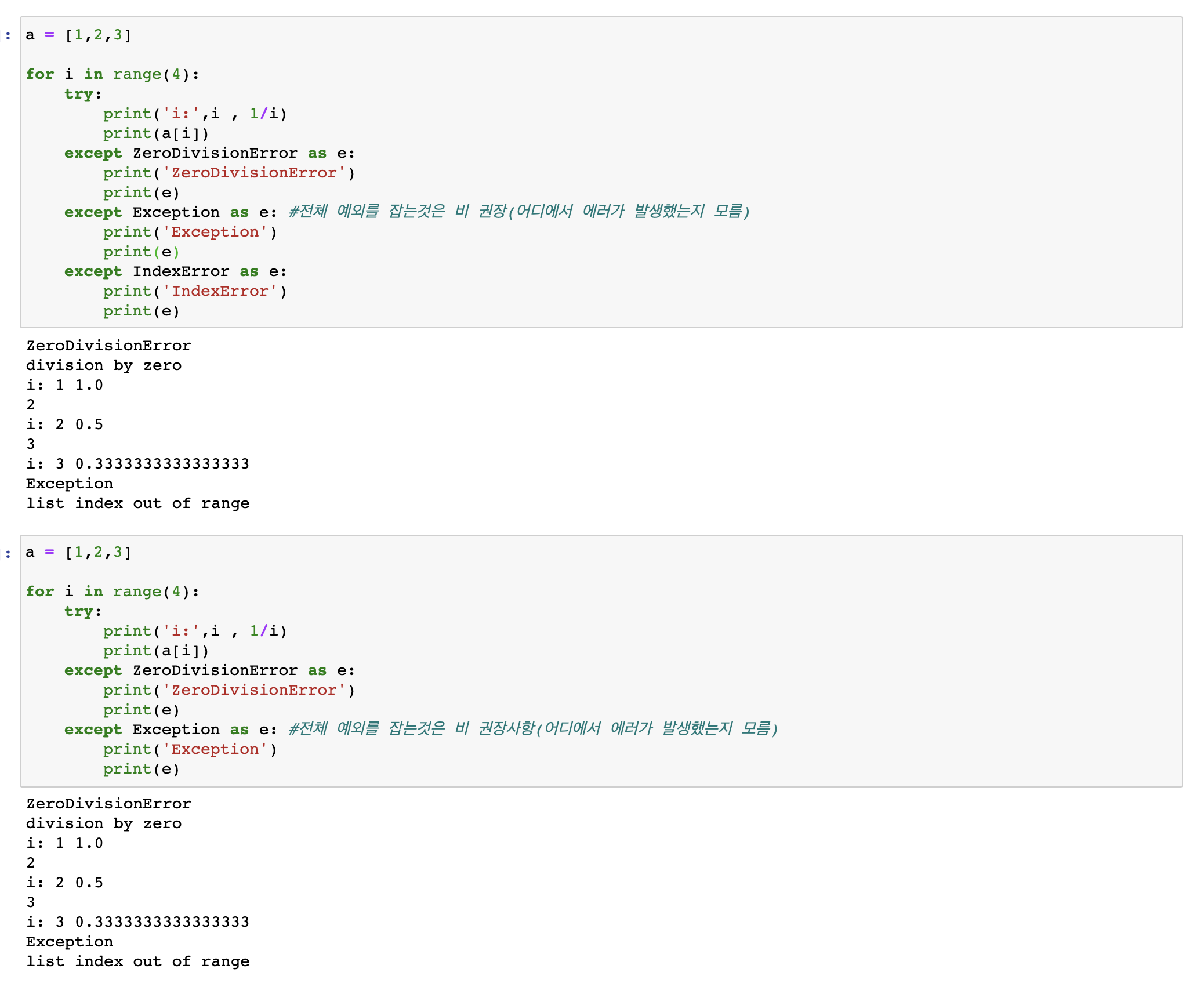
- Exception은 모든 오류를 잡아 낼 수 있다.
