해당 글은 유튜버 테디노트님의 강의를 보고 공부한 내용을 정리한 것입니다.
출처: 테디노트의 LangGraph 개념 완전 정복 몰아보기(3시간)
이번 시간에는 LangGraph의 코드를 직접 짜보면서 노드 구성 방법과 연결에 대해서 알아보고자 한다.
State 정의
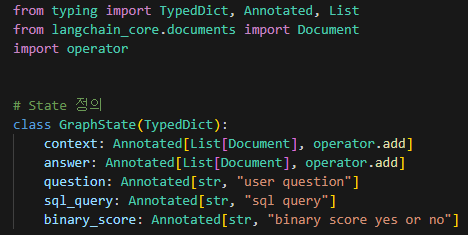
먼저 위 내용은 State를 사전에 정의한 것이다.
State는 이전에 말했듯이 노드와 노드 간에 정보를 전달할 때 상태(state) 객체에 담아 전달하는 것을 의미한다.
상태를 먼저 정의해두어야 안에 내용을 저장하고 다음 노드로 저장한 내용을 넘길 수 있다.
TypeDict
TypedDict는 타입을 딕셔너리 형태로 저장한다는 의미로 위 코드에서는 다음와 같이 해석된다.
context라는 키에 대해서 리스트 형태로 저장한다는 의미이다.
Annotated
Annotated는 해석하면 주석이라는 의미로, context: Annotated[str, "주석"]
이렇게 활용된다. 이때 주석 부분에는 해당 str에는 어떤 내용이 들어가야 하는지 주석을 넣어주는 형태로 활용된다.
operator
operator는 리스트 형식에서만 활용이 가능하며, 문서 병합의 개념으로 활용된다.
context: Annotated[List[Document], operator.add] 이렇게 코드를 작성하게 되면
하나의 노드에서 context에 리스트를 이미 저장해 두었다면, 다른 노드에서 다시 context를 건드릴 때 operator.add가 있다면 + 연산을 수행하는 것이 가능하다.따라서 operator를 활용해 리스트를 overwrite하지 않고 계속해서 추가하는 것이 가능해진다는 것이다.
이렇게 활용하고자 하는 모든 State를 정의해주면 되고, 이후 추가로 필요한 State가 있다면 추가해주면 된다.
노드 정의
이제 노드를 만들어보자.
우리가 노드를 정의할 때는 반드시 함수로 정의하게 된다.
이때 함수의 입력인자는 상태(State) 객체이고, 반환(return)은 대부분이 상태(State) 객체일 것이다.
하지만 이때 반환의 경우엔 conditional edge에 따라서 달라질 수 있다.
조건부 엣지를 활용하기 위해서는 반환할 때 다른 값을 주어서 다른 노드로 이동시켜야 하기 때문이다.
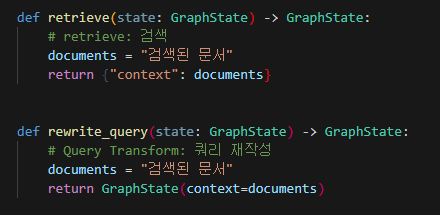
먼저 위 코드를 보면 입력인자는 모두 GraphState로 같지만, 반환 인자의 모양이 다른 것을 확인할 수 있다.
미리 답을 말하자면 둘 다 모습만 다를 뿐 같은 것을 의미하는 코드이다.
둘 다 "context"라는 값을 상태로 돌려주는 것으로 결과는 똑같이 {"context": "검색된 문서"} 이렇게 생긴 딕셔너리 형태이다.
그 이유는 첫 번째 return {"context": documents}는 그냥 파이썬 기본 방식을 활용한 것이고, 두 번째 return GraphState(context=documents)는 '나는 이걸 GraphState 타입이라고 알려줄게!'라는 의미이다.
