해당 내용은 논문 attention is all you need의 내용을 정리한 글입니다.
1. 초록
기존 모델의 한계:
- 기존의 주된 Sequence Transduction 모델은 복잡한 RNN이나 CNN을 기반으로 하며, Encoder와 Decoder를 포함했다.
- 최고 성능 모델은 Encoder와 Decoder를 Attention 메커니즘으로 연결했지만, 여전히 RNN이나 CNN을 함께 사용했다.
CNN (Convolutional Neural Network)
- 이미지나 공간적인 데이터를 처리하는 데 특화된 신경망
- CNN은 이미지를 작은 필터(커널)로 훑으면서 특징(Feature)을 추출
- 예를 들어, 눈, 코, 테두리, 선 등의 정보를 추출
CNN의 경우 이미지 처리에 강했지만, NLP에서도 다음과 같이 실험이 진행됨
- CNN은 단어들을 일정한 크기의 창으로 잘라서 그 안의 패턴을 보는 방식으로 적용
- "이 영화는 정말 재미없다"라는 문장을 단어 단위로 나눠보면 -> {이, 영화는, 정말, 재미없다}로 나눠어지고
- CNN이 창 크기 2로 문장을 훑는다고 한다면 {이, 영화는}, {영화는, 정말}, {정말, 재미없다}가 된다. 이때 조각에서 유용한 문맥적 패턴을 추출해서 사용하게 된다.
RNN (Recurrent Neural Network)
- 시간적 순서가 있는 데이터를 처리하는 데 특화된 신경망
- RNN 모델은 입력 및 출력 Sequencde의 각 위치(단어 등)에 대해 계산을 순차적으로 수행함
- 즉, 시간 t에서의 은닉 상태 (ht)는 이전 시간 (h{t-1})과 현재 입력에 의존하는 순차적 특성 때문에 학습 과정에서 병렬화가 어려움 -> 길이가 길어지면 이러한 한계는 더욱 두드러짐
쉽게 정리하면 RNN은 데이터를 한 번에 하나씩, 순서대로 처리하면서 이전 정보(기억)를 다음으로 넘김
- 예: “나는 밥을 먹” → 그다음 “는다”를 예측할 때 앞 문장을 기억해야 함
- 즉 장기 의존성(long-term dependency)을 지키기 어려움
- 앞 문장을 기억해야 한다는 단점이 존재했고, 긴 문장을 처리할 때 과거 정보를 잘 잊어버려 처음 내용과 마지막 내용의 관계가 이상했음.
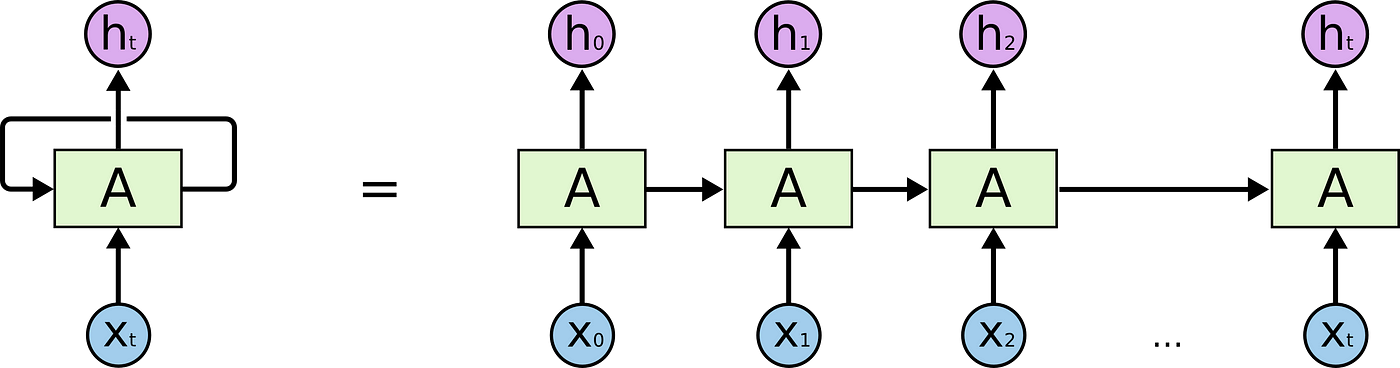
CNN과 RNN의 문제점
시퀀스 전체의 관계를 보거나, Long-term dependency(장기 의존성)를 처리하는 데는 한계가 존재했음
예제:
“민지는 초콜릿을 매우 싫어한다. 어릴 때부터 단 음식을 잘 먹지 못했고, 초콜릿 냄새만 맡아도 속이 울렁거렸다. 초콜릿이 들어간 과자나 아이스크림도 피했다. 친구들이 생일 선물로 초콜릿을 줄 때마다 다른 간식으로 바꿔달라고 부탁하곤 했다. 그런 그녀는 오늘, 진한 초콜릿 케이크를 아주 맛있게 먹었다.”