- except문이 여러개가 있으면 위에서부터 조사를 하다 해당 예외시 처리가 됨
- "as" 문을 이용하여 오류문을 출력할 수 있음

-
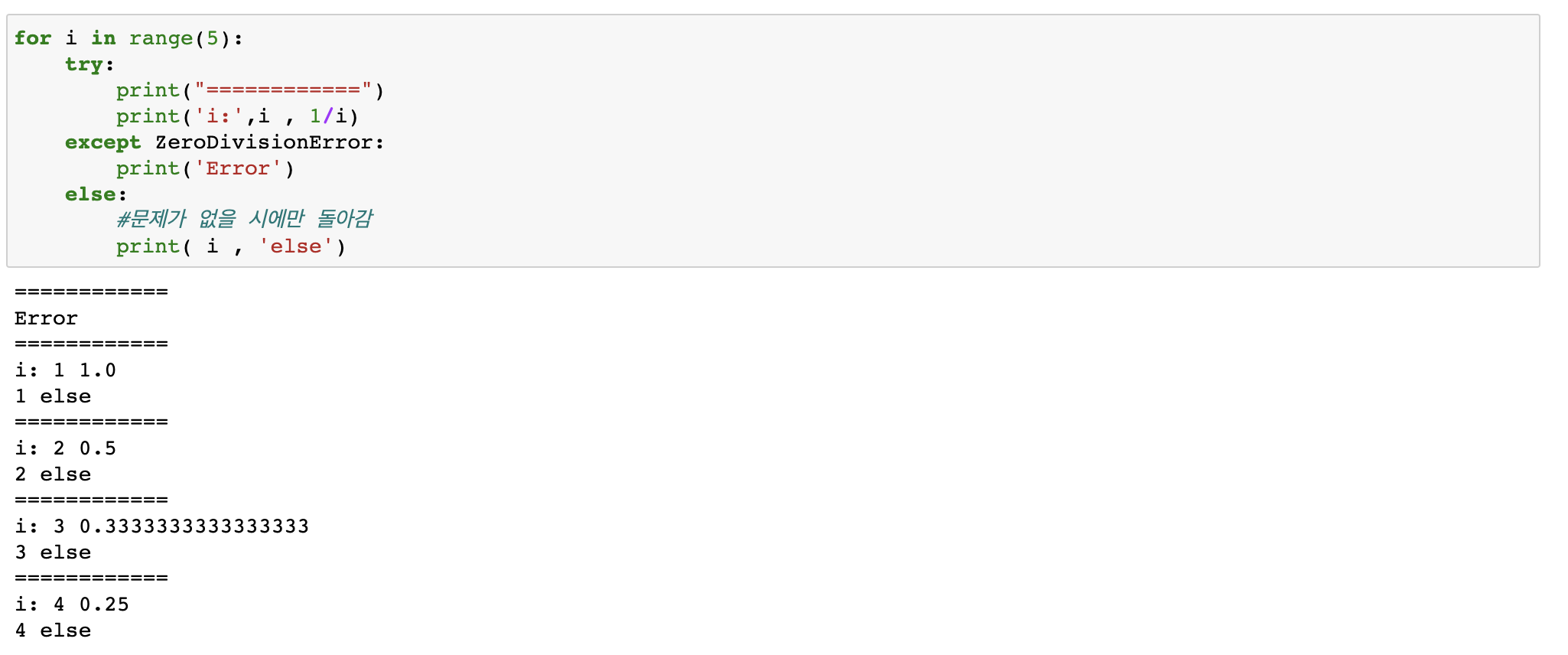
try ~ except (+)구문
- try ~ except ~ else : try구문이 에러없이 수행 시 기능을 수행
- try ~ except ~ finally : try 혹은 except구문이 수행 된 후 수행이 됨

-
raise구문
- 사용자가 원하는 시점에 예외를 발생 시킬 수 있음
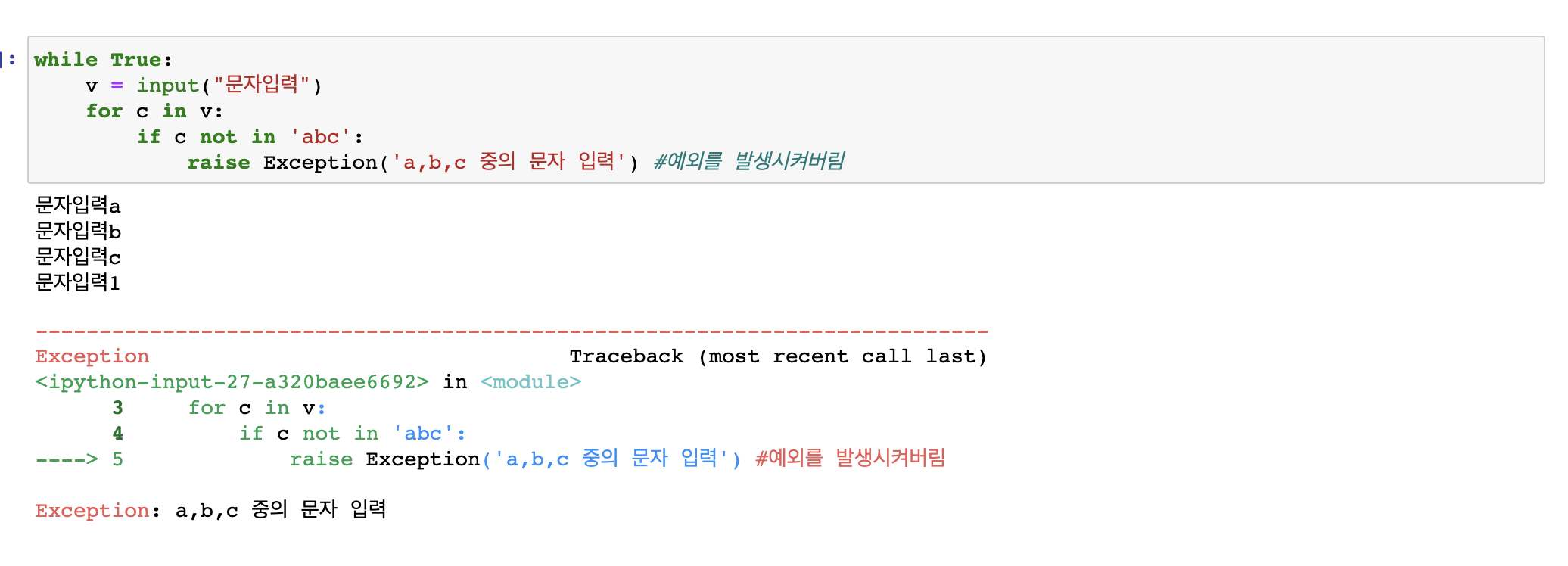