더 쉽게 이야기하면 첫 번째 방식은 생일선물을 줄 때 일반 포장지에 전달하는 방식이고 두 번째 방식은 내가 직접 만든 예쁜 포장지에 이름을 적어서 보내주는 것이라고 생각하면 된다.
그래서 원하는 방식을 골라서 작성해주면 되지만, 일단 시각적으로 제대로 이해하기 좋은 것은 두 번째 방식이라고 생각한다.
그럼 노드의 입력과 출력 상태에 대해서 알아봤으니 내부 구현을 알아보자
현재는 간단하게 구현하기 위해서 안에 내용은 단순히 변수에 문자열을 저장하는 형태로 진행했다.
이후에는 직접 해당 함수에 대해서 직접 넣고 싶은 내용을 넣어서 함수를 구현해주면 된다.
단 반드시 입력과 출력은 State가 되어야 하는 것을 잊지 말자!!
(출력의 경우 조건부 엣지가 존재하면 출력이 State가 아닐 수 있음)
그래프 정의
이제는 그럼 위에서 노드를 구현해 두었으니, 그래프를 정의해보자.
그래프 정의는 시작과 끝 그리고 정의한 노드(함수)들을 추가하고 연결하는 과정이라고 생각하면 된다.
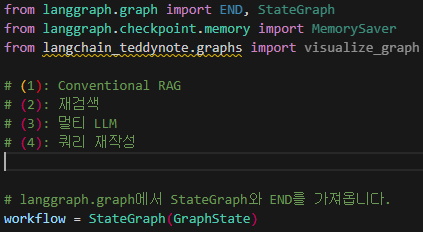
항상 우리가 그래프를 정의하기 전에는 상태 그래프라는 것 안에 위에서 먼저 정의해주었던 상태를 가져와 주어야 한다.
변수는 바뀌어도 상관이 없지만, 대부분 workflow라고 칭한다.
workflow = StateGraph(상태) 이런 형태로 구성되며 상태에는 위에서 정의한 GraphState를 넣어주면 된다.
workflow = StateGraph(GraphState)
이렇게 상태 정의가 끝나면 이후에 노드를 하나씩 추가해주면 된다.
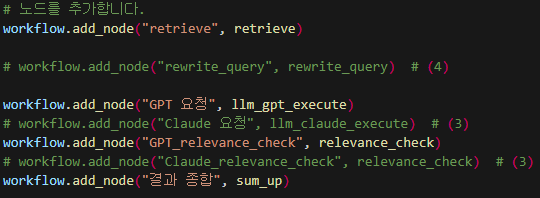
노드 추가는 어렵지 않게 위에서 정의한 workflow에 .add_node를 활용하여 추가하도록 하면 된다.
구성은 다음과 같다.
workflow.add_node("노드이름", 함수이름)
이때 노드의 이름은 한글, 영어 상관없지만 대부분 영어로 작성한다.
그리고 오른쪽에는 우리가 위에서 정의한 노드(함수)의 이름을 적어주면 된다.
이번 시간에는 우리가 Conventional RAG(리트리버하고 문서를 가져와 LLM에게 전달해 답변을 받는 가장 기본적인 RAG)를 진행할 것이기 때문에 남은 노드들도 똑같이 추가해주도록 하면 된다.
위 노드들의 과정은 다음과 같다.
리트리버 진행 -> GPT가 답변 생성 -> GPT 답변에 대한 관련성 체크 -> 결과 종합
그럼 이제 노드 연결을 진행해보자.
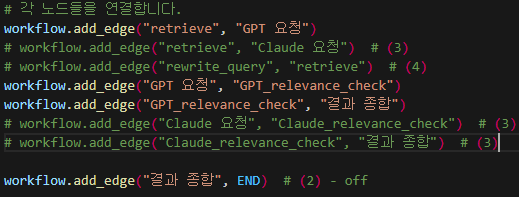
노드 연결 과정은 정말 간단하다.
workflow에 대해서 .add_edge를 통해 이전에 구성한 노드 이름을 활용해 하나씩 연결해주면 되기 때문이다.
