- 제목: Multi-Agent Collaboration via Evolving Orchestration
- 저자: Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, Xuantang Xiong, Lei Han, Zhiyuan Liu, Maosong Sun
- 소속 기관: 중국의 대학 및 연구기관 (예: Tsinghua University, Shanghai Jiao Tong University 등)
- 학회: NeurIPS 2025 accept
출처: Dang, Yufan, et al. "Multi-Agent Collaboration via Evolving Orchestration." arXiv preprint arXiv:2505.19591 (2025).
1. abstract
최근 연구에서 LLM 간의 멀티 에이전트 협업을 탐구하는 연구가 많이 늘어나고 있다.
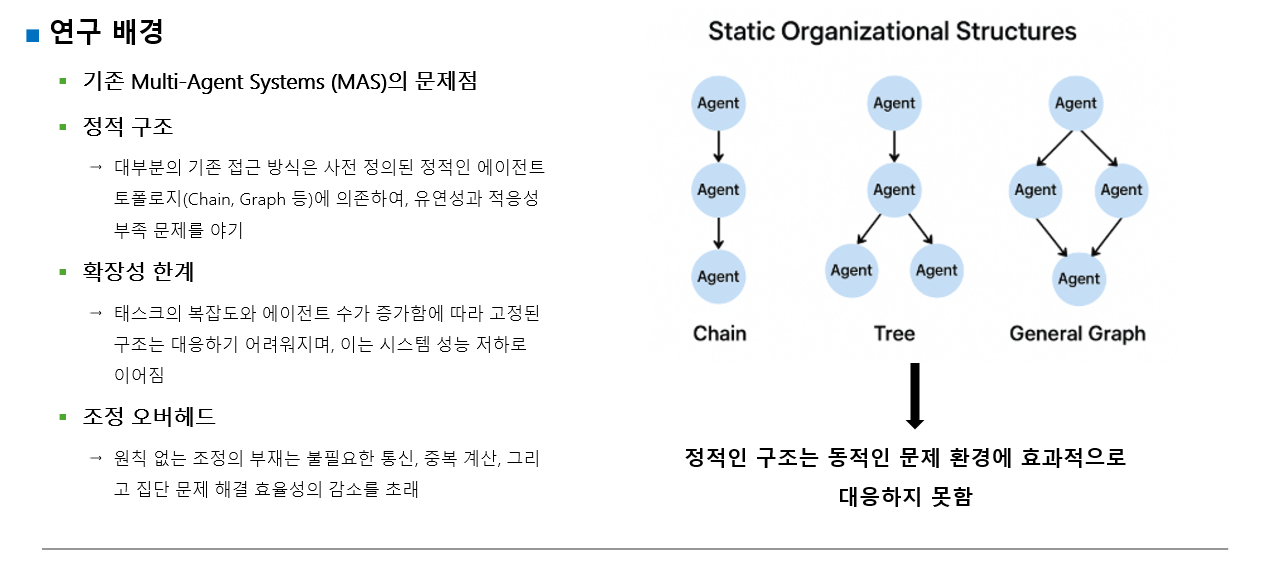
하지만 대부분의 접근 방식은 태스크 복잡성과 에이전트 수가 증가함에 따라 적응하는 데 어려움을 겪는 정적 조직 구조에 의존하여 조정 오버헤드와 비효율성을 초래한다.
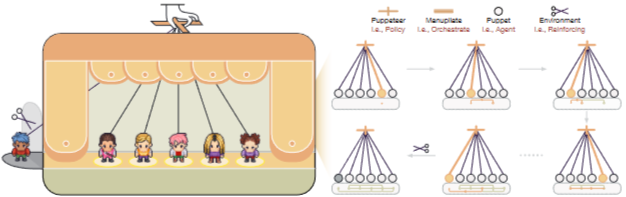
이를 위해 제안하는 연구에서는 LLM 기반 멀티 에이전트 협업을 위한 퍼펫티어(puppeteer) 스타일 패러다임을 제안한다.
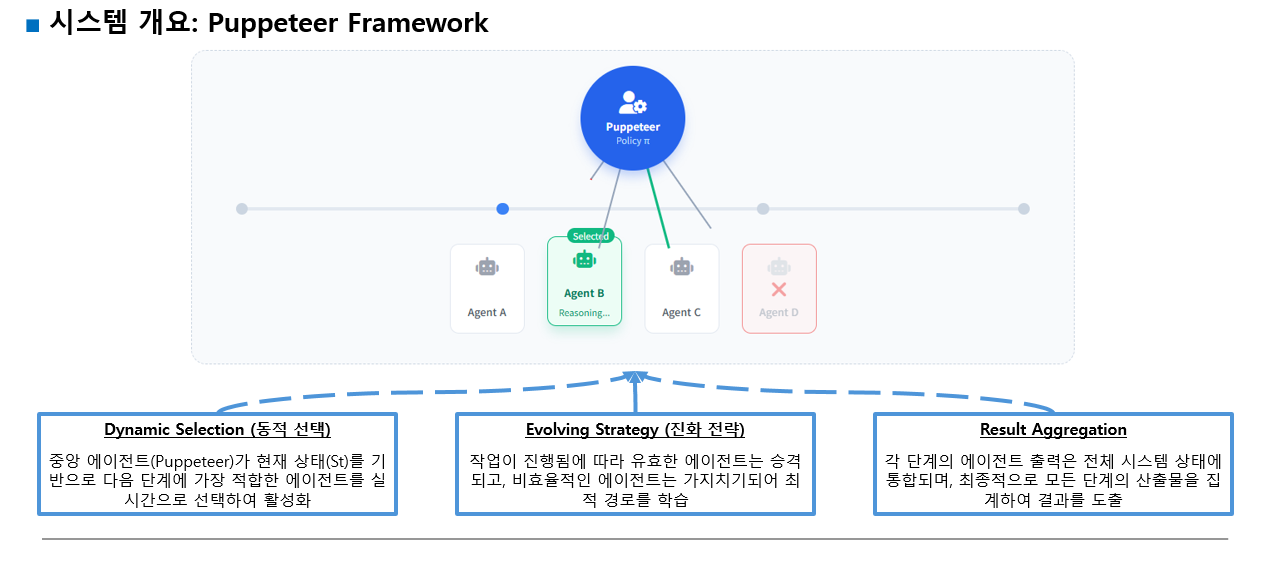
이 패러다임에서는 중앙 집중식 오케스트레이터("퍼펫티어")가 진화하는 태스크 상태에 대응하여 에이전트("퍼펫")를 동적으로 지시한다.