- 사용자가 원하는 시점에 예외를 발생 시킬 수 있음
-
assert문
- 뒤의 조건이 True가 아니면 AssertError를 발생시킨다.(함수의 타입체크 같은 경우 사용 할 수 있다.<힌트를 사용하는 방법도 존재>)
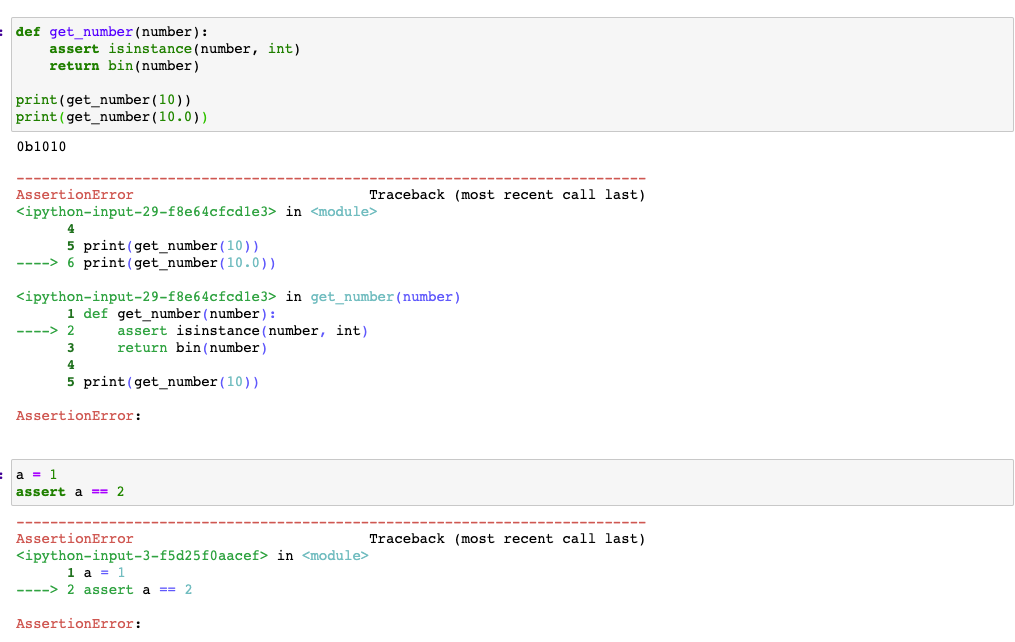
- 뒤의 조건이 True가 아니면 AssertError를 발생시킨다.(함수의 타입체크 같은 경우 사용 할 수 있다.<힌트를 사용하는 방법도 존재>)
파이썬의 파일 입출력
-
파일 열기 모드의 종류

-
파일 읽어오기

-
파일 읽어오기(readlines) : 내용을 한번에 가져옴

