왜 몽고디비를 사용할려고 하는가?
- 회사 기술 스택이 MongoDB 라서 😊
- RDBMS에서 벗어난 NoSQL이란놈이 궁금해서! 😎
몽고 디비란?
몽고 디비의 정의 NoSQL로 분류되는 크로스 플랫폼 도큐먼트 지향 데이터베이스 시스템 입니다.
NoSQL?
NoSQL이란 SQL이 없는 데이터 베이스구나! 가 아닌 Not Only SQL로 기존의 RDBMS의 한계를 극복하기 위해 만들어진 새로운 형태의 데이터 저장소입니다. 관계형 DB가 아니므로, 고정된 스키마 및 Join 이 존재하지 않습니다!
Document? 문서?
Document : Key,Value Pair로 이루어진 JSON 형태의 자료입니다.
MongoDB 샘플 Document를 보며 확인해보겠습니다.
{
"_id": ObjectId("5099803df3f4948bd2f98391"),
"username": "velopert",
"name": { first: "M.J.", last: "Kim" }
}
key는 _id,username,name이고, value는 오른쪽에 있는 값을 의미합니다.
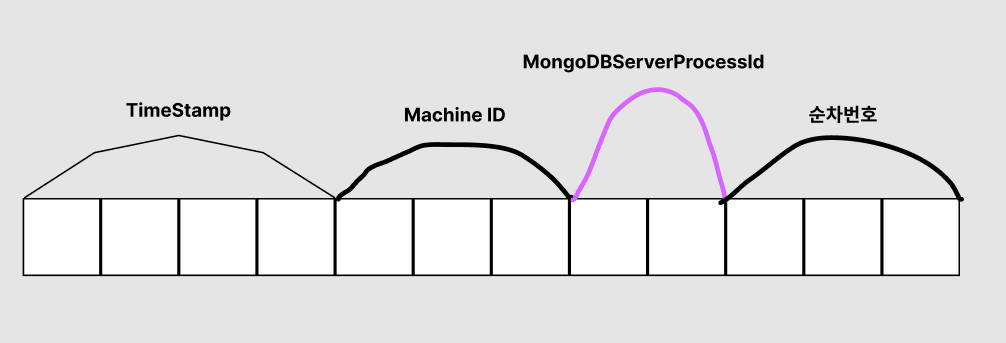
_id는 12bytes의 hexadecimal 값으로써 각 document의 유일함(uniqueness)을 제공합니다.
이 값의 첫 4bytes는 timestamp, 다음 3bytes machine id, 2bytes MongoDB server process ID, 3bytes 순차 번호로 이루어져있습니다.
Document는 동적(dynamic)의 schema 를 갖고있습니다. 같은 Collection 안에 있는 Document 끼리 다른 schema 를 갖고 있을 수 있는데요, 쉽게 말하면 서로 다른 데이터 (즉 다른 key) 들을 가지고 있을 수 있습니다.
Collection? DataBase?
Collection은 Document의 그룹입니다. RDBMS에서 Table과 비슷한 개념입니다만, 따로 Schema를 가지지 않고 각 동적인 Document를 가지고 있습니다.
DataBase 는 Collection들의 물리적인 컨테이너입니다. 각 DB는 파일 시스템에 여러파일들로 저장됩니다.
MongoDB Schema 디자인 가이드
NoSQL의 장점이자 MongoDB의 장점은 동적 스키마에 있습니다. 동적 스키마를 활용해 어떤 값이든 넣을 수 있고, 불필요한 조인 값을 아낄 수 있다는 장점이 있습니다. 이러한 자유로움 속에서도 디자인 가이드가 있는 것은 앱마다 효율적인 스키마가 있고 비효율적인 스키마가 존재한다는 것을 의미합니다.
본 글에서는 Mongo DB에 잘 정리된 글이 있어,해당 문서를 복습 차원에서 요약한 글입니다.