이 오케스트레이터는 강화 학습을 통해 훈련되어 에이전트를 적응적으로 순서화하고 우선순위를 지정함으로써 유연하고 진화 가능한 집단적 추론을 가능하게 한다.
폐쇄형 및 개방형 도메인 시나리오에 대한 실험은 이 방법이 계산 비용을 줄이면서도 우수한 성능을 달성함을 보여준다. 분석 결과, 핵심 개선 사항은 오케스트레이터의 진화 하에서 보다 간결하고 순환적인 추론 구조의 출현에서 일관되게 비롯됨을 추가로 밝혔다.
깃허브 코드: https://github.com/OpenBMB/ChatDev/tree/puppeteer
2. introduction
최근 대규모 언어모델(LLM)은 계획, 추론, 의사결정 등 다양한 영역에서 뛰어난 성능을 보여주고 있다. 하지만 복잡한 문제 해결, 툴 사용, 다중 에이전트 협업 등 점점 더 어려운 과제를 다루면서 단일 LLM의 한계가 명확해지고 있다.
이를 해결하기 위해 연구자들은 전문성을 가진 여러 LLM 에이전트가 협업하는 Multi-Agent System(MAS)을 탐구하고 있으나, 기존 접근법의 대부분은 정적인 에이전트 구조에 의존한다.
문제:
즉 기존 MAS 연구 대부분은 에이전트 A -> B -> C 순서로 협업을 진행하는 고정된 구조를 사용하기 때문에 어떤 문제든, 어떤 입력이 들어오든, 어느 에이전트가 잘하는지와 상관없이 늘 같은 방식으로 협업해야 한다.
즉
- 고정된 구조는 유연성이 부족함
- 에이전트 수가 늘수록 조정 비용 증가, 중복 계산 발생, 성능 저하
- 변화하는 과제에 맞춰 에이전트 협업 방식을 최적화하지 못함
따라서 해당 제안하는 연구에서는 '퍼펫티어' 기반 동적 오케스트레이션을 제안하고자 한다.
논문에서는 인형극(Puppet show)에서 영감을 얻어, 여러 에이전트를 조율하는 중앙 오케스트레이터가 상황에 맞게 어떤 에이전트를 언제 사용할지 동적으로 결정하는 새로운 프레임워크를 제안한다.
기존 방식의 한계점
- 기존 방식
기존 다중 에이전트 시스템에서 에이전트들이 협업하는 방식(협업 토폴로지)은 가능한 경우의 수가 너무 많아(combinatorially large space) 모두 탐색하는 것이 사실상 불가능하다.
이러한 문제 때문에 기존연구들은 주로 미리 정의된 단순한 구조(예: 사슬형, 트리형 그래프 등)에 초점을 맞추었다.
즉 기존 방법은 에이전트 A가 에이전트 B에게 결과를 주고, 에이전트 B는 에이전트 C에게 주는 '사슬 구조', 또는 에이전트 A가 여러 에이전트 B, C, D에게 작업을 분배하고, 이들이 다시 A에게 결과를 돌려주는 '트리 구조', 혹은 에이전트들 간의 복잡한 연결이 미리 설계된 '일반 그래프' 구조 등이 있었다.
이러한 미리 정의된 복잡한 그래프 구조는 태스크의 복잡성이 커지거나 에이전트의 수가 늘어날수록, 미리 모든 상호작용 경로와 종속성을 설계하는 것이 거의 불가능하다.
- 제안하는 직렬화된 오케스트레이션
이 논문에서는 복잡한 토폴로지 공간 전체를 탐색하는 대신, 협업 추론 과정을 '직렬화'하는 방법을 제안한다.
이는 중앙 오케스트레이터('puppeteer')가 에이전트 간의 상호작용 그래프를 하나의 '추론 시퀀스'(reasoning sequence')로 '펼치는(unfolds)' 방식이다.
이 시퀀스는 토폴로지 순회 전략(topological traversal strategy)에 따라 진행되며, 에이전트 활성화의 부분 순서를 따르도록 한다. 즉, 문제 해결을 위해 에이전트들이 수행해야 하는 순서와 종속성을 유지하면서 순차적으로 에이전트를 선택한다.
