문자열 검색 알고리즘, KMP 알고리즘에 대해서 설명을 시작합니다~!
시작하기 전에 다들 백준이나 프로그래머스에서 알고리즘 문제을 풀 때 한번쯤은 문자열 검색 문제를 마주했을거라고 예상합니다. 효율성을 따지지 않고 간단하게 생각해본다면 이렇게 생각할 수 있습니다.
"ABCDEF"에서 "ABC"를 찾자.
라는 예제를 가져와봤는데요. 간단히 생각해서 풀어보면


이렇게 "ABC"를 한글자씩 옮겨가며 비교를 하게됩니다.
하지만 효율성을 따지지 않았기 때문에 비교해야하는 대상이 10만개, 수만개가 되면 타임오버가됩니다. 이런 현상을 방지하게 만든 알고리즘이 바로 KMP 알고리즘 입니다.
잠시만요! 알고리즘에 대해서 알아보기 전에 사전지식이 필요합니다.
1. 접두사와 접미사
첫번째로 접두사와 접미사를 알아야합니다. 예시를 통해서 쉽게 알려드리겠습니다.
Banana를 예시로 들어보겠습니다.
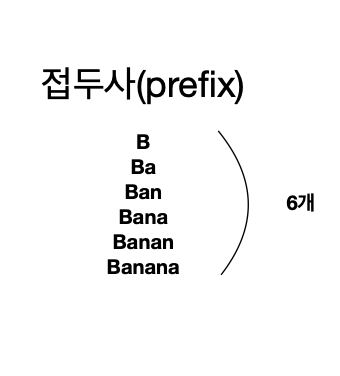
Banana의 접두사(prefix)는 앞에서부터 차례대로의 부분문자열이라고 생각하면됩니다.
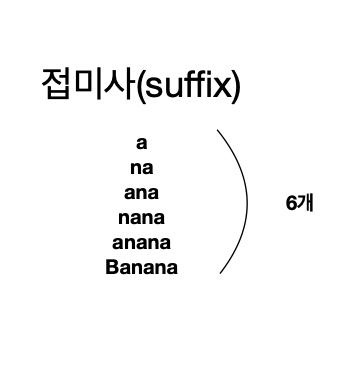
Banana의 접미사(suffix)는 뒤에서부터 차례대로의 부분문자열이라고 생각하면됩니다.
2. pi 배열
: pi[i]는 주어진 문자열의 0~i까지의 부분 문자열 중에서 prefix == suffix가 될 수 있는 부분문자열 중에서 가장 긴 것의 길이
예시를 통해서 이해하기 쉽게 설명해드리겠습니다.
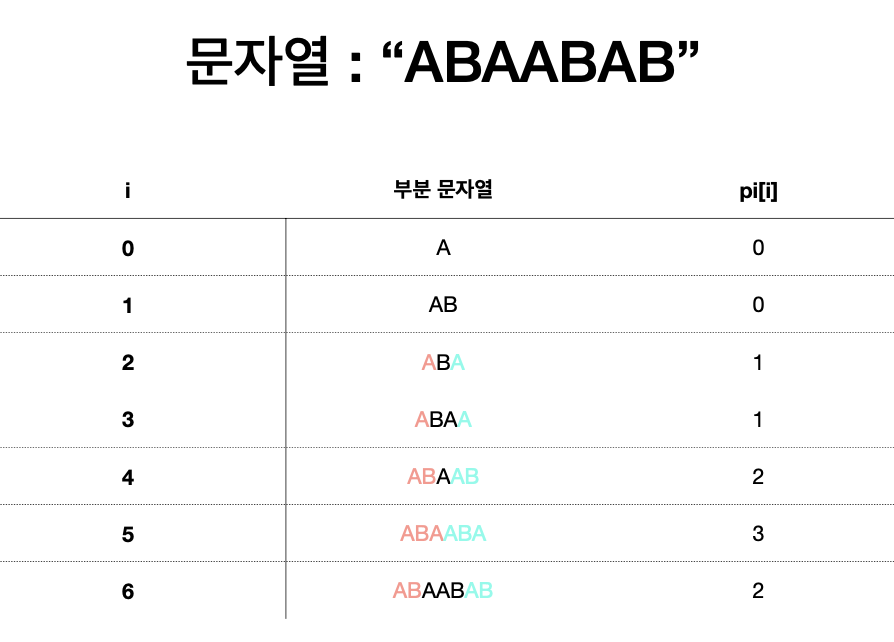
pi[5] = 3 일 때 가장 길다는 것을 알 수 있습니다.
결론은 매칭되는 길이마다 접두사와 접미사가 같은 부분 문자열을 찾아서 그 길이 중 가장 긴 길이를 구하면 어디서부터 탐색할지 정할 수 있습니다.
이제 본격적으로 알아볼까요??
KMP 알고리즘
- 원리
처음 비요할 때, 일치했던 부분문자열의 정보를 이용하여 불필요한 비교 즉, 어차피 틀릴걸 아는 부분은 건너뛰어버리는 원리 - 순서
- 비교할 대상과 찾으려는 패턴은 둔다
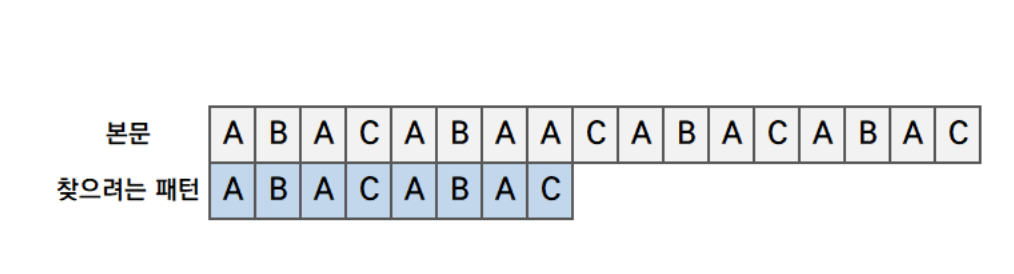
- 일부가 일치하지 않은 경우, 불일치한 부분을 제외한 부분을 찾습니다.