1:1 (one to one)
1:1 data 는 key-value pair로 간단히 연결 해주자
{
"_id": "ObjectId('AAA')",
"name": "Joe Karlsson",
"company": "MongoDB",
"twitter": "@JoeKarlsson1",
"twitch": "joe_karlsson",
"tiktok": "joekarlsson",
"website": "joekarlsson.com"
}1:FN (one to few)
한 유저가 살고 있는 주소가 한정적일때
{
"_id": "ObjectId('AAA')",
"name": "Joe Karlsson",
"company": "MongoDB",
"twitter": "@JoeKarlsson1",
"twitch": "joe_karlsson",
"tiktok": "joekarlsson",
"website": "joekarlsson.com",
"addresses": [
{ "street": "123 Sesame St", "city": "Anytown", "cc": "USA" },
{ "street": "123 Avenue Q", "city": "New York", "cc": "USA" }
]
}1:MN(one to many)
특정 제품에 대한 상세 정보를 제공 해주고, 특정 제품을 활용해 하나의 Object를 만들때(예:자전거)

Product
{
"name": "left-handed smoke shifter",
"manufacturer": "Acme Corp",
"catalog_number": "1234",
"parts": ["ObjectID('AAAA')", "ObjectID('BBBB')", "ObjectID('CCCC')"] // Parts의 _id
}
-----------------------------------
Parts
{
"_id" : "ObjectID('AAAA')",
"partno" : "123-aff-456",
"name" : "#4 grommet",
"qty": "94",
"cost": "0.94",
"price":" 3.99"
}1:SN (one to squillions)
만약 몇백만개의 subDocument가 있는 경우엔? log나 카카오 메시지 처럼?
MongoDB는 Document당 최대 용량을 16MB 지정해놓았기에 log:[Object('aaaa'),... 100만개] 이러한 방향으로 저장할 경우 매우 위험하다. 이럴 경우 양쪽 관계를 가져가지 말고 아래 예시처럼 진행하자
Hosts
{
"_id": ObjectID("AAAB"),
"name": "goofy.example.com",
"ipaddr": "127.66.66.66"
} // Hosts에선 Log에 대한 정보를 찾을 수 없다
------------------------
Log Message
{
"time": ISODate("2014-03-28T09:42:41.382Z"),
"message": "cpu is on fire!",
"host": ObjectID("AAAB")
} // Log에선 Host의 _id 값을 통해 접근한다.N:N (Many to Many)
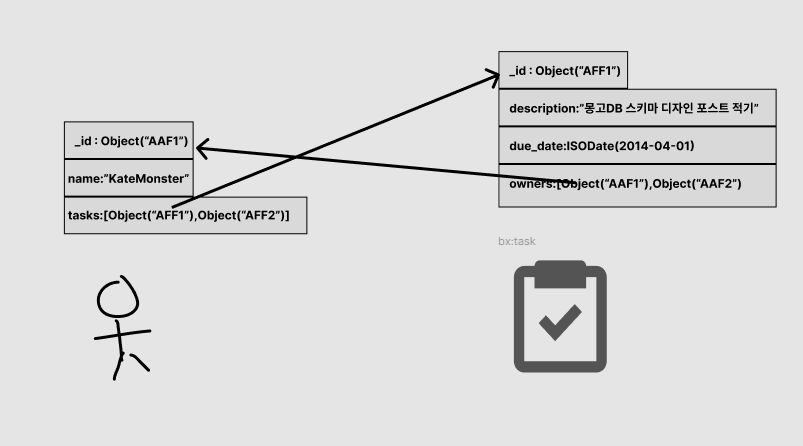
채팅방이나 todo-app의 task와 관련된 스키마를 짠다고 가정해보자.
어떤 유저가 A라는 task를 담고 있고, task에는 A라는 유저가 task를 가지고 있다고 데이터를 저장하는 경우를 생각해보자. user도 여러 task를 가져가고 task도 여러 user를 가져간다.
