해당 글은 유튜버 테디노트님의 강의를 보고 공부한 내용을 정리한 것입니다.
출처: 테디노트의 LangGraph 개념 완전 정복 몰아보기(3시간)
1. LangGraph의 탄생 배경에 대해서...
RAG(Retrieval-Augmented Generation)라는 기능에 대해서 우리는 많은 편리함을 느꼈지만 다음과 같은 갈등을 마주하게 된다.
- LLM이 생성한 답변이 Hallucination이 아닐까?
- RAG를 적용해서 받은 답변이 문서에 없는 "사전지식"으로 답변한 건 아닐까?
- 문서 검색에서 원하는 내용이 없는 경우엔 따로 인터넷 혹은 논문 검색을 통해 부족한 정보를 채울 수 없을까?
예를 들어 RAG의 문제점은 다음과 같습니다.
질문: 건국대학교의 컴퓨터공학과의 학과장을 알려줘!
문서: 건국대학교의 컴퓨터공학과는 1990년도에 만들어졌습니다.
1번 LLM: 답변, 건국대학교 컴퓨터공학과는 1990년도에 만들어졌지만 학과장에 대한 정보는 없습니다.
이를 해결하기 위한 방법
부족한 정보를 웹에서 검색하여 문서에 추가하는 로직을 진행해보자!
1번 LLM: 답변, 건국대학교 컴퓨터공학과는 1990년도에 만들어졌지만 학과장에 대한 정보는 없습니다.
2번 LLM: 검색 쿼리 작성, "1990년도에 만들어진 건국대학교 컴퓨터공학의 학과장"
검색 실행: 건국대학교 컴퓨터공학과의 학과장은 000입니다.
문서 검색 정보와 병합.
문서: 건국대학교의 컴퓨터공학과는 1990년도에 만들어졌습니다.
검색결과: 건국대학교 컴퓨터공학과의 학과장은 000입니다.
1번 LLM: 답변, 1990년도에 만들어진 컴퓨터공학과의 학과장은 000입니다.
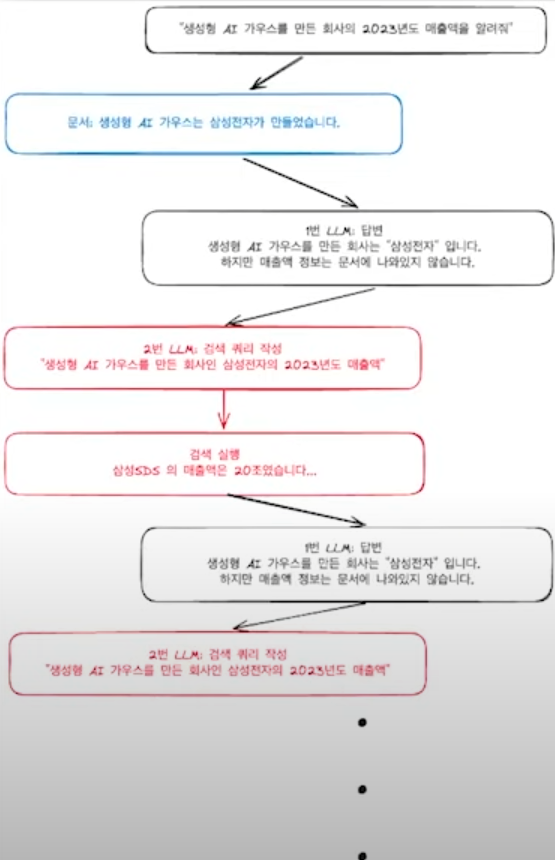
그런데 만약 검색 결과에 잘못된 결과가 포함되어 있다면???
1번 LLM: 답변, 건국대학교 컴퓨터공학과는 1990년도에 만들어졌지만 학과장에 대한 정보는 없습니다.
2번 LLM: 검색 쿼리 작성, "1990년도에 만들어진 건국대학교 컴퓨터공학의 학과장"
검색 실행: 건국대학교 커뮤니케이션 학과의 학과장은 XXX입니다.
(이와 같이 잘못된 검색 실행)
문서 검색 정보와 병합.
문서: 건국대학교의 컴퓨터공학과는 1990년도에 만들어졌습니다.
검색결과: 건국대학교 커뮤니케이션 학과의 학과장은 XXX입니다.
