논문 출처 : https://arxiv.org/html/2408.14717v1
위 논문은 데이터베이스와 AI 언어 모델을 결합해 자연어 질문에 답하는 새로운 접근 방식을 제시하는 연구이다.
기존의 Text2SQL이나 RAG와 같은 방법들이 가진 한계를 해결하기 위해 TAG(Table-Augmented Generation)라는 새로운 모델을 도입했고, 이를 통해 더욱 복잡하고 유연한 질문에도 답할 수 있도록 한 것이다.
이 논문에서 말하는 주요 내용과 그 과정들을 자세히 확인해보자.
1. 기존 방식의 한계
AI와 데이터베이스를 결합하는 데 가장 많이 쓰이는 2가지 방법이 있다.
바로 Text2SQL과 RAG이다.
Text2SQL과 RAG에 대해서 간단히 살펴보자.
Text2SQL
Text2SQL은 사용자의 자연어 질문을 SQL 쿼리로 변환해주는 방식이다.
예를 들어
사용자 질문 : 어떤 영화가 가장 높은 평점을 받았나요?
AI : SELECT movie_title
FROM movies
WHERE rating =
(
SELECT MAX(rating)
FROM movies
);위와 같이 사용자의 자연어 질문을 AI가 SQL 쿼리로 변환해준다.
그리고 변환된 SQL 쿼리는 데이터베이스에서 실행되어, 데이터베이스에 저장된 데이터를 바탕으로 결과를 반환해준다.
이렇게 보면 Text2SQL만 사용하여 모든 것을 처리할 수 있을 것 같지만 Text2SQL에는 한계가 존재한다.
바로 복잡한 추론을 요구하는 질문에는 약하다는 것이다.
예를 들어
"왜 이번 분기에 매출이 감소했나요?" 라는 질문은 단순한 데이터 조회 이상의 해석이 필요하기 때문에 이런 질문을 SQL로 표현하는 것은 거의 불가능하다.
게다가 Text2SQL은 데이터베이스에 저장된 정보만을 바탕으로 답변을 제공하기 때문에, 데이터베이스에 없는 정보(예 : 최신 뉴스, 외부 지식)를 처리하지 못한다는 한계도 정확히 보여준다.
RAG
RAG는 텍스트 생성 모델에 데이터베이스에서 가져온 정보를 추가하여 답변을 생성하는 방식이다.
이 방식은 AI 언어 모델이 데이터베이스의 데이터를 바탕으로 답변을 생성하는 데 도움을 준다.
RAG의 경우 자언여 질문을 받으면 먼저 데이터베이스에서 관련 데이터를 검색한다.
예를 들어
사용자 질문 : 어떤 고객 리뷰가 긍정적인가요?
RAG :
1. 데이터베이스에서 리뷰와 관련된 데이터를 검색
2. 검색된 데이터를 언어 모델에게 전달
언어 모델 : AI 언어 모델이 해당 데이터를 이해, 분석한 뒤 자연어로 답변을 생성하지만 RAG에도 단순한 검색 기반의 데이터 처리라는 한계가 존재한다.
RAG도 주로 데이터를 검색하고 그 데이터를 바탕으로 답변을 생성하기 때문에, 복잡한 계산이나 논리적 추론이 필요한 경우에는 성능이 떨어지게 된다.
예를 들어
"가장 인기 있는 제품의 리뷰를 모두 분석해서 요약해줘" 같은 질문은 데이터베이스에서 관련 리뷰를 검색한 후 복잡한 분석을 해야 하지만 RAG는 단순한 데이터 조회와 요약에 한정되어 있어 정확한 분석을 보장하기 어렵다.
TAG
TAG 모델은 위 두 방식의 한계를 보완하기 위한 방식으로 언어 모델과 데이터베이스의 강점을 결합한 시스템이다.
TAG 시스템은 Text2SQL처럼 데이터베이스에서 필요한 정보를 가져오고, RAG처럼 그 데이터를 분석해 답변을 생성한다.