이와 같은 예제를 보면 문장이 길고 중간에 정보가 많아질수록 RNN은 초반 정보("초콜릿을 싫어한다")를 까먹을 가능성이 높아짐
이런 경우 마지막 문장과 같이 "초콜릿 케이크를 맛있게 먹었다."는 문장을 그냥 받아들일 수 있음. 즉 모순을 인지하지 못함
Transformer 제안:
- 해당 논문은 RNN과 Convolution을 완전히 배제하고, 오직 Attention 메커니즘으로만 구성된 Transformer라는 새로운 네트워크 구조를 제안한다.
Transformer의 주요 결과:
- 두 가지 기계 번역 Task(WMT 2014 영어-독일어, 영어-프랑스어)실험에서 Transformer가 기존 모델보다 뛰어난 성능을 보임
- 높은 병렬화가 가능하여 훈련 시간이 단축
- 영어 Constituency Parsing Task에도 성공적으로 적용
Constituency Parsing Task: 문장을 중첩된 성분으로 나누어 문장의 구조를 파악하는 방법
Transformer의 장점:
- RNN처럼 순차적으로 처리할 필요 없음.
- Self-Attention을 이용해 모든 단어가 서로를 한 번에 참조할 수 있음
- CNN이나 RNN 없이도 더 잘 작동함 -> 완전한 패러다임 변화가 만들어짐
2. 소개
기존 주력 모델:
이전까지 언어 모델링이나 기계 번역과 같은 Sequence Transduction 문제에서는 LSTM, GRU, RNN 기반 모델이 지배적이었음.
Sequence Transduction: 입력 시퀀스를 받아서 다른 형태의 출력 시퀀스로 변환하는 모델
예시
- 기계 번역
입력 시퀀스: "Hello" ->출력 시퀀스: "안녕하세요"
- 음성 인식(Speech-to-Text)
음성 데이터 -> 텍스트
- 텍스트 요약
문장 -> 요약 문장
- 언어 모델링(다음 토큰 예측)
"나는 밥을 먹" -> "는다"
LSTM (Long Short-Term Memory): 정보를 잊을지 말지를 스스로 결정하는 장치(게이트)를 추가
LSTM은 아래 3가지 게이트를 통해 정보를 조절하도록 함
- Forget Gate: 이전 정보를 얼마나 잊을지 결정
- Input Gate: 새로운 정보를 얼마나 저장할지 결정
- Output Gate: 어떤 정보를 출력으로 보낼지 결정
이 덕분에 중요한 정보는 오래 기억하고, 불필요한 정보는 버릴 수 있어, 장기 의존성을 더 잘 유지함.
GRU (Gated Recurrent Unit): LSTM보다 단순하게 만들자
GRU는 LSTM보다 더 간단한 2개의 구조를 가짐
- Update Gate: 이전 정보를 유지할지 업데이트할지 결정
- Reset Gate: 현재 입력과 과거 정보를 얼마나 섞을지 결정
2개의 게이트만 갖고 있기에 LSTM보다 속도가 더 빠르고, 파라미터 수도 적음
위 기존 주력 모델의 한계를 해결하기 위해서 Attention 메커니즘이 떠오르기 시작
Attention 메커니즘은 입력이나 출력 Sequence의 거리에 상관없이 의존성을 모델링할 수 있도록 하여 Sequence 모델링 및 Transduction 모델에서 중요한 역할을 하게 됨.
