EDA
Pandas 데이터 처리
titanic data
데이터 불러오기 + 기본
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#지도 : follium
#3D : plotly
#re, datetime ...
path = '/content/titanic_train.csv'
data = pd.read_csv(path, index_col = "PassengerId")
data.head()조건에 대한 필터링
# 값의 조건 (글자, 숫자)
data[(data["Embarked"]=="C") & (data["Fare"]>200) ] #Embarked "C"이고, Fare 200 이상
# Age의 결측치 데이터만 얻기
data[data['Age'].isnull()]
# 모든 col의 결측치 비율 얻기
for col in data.columns :
print(col,":", len(data[data[col].isnull()])/len(data))
# Age의 범위에 따라 구분하기
# 2분법적으로 접근 apply+lambda+if~else~
data["Age"].apply(lambda x : 1 if x < 30 else (2 if x < 55 else 3))
# NaN가 3으로 처리될 수 있음에 유의
# Age 값을 변경 (함수)
def age_cat(age) :
if age < 30 :
return 1
elif age < 55 :
return 2
else :
return 3
data['Age'].apply(lambda x : age_cat(x))
#또는 list로 값 얻기 : [age_cat(age) for age in data['Age']]
#새로운 컬럼에 할당
data['Age_new'] = data["Age"].apply(lambda x : 1 if x < 30 else (2 if x < 55 else 3))
data
#구분한 컬럼의 값의 종류와 개수 : value_counts()
data['Age_new'].value_counts()
#비율
data['Age_new'].value_counts(normalize=True)데이터 핸들링 + 시각화
#남/녀
data["Sex"].value_counts().plot(kind ="bar")
# kinds: ('line', 'bar', 'barh', 'kde', 'density', 'area', 'hist', 'box', 'pie', 'scatter', 'hexbin')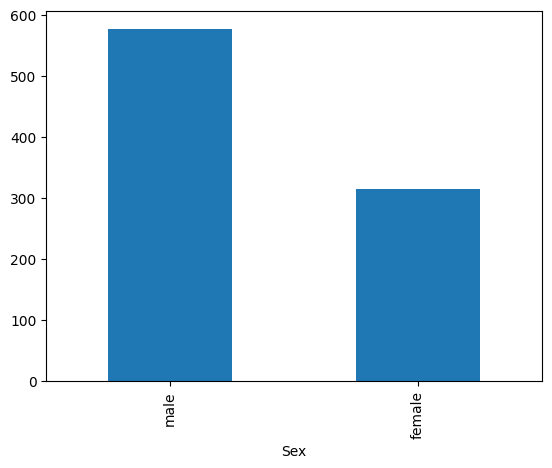
# pivot_table, groupby
# ==> 기존의 자료를 모양을 변경 + 집계 처리
# ==> 대표적으로 많이 사용되는 기능 : 카운팅 crosstab
pd.crosstab(data["Pclass"], data["Sex"])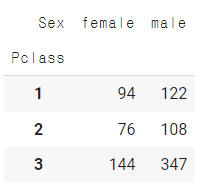
# boxplot
sns.boxplot( x=data["Survived"], y=data["Age"])
sns.boxplot(data=data, x="Survived", y="Age")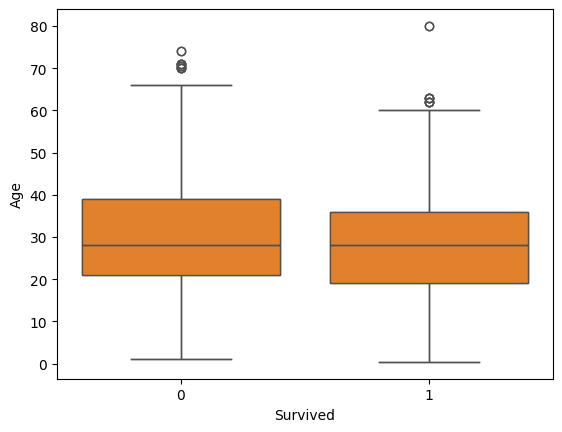
