Dropout & Bottleneck feature & Batch normalization
딥러닝 관련 논문 및 포스팅을 보다보면 Dropout, Bottleneck-feature, Batch-normalization라는 용어를 많이 볼 수 있습니다.
이 글에서는 이 용어들에 대해 알아보려고 합니다.
Dropout
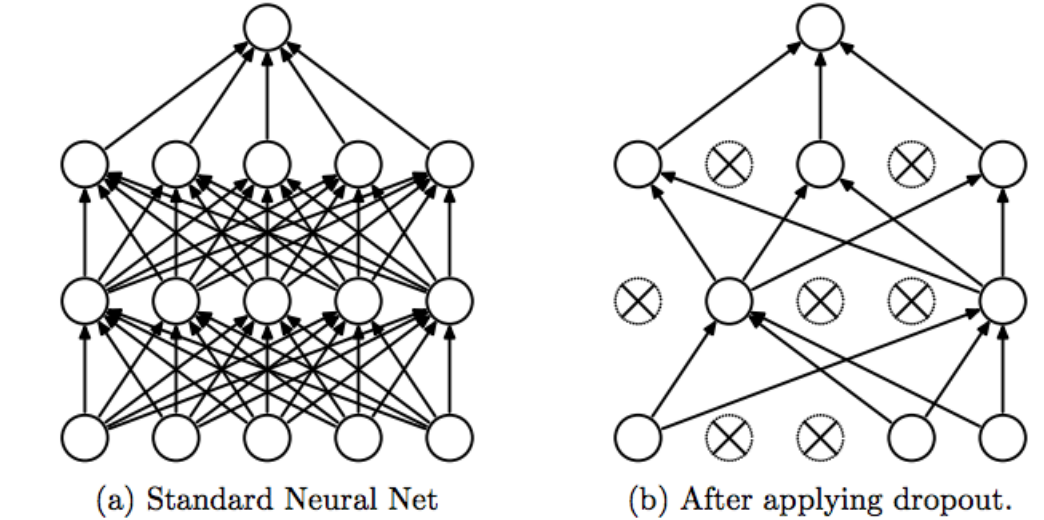
Dropout은 overfitting을 피하기 위한 방법 중 하나입니다.
드롭아웃을 초기에 도입한 유명한 모델중 하나는 AlexNet 입니다.
전통적으로 모델의 성능을 올리는 방법중 하나인 Ensemble은 여러개의 다른 모델을 학습 시킨 뒤, 각 모델의 결과를 조합하는 방식입니다. 하지만 이 방식은 여러개의 모델을 각각 학습시키는 시간이 오래걸린다는 단점이 있습니다.
Dropout은 더 효율적인 방법으로 위와 같은 효과를 내는 방법입니다.(기존보다 약 2배의 학습시간)
모델을 학습시에 hidden layer에서 각 뉴런의 output을 0.5의 확률로 0으로 만듭니다.
해당 뉴런은 dropped out됐다고 표현하며, 모델의 순전파와 역전파에 사용되지 않습니다.
확률에 따라 dropout 되므로 매 입력마다 모델의 구조가 조금씩 달라집니다.
모델의 학습 과정에서만 동작하며 추론 및 테스트 시에는 dropout을 사용하지 않습니다. (Pytorch에서는 model.eval() 명령어를 통해 비활성화)
Dropout을 통해 뉴런들이 서로 의존적이게 되는 co-adaptation을 피할 수 있습니다. 따라서 좀 더 robust한 모델을 구축할 수 있습니다.
co-adaptation은 같은 층의 여러 뉴런들의 입력 및 출력 연결강도가 같아지면, 학습이 진행되어도 해당 뉴런들은 같은 일을 수행하게 되어 컴퓨팅 파워와 메모리의 낭비가 일어나는 문제입니다.
또한, 각 mini-batch 마다 모델의 구조가 조금씩 다르므로 결과적으로 여러개의 모델을 조합하는 voting 효과를 얻을 수 있습니다.