-
파일 읽어오기(readline) : 내용을 한줄씩 가져옴(대용량의 파일 처리시 유용, 종료조건 설정을 해 주워야 함)
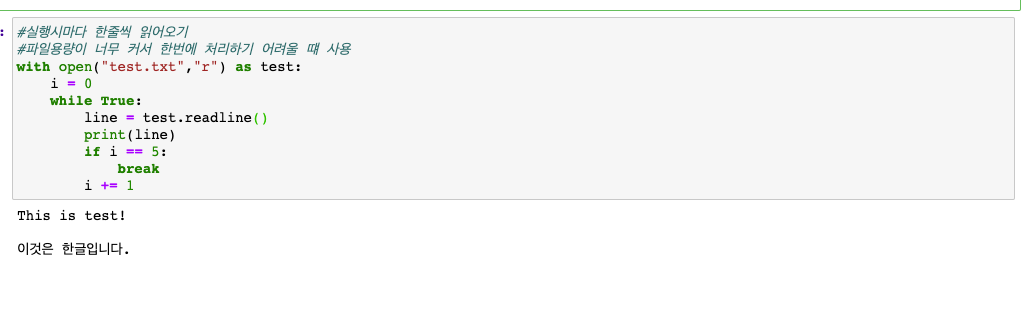
-
인코딩 방식에 따른 파일 쓰기
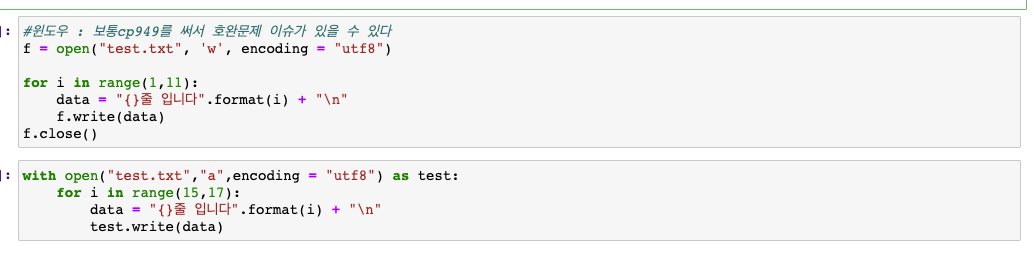
-
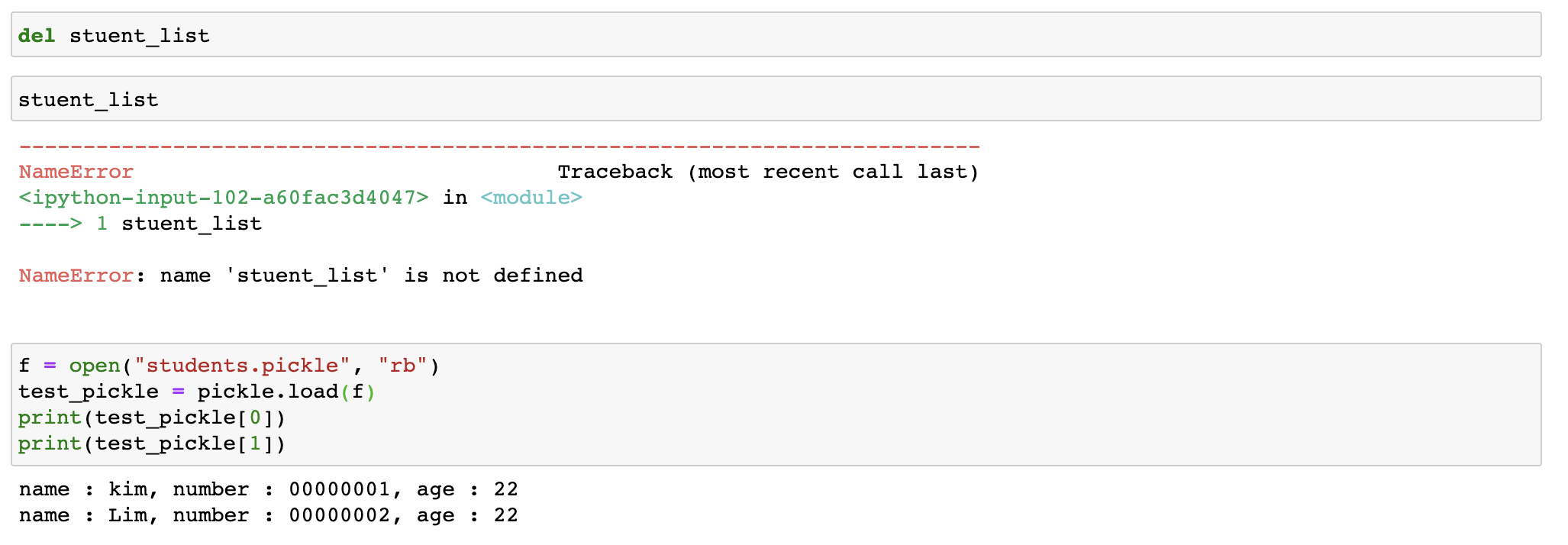
pickle
- 파이썬의 객체를 영속화 하는 bulit-in객체(객체의 정보를 pickle파일로써 저장)
- 저장해야 하는 정보, 계산 결과(모델)등에서 활용을 할 수 있다.
