Web Search
이전 search engine
- 웹 크롤링
- 단어가 포함된 페이지를 인덱스화
- querie에 포함된 단어들을 포함한 페이지를 보여줌
이전 page ranking
- search query와 얼마나 맞는가에 따라 정렬
- 고려하는 점
- 얼마나 그 단어가 나타났는지
- 단어가 어디에 위치했는지 (title, header)
Spam
- 페이지가 검색엔진 상에서 좋은 위치에 있도록 하는 기법이 적용된 페이지
- 10~15%가 spam임
Term Spam
- 페이지에 특정 주제에 관한 단어를 잔뜩 추가시키고 보이지 않게 처리
- 높은 랭크를 가진 페이지의 내용을 가져와서 보이지 않게 처리
- 해결책
- anchor text, 그리고 인접한 text들을 사용해서 해결
Link Spam
- Page Rank를 올리기위해 링크 구조를 만든 것
- 3가지 종류의 페이지
- Inaccessible pages
- Accessible pages
- 블로그 댓글 등에 target page link 올림
- Owned pages
- spammer 가 온전히 관리할 수 있는 페이지
Link farm
- Target page t의 rank 의 값을 최대화 하기위해 만들어진 것
- t에 가능한 많은 accessible page를 링크
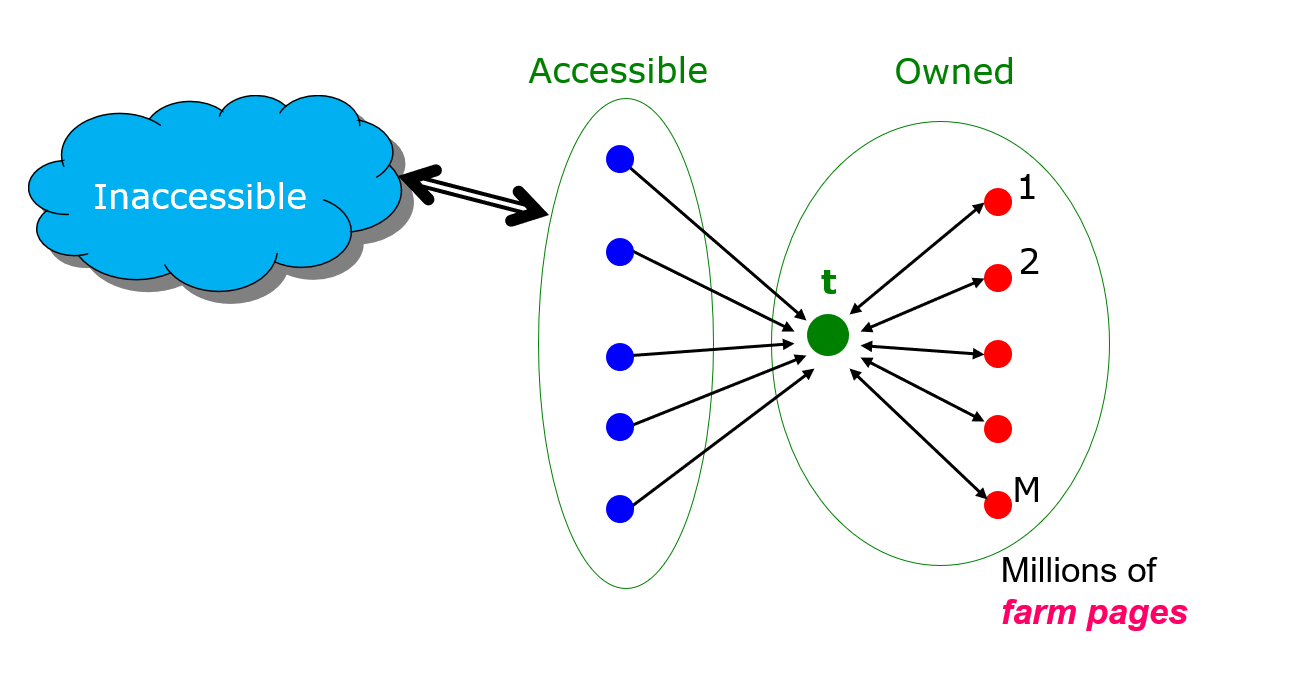