1번 LLM: 답변, 1990년도에 만들어진 건국대학교 커뮤니케이션 학과의 학과장은 XXX입니다.
이렇게 되면 잘못된 검색결과로 인해 결국 Hallucination으로 이루어질 수 있음
우리가 이 Hallucination을 해결하기 위해 Hallucination checker를 두어서 검증 후 다시 검색을 하도록 할 수 있지만, 이런 경우엔 chain이 덕지덕지 붙기 때문에 구조가 너무 복잡하고 계속해서 문제를 해결하기 위한 chain이 붙게 된다.
위와 같은 구조가 된다고 해서 일단 답변의 퀄리티가 올라간다는 보장도 없고, 또한 길어지면 길어질수록 코드가 길어지고 복잡해진다.
그리고 LLM의 일관되지 않은 답변이 마치 나비효과로 이어져 답변 품질저하로 이어지게 된다.
그래서 우리가 지금까지 사용해오던 RAG의 경우 정리하면 다음과 같은 문제점이 있다는 것을 알 수 있다.
- 사전에 정의된 데이터 소싱(PDF, DB, Table 등) 자원
- 사전에 정의된 Fixed Size Chunk
- 사전에 정의된 Query 입력
- 사전에 정의된 검색 방법
- 신뢰하기 어려운 LLM 혹은 Agent
- 고정된 프롬프트 형식
- LLM의 답변 결과에 대한 문서와의 관련성/신뢰성
즉 위와 같은 모든 구조가 정확하게 이루어져야 제대로된 답변이 나온다는 것이 가장 큰 문제점이다.
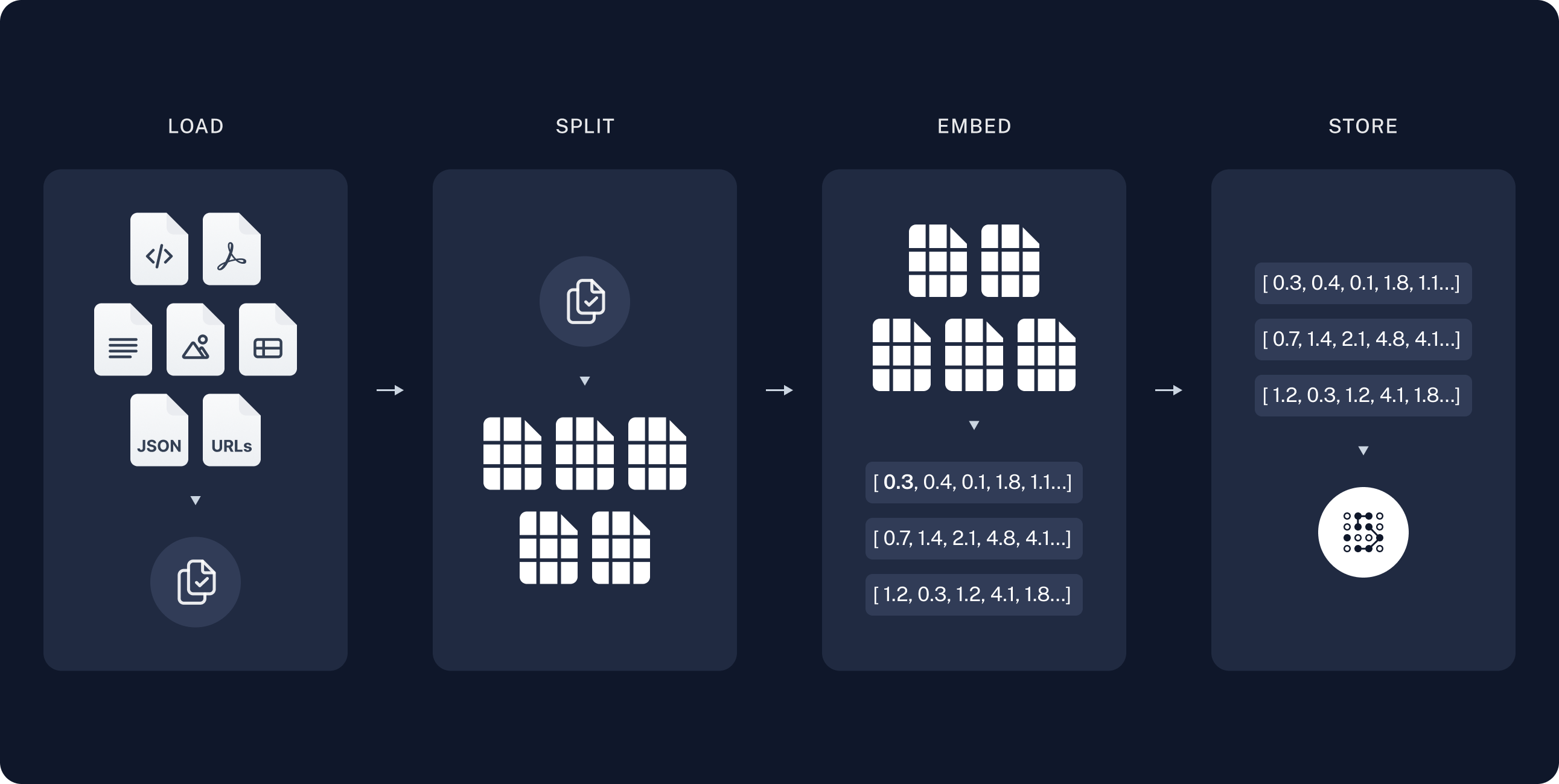