Attention 메커니즘?
: 입력 시퀀스 중에서 "어디를 집중해서 볼지"를 스스로 판단해서 가중치를 부여하는 메커니즘
예시로 쉽게 이해해보자.
기계 번역으로 예시를 들면
영어 "I love you"
프랑스어: "Je t'aime" (Je = 나는, te = 너를, aime 사랑합니다.)위와 같이 영어를 프랑스어로 번역할 때 디코더가 "aime"를 생성하려고 할 때,
어떤 입력 단어("I", "love", "you")를 가장 많이 참고할까?당연히 love를 가장 많이 참고할 것이다.
이걸 모델이 스스로 판단해서 입력 단어들에 중요도(가중치)를 주는 게 바로 Attention이다.
Attention을 조금 더 기술적으로 설명하면
Attention score 계산 과정
- Query (Q): 지금 어떤 단어를 생성할지에 대한 질문
- Key (K): 입력 시퀀스 각각의 단어가 가진 정보 (주소표 같은 느낌)
- Value (V): 진짜 참고할 정보
Query와 Key를 비교해서 유사도(중요도 점수)를 계산하고, 그 점수를 바탕으로 Value를 뽑아냄
RNN과 Attention을 비교하면 다음과 같음
- 단어를 하나씩 순차적으로 처리하는 RNN과 다르게 전체 시퀀스를 한 번에 보고, 중요한 위치에 집중
- 멀리 떨어진 단어라도 잘 참조 가능
- 필요한 정보만 골라서 참조 가능
그럼 Transformer에서의 Self-Attention은 뭔데?
간단히 말하면 자기 자신 내부에서도 어떤 단어가 다른 단어에 얼마나 영향을 주는지를 스스로 계산하는 것
예를들어 "고양이가 쥐를 잡았다."라는 문장에서 "잡았다"는 단어는 "고양이"가 "쥐"보다 더 관련이 있음
이처럼 모델이 그 관계를 스스로 계산해서 집중하는 것을 말함.
그러나 이러한 Attention 메커니즘은 transformer(RNN 없이 Attention만 사용하는 모델)가 나오기 전까지는 RNN과 함께 사용되었다.
그래서 해당 논문에서는 순환 구조를 완전히 배제하고 오직 Attention 메커니즘만을 사용해서 입력과 출력 간의 전역적인 의존성을 파악하는 새로운 모델 구조인 Transformer를 제안한다.
여기서 순환 구조란 RNN 문맥에서 이전 상태를 이용해 다음 상태를 계산하는 구조를 의미함.
Transformer의 장점:
- 순환 구조가 없기 때문에 기존 RNN 기반 모델보다 훨씬 뛰어난 병렬 처리가 가능함
- 이를 통해 휠씬 짧은 시간만으로도 기계 번역 분야에서 새로운 최고 성능을 달성함
즉, 이 논문은 기존 Sequence 모델의 핵심이었던 RNN의 순차적 계산 한계를 극복하기 위해 Attention 메커니즘에만 전적으로 의존하는 Transformer를 제안했으며, 이를 통해 계산 효율성과 성능 모두에서 큰 발전을 이루었음을 강조
Transformer의 구조
Transformer는 전통적인 신경망 기반 번역 모델과 유사하게 인코더-디코더 구조를 따른다.
기존 인코더-디코더의 구조:
인코더: 입력 시퀀스(단어 나열)를 연속적인 표현(벡터 시퀀스)으로 변환하는 역할을 진행
디코더: 인코더의 출력을 바탕으로 출력 시퀀스를 하나씩 생성, 디코더는 이전 단계에서 생성된 심볼을 입력으로 사용하여 다음 심볼을 예측하는 자기회귀 방식을 따름
Attention 메커니즘만 사용:
Transformer는 순환 또는 컨볼루션 레이어를 사용하지 않고, '쌓아 올린(stacked)' 셀프-어텐션(self-attention)과 각 위치별(point-wise) 완전히 연결된(fully connected) 레이어만으로 인코더와 디코더를 구성한다.