: Spammer owned page
: pages on the web
: accessible page들에 의한 PageRank
: t의 PageRank
각 farm에서 오는 rank =
결국 M이 클수록 Y가 증가함
Trust Rank
spam 처리
- Term
- 이메일 스팸 걸러 내는 것과 유사
- 통계학적 기법을 통해 분석
- 복제된 페이지 탐지에도 좋음
- link
- spam farm 같은 구조를 탐지하고 블랙리스트에 올린다
- Trust Rank
- 믿을 수 있는 페이지들의 집합으로 텔레포트 하는 Topic-specific PageRank
Idea of Trust Rank
- Approximat isolation : 좋은 페이지가 스팸 페이지를 가리키는 건 거의 없다
- seed page를 샘플로 몇개 고른다
- 인간이 seed page를 판별한다
- 비싼 작업이기에 크기가 작으면 작을수록 좋다
- 여기서 good으로 분류된 페이지를 "Trusted Page"
- 그 뒤로 teleport-set에 Trusted Page를 널고 Topic-specific PageRank 진행
- 0~1의 trust 값을 가집
- 임계값을 이용해 스팸 구분
Simple Model
- Trusted page의 trust값을 1로
- page p의 trust 값:
- P의 outgoing link 가리키는 노드들의 집합
- : p가 q에게 trust값을 주다
- Trust는 누적값임
- Topic-specific PageRank 비슷하지만 초기값 설정이 다르다
Seed set 고르기
- 적당한 크기를 골라야함
- 고르는 방법
- PageRank
- Use trusted domains
Spam mass
- : p의 페이지 랭크
- : p의 페이지 (신뢰한 페이지로 텔레포트 한 경우)
- : 스팸 페이지에서 오는 랭크값
- spam mass p =
HITS (Hpertext-Induced Topic Selectopn)
페이지 랭크와 비슷한 개념, Link as votes
그러나 페이지 랭크와는 다르게 u 에서 나가는 노드를 중요하게 여김
Hubs
- Quality as an expert
- 연예 기획사
- link to authrities
Authorities
- authority
- 연예인
- 중요한 정포를 포함
연예기획사에 소속된 연예인이 유명하면 소속사도 유명하다!
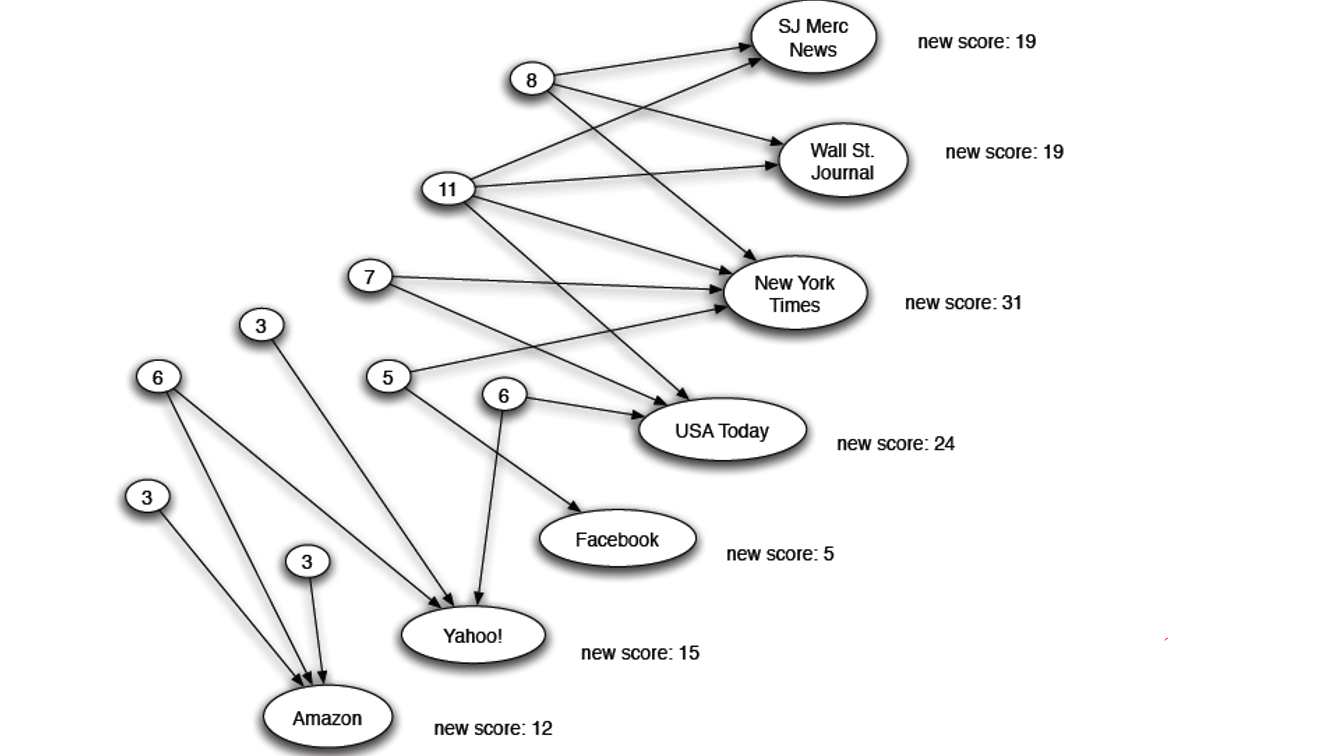
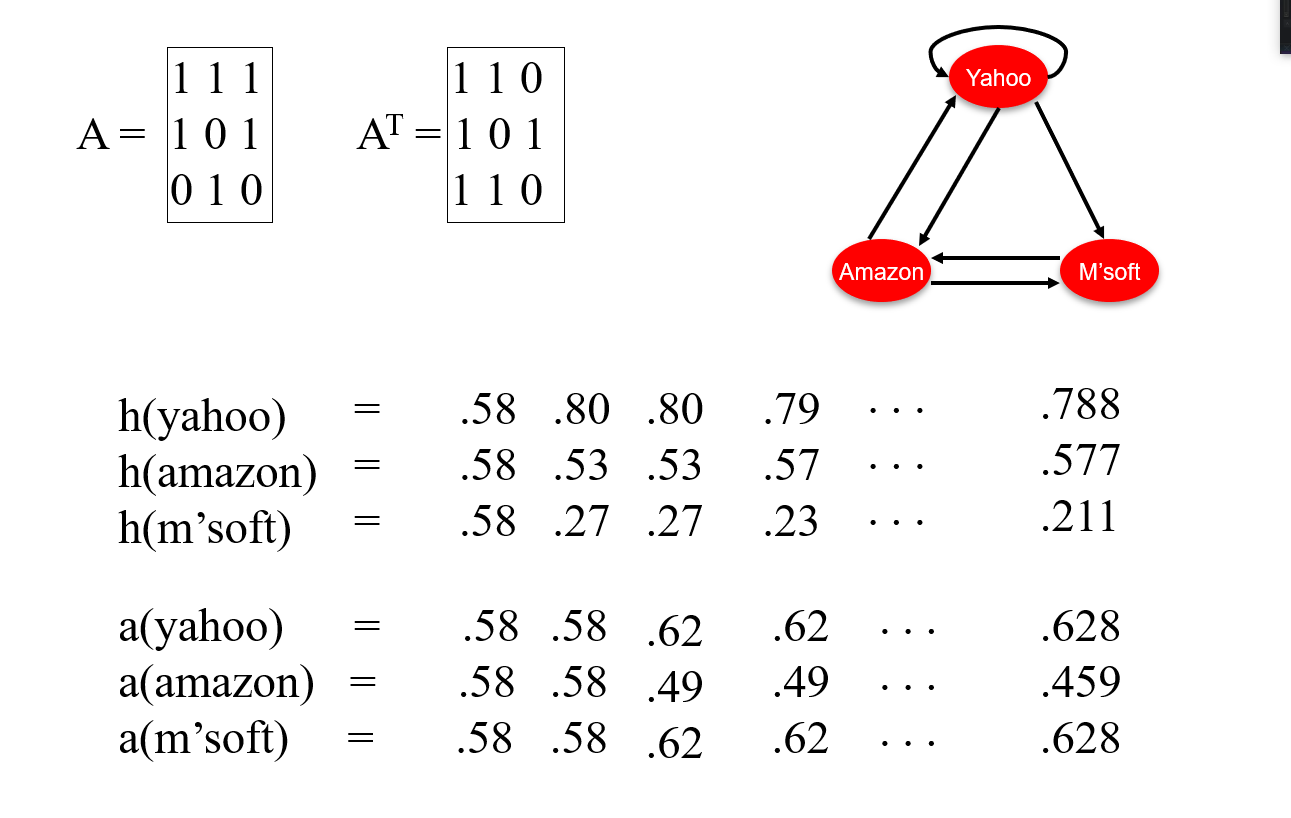
HITS algorithm
- Authrity score:
- Hub score:
- 초기화
- 정규화:
기타 사항
- HITS는 하나의 stable point 로 수렴함
- So

일단 창고에 넣어놓으면 언젠가는 쓰겠지