📌 Decision Tree
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 알고리즘
(쉽게 이해하려면 if-else문을 자동으로 찾아내 예측 위한 규칙을 만드는 알고리즘)
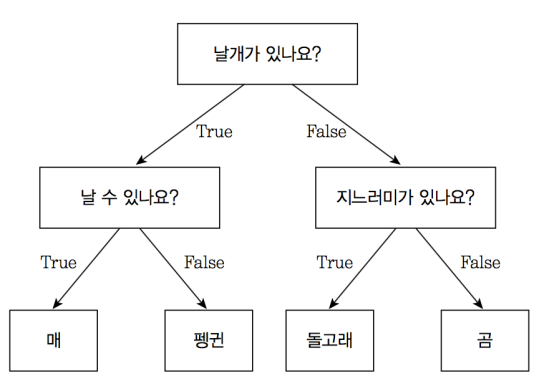
구조
- 루트노드 : 시작점
- 리프노드 : 분류 클래스의 총 개수
- 규칙노드(=내부노드) : 데이터셋의 feature가 결합해 만들어진 분류 위한 규칙 조건
📌 Bagging
- 배깅(Bagging) : Bootstrap Aggregating의 약자
- 보팅(Voting)과 달리 동일한 알고리즘으로 여러 분류기를 만들어 보팅으로 최종 결정
💡 배깅 진행 과정
1) 동일한 알고리즘을 사용하는 일정 개수의 분류기 생성
2) 각 분류기는 부트스트래핑(Bootstraping) 방식으로 생성된 샘플 데이터를 학습
3) 최종적으로 모든 분류기가 보팅 통해 예측 결과 결정
📌 RandomForest: 랜덤포레스트
#개의 결정트리(Decision Tree)를 활용한 배깅 방식의 대표적인 알고리즘
1. 장단점
장점
- 결정트리의 쉽고 직관적인 장점 그대로 지님
- 앙상블 알고리즘 중 비교적 빠른 수행 속도
- 다양한 분야에서 좋은 성능 보임
단점
- 하이퍼 파라미터가 많아 튜닝을 위한 시간 # 소요
2. 하이퍼 파라미터 튜닝
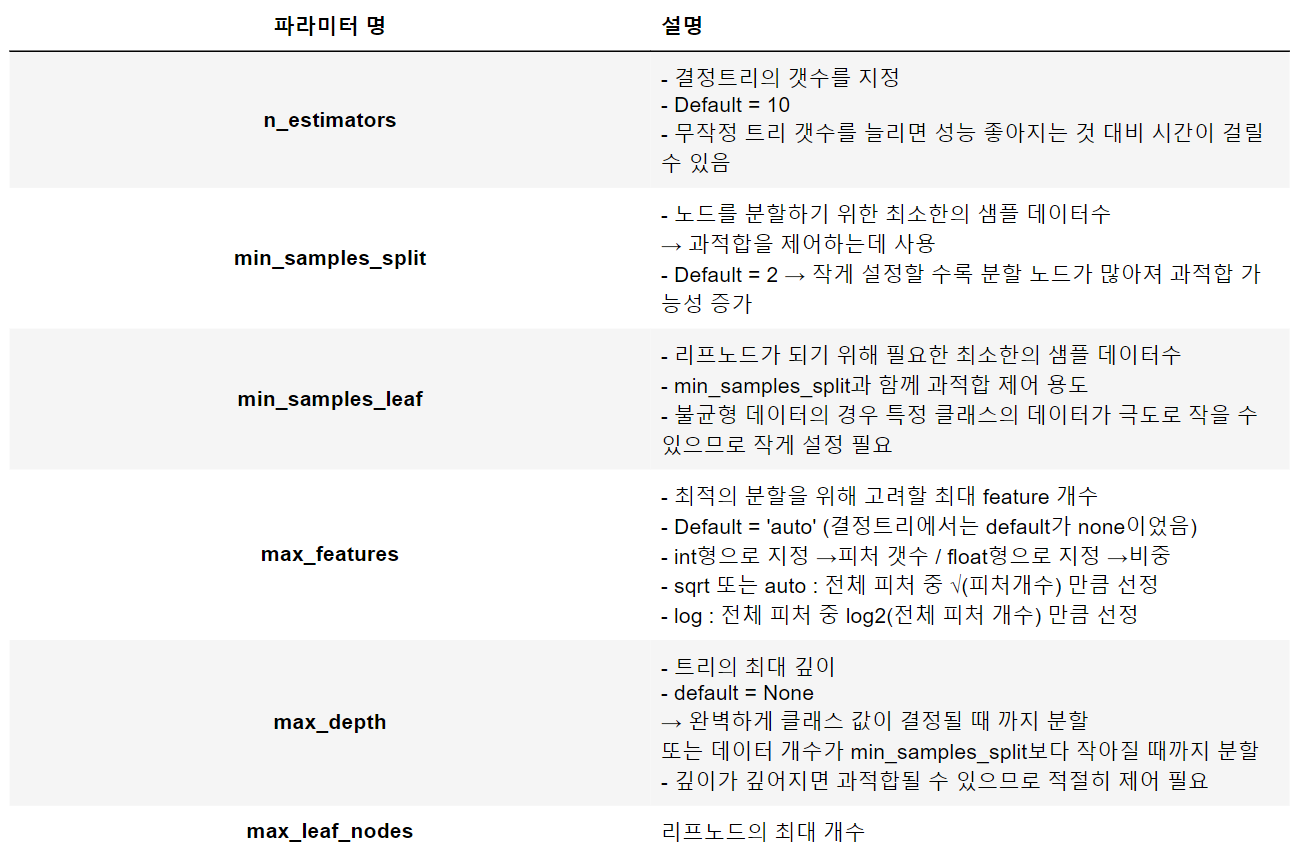
3. GridSearchCV (GridSearch + CrossValidation)
GridSearch란?
