
Cache
CPU pipeline
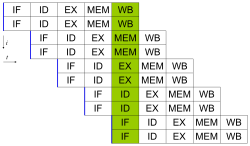
슈퍼 스칼라
여러개의 명령어를 동시에 처리하기위해 파이프라인 및 연산 유닛을 다중화, 명령어 재배치
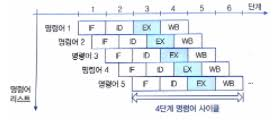
슈퍼 파이프라이닝
파이프 라인의 소요시간을 조절해서 병렬성을 높임
컴파일러 최적화
실행시간, 메모리 사용량을 줄이기 위한 기법 주로 불필요한 연산을 줄임.
컴파일 타임에 상수 값을 결정하기, 순서 바꾸기 등기, 순서 바꾸기 등
Memory Model
배경
위에서 살펴본 컴퓨터 구조 때문에, 각 명령어들을 재배치해서 최적화함
다음 예시를 살펴보자
#include <thread>
#include <atomic>
int32 x = 0;
int32 y = 0;
int32 r1 = 0;
int32 r2 = 0;
volatile bool ready;
void Thread1()
{
while (!ready);
y = 1;
r1 = x;
}
void Thread2()
{
while (!ready);
x = 1;
r2 = y;
}
int main()
{
int32 count = 0;
while (true)
{
ready = false;
count++;
x = y = r1 = r2 = 0;
thread t1(Thread1);
thread t2(Thread2);
ready = true;
t1.join();
t2.join();
if (r1 == 0 && r2 == 0)
break;
}
cout << count << endl;
}싱글 스레드 관점에서 살펴보면 위 코드는 종료되지 않고 무한 루프를 돌아야 한다.
하지만 멀티 스레드에서는 변수의 가시성, 명령어 재배치 등에 의해서 종료되는 결과를 보여준다.
Memory Model
- c++11 부터 도입
- Atomic(원자적) 연산에 한해, 모든 스레드가 동일 객체에 대해서 동일한 수정 순서를 관찰
- is_lock_free()를 통해서 CPU차원에서 원자적 연산이 가능한지 확인
수정 순서
- Write - write 일관성
- A,B두 쓰기가 같은 메모리 M에 대해서 A가 B보다 먼저 발생한다면 모든 쓰레드는 A B 순서로 관찰
- 쓰기의 순서가 바뀌지 않음
- Read - read 일관성
- 메모리 M에대한 읽기 A, B가 있고 A가 B보다 먼저 발생
- A가 어떤 쓰기X (M에 X를 씀)에서 값을 가져 왔으면
- B가 읽은 값은 X 혹은 Y(X 이후의 쓰기)이다
- X 이전의 값을 볼 수 없다.
- Read - write 일관성
- 읽기 A가 쓰기 B보다 먼저 발생하면
- A가 읽은 값은 B이전에 변경된 값
- B 이후의 값을 볼 수 없음
- Write - read 일관성
- 쓰기 X가 읽기 B 이전에 일어나면
- B는 X 또는 이후의 Y의 값을 본다
- 즉, 과거의 값을 볼 수 는 없음.
- Happens-before (먼저 발생함)
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true:- A is sequenced-before B.
- A inter-thread happens before B.
정책
- Sequentially Consistent
- seq_cst
- 가장 엄격, 최적화 여지 적음, 직관적
- 가시성, 재배치 해결
- seq_cst
- Acquire-Release
consume(C++26부터 비권장)- acquire
- release와 짝을 맞춰서 사용
- acquire로 같은 변수를 읽으면 release 이전의 명령들이 acquire 하는 순간 관찰 가능(가시성 보장)
- release
- acquire와 짝을 맞춰서 사용
- release 이전의 명령들이 release이후로 재배치 될 수 없음
- acq_rel
- 바로 위 2개를 합쳐 놓은 것
- Relaxed
- relaxed
- 자유로움, 최적화 여지 많음, 직관적이지 않음
- relaxed
- intel, AMD에서는 그냥 store, load를 사용해도 하드웨어 차원에서 지원을 하기에 seq_cst 한거랑 같다고 함
- ARM은 차이가 있다고 함.
사용
#include <thread>
#include <atomic>
atomic<bool> ready = false;
int32 value;
//같은 경우도 사실은 memory_order의 기본 값을 통해서 함수를 호출하고 있었던 것
void Producer()
{
value = 10;
ready.store(true, memory_order::memory_order_seq_cst);
//ready.store(true, memory_order::memory_order_release); // 이 위의 명령어는 아래로 재배치 금지
//ready.store(true, memory_order::memory_order_relaxed);
// atomic 없이 사용하려면
std::atomic_thread_fence(memory_order_release);
}
void Consumer()
{
while (ready.load(memory_order::memory_order_seq_cst) == false);
//while (ready.load(memory_order::memory_order_acquire) == false);// 이 아래의 명령어는 위로 재배치 금지, release 이후의 변경사항이 모두 반영
//while (ready.load(memory_order::memory_order_relaxed) == false);
cout << value;
}
int main()
{
ready = false;
value = 0;
thread t1(Producer);
thread t2(Consumer);
t1.join();
t2.join();
}Thread Local Storage (TLS)
개념
- 스레드가 독립적으로 가지는 로컬 스토리지 (각자가 가진 스택 말고 다른거임)
- 나만의 전역 메모리
- 데이터를 TLS로 옮길때만 lock을 걸고 TLS에서 자유롭게 쓰기
사용
#include <thread>
#include <atomic>
#include <chrono>
thread_local int32 LThreadId = 0;
void ThreadMain(int32 threadId)
{
LThreadId = threadId;
while (true)
{
printf("Hi I am Thread %d \n", LThreadId);
//cout << "Hi I am Thread " << LThreadId << endl;
this_thread::sleep_for(1s);
}
}
int main()
{
vector<thread> threads;
for (int i = 0; i < 10; i++)
{
int32 threadId = i + 1;
threads.push_back(thread(ThreadMain, threadId));
}
for (auto& t : threads)
t.join();

일단 창고에 넣어놓으면 언젠가는 쓰겠지