Transformer
transformer를 학습할 때 논문에서는 Masked Multi-Head Self-Attention 기법을 활용했다.
과정은 다음과 같다.
[Encoder]
입력 전체 문장 → Self-Attention → 문맥 표현 생성
[Decoder]
정답 문장 일부 + Masked Self-Attention → 이전 단어까지만 보고 다음 단어 예측
- Encoder-Decoder Attention → 입력 문장에서 중요한 단어 참고
[Loss 계산]
디코더가 만든 출력과 실제 다음 단어(정답)를 비교 → Cross-Entropy Loss
위와 같은 방법으로 인코더에는 입력한 전체 문장이 마스킹 없이 들어가게 된다.
이때 인코더는 Self-Attention을 사용해서 문맥 정보를 잘 담은 벡터 시퀀스를 생성한다.이후 디코더의 경우 정답 시퀀스를 왼쪽부터 하나씩 순차적으로 넣되, 미래 단어는 마스킹한다.
예시
encoder_input = ["I", "ate", "rice"]
decoder_input = ["", "나는", "밥을", "먹었다"]
이 시퀀스를 Self-Attention + Masking에 넣음
위 예시에서 디코더가 "나는" 위치에서 다음 단어를 예측할 땐:
"나는"만 보도록 마스킹
"밥을", "먹었다"는 못 보게 함즉, Look-Ahead Masking을 통해
→ 현재 위치보다 오른쪽(미래)의 단어는 못 보도록 함
쌓아 올린 레이어:
인코더와 디코더 모두 동일한 레이어를 여러 개 쌓아 올린 형태로 이루어져 있다. 이 논문에서는 기본적으로 N=6개의 레이어를 사용함.
- 인코더 레이어: 각 인코더 레이어는 두 개의 하위 레이어로 구성된다.
- 첫 번째는 Multi-Head Self-Attention 메커니즘
- 두 번째는 간단한 Position-wise Fully Connected Feed-Forward Network
- 디코더 레이어: 각 디코더 레이어는 세 개의 하위 레이어로 구성된다.
- 첫 번째는 Multi-Head Self-Attention 메커니즘 (이때, 이후 위치의 정보는 보지 않도록 마스킹됨)
- 두 번째는 인코더 스택의 출력에 대해 수행되는 Multi-Head Attention(Encoder-Decoder Attention)
- 세 번째는 인코더와 동일한 Position-wise Fully Connected Feed-Forward Network
쌓아 올린 레이어에서 인코더와 디코더의 구조 설명
인코더
- 역할: 입력 시퀀스를 받아서 문맥을 반영한 고차원 벡터 표현으로 변환해 디코더가 참고할 수 있는 정보로 제공
입력 구성
- 단어 임베딩: 각 단어를 고정된 차원의 벡터로 변환
- 위치 인코딩: Transformer는 RNN처럼 순서를 자연스럽게 인식하지 못하므로, 단어의 위치 정보를 인코딩해서 더함(사인/코사인 함수 기반 위치 벡터를 사용)
- 최종 입력 = 단어 임베딩 + 위치 인코딩
- 인코더 구조: 6개의 동일한 레이어
각 인코더 레이어는 아래의 블록으로 구성된다.