fig, axes = plt.subplots( nrows=1, ncols=2)
sns.boxplot(data=data, y="Fare", x="Pclass", ax=axes[0])
#boxplot에서 아웃라이어 때문에 정확한 데이터 분석이 어려움 -> 상위 5프로를 제외한 데이터로 다시 분석
sns.boxplot( data=data[ data["Fare"] < data["Fare"].quantile(0.95)],
x="Pclass",y="Fare", ax=axes[1])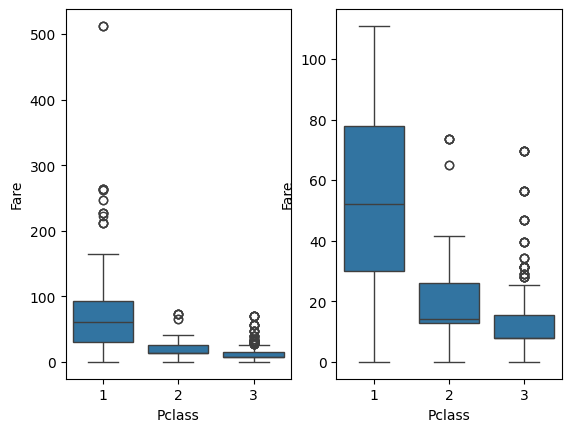
# countplot
# 객실 별 승객 수 : 생존여부에 따라
sns.countplot( data=data, x="Pclass",
hue="Survived")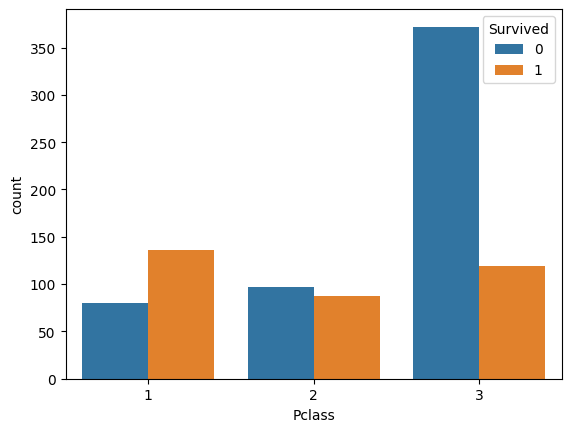
#두 그래프를 한번에 그리기
# 1) 전체 판을 세팅
fig, axes = plt.subplots( nrows=1, ncols=2)
# 2) 왼쪽 그래프 설정 : pandas --> plot
data["Pclass"].value_counts().plot(kind="barh", color="g", ax=axes[0])
axes[0].set_xlabel("Pclass Count")
# 3) 오른쪽 그래프 설정 : seaborn --> countplot
sns.countplot(data=data, x="Pclass", hue="Survived", ax=axes[1])
axes[1].set_xlabel("Pclass vs Survived")
# 4) 판 정리
fig.tight_layout()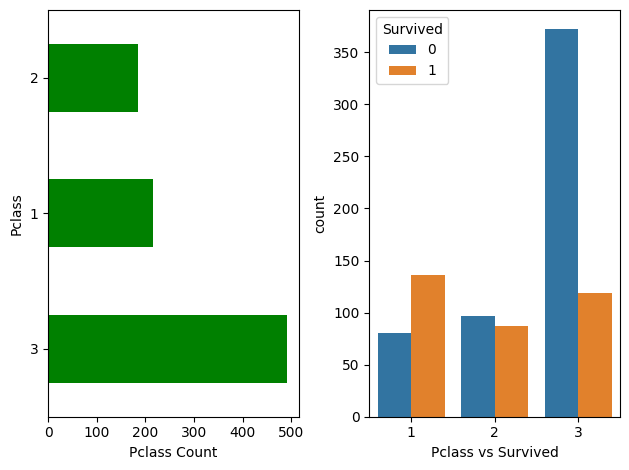
GPT 이용
colab으로 돌아가게 세팅
!pip install langchain
!pip install openai
!pip install langchain-experimental
!pip install --upgrade pip
!pip install "langserve[all]"
!pip install langchain-cli
!pip install -U langchain-openai
from getpass import getpass
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_openai import OpenAI
from langchain.llms import OpenAI
agent = create_pandas_dataframe_agent(OpenAI(temperature=0, openai_api_key=openai_api_key),df, verbose=True,allow_dangerous_code=True)
openai = OpenAI(temperature=0.0, openai_api_key=openai_api_key)
q_text = "객실 등급에 따라서 생존율에 대한 그래프를 그려주세요"
agent(q_text)비정형 데이터를 정형 데이터로 변환하기 용이함!