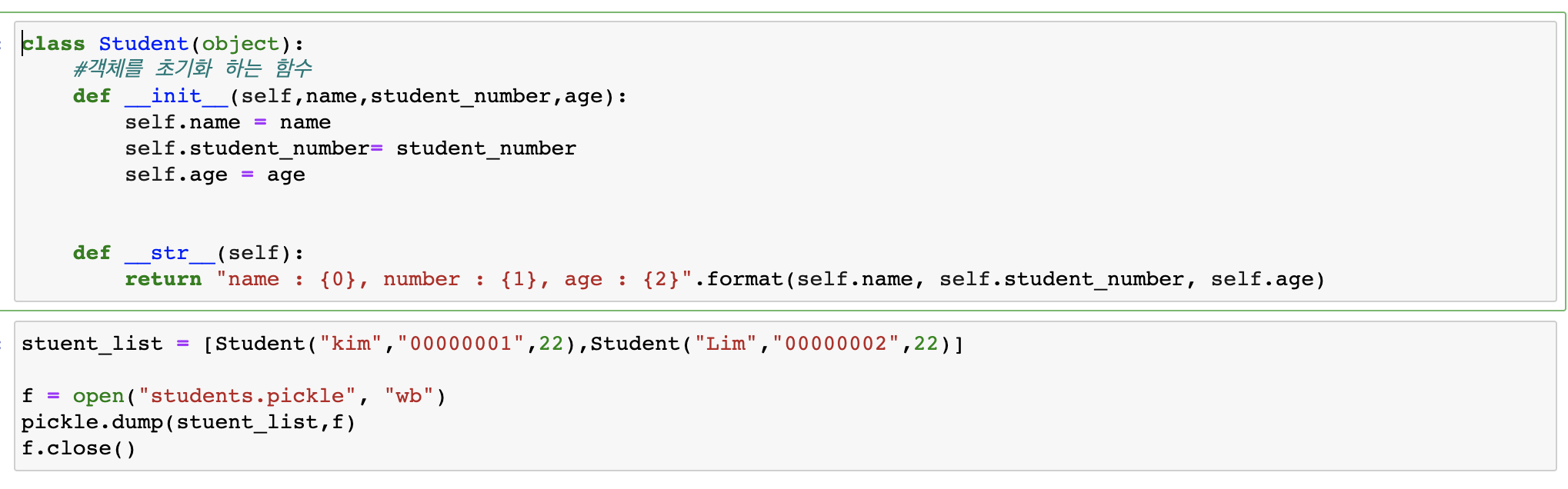
파이썬의 로그 남기기
- print()와는 다르게 logging모듈을 사용하면 어떠한 메세지인지(단순정보, 에러 등...)판단하기 쉽기에 loggig모듈을 사용할 수 있다. 또한, 파일에 내용을 저장하여 프로그램의 진행 상황을 남길 수 있다.
-
os모듈에 있는 path.join을 이용하면 운영체제에 맞는 경로를 도출해 낼 수 있다

-
파일 복사

-
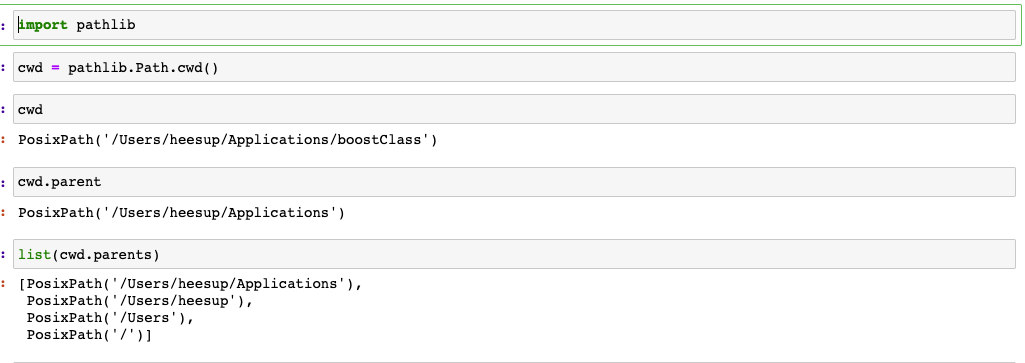
pathlib 모듈을 사용하여 path를 객체로 담에 더욱 편리하게 접근 가능
-
원하는 파일에 남기고 싶은 문자열(문구)저장

-
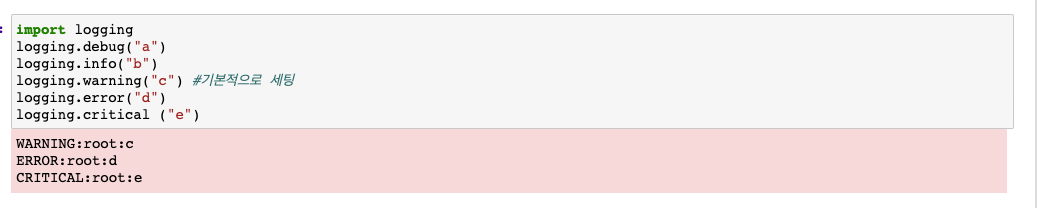
Logging Handling : logging 모듈을 사용하여 기본 로그들을 관리할 수 있다.