아래에서 조금 더 정확히 이야기 해보자,
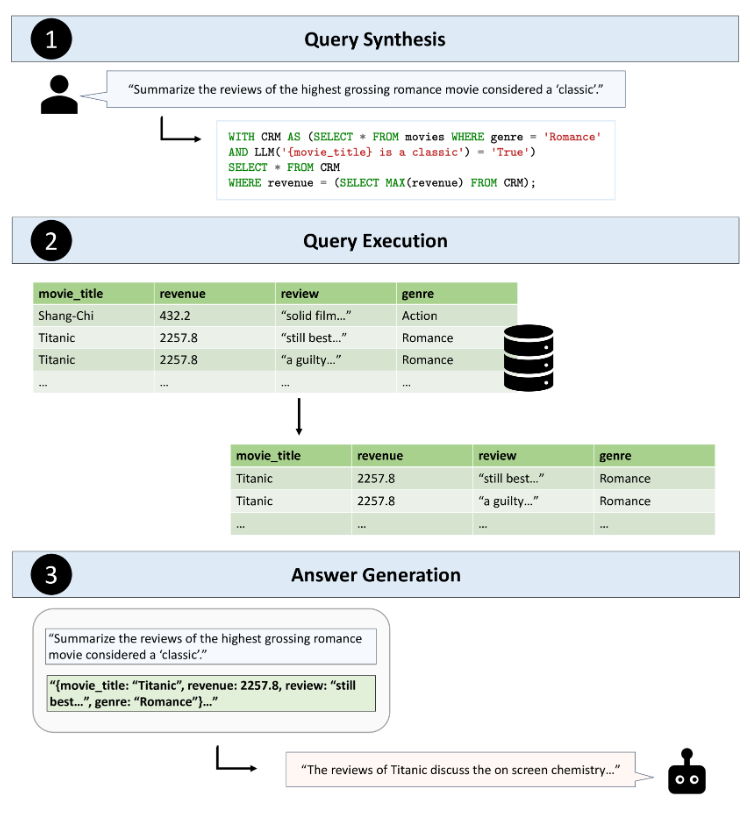
TAG는 크게 세 단계로 나뉘어진다.
1. 쿼리 생성
사용자의 자연어 질문을 데이터베이스 쿼리로 변환하는 단계
기존의 Text2SQL 방식과 달리, TAG는 데이터베이스의 구조뿐만 아니라 AI의 세계 지식을 활용해 더 복잡한 질문도 처리할 수 있다.
예를 들어
“클래식으로 여겨지는 영화 중 가장 많은 수익을 낸 영화의 리뷰를 보여줘”라는 질문에 대해, TAG는 "클래식"이란 단어의 의미를 파악하고, 그에 맞는 데이터를 찾을 수 있는 것이다.
2. 쿼리 실행
생성된 쿼리를 데이터베이스에서 실행하는 단계
이 단계에서는 쿼리를 통해 필요한 데이터를 검색하고, 이 데이터를 AI가 이해할 수 있는 형태로 준비하는 단계이다.
이때 중요한 점은 TAG가 단순한 데이터 검색에서 그치는 것이 아니라 필터링, 집계, 정렬과 같은 복잡한 작업도 수행할 수 있다는 것이다.
3. 답변 생성
마지막 단계는 AI 언어 모델이 데이터를 바탕으로 자연어 답변을 생성하는 단계
예를 들어
“영화 Titanic의 리뷰를 요약해줘”라는 질문에 대해, TAG는 데이터베이스에서 Titanic의 리뷰 데이터를 가져와 그 내용을 요약해 줄 수 있다.
이 과정에서 TAG는 기존의 RAG 방식과 유사하게 동작하지만, 더 복잡한 질문에도 답할 수 있는 추론 능력과 텍스트 처리 능력을 가지고 있다.
이미지 출처 : https://arxiv.org/html/2408.14717v1
논문에서 진행한 실험을 통한 비교
1. 정확도 비교
TAG 모델은 복잡한 질문에 대해 기존 방식보다 훨씬 높은 정확도를 보였다.
실험에서는 Text2SQL과 RAG가 복잡한 질문에서 20% 이하의 정확도를 기록한 반면, TAG는 55% 이상의 정확도를 기록했다.