이와 같이 기존 방식의 문제점을 해결하기 위해서 해당 논문에서는 "에이전트들이 서로 어떻게 연결될지 미리 복잡한 그래프 구조를 정의하려고" 하지 않았다.
대신 에이전트들이 협력하여 문제를 해결하는 과정 자체를 매 순간 "무엇을 할 것인지"를 결정하는 순차적인 문제로 재정의한다.
여기서 무엇을 할 것인가는 "다음으로 어떤 에이전트를 활성화할 것인가"를 의미한다.
직렬화된 오케스트레이션의 역할:
이러한 접근 방식을 "직렬화된 오케스트레이션"이라고 부른다.
직렬화는 복잡한 것을 시간의 흐름에 따라 하나의 순서로 나열한다는 의미이다.
오케스트레이터는 복잡한 '협업 그래프' 전체를 미리 만들려고 하는 대신, 그 그래프를 '추론 시퀀스'로 '펼쳐'나간다.
즉, 지금 이 시점에서 가장 적합한 에이전트를 하나 선택하고, 그 에이전트의 작업이 끝나면 다음 순간에 또 가장 적절한 에이전트를 선택하는 과정을 반복한다.
이때 중요한 것은 "토폴로지 순회 전략"에 따라 추론 시퀀스를 유도한다는 것이다.
이는 단순히 아무 에이전트나 고르는 것이 아니라, 문제 해결의 논리적인 흐름과 종속성(부분 순서)을 따르면서 에이전트를 선택한다는 것이다.
예를 들어 '설계' 에이전트가 먼저 실행되어야 '코딩' 에이전트가 의미 있는 작업을 할 수 있다는 식의 순서를 고려하는 것이다.
에이전트 토폴로지(Agent Topology)란?
여러 에이전트들이 어떤 구조(형태)로 연결되어 협업하는지 나타내는 그래프 구조 전체를 의미
동적 그래프 형성의 의미(보이지 않는 구조)
그럼 이렇게 매 순간마다 선택된 에이전트로 만들어진 결과를 돌아보게 되면, 매 스텝마다 에이전트를 순차적으로 선택하고 실행하는 과정이 겉으로는 '직렬화된' 것처럼 보인다.
하지만 이 모든 스텝들이 완료된 후, 어떤 에이전트가 어떤 에이전트 다음에 실행되었는지, 누가 누구의 결과에 영향을 받았는지 등을 추척하여 기록하면, 최종적으로 에이전트들 간의 복잡한 '방향성 그래프' 구조가 자연스럽게 형성된다.
이것을 재 구성하면 방향성 그래프로 다시 만들어질 수 있다고 논문에서는 말하고 있다.
즉 명시적으로 설계하지 않았지만, 동적 step-by-step 결정의 결과로 에이전트들 간의 효과적인 협업 구조(그래프)가 암묵적으로 만들어진다는 것이다.
그럼....
이런 동적 그래프를 가지고 뭘 할 수 있을까??
논문에서는 이러한 동적 그래프를 활용해
어떤 에이전트가 자주 호출이 되는지, 또 호출이 되는데 문제 해결에 기여를 정확하게 잘 하는지, 잘못된 패턴으로 반복 호출되어 비효율적인 부분이 없는지, 실제로 에이전트들이 어떤 순서로 누구와 데이터를 주고 받았으며, 어떤 정보가 어디로 흘러갔는지를 확인할 수 있게 된다.
또한 가장 중요한 부분은 동적 그래프를 활용한 오케스트레이터의 학습 및 개선이다.
논문에서는 오케스트레이터를 강화학습을 통해 훈련한다고 명시하고 있다.

조금 더 간단하게 설명을 하자면...
해당 논문에서 말하고자 하는 것은
기존 다중 에이전트 구조에서 복잡한 요청이 들어왔을 때 어떤 에이전트를 뽑고 선택된 에이전트들의 순서를 모두 고려해서 가장 효율이 좋은 모든 과정을 진행하는 것은 어려우니...
하나의 메인 에이전트(중앙 오케스트레이터, 'puppeteer')를 뽑아서 step-by-step 형식으로 요청에 맞춰 첫 번째로 진행될 에이전트를 뽑고, 해당 에이전트가 종료된 뒤 다시 메인 에이전트가 다시 다음 에이전트를 뽑아서 진행하는 형식으로 가보고자 한다는 것이다.
이때 매 스템마다 오케스트레이터(메인 에이전트)는 "현재 전역 시스템 상태(St)와 작업 명세(t)에 따라 하나의 에이전트(at)를 선택하게 된다.
즉 사용자의 요청이 들어왔을 때 오케스트레이터가 미리 전체 작업 경로를 한 번에 다 계획하는 것이 아니라, 현재까지 진행된 상황을 보고 '가장 다음으로 필요한 에이전트'를 실시간으로 결정하는 방식임을 말한다.