위 이미지와 같이 단방향 구조로 한 번에 잘해내야 좋은 답변을 얻을 수 있다는 것이다.
Conventional RAG의 문제점
: 데이터 로드 -> 답변과 같이 RAG 파이프라인이 단방향 구조
- 따라서 모든 단계를 한 번에 잘해야 함
- 이전 단계로 되돌아가기 어려움
- 이전 과정의 결과물을 수정하기 어려움
여기서 위 문제를 해결하기 위해서 제안된 방법이 바로 LangGraph이다.
LangGraph 제안
- 각 세부과정을 노드(Node)라고 정의
- 이전 노드 -> 다음 노드: 엣지(Edge) 연결
- 조건부 엣지를 통해 분기 처리가 가능
즉 RAG 파이프라인을 보다 유연하게 설계하는 것이 가능함.
예시 노드
: 문서를 올려주는 노드, 문서를 나눠주는 노드, 문서를 임베딩하는 노드, 임베딩 된 문서를 저장하는 노드 등등
그럼 RAG와 LangGraph로 만들었을 때 뭐가 달라지는지 한 번 확인해보자.

위 이미지는 일반적은 RAG의 과정으로 질문부터 답변까지 모두 하나의 방향으로 이루어지는 것을 확인할 수 있다.
이런 경우에 중간에 문서 검색 혹은 내용이 잘못 되어도 멈춰서 이전 단계로 돌아가는 것이 어렵다.
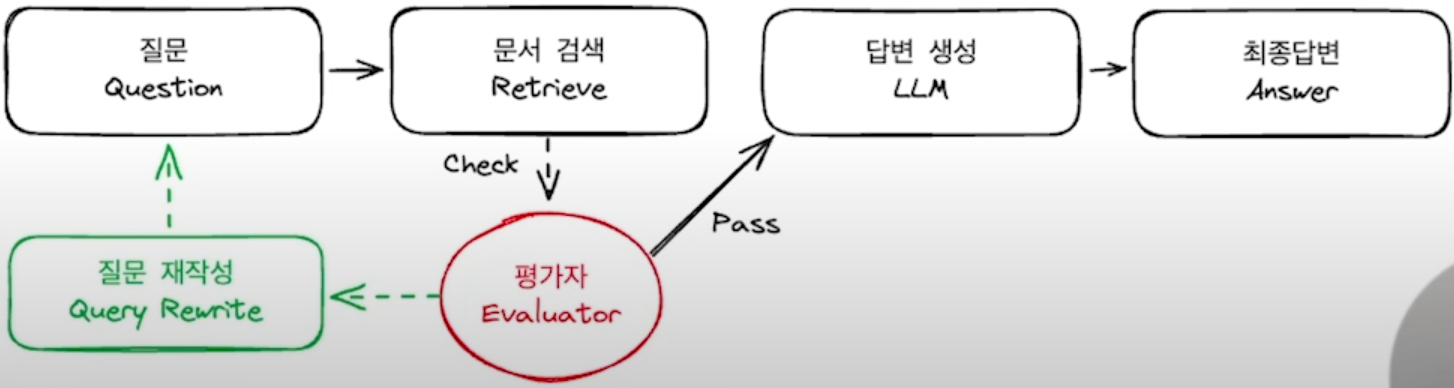
반면 LangGraph의 경우 위와 같이 흐름을 우리가 직접 만들어서 검증하는 것이 가능하다.