특히, 텍스트 분석이나 복잡한 계산이 필요한 질문에서 TAG의 성능이 더 뛰어났다.
예를 들어, “어떤 리뷰가 긍정적인가?” 같은 질문은 단순한 데이터 조회를 넘어서 리뷰 내용을 분석해야 하는데, TAG는 이 과정에서 AI의 텍스트 분석 능력을 활용해 정확한 답을 제공할 수 있었다.
2, 속도 비교
TAG는 복잡한 질문을 처리하면서도 최대 3.1배 더 빠른 처리 속도를 기록했다.
특히 대규모 데이터 세트를 처리할 때도 빠르게 결과를 도출할 수 있었다.
이는 TAG가 데이터를 효율적으로 필터링하고 병렬 처리를 잘 활용하기 때문이다.
기존 방식에서는 AI가 모든 데이터를 직접 분석해야 했던 반면, TAG는 DB 시스템이 많은 작업을 처리해줘서 AI의 부담을 덜어준 것이다.
정리
TAG 모델은 기존의 AI와 데이터베이스 방식들이 갖는 여러 한계를 극복하며, 다음과 같은 장점을 가지고 있다.
- 복잡한 질문 처리 가능
= Text2SQL이 처리할 수 없었던 복잡한 추론과 계산이 필요한 질문도 처리 가능.
- 데이터와 AI의 강력한 결합
= TAG는 데이터베이스의 정확한 계산 능력과 AI의 세계 지식을 결합해 복잡한 텍스트 분석과 추론이 가능.
- 효율성
= 데이터베이스의 큰 역할로 AI의 부담을 덜어 더 빠르고 정확하게 질문에 답할 수 있음.
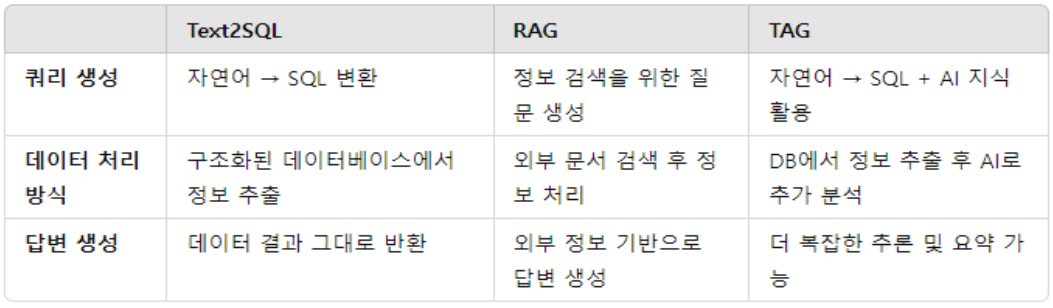
Text2SQL, RAG, TAG의 비교 정리:
Text2SQL
- 자연어를 SQL로 변환해 데이터베이스에서 직접 답을 찾음. 하지만 복잡한 추론이나 텍스트 분석에 취약.
RAG
- 데이터를 검색한 후 AI가 이를 분석해 답변을 생성. 하지만 복잡한 계산을 처리하기 어렵고, 단순한 검색에 머무름.
TAG
- Text2SQL과 RAG의 장점을 결합해, 데이터베이스에서 정보를 정확하게 가져오고, AI가 복잡한 질문에 대해 추론과 텍스트 분석을 수행할 수 있음.
- 데이터베이스와 AI의 협업을 통해 더 복잡한 자연어 질문도 처리 가능.
결론
TAG는 Text2SQL과 RAG 방식의 한계를 극복하며, 데이터베이스와 AI 언어 모델의 협업을 강화하는 방식이다.
이 모델은 복잡한 자연어 질문을 더 잘 처리하고, 정확도와 효율성을 크게 향상시킬 수 있다.
Text2SQL과 RAG가 각각의 제한적인 영역에 머물렀다면, TAG는 두 방식을 통합해 복잡한 질문에도 더 나은 답변을 제공할 수 있는 가능성을 열어준다.