기본적으로 초기 세팅은 warning단계부터 출력을 해 줌
단계 조절은 추가적인 세팅이 필요함

로그의 내용을 파일에 저장 가능

formatter적용 : 로그의 형식을 지정 해 줄 수 있음
-
#log formatter
#log의 결과값의 format을 지정해줄 수 있음
import logging
logger = logging.getLogger('spam_application')
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('spam.log') #파일에 로그 저장
fh.setLevel(logging.DEBUG)
ch = logging.StreamHandler() #콘솔에 찍히는 로그 레벨 저장
ch.setLevel(logging.ERROR)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)
logger.debug("a")
logger.info("b")
logger.warning("c")
logger.error("d")
logger.critical ("e")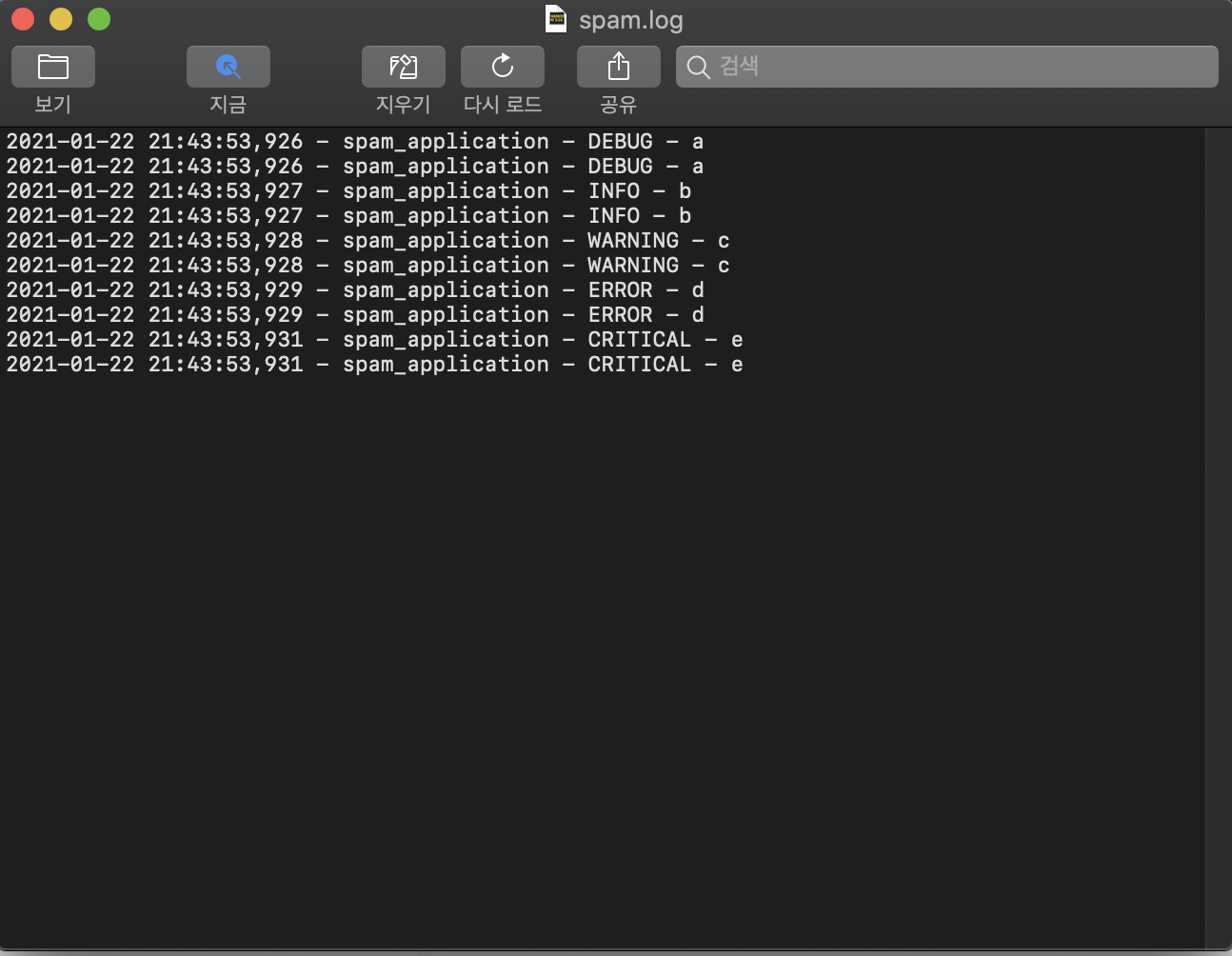
파이썬의 설정 관리
-
파일 위치, 저장장소 , Operation타입 등 프로젝트 내에서 반복적으로 쓰이는 설정 정보를 관리하기 위해 파이썬은 1)configparser 2)argparser를 이용한다
-
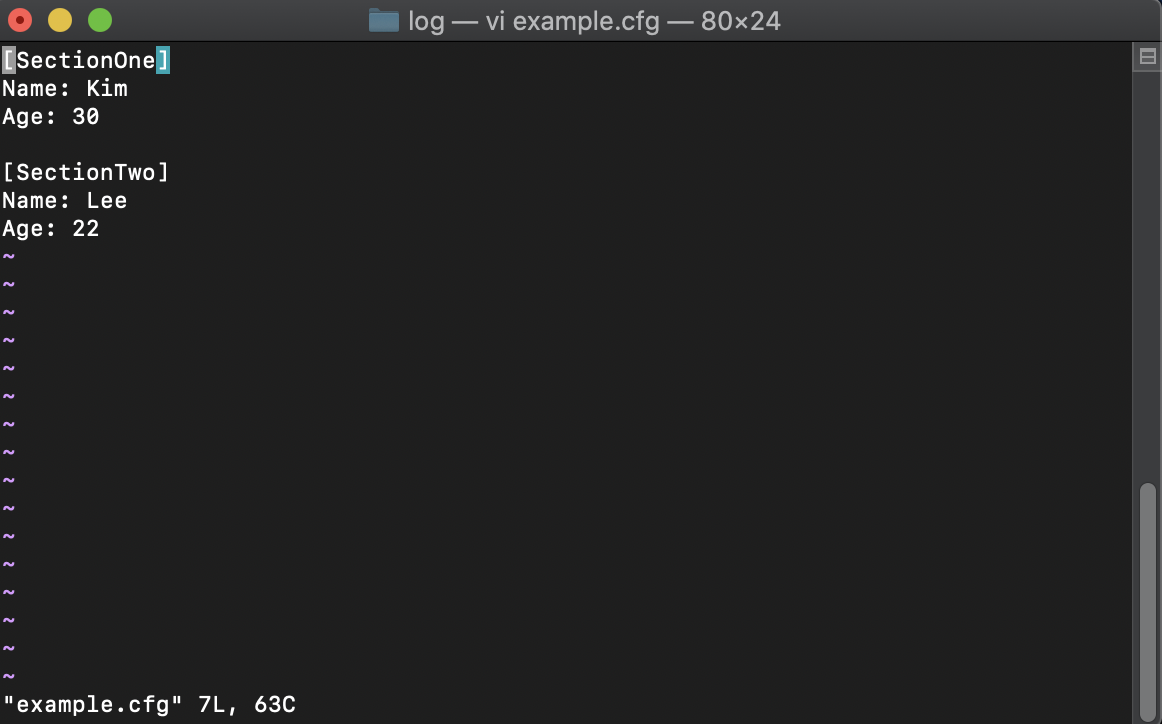
configparser : 프로그램 설정 정보를 파일에 넣고 모듈을 이용하여 값을 사용
터미널의 touch 명령어를 사용하여 파일을 생성 후 vi 명령어를 통하여 파일 수정

-argparser(Command-Line Option) : 콘솔에서 프로그램 실행시 설정값을 제공하여 저장
import argparse
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('integers', metavar='N', type=int, nargs='+',