🔸 1. Multi-Head Self-Attention>
- 입력 문장 안의 모든 단어 쌍 사이의 관계를 학습
- “it”이 문장 속 어느 명사를 가리키는지 등 문맥 파악 가능
- 다중 헤드(Multi-Head): 다양한 시점의 관계를 병렬로 학습
→ 다양한 의미론적/구문적 관계를 포착 가능🔸 2. Position-wise Feed-Forward Network
- 각 단어 위치에 대해 독립적으로 2층의 Fully Connected Layer 적용
- 모든 단어에 동일한 네트워크 구조가 적용되지만, 파라미터는 학습됨
🔸 3. Residual Connection + Layer Normalization
- 각 블록의 입력 + 출력을 더해서 잔차 연결(Residual Connection)
- → 학습 안정성 및 성능 향상
- 이후 레이어 정규화로 분산 조정
✔️ 인코더 출력
- 인코더 스택의 최종 출력은 각 입력 단어에 대한 의미가 풍부한 표현 벡터들
- 디코더에서 인코더-디코더 어텐션 시 입력으로 사용됨
디코더
- 역할: 인코더의 출력을 참고하면서, 이전까지 생성한 단어들을 기반으로 다음 단어를 예측하여 최종적으로 전체 출력 시퀀스를 생성
입력 구성
- 이전에 생성된 출력 단어들의 임베딩 + 위치 인코딩
- 인코더 스택의 최종 출력
- 디코더 구조: 6개의 동일한 레이어
각 인코더 레이어는 아래의 블록으로 구성된다.
🔸 1. Masked Multi-Head Self-Attention
- 디코더가 아직 생성되지 않은 미래 단어를 보지 못하게 마스킹 처리
- 예: "나는 밥을" → 다음 단어 "먹었다" 예측 시 "먹었다"는 아직 생성되지 않았으므로 참조 불가
- 이렇게 함으로써 Auto-Regressive (자기회귀) 방식 유지
🔸 2. Multi-Head Attention (Encoder-Decoder Attention)
- Query: 디코더의 이전 출력
- Key & Value: 인코더 출력
- 디코더가 입력 문장의 어느 부분을 참고해야 하는지 학습
- → 번역 시 원문과 번역문 간의 정렬(alignment)을 학습하는 핵심 단계
🔸 3. Position-wise Feed-Forward Network
- 인코더와 동일하게 적용
🔸 4. Residual Connection + Layer Normalization
- 각 블록의 출력과 입력을 더한 뒤 정규화
✔️ 디코더 출력
- 최상단 레이어에서 얻은 벡터를 선형 레이어 + Softmax를 통해 전체 단어 사전 내 확률 분포로 변환
- 가장 확률이 높은 단어 선택 → 다음 단어로 출력
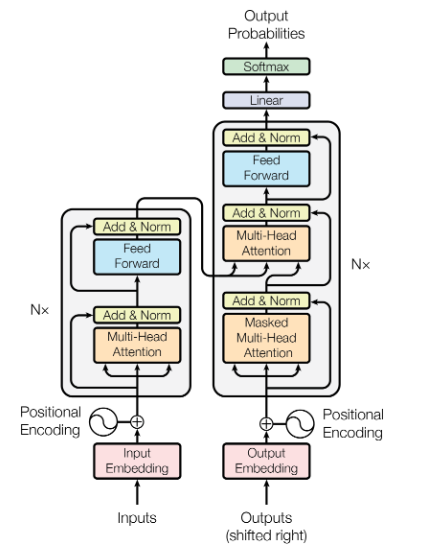
위에서 언급된 단어 설명
셀프 어텐션(Self-Attention):
- 입력 시퀀스 내에서 단어들 간의 관계를 파악하는 메커니즘
- 예를 들어 문장 안에서 대명사가 어떤 명사를 가리키는지 등을 모델링하는 데 유용함
- Transformer에서는 Multi-Head Attention 형태로 사용됨
Position-wise Fully Connected Feed-Forward Network
- Attention 하위 레이어에서 나온 각 단어의 표현에 대해 독립적으로 적용되는 간단한 피드-포워드 신경망
- 이는 모델의 표현력을 높이기 위해 각 단어 표현을 비선형적으로 변환하는 역할
- 커널 크기가 1인 컨볼루션 레이어 두 개로 설명할 수 있음
잔여 연결(Residual Connection) 및 레이어 정규화(Later Nomalization)
- 각 하위 레이어의 출력은 해당 레이어의 입력과 더해진 후(잔여 연결), 레이어 정규화를 거침
- 이는 깊은 신경망의 학습을 안정화하고 돕는 역할을 함
Multi-Head Self-Attention:
- 이 하위 레이어는 현재 레이어의 입력 시퀀스 표현을 스스로(Self) 어텐션 함
- 즉, 입력 시퀀스 안의 모든 위치에 있는 단어들이 서로에게 얼마나 중요한지(관련 있는지) 계산하고, 그 중요도에 따라 가중치를 부여하여 새로운 표현을 만듬
- 예를 들어 "it"이라는 단어가 문장 내의 어떤 명사를 가리키즌지 등을 이 메커니즘을 통해 학습할 수 있음
- 여러 개의 "헤드(Head)"를 사용하여 다양한 종류의 관계를 동시에 포착하도록 함
Transformer에서 인코더-디코더 어텐션과 self 어텐션의 차이점
인코더 디코더 어텐션
- 이는 디코더 스택 내의 레이어에 위치합니다.