핵심 아이디어 2가지
1. Dynamic Orchestration - 동적 라우팅
- 스텝마다 어떤 에이전트를 활성화할지 오케스트레이터가 선택
- 문제 해결 과정을 순차적 의사결정 문제로 모델링
- 필요할 때만 특정 에이전트를 쓰고, 불필요한 계산을 건너뛸 수 있음
- 결과적으로 암시적이고 유연한 협업 그래프가 생성됨
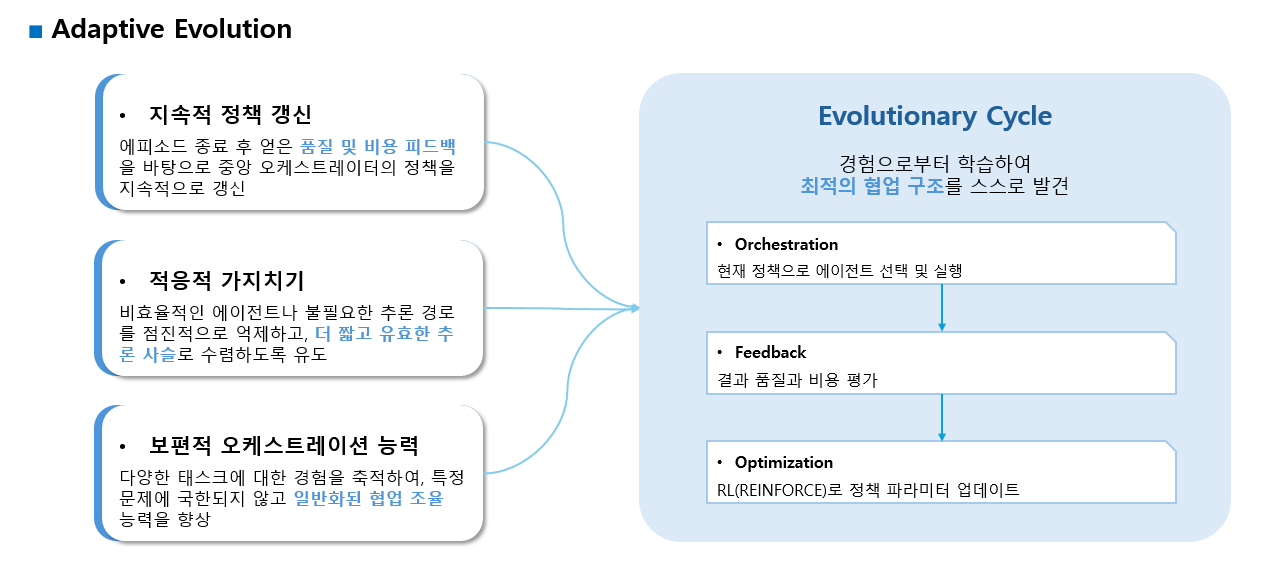
2. Adaptive Evolution - 적응적 진화 (강화학습 RL 기반 최적화)
- 작업이 끝난 후 얻은 피드백을 활용해 강화학습으로 오케스트레이터 정책 업데이트
- 잘하는 에이전트는 더 자주 사용되고, 비효율적인 에이전트는 자연스럽게 제외됨
- 시간이 지날수록 더 효율적이고 컴팩트한 협업 구조가 진화
- 효율성을 극대화하고 중복을 최소화하기 위해, 완료된 작업의 피드백을 활용하여 오케스트레이션의 정책을 지속적으로 강화학습을 통해 업데이트
3. Method
즉 중앙 집중식 정책을 사용하여 다중 에이전트의 협업을 동적으로 오케스트레이션하고 강화 학습을 통해 협업 프로세스를 지속적으로 최적화함으로써 다양한 LLM 기반 에이전트를 구성하는 통합 프레임워크를 제안함.
기본 개념들 - 에이전트와 MAS의 수학적 표기
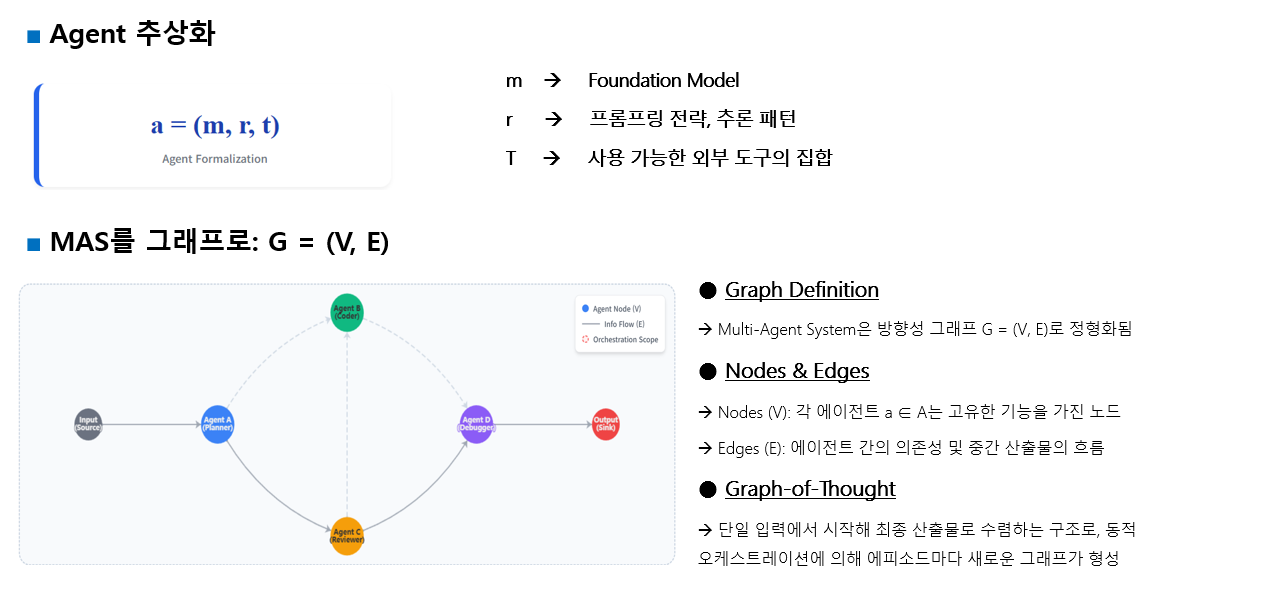
에이전트(atomic unit): 논문은 LLM 기반 에이전트를 최소 구성으로
a = (m, r, t) 로 추상화한다.