이 경우엔 아래 그림처럼 user도 tasks ObjectID를 가진 subArray를 embed 하고 task도 user의 ObjectID를 가진 subArray를 embed 한다.
Users
{
"_id": ObjectID("AAF1"),
"name": "Kate Monster",
"tasks": [ObjectID("ADF9"), ObjectID("AE02"), ObjectID("AE73")]
}
------------------
Tasks
{
"_id": ObjectID("ADF9"),
"description": "Write blog post about MongoDB schema design",
"due_date": ISODate("2014-04-01"),
"owners": [ObjectID("AAF1"), ObjectID("BB3G")]
}
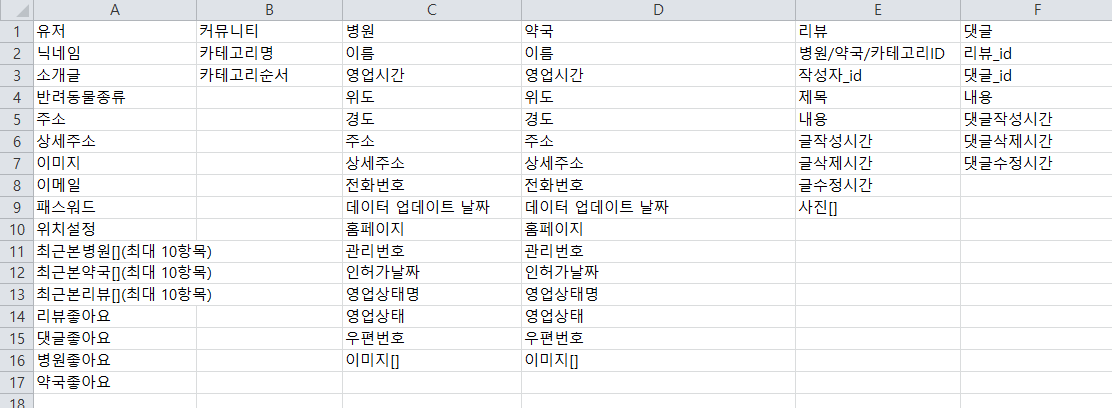
ToyProject 스키마 디자인 만들기!
- 엑셀로 먼저 필요한 정보에 대한 내용을 정리 해보았습니다!
- ERD를 통해 데이터를 시각화하여 정규화 혹은 더 효율적인 스키마가 있는지 확인 해보는 과정을 가져보겠습니다!
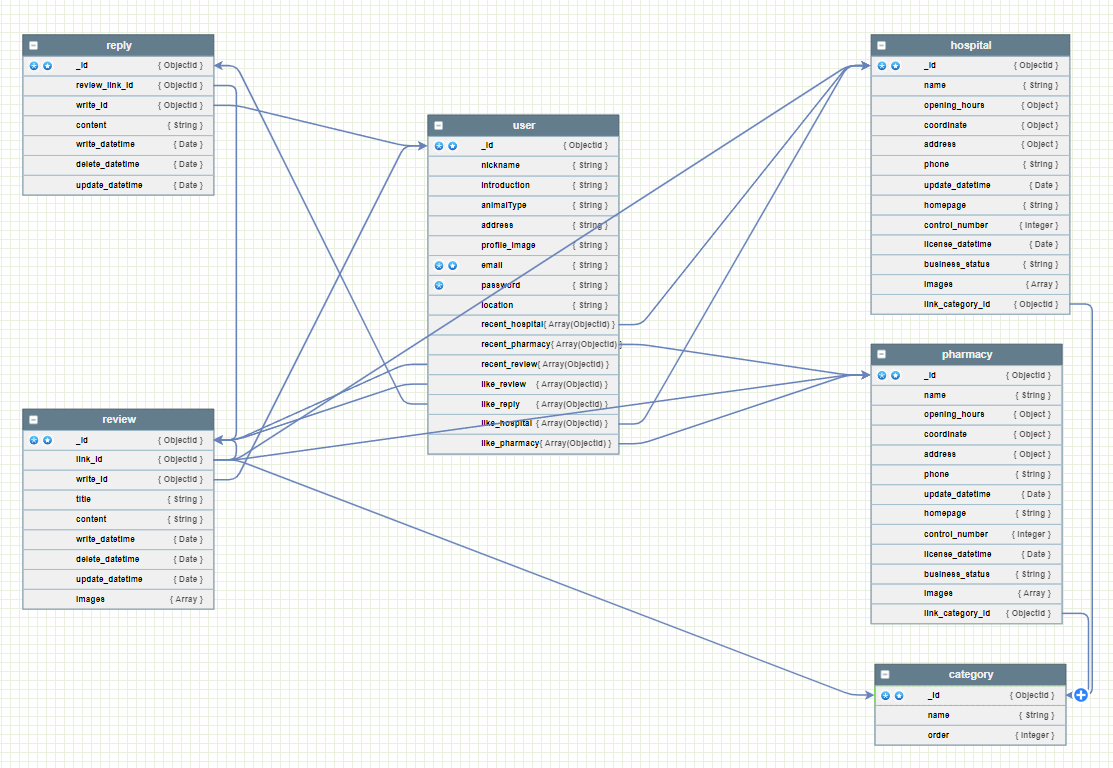
??? RDBMS에서 익숙해서 그런가 뭔가 많이 엉켜있습니다
하나씩 뜯어 보도록 하죠 ㅋㅋ 😋
user _id 에 연결된 속성
- reply-write_id 댓글 작성자
- review-write_id 리뷰 작성자
두 경우엔 nickname과 연관된 속성이라 유저가 닉네임 변경시 변경이 필요한 값이므로 Pass
review_id에 연결된 속성
- reply-review_link_id 리뷰-댓글 연결용
- user-recent_reviews 최근본 리뷰 연결용
- user-like_reviews 찜한 리뷰 연결용
hospital_id에 연결된 속성
- review-link_id 리뷰-병원 연결용