위와 같이 retrieve와 GPT 요청 노드를 연결하는 데 이때 앞에 있는 노드가 더 먼저 실행되는 노드라고 생각하면 된다.
위와 같이 모든 노드들을 연결해주고 마지막 노드의 경우 END까지 연결해주면 끝난다.
시작 포인트, 메모리 저장소, 그래프 컴파일, 그래프 시각화
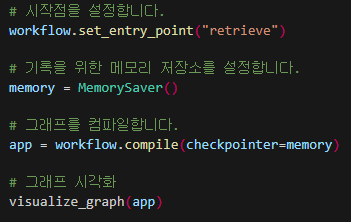
이제 우리는 노드 연결과 끝점까지 설정을 해주었으니, 마지막으로 시작점을 설정해야 한다.
우리가 만약 사전에

이와 같이 START로 시작점을 END와 같이 만들어서 연결해주었으면 상관없지만 현재는 따로 시작점을 만들어주지 않았기 때문에 위와 같이 workflow에 대해서 set_entry_point를 통해 가장 먼저 시작하는 "retrieve" 노드를 시작점으로 설정해주어야 한다.
방법은 위와 같이 workflow에 대해 .set_entry_point("시작 노드 이름") 이렇게 구성해주면 된다.
이렇게 시작점 생성이 되었으면 우리는 기록을 메모리에 저장하기 위해서 따로 MemorySaver()를 생성해 memory 변수에 저장하도록 해야 한다.
이렇게 메모리를 설정해주는 이유는 LangGraph에서 노드들이 어떻게 동작했는지 기록하기 위해서이다.
예를 들어 context, answer같은 상태가 노드마다 어떻게 바뀌었는지 알아야하는 노드들의 경우 메모리를 통해서 확인이 가능하다.
이렇게 메모리를 설정해주면 마지막으로 그래프를 최종적으로 만들어주어야 한다.
그래프를 최종적으로 동작하게 만들어주기 위해서는 완성한 그래프를 컴파일하는 과정을 거쳐야 하고 이때 위에서 만든 memory가 활용된다.
app = workflow.compile(checkpointer=memory) 이렇게 메모리를 checkpointer로 활용하기 위해 연결해주고 workflow를 컴파일해주면 그래프가 완성된다.
이제 마지막으로 우리가 만든 그래프를 시각화하는 과정을 거쳐야 한다.
시각화의 경우 visualize_graph를 통해 만든 그래프를 쉽게 시각화할 수 있다.
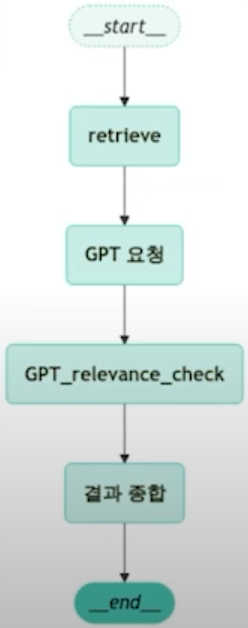
시각화의 내용은 위와 같이, 우리가 만든 그래프에서 노드의 흐름이 이와같이 흘러간다는 것을 알 수 있다.
조건부 엣지(conditional_edges)
현재 우리의 로직은 위 이미지와 같이 진행되는데 우리가 만약 재검색을 진행하고자 한다면 어떻게 해야 할까?
우리는 이때 사용해야 하는 것이 바로 조건부 엣지이다.
이는 함수 A의 결과가 a, b 2개가 나오는 데 이때 서로 다르게 처리해주고 싶은 경우에 활용된다.
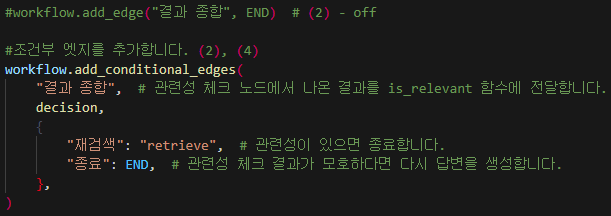
위 코드와 같이 이전에 작성해두었던 END 부분을 주석처리하고 조건부 엣지를 설정해주면 된다.