- m = foundation model (예: LLaMA, GPT 등)
- r = reasoning pattern / prompting strategy (예: reflect, critic, planning)
- t = 사용 가능한 외부 도구(tool) 집합 (웹검색, 코드 실행기 등).
즉, 가능한 모든 조합이 에이전트 공간 A = {(m,r,t)} 을 이룬다.
간단히
A는 사용 가능한 에이전트들의 전체 목록(카탈로그)를 의미하고
MAS는 에이전트들이 실제로 협엽하는 시스템을 말한다.
MAS(멀티에이전트 시스템) 그래프 표기:
MAS는 방향 그래프 G=(V,E) 로 모델링된다. 각 노드 v ∈ V는 에이전트 a ∈ A를 의미하고, 간선 (vi, vj)는 정보 흐름(의존성)을 뜻한다.
보통 단일 입력(source) → 단일 출력(sink) 구조를 고려하며. 논문은 이 구성을 “graph-of-thought”와 유사하다고 본다.
(입력 -> agent 1 -> agent 2 -> agent 3 -> 최종답)
간단히 말하면 MAS는 단순히 에이전트들의 모음이 아니라 어떤 에이전트가 어떤 에이전트에게 정보를 넘기고, 어떤 순서로 어떤 협업을 하는지를 표현하는 시스템이다.
그래서 MAS를 방향 그래프인 G = (V, E)로 모델링한다.
- V: 노드 집합(에이전트들)
- v_i라는 노드는 A 안의 특정 agent a_i와 1:1 대응
- E: 방향 간선(정보의 흐름)
- v_i -> v_j = 에이전트 i의 출력이 에이전트 j에게 입력으로 전달됨
graph of thought란?
기존 LLM의 생각 과정인 thought process를
단순한 선형 CoT(chain of thought)가 아니라
그래프 형태의 구조적 추론(reasoning)으로 표현하자는 철학즉 멀티에이전트 협업을 상호작용하는 '그래프 형태의 사고 과정'으로 본 것
3-1 동적 오케스트레이션
- 문제 인식:
이전의 분산/자율적 에이전트 선택 방식은 에이전트 수/다양성 증가 시 조정 오버헤드가 커지고 확장성 문제가 발생한다.
- 해결 방안:
중앙 오케스트레이터(puppeteer)가 존재하여 매 스텝마다 어떤 에이전트를 활성화할지 동적으로 선택하고, 해당 에이전트에게 추론 작업을 위임한다.
이렇게 하면 에이전트 내부 동작과 선택을 분리하여 유연성과 적응성을 높일 수 있다.
- 장점:
- 에이전트들이 서로 누구랑 일할 것인지 협상하는 대신 중앙에서 결정을 내리기 때문에 통신, 조정 비용 감소
- 새로운 에이전트를 추가, 제거하여도 오케스트레이터 정책만 재학습하면 됨
3-2 직렬화된 전개 (Serialized Orchestration)
- 문제:
가능한 그래프 토폴로지(에이전트 연결 구조)는 조합적으로 폭발 -> 전수 탑색 불가.
- 해법:
협업을 하나의 순차적 reasoning seqence로 "펼쳐(unfold)" 실행함.
즉, 그래프 전체를 미리 설계해서 탐색하지 않고, 매 스텝 오케스트레이터가 다음 에이전트만 골라 직렬로 실행해 나아감.
이 직렬 로그(시퀀스)는 나중에 folding하면 그래프로 재구성할 수 있다.
- 직렬화의 의의
- 그래프 탐색을 순차적 의사결정(MDP)으로 바꿔 탐색 복잡도를 현실적으로 낮춤
- 여전히 복잡한 그래프(분기, 사이클)를 표현 가능 - 실행 관점에서도 단순한 시퀀스
3-3 형식화: 오케스트레이션을 MDP(Sequential Decision Process)로
MDP란?
MDP는 (상태, 행동, 보상)을 기반으로 한 순차적 의사 결정 모델로
- 상태 St: 지금까지의 정보(중간 답 + 문맥)
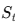
- 행동 at: 어떤 에이전트를 호출할지 선택
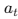
- 보상 Rt: 최종 결과 품질 / 비용 기반 보상
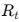
- 전이
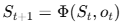
즉, "어떤 순서로 어떤 에이전트를 호출하면 가장 좋은 답과 효율을 얻을까?"를 MDP로 표현한 것이다.