help='an integer for the accumulator')
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max,
help='sum the integers (default: find the max)')
args = parser.parse_args()
print(args)
print(args.accumulate(args.integers))python3 argparser_ex.py 1 2 3 4 
python3 argparser_ex.py 1 2 3 4 --sum
python3 argparser_ex.py -h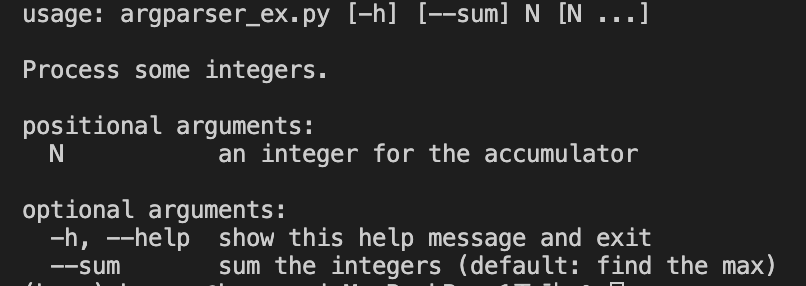
데이터의 저장 방식
- 데이터 저장 방식의 종류
- csv
- 웹<html> 파일
- XML파일
- JSON파일
- csv(comma separate Values)
- 필드를 쉼표로 구분한 텍스트 파일
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위해서 만들어짐
with open("csv/customers.csv") as f:
while True:
data = f.readline() #한줄씩 가져옴
if not data:
breakimport csv
with open("csv/customers.csv") as f:
#delimiter : 필드의 구분, quotechar : delimiter를 포함한 데이터를 묶을 구분자, quote의 필드 적용범위<csv.QUOTE_ALL - 모든 필드가 '"'로 구분>
reader = csv.reader(f,delimiter = ',', quotechar = '"', quoting = csv.QUOTE_ALL)- 웹<html> 파일
- 웹의 html에서 특정 데이터를 크롤링을 할 때 보통 사용
- 정규식을 이용하여 원하는 데이터 추출 가능
- https://regexr.com/ 에서 정규식 테스트 가능
import re
import urllib.request
#html내용을 가져옴
url = "https://bit.ly/3rxQFS4"