- user-recent,like_hospital 최근,찜한 병원 연결용
pharmacy_id에 연결된 속성
- review-link_id 리뷰-약국 연결용
- user-recent,like_hospital 최근,찜한 약국 연결용
category_id에 연결된 속성
- review-_id 카테고리-리뷰 연결용
- hospital-_id 병원-카테고리 연결용
- pharmacy-_id 약국-카테고리 연결용
reply_id에 연결된 속성
- user-like_reply 유저-댓글 연결용
스키마 최적화 고민
- review - reply을 따로 저장해야 하는가? 1:MN 관계이기에 현재 방식으로 진행하는게 좋을듯 싶습니다.
채워나갈 부분들 (주요기능)
애드혹 쿼리
몽고DB는 필드, 레인지 쿼리, 정규 표현식 검색을 지원한다.[6] 쿼리는 특정 필드의 도큐먼트를 반환할 수 있으며 사용자 지정 자바스크립트 함수를 포함할 수도 있다. 쿼리는 주어진 크기의 임의의 결과 샘플을 반환하도록 설정할 수도 있다.
색인
몽고DB 도큐먼트의 필드는 프라이머리(primary) 인덱스와 세컨더리(secondary) 인덱스로 인덱싱할 수 있다.
리플리케이션
몽고DB는 리플리카 세트(replica set)와 함께 고가용성을 제공한다.[7] 리플리카 세트는 둘 이상의 데이터 사본으로 구성된다. 각 리플리카 세트 멤버는 어느 시점에서나 프라이머리나 세컨더리 리플리카 역할을 수행할 수 있다. 모든 쓰기와 읽기는 기본값으로 프라이머리 리플리카에서 수행된다. 세컨더리 리플리카는 내장된 리플리케이션 기능을 사용하여 프라이머리의 데이터의 사본을 관리한다. 프라이머리 리플리카가 실패하면 리플리카 세트는 어느 세컨더리가 프라이머리가 되면 좋을지 결정하기 위해 선거 과정을 자동으로 수행한다. 세컨더리 리플리카들은 선택적으로 읽기 조작을 서비스할 수 있으나 해당 데이터는 기본적으로 일관성을 유지한다.