행동 선택 수식(정식 표현)
오케스트레이터는 정책 π는 다음과 같이 정의된다.
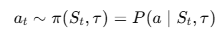
여기서 각 변수는 다음과 같다.

π는 오케스트레이터의 정책을 의미하며, 이 정책은 현재 상태와 작업 사양에 따라 어떤 에이전트를 선택할지에 대한 규칙이고 본 논문에서는 이 정책을 강화 학습을 통해 학습시키도록 한다.

선택된 에이전트의 출력과 상태 업데이트
선택된 에이전트 at는 다음을 수행:
- 입력을 받아 reasoning 수행
- 출력 ot 생성
수식은 다음과 같다.
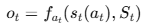
그 후 전체 시스템 상태가 업데이트 된다.
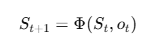
여기서

즉, A가 말하고 B가 말하고 C가 말한 내용이 전부 S에 누적되는 것이다.
Markov property(중요!)
오케스트레이터는 다음 스텝 행동을 고를 때 과저 전체 히스토리를 묻지 않는다. 오직 지금 상태 St만 보면 충분하다.
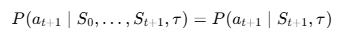
즉, 지금까지 모든 에이전트들이 생성한 정보가 S에 들어있으므로, 과거를 별도로 기억할 필요 없다는 것이다.
이후 T 스텝에 도달하거나 종료 에이전트가 선택되면 끝나게 된다.
최종 출력은 모든 출력 O0 ~ OT를 집계해 만든다.
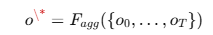
따라서 해당 오케스트레이션을 MDP 표현한 부분의 핵심은 다음과 같다.
핵심 정리
- MAS 협업을 "스텝마다 어떤 에이전트를 부를지 결정하는 문제"로 봄
- 이것을 MDP로 모델링
- 상태 S_t: 지금까지의 reasoning 결과
- 행동 a_t: 다음 실행 에이전트
- 전이: S_{t+1} = S_t에 현재 출력 추가
- 종료 후 모든 결과 집계
3-4 Adaptive Evolution: 정책 학습과 구조 진화
이 파트는 RL(강화학습)로 오케스트레이터를 계속 학습하는 과정을 말한다.
핵심 개념:
오케스트레이터 π가 처음에는 무작위에 가까운데, 여러 에피소드를 수행하면서 좋은 에이전트 선택을 강화하고 나쁜 선택은 약화시키면서 스스로 더 효율적인 협업 구조로 진화하도록 한다.
강화 학습을 사용하는 이유는 다음과 같다.
- 에이전트를 어떤 순서로 호출해야 결과가 좋아지는지 정답이 없음
- 평가(보상)는 전체 에피소드 후에만 알 수 있음
- 각 행동의 효과는 delayed reward 구조임
- 목표는 "정답률 + 계산 효율 모두 최적화"
--> 이는 전형적인 RL 문제이다.
따라서 해당 연구에서는 강화 학습을 활용해 오케스트레이터를 계속 학습하고자 하였다.
REINFORCE 사용 (정책 경사법)
REINFORCE
REINFORCE는 몬테카를로(Monte-Carlo) 방식으로 전체 에피소드를 보고 난 후에 정책을 업데이트한다. 정책 πθ(a|s)를 파라미터 θ로 표현하고, 기대되는 총 보상 J(θ) 를 최대화하도록 θ를 조정한다.
간단히
좋은 리턴을 얻은 행동의 확률을 높이고, 나쁜 리턴을 얻은 행동의 확률은 낮춘다는 의미이다.
정책 θ(오케스트레이터 파라미터)는 아래를 최대화한다.
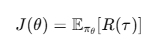
정책 경사 근사:
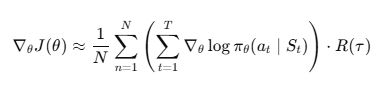
업데이트:
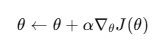
--> 성공적인 선택일수록 log π(a_t | S_t)의 기울기가 +(플러스) 방향으로 업데이트 된다.
즉,
- 올바른 에이전트 선택은 더 자주 일어나고
- 불필요한 에이전트 선택은 덜 발생하게 된다.