html = urllib.request.urlopen(url)
html_contents = str(html.read().decode("utf8"))
results = re.findall(r"([A-Za-z0-9]+\*\*\*)", html_contents) #패턴을 가진 문자열을 찾아냄
for result in results:
print(result)- XML
- 데이터의 구조와 의미를 설명하는 TAG를 사용하여 표시
- TAG사이에 구조적인 정보 표현 가능
- 스키마와 DTD(Document Type Definition)등으로 정보에 대한 메타정보 표현, 다향한 형태 전환 가능
- html과 문법이 비슷하다.
- 다양한 모듈 지원(ex BeautifulSoup)이 지원됨
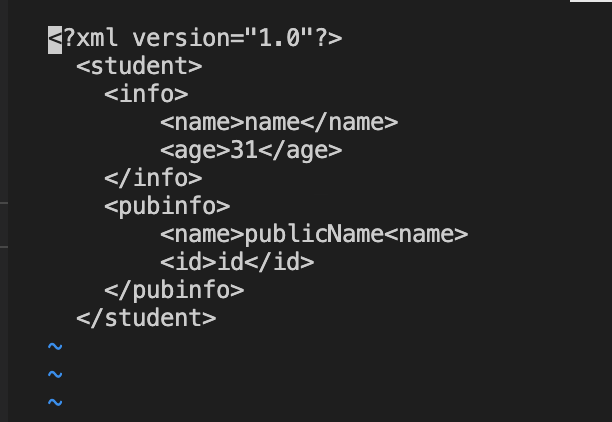
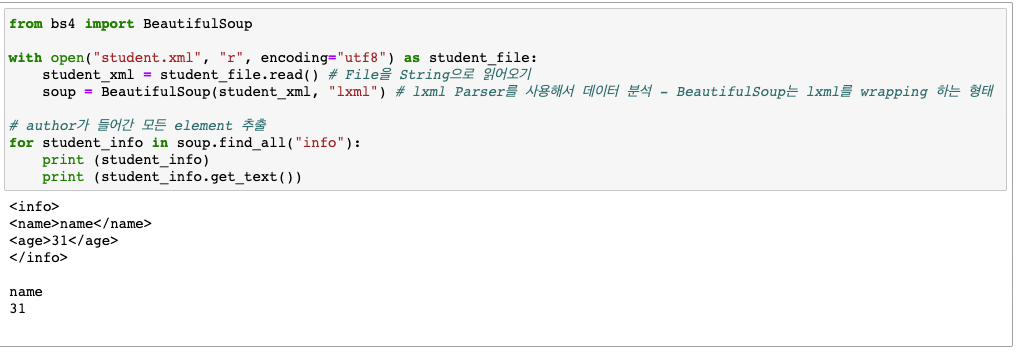
- JSON(JavaScript Object Notation)
- 원래는 jsdml 데이터 객체 표현 방식이었으나 이해하기 편한 구조라 XML의 대체제로써 많이 쓰임
- 파이썬의 dict타입과 상호 호환 가능
- 각종 API 사용시 데이터 전송간 많이 쓰이는 데이터 구조


Reference
Naver BoostCamp AI Tech - edwith 강의
https://m.blog.naver.com/PostView.nhn?blogId=acornedu&logNo=220934409189&proxyReferer=https:%2F%2Fwww.google.com%2F
https://wikidocs.net/21050
https://wikidocs.net/26
https://tariat.tistory.com/844
https://docs.python.org/ko/3/library/argparse.html
https://docs.python.org/ko/3.7/howto/logging-cookbook.html
https://docs.python.org/ko/3/howto/logging-cookbook.html