이렇게 설정하게 되면 workflow에 대해서 .add_conditional_edges를 진행하게 되고 이는 "decision"이라는 함수의 결과가 종료인 경우엔 END 노드로, 재검색인 경우엔 "retrieve" 노드로 이동하게 한다.
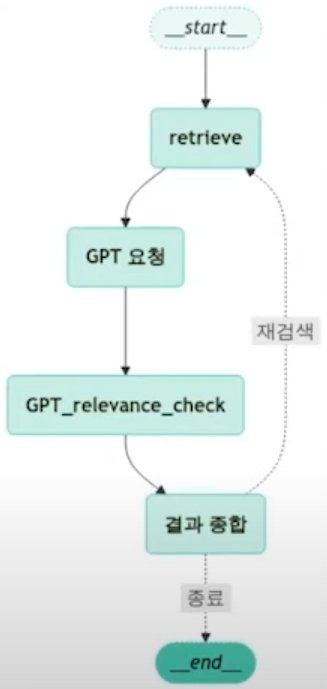
위와 같이 수정 후 다시 시각화를 진행하면 위와 같이 GPT 관련성 체크 노드 이후의 결과가 "결과 종합"이라는 조건부 엣지에 따라서 끝나거나 다시 재검색되는 경우를 확인할 수 있게 된다.
우리가 LangChain에서는 이러한 흐름을 바꾸기 위해서는 처음부터 코딩을 수정했어야 했다.
하지만 LangGraph의 경우엔 우리가 미리 만들어둔 노드들의 순서만 바꿔주거나 조건부 엣지를 통해 성공, 실패 혹은 결과가 1번, 2번, 3번인 경우에 따라서 다른 노드로 이동해 진행하는 것이 가능하다.
그럼 조건부 엣지의 활용방안에 대해서 자세하게 살펴보자.
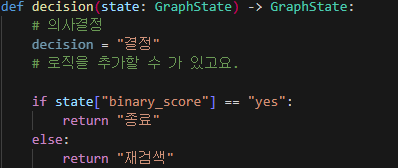
조건부 엣지도 마찬가지로 노드이기 때문에 함수로 구성되어야 한다.
위와 같이 조건부를 처리하기 위한 함수를 지정해주도록 한다.
예를 들어 a라는 결과를 받게 되면은 A라는 응답을, b라는 결과를 받게 되면은 B라는 응답을 return 해주는 것이다.
이후 완성한 함수에 대해서

위에서 진행한 노드 추가와 똑같이 함수에 대해서 노드 추가를 진행해주어야 한다.
workflow에 대해 .add_conditional_edges를 활용해 다음과 같이 작성해주면 된다.
workflow.add_conditional_edges(
"지금 실행 중인 노드의 이름", # (1) 조건 분기를 시작할 노드
decision_function, # (2) 다음 흐름을 결정할 함수,
#현재 state를 받아서 "재검색" 또는 "종료" 같은 문자열 값을 반환
{
"조건1": "조건1일 때 갈 노드", # (3)
"조건2": "조건2일 때 갈 노드",
...
}
)이때 "결과 종합"은 우리가 위에서 미리 만들어 둔 노드 중 하나로 조건 분기를 시작할 노드에 해당되고,

이후 decision은 우리가 state를 받아서 다음 흐름을 결정할 함수가 된다.
이제 오늘은 상태를 정의하고, 노드를 코드로 어떻게 생성하고 연결하며, 조건부 엣지는 무엇이며 어떻게 작성하는지에 대해서 살펴보았다.
이제 다음 정리에서는 조금 더 자세하게 진행되는 내용을 정리해서 요약해보고자 한다.