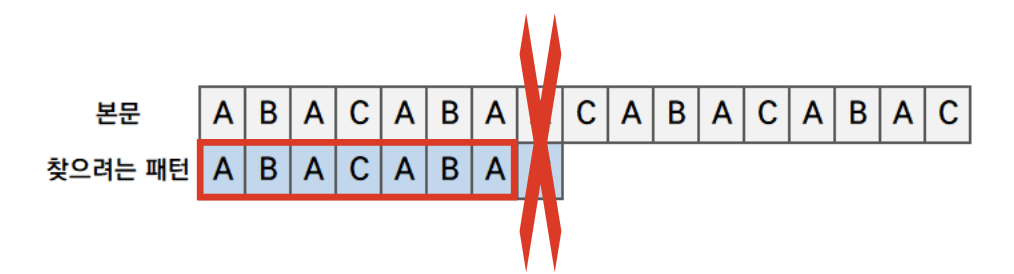
빨간 테두리로 감싸져있는 박스가 바로 일치한 부분만 찾은 것입니다.
- 불일치한 부분을 제외한 직전까지 일치하는 패턴에서 최대 길이의 경계를 찾는다. 경계에서 접두사, 접미사를 파악합니다.
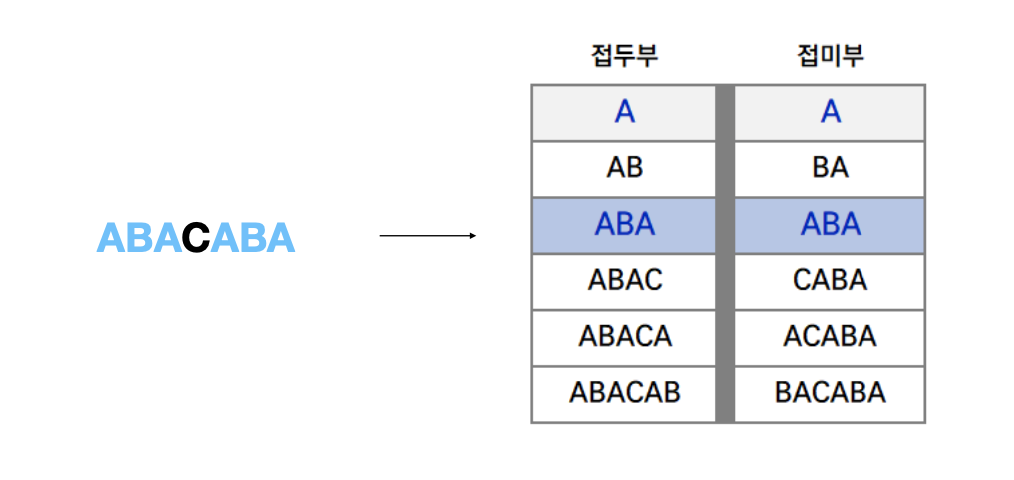
아까 빨간 테두리로 표시되어있던 부분에 있던 문자열이 "ABACABA" 이기 때문에 pi 배열을 이용해서 접두사와 접미사를 파악할 수 있습니다.
- 찾으려는 패턴을 접미사의 시작열까지 이동합니다.
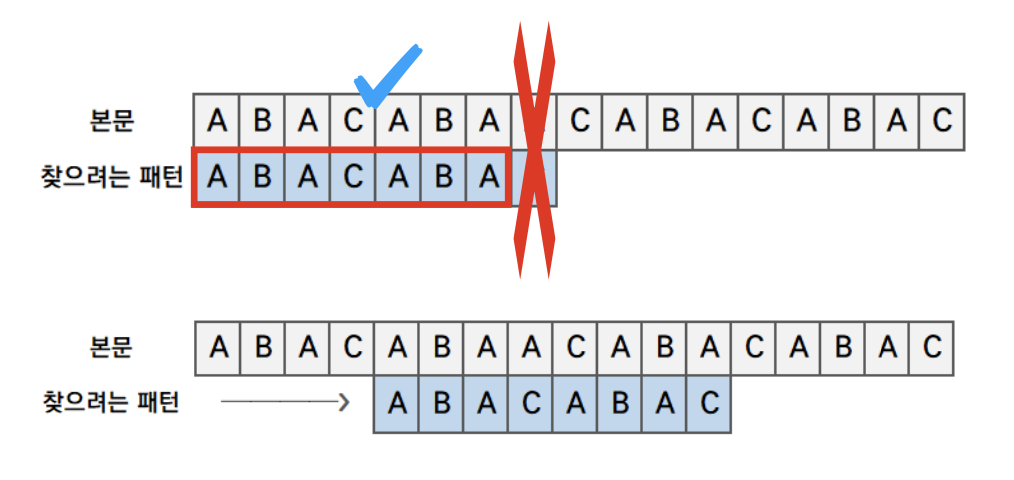
아까 정했던 접미부의 시작은 뒤에있는 ABA이기 때문에 시작은 A부터입니다.그래서 불필요한 비교를 하지 않게 됩니다.
- 결론
조금이라도 일치했었다는 정보에 주목하고 미리 전처리해둔 pi 배열을 이용해서 많은 중간시도를 건너 뛸 수 있게 한다. + 시간 복잡도가 효율적으로 ~~~

iOS developer