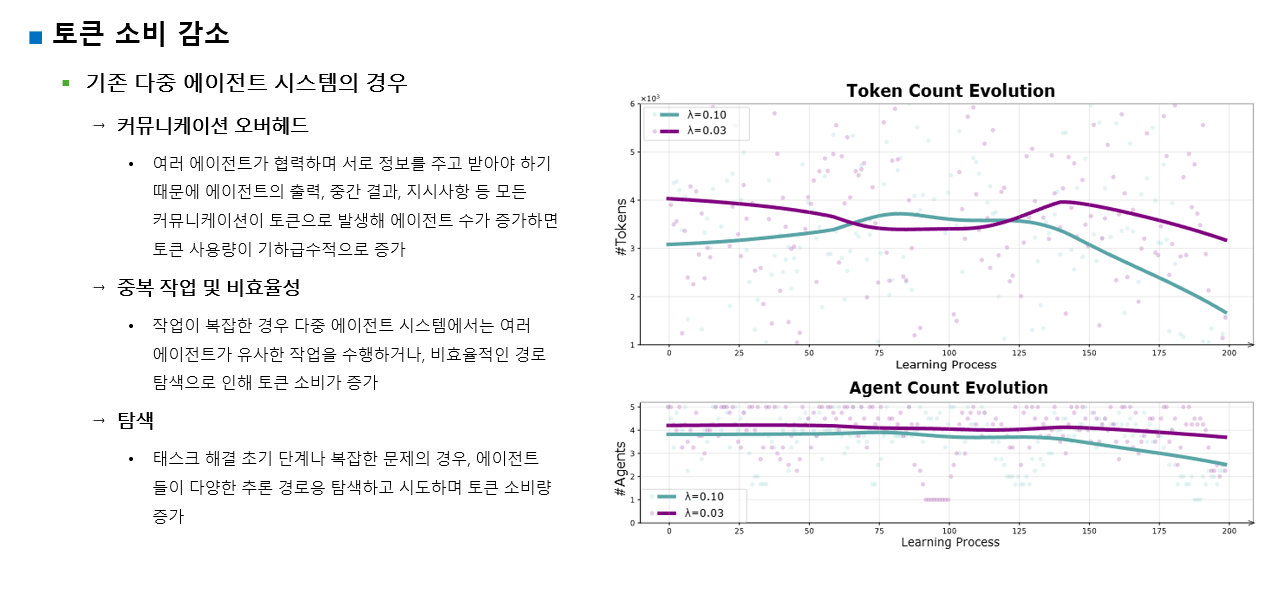
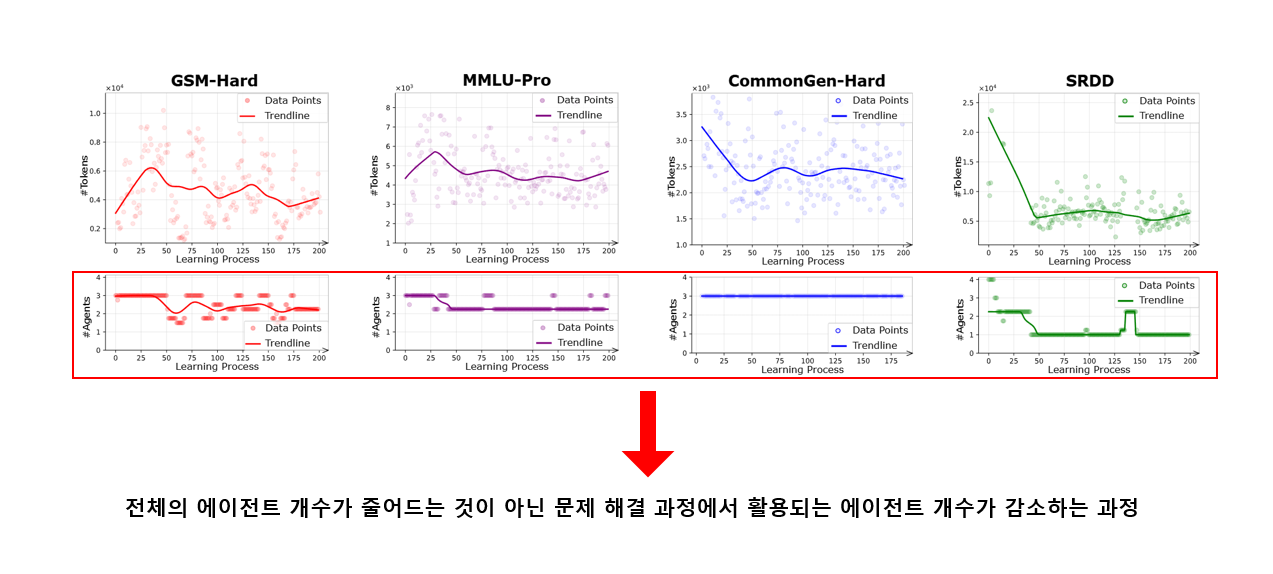
결론적으로 시간이 지남에 따라 구조적 진화(Topology Evolution)가 발생하게 된다.
학습이 진행될수록:
- 쓸데없는 에이전트는 거의 선택되지 않음(프루닝)
- 특정 reasoning 패턴들이 반복 활성화됨(Cyclic)
- 불필요하게 깊은 경로는 사라짐(compaction)
- 적은 수의 핵심 에이전트 중심으로 협업 구조가 재구성됨
즉, 오케스트레이터가
불필요한 경로를 줄이고 효율적인 reasoning chain을 스스로 만들어내도록 하는 것이다.
따라서 해당 Adaptive Evolution 부분의 핵심은 다음과 같다.
