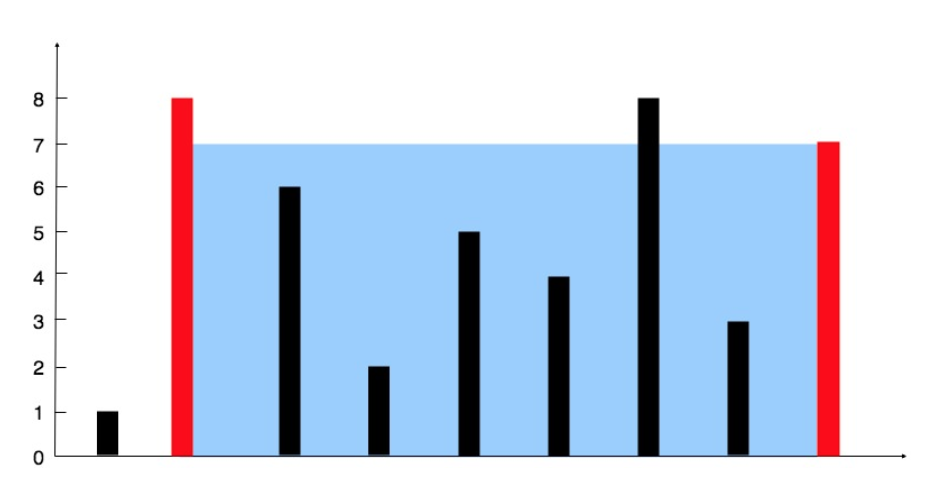
인자인 height는 숫자로 이루어진 배열입니다. 그래프로 생각한다면 y축의 값이고, 높이 값을 갖고 있습니다.
아래의 그래프라면 height 배열은 [1, 8, 6, 2, 5, 4, 8, 3, 7] 입니다.
저 그래프에 물을 담는다고 생각하고, 물을 담을 수 있는 가장 넓은 면적의 값을 반환해주세요.가정: 배열의 길이는 2이상입니다.
내가 푼 답
function getMaxArea(height) {
let maxArea = 0;
for (let i = 0; i < height.length; i++) {
for (let j = i + 1; j < height.length; j++) {
const currentArea = (j - i) * Math.min(height[i], height[j]);
maxArea = maxArea > currentArea ? maxArea : currentArea;
}
}
return maxArea;
}문제를 보자마자 가장 먼저 생각난 것은 중첩 반복문이었다. 구할 수 있는 모든 면적을 구해가며 가장 큰 값을 반환할 변수에 담으면 된다고 생각했다.
실제로 풀어서 통과는 했는데, 시간 복잡도가 O(N^2)라는 게 마음에 걸렸다. 실제로 문제가 예시로 든 배열은 요소로 9개를 갖고 있지만, 테스트 케이스 중 하나는 무려 300개의 요소를 갖고 있었다. 아무리 j가 i + 1에서 시작한다고 하더라도, 효율적이지 못한 알고리즘이라는 것은 변함없었다.
최대의 값을 구해야 한다는 점에서 탐욕 알고리즘을 사용하는 문제일 것이라 생각했는데, 한 시간 동안 고민해봐도 마땅한 방법이 떠오르지 않았다. 그래서 maxarea greedy javascript 등의 키워드로 구글링을 했고 O(N)으로 풀이하는 답을 얻을 수 있었다.
효율적인 답
function getMaxArea(height) {
let left = 0;
let right = height.length - 1;
let maxArea = 0;
while (left < right) {
const currentArea = (right - left) * Math.min(height[left], height[right]);
maxArea = maxArea > currentArea ? maxArea : currentArea;
height[left] > height[right] ? (right -= 1) : (left += 1);
}
return maxArea;
}양 끝 인덱스에서 시작해, 각 인덱스가 가리키는 요소의 높이를 비교한 뒤 더 짧은 쪽의 인덱스를 이동하는 방식이다. 알고리즘을 설명하는 gif를 보며 간신히 논리를 파악해 작성할 수 있었고, 모든 테스트 케이스를 통과할 수 있었다. 이 알고리즘은 내가 생각한 알고리즘과는 달리, O(N)으로 효율적인 알고리즘이다. (이 답을 설명하고 있는 글은 내가 푼 논리를 순진한 Naive 알고리즘이라고 설명하기도 했다.)
문제는 일단 통과는 했으나 왜 통과가 되는지 이해가 안 갔다는 점이고, 더 큰 문제는 답을 설명한 글이 영어로 작성되어 있었다는 점이다. 코드카타 짝에게 내가 푼 논리는 설명이 가능했는데, 이 논리는 '이렇기 때문에 답이 도출된다'라고 설명할 수가 없었다. 그저 '이게 더 효율적으로 풀 수 있는 답이래요'라는 말만 반복할 수밖에...
알고리즘 풀이
Everytime, we are moving our pointer i ahead if height of line at ith index is smaller or j pointer if height of line at jth index is smaller. This means whichever line is smaller, we won’t consider it again, because, this line could be the answer only if the other line is larger than it and at maximum width and to be noticed that this is the time when other line is larger as well as max distance apart. So, not considering it makes sense.
대략 원 글을 해석해보면 다음과 같다. 의역이 포함되어 있다.
"매번, 우리는 왼쪽과 오른쪽 중 더 작은 쪽 인덱스를 움직였다. 이것은 둘 중 어느 쪽이 더 작든 간에, 우리는 작은 쪽을 다시는 고려하지 않을 것이라는 뜻이다. 왜냐하면 작은 쪽이 답이 되기 위해선 다른 쪽이 더 커야함과 동시에 가장 큰 너비일 때만 가능한데, 작은 쪽을 옮기는 지금이 바로 그 순간이기 때문이다. 따라서 고려하지 않는 것은 타당하다."
반복문을 돌면서 양 끝 인덱스는 점점 좁혀진다. 따라서 가장 큰 너비(maximum width)는 매번 그 상황의 j - i (양 끝 인덱스의 차)일 수 밖에 없다. 만일 작은 쪽의 인덱스가 가리키고 있는 값이 정답에 포함되려면, 반대쪽의 인덱스는 그 값에서 가장 멀리 있으면서 + 그 값보다 큰 값을 가리키고 있어야 한다. 그리고 그 상황이 작은 쪽의 인덱스를 옮기고 있는 바로 지금의 상황이므로, 만일 지금이 정답이라면 이미 기존의 maxArea와 비교해 대체됐을 것이다.