Pytorch에서는 아래와 같이 드롭아웃 동작을 확인할 수 있습니다. Colab링크

Dropout을 사용하면 다음 뉴런으로 가는 output이 일부 사라져 최종적으로 해당 뉴런이 받는 값들이 줄어듭니다. 그러면 모델의 뒤로갈수록 input값이 작아지는 현상이 발생하기 때문에 실제 동작할때는 "dropout 확률이 p인 layer"의 output은 1/(1-p) 값이 곱해지게 됩니다.
Bottleneck feature
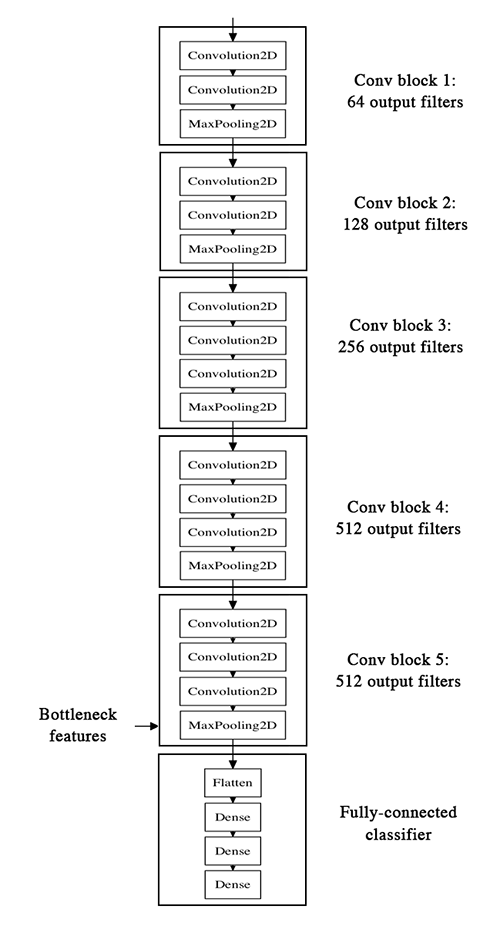
CNN모델은 크게 feature extraction의 Conv. layer와 classification의 FC layer의 두 part로 구분됩니다. 이때 Conv.layer의 마지막 convolution을 통해 얻은 결과맵을 bottleneck feature라고 합니다.
bottleneck feature는 가장 추상화된 값, 가장 작은 사이즈의 feature map을 가지고 있으며 전이학습(transfer learning)을 할 때, FC layer부분의 input값으로 사용됩니다.
Batch normalization
PMLR 2015에서 처음 언급된 개념으로 Gradient Vanishing / Gradient Exploding을 방지하기 위한 방법입니다. (ReLU 사용, Careful initialization, Small learning rate 등의 방법도 있습니다.)
배치 정규화의 장점은 학습 속도를 빠르게 만들어주고(with 성능 유지 및 성능 향상), weight initialization에 대한 민감도를 감소시키며, 모델의 일반화(regularization)효과가 있습니다.
ML에서는 입력 정규화(normalization)을 통해 parameter들의 variance를 맞춰줌으로써 더 큰 learning-rate를 사용할 수 있게되고, 학습속도를 증가시킬 수 있습니다. Batch norm.은 input data뿐만 아니라 각 hidden layer의 input을 정규화하는 방법입니다.
Whitening(화이트닝)기법은 입력값들의 특징을 uncorrelated하게 만들어주고 각각의 분산을 1로 만들어주는 작업입니다(공분산 행렬 = 단위행렬). 하지만 정규화에 비해 계산량이 많아 화이트닝보다 정규화 기법을 많이 사용합니다.