핵심 정리
- 오케스트레이터는 REINFORCE로 학습
- 전체 trajectory 보상을 보고 더 나은 에이전트 선택 정책을 학습
- 점차 더 "짧고 효율적이고 정확한" 에이전트 구조로 진화
- 에이전트 자동 pruning + compact 토폴로지 형성
3-5 Reward Design - 보상 설계
게이트키퍼: 최종 보상 r
문제의 답이 정확하면:
- closed task: r ∈ {0,1}
- open task: r ∈ [0,1] (quality score)
전체 보상 정의
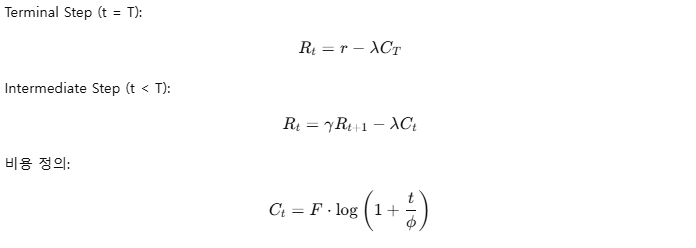
각 요소의 의미 쉽게 해석
λ (lambda): 정확도 vs 효율성 조절
- λ가 크면 → 비용 패널티가 커짐 → 효율성(토큰 절약) 중요
- λ가 작으면 → 정확도 우선
γ (gamma): discount factor
- 미래 보상을 얼마나 중요하게 볼지
- 일반적으로 0.9~1 사용
- γ=1이면 미래 보상도 동일 비중
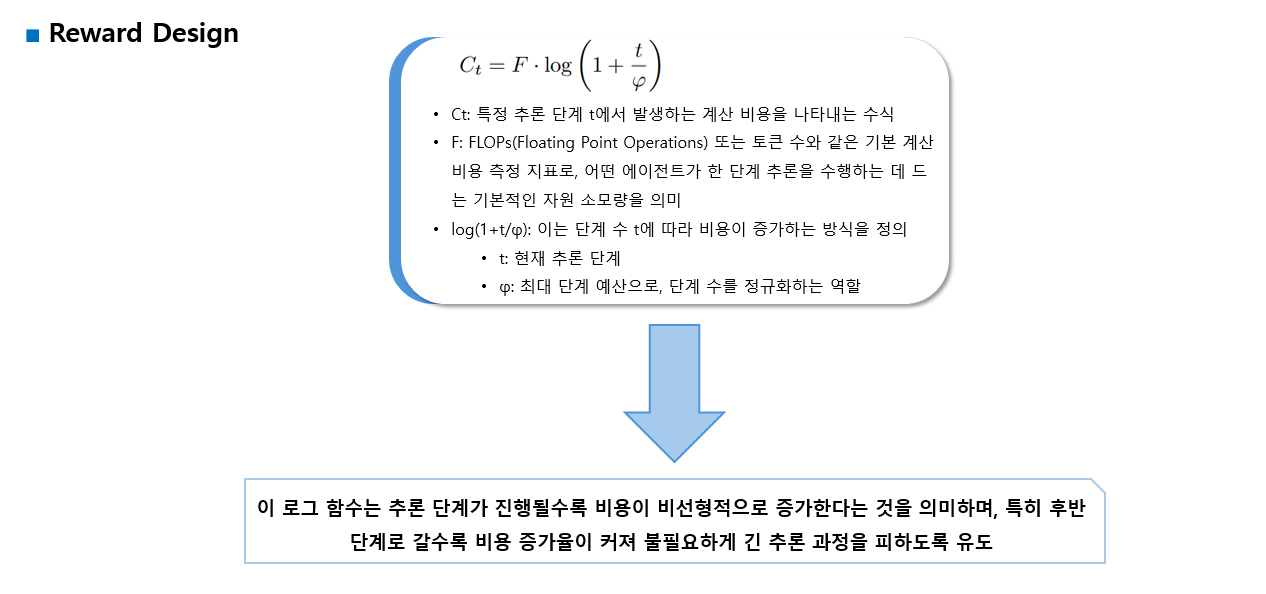
Ct (step cost): 왜 log??
이유:
- 초반에는 비용이 낮게 시작하고
- 스텝이 늘어날수록 증가
- 하지만 기하급수적 증가를 막고 완만하게 증가시키기 위해 log 형태를 사용
즉,
"한두 스텝 더 쓰는 건 괜찮지만, 너무 길어지면 페널티 급증"
"불필요한 장기 reasoning 억제"
Reward는 결국 어떤 행동을 유도하나?
오케스트레이터는 학습을 통해:
- 정답에 크게 기여하는 에이전트 → 많이 선택
- 기여 적거나 비용 큰 에이전트 → 거의 선택하지 않음
- 반복적으로 도움 되는 chain → 안정적으로 재사용
- reasoning depth → 불필요하게 길어지지 않게 억제
즉, 보상이라는 것을 통해(강화학습)
정확성과 비용을 동시에 극대화하는 reasoning 구조를 스스로 학습한다.
따라서 해당 Reward Design - 보상 설계 부분의 핵심은 다음과 같다.
핵심 정리
- 최종 정답 기반 r에서 비용(C_t · λ)을 뺀 값이 보상
- log 비용을 넣어 긴 reasoning 길이에 페널티
- RL은 이 보상을 기반으로 에이전트 선택 정책을 튜닝
- 결과적으로 “짧고 정확한” 구조로 진화
3-3 ~ 3-5 주제 정리
- MAS 협업은 "스템마다 어느 에이전트를 부를지" 의사결정 문제 → MDP로 모델링
- 상태 St는 지금까지의 reasoning 컨텍스트, 행동은 에이전트 선택
- REINFORCE로 오케스트레이터 정책 학습 → 잘한 선택은 강화
- 그 결과 불필요한 경로는 사라지고 compact, cyclic 구조로 진화함
- Reward는 "정답 품질 - 비용 페널티" 구조 → 효율성과 정확성 모두 최적화