예를 들어
- 우리가 질문을 질문 노드에 입력했다.
- 질문 노드 -> 문서 검색 노드
- 문서 검색 노드에서는 전달 받은 질문을 활용해 문서를 검색한다.
- 문서 검색 노드 -> 평가자 노드
- 평가자 노드에서는 문서를 평가해서 적합한 문서인 경우 답변 생성 LLM 노드로 그렇지 않은 경우 질문 재작성 노드로 이동하도록 한다(조건부 엣지)
- 평가자 노드 -> 답변 생성 LLM 노드
- 답변 생성 LLM 노드에서는 전달 받은 문서와 질문을 활용해 답변을 생성하도록 한다.
- 답변 생성 LLM 노드 -> 최종답변 ANSWER 노드
- 최종답변 노드에서는 전달 받은 답변을 사용자에게 전달해준다.
이와 같이 구성하게 되면 우리는 마음대로 원하는 순간에 검증 혹은 데이터를 수정하는 것이 가능해지며, 결국 처음에 말한 Hallucination을 예방할 수 있게 된다.
조금 더 복잡해지면 다음과 같다.
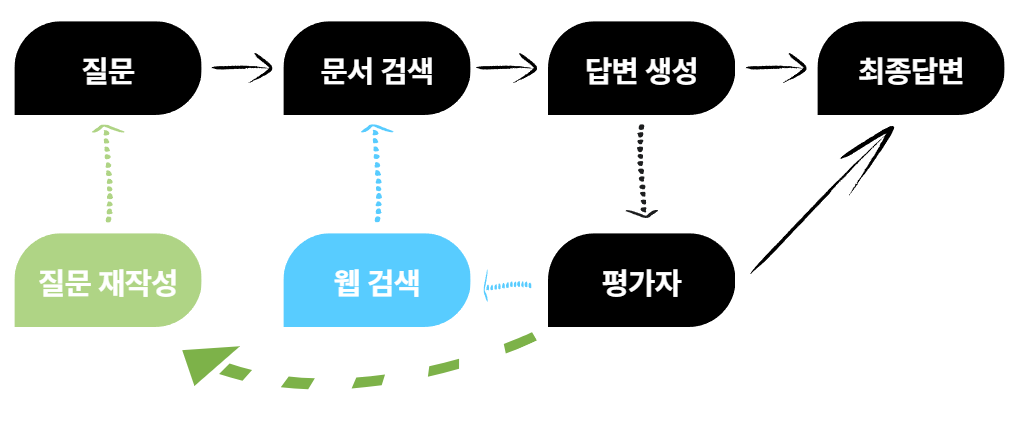
위와 같이 모든 과정을 노드로 구성한 후 이전과는 다르게 생성된 답변을 평가자가 평가한다면
답변의 내용 중 사용자의 질문이 부족한 것인지 혹은 문서 검색이 잘못된 것인지를 파악해 조건부 엣지를 설정하여 부족한 부분으로 돌아가 다시 실행 혹은 추가적인 툴을 호출해 부족한 부분을 채우는 것이 가능해진다.
이렇게 부족한 부분을 수정한 후 최종답변을 생성해 더욱 유연해지고 답변의 퀄리티가 높아지게 된다.
만약 더 퀄리티를 높이고 싶다면 평가자를 1개가 아닌 2개 혹은 3개로 구성하여 단계별로 제대로 실행된 것인지, 부족한 부분은 없는지 판단해 처리하는 것 또한 쉽게 가능하다.
(노드를 함수로 구현해서 단순히 연결만 시켜놓으면 되는거니까!)
이렇게 보면
기존 RAG와
LangGraph의
확실한 차이점을 알 수 있을 것이다.
이전에 말했던 것과 같이 RAG의 경우 우리는 단방향으로 흘러가기 때문에 질문도 잘해야 했고 문서 검색도 한번에 제대로 수행되어야 하고 답변 생성도 우리가 마음에 들게 한번에 잘 생성되어야 했다.