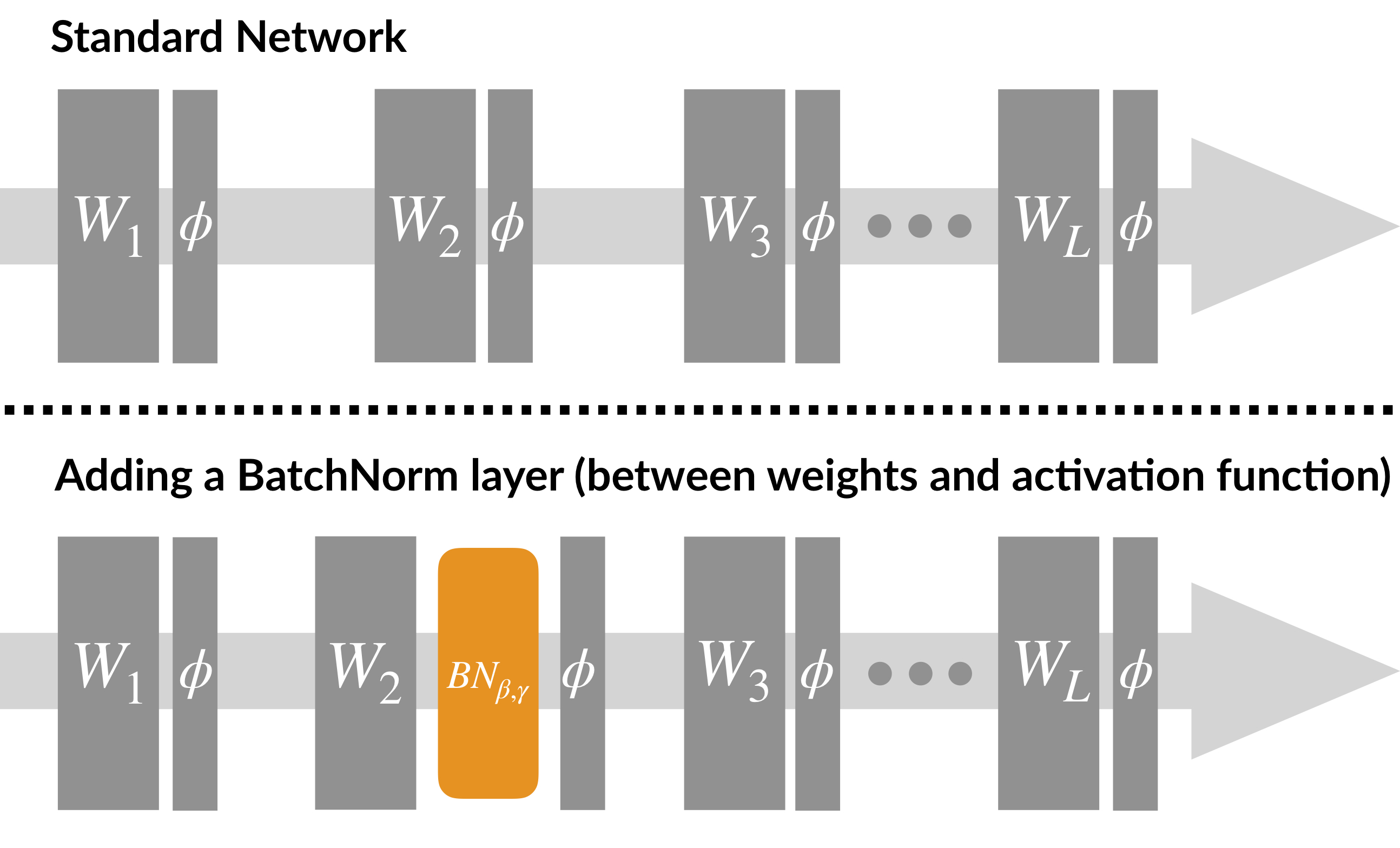
모델에 BN(batch norm.) layer를 추가하여 parameter 감마(scaling)와 베타(shifting)를 학습시키며, non-linearity를 잘 유지하는 방향으로 학습이 진행됩니다.