- 사용자가 직접 모델의 하이퍼 파라미터 값을 리스트로 입력하면, 값에 대한 경우의 수마다 예측 성능을 측정 평가하여 비교하면서 최적의 하이퍼 파라미터 값을 찾는 과정
- 즉, 파라미터 후보값들을 사전에 정의해주고, 이를 일일이 for문처럼 반복 적용해보는 걸 대신해주는 것임
- 추가적으로 교차 검증까지 수행해줌
CrossValidation
-
머신러닝 모델을 test 데이터로 검증하기 전에 모델의 성능을 중간 점검하는 방법
-
K-fold
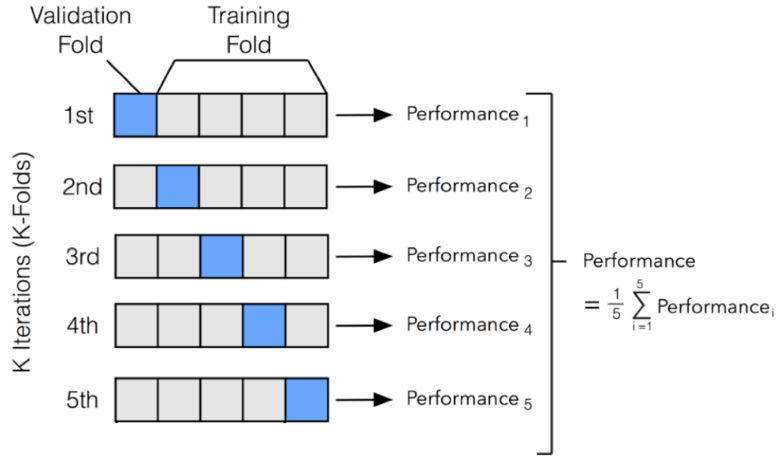
-
이때, fold = 파란색 박스
💡 if) fold 개수(K값)을 5로 설정하면, 위 그림처럼 5번의 모델링 검증 시행함 -
1번 검증을 시행할 떄마다 검증용 데이터가 각각 파란색 박스로 매번 달라짐
-
5번의 교차검증이 종료된 후, 각 검증마다 도출된 정확도들의 평균값으로 최종 정확도 계산함
4. Feature Importance
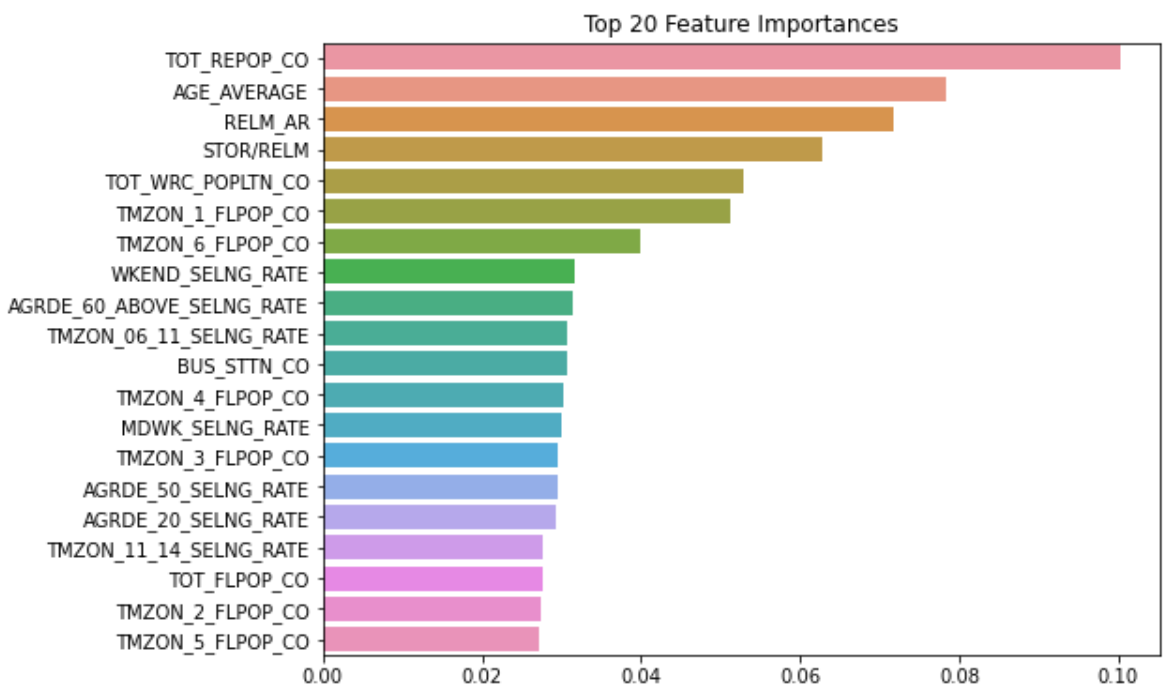
- Scikit-learn에선 지니 중요도(Gini Importance)를 이용해서 각 feature의 중요도 측정함
- 해당 노드에 샘플들이 이질적으로 구성돼 있을수록
즉, 모든 클래스에 골고루 분포돼 있을수록 지니불순도는 높아짐 - Decision Tree는 불순도를 감소시키는 방향으로 노드를 생성하고 분류를 진행함

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