그렇지만 LangGraph의 경우 질문이 잘못되었다면 검사해서 다시 질문을 작성하도록 하거나, 문서 검색 내용이 부족하다고 생각되면 다시 검색 혹은 추가적인 툴(웹 검색)을 활용해 더 보완하는 것이 쉽게 가능하다.
즉 LangGraph의 경우 한번에 잘하지 않아도 계속해서 만들어진 흐름을 돌면서 충분한 정보 검색이 가능하다는 것이다.
LangGraph의 장점
= 랭그래프의 다이나믹한 특성 때문에 우리가 flow 엔지니어링을 통해서 RAG의 파이프라인을 조금 더 정교하게 만들어 낼 수 있다.
LangGraph 용어 정리
- Node(노드), Edge(엣지), State(상태관리)를 통해 LLM을 활용한 워크플로우에 순환(Cycle) 연산 기능을 추가하여 손쉽게 흐름 제어
- RAG 파이프라인의 세부 단계별 흐름제어가 가능
- Conditional Edge: 조건부 엣지(if, elif, else와 같은...) 흐름 제어
- Human-in-the-loop: 필요시 중간 개입하여 다음 단계를 결정
- Checkpointer: 과거 실행 과정에 대한 "수정" & "리플레이" 기능
이때 노드는 함수로 이루어져 있다!
추가로 State의 경우는 간단하게 설명하면 다음과 같다.
우리가 노드들을 하나씩 만들어 줄 것인데 노드의 경우 각각이 독립적인 상태, 간단히 하나의 회사라고 생각하면 된다.
엣지로 연결된 노드들은 서로 협력 관계가 있는 회사들인데, 각각의 회사는 서로가 어떤 데이터를 가지고 있는지 전혀 알지 못한다.
이때 사용되는 것이 바로 State이다.
A 노드와 B 노드가 서로 통신하기 위해서는 바로 State가 활용되고 이때 State는 단순히 메시지 전달자의 역할을 진행하게 된다.
A 회사가 처리한 데이터를 택배에 담아서 B 회사에 보내게 되면 B 회사는 택배를 열어서 B 회사에서 진행해야 하는 일을 처리하고 다시 처리된 데이터를 포장해서 C 회사에 보내게 된다.
이렇게 State는 각 노드들에게 데이터를 전달하고 받기 위한 통신의 역할을 하게 된다.
Human-in-the-loop: 특정 노드에서 사람이 개입 가능
해당 부분은 어떤 특정한 노드에 도착했을 때 필요한 경우 사람이 관여할 수 있도록 허락해주는 기능을 말한다.
예를 들어
:조건부 노드에 Human-in-the-loop 기능을 넣게 되면은 추가 정보가 필요한지 아닌지에 대해서 사람이 입력으로 추가 정보를 넣도록 할 수 있다.따라서 중간에 사람이 관여하여 필요한지 아닌지, 혹은 데이터를 추가할지 버릴지를 선택 가능하게 된다.
Checkpointer: 과거 실행 과정에 대한 수정 혹은 리플레이 기능
해당 부분은 과거 실행 과정에 일어났던 내용들을 저장해주는 역할을 한다.
이 Checkpointer 덕분에 우리는 과거에 했던 대화 내용들을 기억하고, 이를 기반으로 'multi turn'이 가능해진다.
또한 이전에 있었던 결과에 대한 '수정', 이전에 실행했던 노드로 돌아가서 다시 해당 노드부터 실행하는 '리플레이' 기능도 가능하다.
멀티턴이란?
사람이랑 챗봇이 여러 번 주고받는 대화를 말한다.
예를 들어, 질문을 하면 챗봇이 다시 물어보고, 또 그에 대답하면 챗봇이 다시 답해주는 식으로 여러 차례 이어지는 대화 방식이다.
한 번 말하고 끝나는 건 싱글턴,
계속 주고받는 건 멀티턴이라고 말한다.
이번 글에서는 간단히 LangGraph가 왜 나왔는지, RAG의 어느 부분을 보완해주는지에 대해 알아보았다.
그럼 다음 글에서는 위에서 언급한 노드, 엣지, 상태에 대해서 자세하게 알아보자.