- 쿼리(Q)는 디코더의 이전 레이어 출력에서 가져옵니다. 즉, 현재 디코딩하려는 위치의 정보를 담고 있습니다.
- 키(K)와 값(V)은 인코더 스택의 최종 출력에서 가져옵니다. 이는 입력 시퀀스 전체에 대한 정보를 담고 있습니다.
목적: 디코더가 출력 단어를 생성할 때, 인코더가 파악한 입력 시퀀스 정보 중에서 현재 출력과 가장 관련 있는 부분을 집중적으로 참고할 수 있도록 합니다. 번역 태스크에서는 입력 문장의 단어들과 출력 문장의 단어들 사이에 암묵적인 정렬(alignment)을 학습하는 역할을 합니다.
셀프 어텐션
- 이는 인코더 스택과 디코더 스택 모두에 위치합니다.
- 쿼리(Q), 키(K), 값(V) 모두 동일한 소스, 즉 해당 스택의 이전 레이어 출력에서 가져옵니다.
목적: 시퀀스 내에서 각 위치의 단어들이 다른 위치의 단어들과 어떤 관계를 맺고 있는지 파악하여 시퀀스 자체의 표현을 강화합니다. 예를 들어, 인코더에서는 입력 문장 내 단어들 간의 관계를, 디코더에서는 이미 생성된 출력 문장 내 단어들 간의 관계를 모델링합니다 (디코더에서는 마스킹이 적용되어 미래의 단어는 보지 못합니다).
핵심적인 차이점:
인코더-디코더 어텐션은 기본적인 Scaled Dot-Product Attention 계산을 사용하지만, 쿼리는 디코더에서, 키와 값은 인코더에서 가져와 디코더가 인코더의 정보를 참고하게 만든다는 점에서, 쿼리, 키, 값 모두 동일한 소스에서 오는 셀프-어텐션과는 다르다.
Transformer 모델의 핵심 구성 요소 중 하나인 "Scaled Dot-Product Attention"
transformer 모델의 핵심 구성 요소 중 하나인 "Scaled Dot-Product Attention은 쿼리, 키, 값 벡터를 사용하여 출력 값을 계산하는 어텐션 함수의 한 종류이다.
- 기존 attention 함수의 경우 기본적으로 쿼리와 키 쌍의 호환성 함수를 계산해서 각 값에 할당할 가중치를 결정한 다음, 이 가중치 값들의 가중합을 계산하여 출력 값을 얻는다.
Scaled Dot-Product Attention의 경우
- 쿼리와 키의 내적(dot product)을 사용하여 호환성을 계산
- 계산된 내적 값을 키의 차원 수인 (d_k)의 제곱근((\sqrt{d_k}))으로 나눔(Scaling).
- Scaling된 결과에 Softmax 함수를 적용하여 값(Value)에 대한 가중치를 얻음
- 얻은 가중치와 값(Value)들을 곱하여 최종 출력 값을 계산
Transformer 모델의 핵심 구성 요소 "Multi-Head Attention"
문제 제기: dmodel 차원의 Q, K, V를 사용하여 하나의 Attention 함수를 수행하는 것은 모델이 다양한 정보를 동시에 집중하는 것을 제한할 수 있다.(단일 Attention Head는 모든 정보를 평균화하는 경향이 있다.)