로드 밸런싱
몽고DB는 샤딩을 사용하여 수평으로 스케일링한다.[8] 사용자는 컬렉션 안의 데이터의 배포 방식을 결정하는 샤드 키를 선택하게 된다. 데이터는 여러 레인지(샤드 키에 따라)로 분리되며 여러 샤드로 배포된다. (샤드는 하나 이상의 리플리카가 존재하는 마스터이다)
몽고DB는 여러 개의 서버 위에서 실행할 수 있고 부하분산이라든지, 기동 중 데이터 복제, 하드웨어 고장 시 수행이 가능하다.
파일 스토리지
몽고DB는 파일 저장을 위해 여러 머신에 로드 밸런싱, 데이터 리플리케이션 기능과 더불어 GridFS라는 이름의 파일 시스템으로 사용할 수 있다.이 기능은 그리드 파일 시스템이라고 부르며[9] 몽고DB 드라이버에 포함되어 있다. 몽고DB는 파일 조작의 기능과 콘텐츠를 개발자들에게 노출한다. GridFS는 mongofiles 유틸리티나 Ngnix 플러그인[10], Lighttpd를 사용하여 접근할 수 있다.[11] GridFS는 파일 하나를 여러 부분이나 덩어리(chunk)로 분리시키며 해당 덩어리들 각각을 별도의 도큐먼트로 저장한다.[12]
애그리게이션
몽고DB는 애그리게이션 수행을 위해 3가지 수단을 제공한다: 애그리게이션 파이프라인(aggregation pipeline), 맵리듀스 기능(map-reduce function), 단일 목적 애그리게이션 방식(single-purpose aggregation method).[13]
데이터 처리와 애그리게이션 조작을 위해 맵리듀스를 사용할 수 있다. 그러나 몽고DB의 문서에 따르면 애그리게이션 파이프라인이 대부분의 애그리게이션 조작에 더 나은 성능을 제공한다.[14]
애그리게이션 프레임워크를 사용하면 사용자들이 SQL GROUP BY 절이 사용되는 결과의 종류를 취득할 수 있다. 애그리게이션 연산자들은 하나로 묶어서 하나의 파이프라인을 형성할 수 있는데, 이는 유닉스 파이프와 비슷하다. 애그리게이션 프레임워크는 여러 도큐먼트로부터 도큐먼트들을 조인(join)할 수 있는 $lookup 연산자를 포함하고 있으며 표준 편차 등의 통계 연산자를 포함한다.
서버사이드 자바스크립트 실행
자바스크립트를 쿼리, 애그리게이션 기능(맵리듀스 등)에 사용할 수 있으며 직접 데이터베이스로 보내어 실행할 수 있다.
캡트 컬렉몽고DB는 캡트 컬렉션(capped collection)이라는 이름의 고정 크기의 컬렉션을 지원한다. 이러한 유형의 컬렉션은 삽입 순서를 관리하고 특정 크기에 도달하면 원형 버퍼처럼 동작하게 만들 수 있다.션
몽고DB는 캡트 컬렉션(capped collection)이라는 이름의 고정 크기의 컬렉션을 지원한다. 이러한 유형의 컬렉션은 삽입 순서를 관리하고 특정 크기에 도달하면 원형 버퍼처럼 동작하게 만들 수 있다.
트랜잭션
멀티 도큐먼트 ACID 트랜잭션 지원이 2018년 6월 4.0 릴리스의 GA(General Availability)와 더불어 몽고DB에 추가되었다.[15]