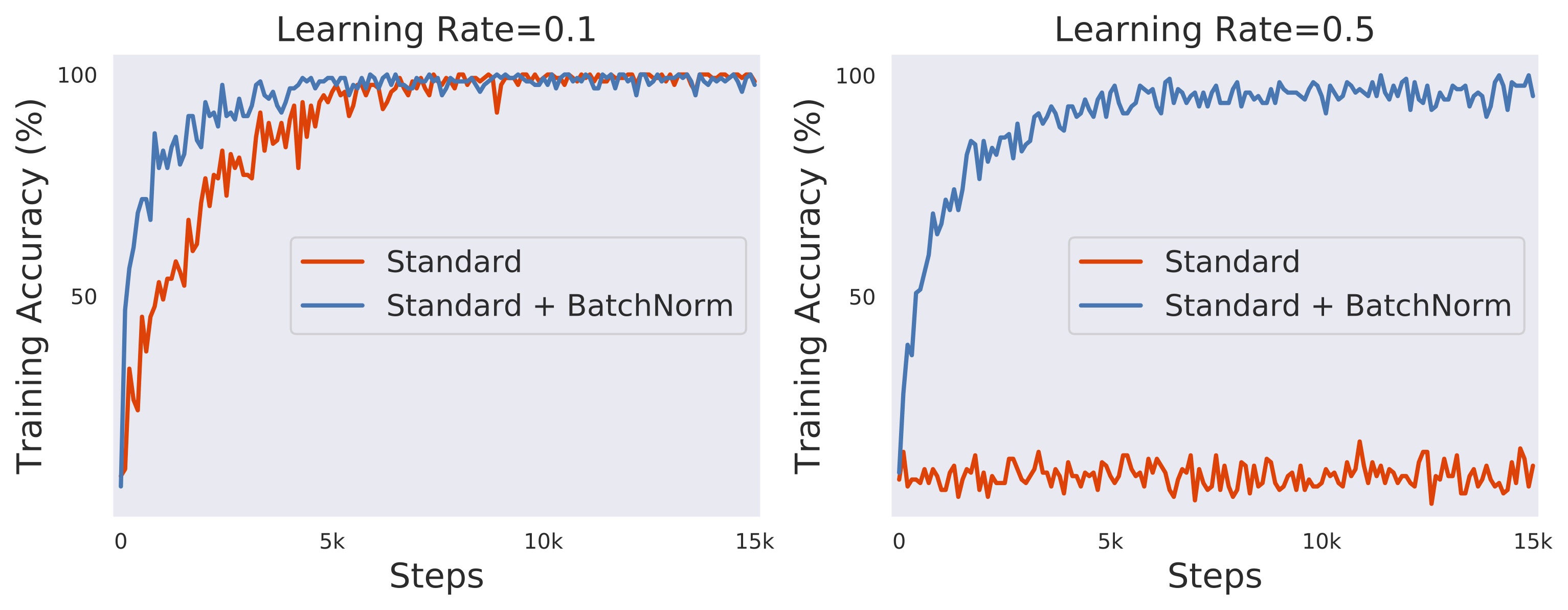
NIPS 2018논문을 보면, BN을 사용하면 기존보다 빠르게 학습이 되며, 큰 Learning-rate에서도 안정적으로 학습이 되는걸 볼 수 있습니다. Learning rate = 0.5의 경우 일반적인 경우는 학습이 진행되지 않는걸 볼 수 있습니다.
Train vs Test
Batch normalization의 BN layer는 모델이 학습(train)할때와 추론(inference, Test or Validation)할 때의 동작이 다릅니다.(작성중..)
Reference
[Dropout]
https://jmlr.org/papers/volume15/srivastava14a.old/srivastava14a.pdf
https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
https://discuss.pytorch.org/t/unclear-behaviour-of-dropout/22890
[Batch Normalization]
http://proceedings.mlr.press/v37/ioffe15.pdf
https://arxiv.org/pdf/1805.11604.pdf
https://youtu.be/58fuWVu5DVU