- Multi-Head Attention의 아이디어: 이러한 한계를 극복하기 위해, Q, K, V를 여러 개의 다른, 학습된 선형 변환 행렬을 사용하여 h번 별도로 투영하는 방법을 제안, 간단히 말하면 하나의 attention 함수를 사용하는 대신, 여러 개의 attention 함수를 병렬적으로 실행하자!
- 각 투영의 결과는 더 낮은 차원(dq, dk, dv)를 가짐
- 병렬 Attention 계산: 이렇게 투영된 Q, K, V 쌍 각각에 대해 Attention 함수를 병렬적으로 수행, 즉, h개의 Attention Head가 동시에 계산됩니다. 각 Head는 dv 차원의 출력 값을 생성
- 결과 결합: h개의 Attention Head에서 나온 각각의 dv 차원 출력 값들은 하나로 연결(concatenate)
- 최종 투영: 연결된 출력 값은 최종적으로 또 다른 학습된 선형 변환 행렬을 통해 투영되어 Multi-Head Attention의 최종 출력 값을 얻음.
- 효과: Multi-Head Attention은 모델이 서로 다른 표현 공간(representation subspace)에서, 그리고 서로 다른 위치의 정보에 동시에 집중할 수 있도록 함, 단일 Attention Head가 평균화하는 것을 Multi-Head Attention은 여러 개의 "관점"을 통해 보완
Transformer 모델의 핵심 구성 요소 위치 인코딩(Positional Encoding)
- Transformer는 기존 순환 신경명(RNN)이나 컨볼루션 레이어(CNN)을 사용하지 않기 때문에, 입력 시퀀스 내 단어들의 순서 정보나 상대적인 위치 정보를 모델 스스로 학습하기 어려움
- 이를 보완하기 위해 위치 인코딩을 사용함.
- 위치 인코딩의 필요성: 위에서 언급한 이유와 같이 Transformer 모델은 시퀀스의 순환적 또는 컨볼루션적 처리가 없기 때문에, 입력 시퀀스에 있는 토큰들의 순서 정보를 명시적으로 알려주어야 함
- 위치 인코딩의 역할: 시퀀스 내 토큰의 절대적 또는 상대적 위치 정보를 주입하는 역할
- 구현 방식: 입력 임베딩에 위치 인코딩 값을 더해줌, 이때 위치 인코딩은 임베딩과 동일한 차원을 가짐
- 이 논문에서 사용한 방식: 사인(sine) 및 코사인(cosine) 함수를 이용한 고정된 위치 인코딩을 사용
결론
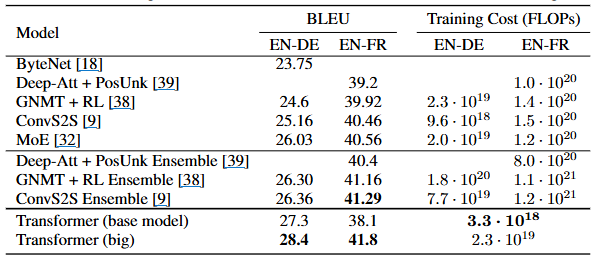
위와 같이
- BLEU: 번역 품질을 측정하는 지표로 점수가 높을수록 번역 품질이 우수함
- Training Cost(FLOPs): 모델 훈련에 소요된 연산량을 나타냄, 수치가 낮을수록 훈련 효율성이 높음
2개의 평가 지표에 대해서 Transformer 모델이 기존의 순환 또는 컨볼루션 신경망 기반 모델들보다 훨씬 효율적이며 훈련 비용으로도 기계 번역 작업에서 월등히 우수한 성능을 달성했음을 명확히 보여줌.
Transformer 모델 소개:
이 논문에서 핵심적으로 제시하는 Transformer는 RNN이나 CNN과 같은 기존의 순환 레이어를 사용하지 않고, 전적으로 Multi-Head Self-Attention 메커니즘에 기반한 최초의 Sequence Transduction 모델로 Encoder-Decoder 구조를 사용하지만, 그 내부는 Attention만으로 구성되어 있음
