
운영체제 수업 + Operating System Concepts 10E 정리 내용
Operating System Ch01 : Introduction
Chapter Objectives
- Describe the general organization of a computer system and the role of interrupts.
- Describe the components in a modern multiprocessor computer system.
- Illustrate the transition from user mode to kernel mode.
- Discuss how operating systems are used in various computing environments.
- Provide examples of free and open-source operating systems.
1. What is Computer?
- CPU와 메모리를 가진(bus로 연결된) 하드웨어 위에 소프트웨어를 돌릴 수 있는 모든 것
- Computer 종류
- Embeded Computer
- 특정 목적을 위해 설계된 SW를 가진다.
- 하드웨어적으로 제한된 능력을 가진다.
ex) 스마트폰, 게임기, 키오스크...
- Personal Computer
- general purpose
- Server Computer
- 매우 고성능
ex) 기상청 컴퓨터..
- Computer System Components
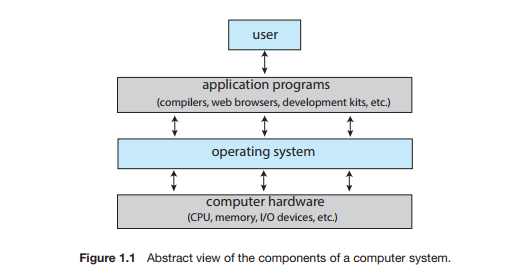
- Operating system은 hardware와 user간의 연결을 해주는 역할
-> 우리가 hardware의 모든 것을 알지 못하더라도 일을 하면 OS가 hardware 처리를 알아서 해줌 - 위 그림에서 User는 개발자를 말한다.(사용자가 아님)
-> User : Frontend 개발자
-> application programs : Backend 개발자
-> Operating system : System 개발자
- Operating system은 hardware와 user간의 연결을 해주는 역할
An operating system is similar to a government. Like a government, it performs no useful function by itself. It simply provides an environment within which other programs can do useful work.
Operating systems exist because they offer a reasonable way to solve the problem of creating a usable computing system.
The operating system includes the always-running kernel, middleware frameworks that ease application development and provide features, and system programs that aid in managing the system while it is running.
- Computer system Organization

- 위 그림에서 CPU와 Memory를 뺀 것들은 모두 I/O 장치
- Modern PC architecture
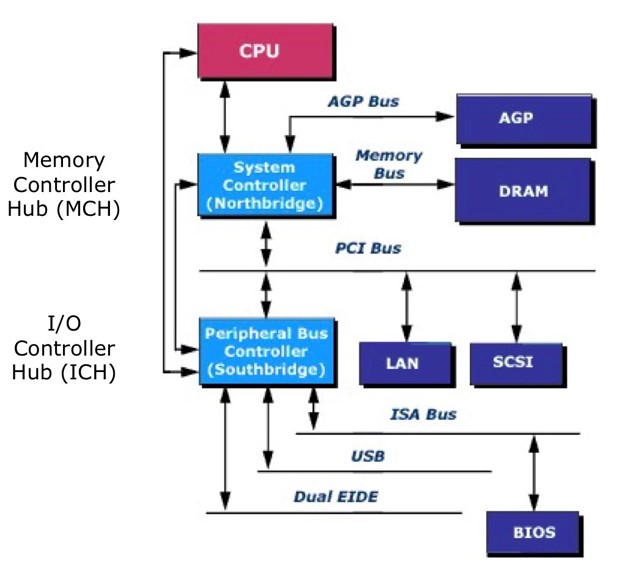
- 현재 컴퓨터는 System controller와 Peripheral Bus Controller가 한개로 이루어져있다.
- Memory Controller Hub : 빠르고 대역폭이 큰 작업
-> AGP는 그래픽카드를 뜻한다.
그래픽 카드는 화면 한 픽셀당 매우 많은 작업(RGB x 해상도 x 주사율)이 필요하기 때문에 I/O 장치임에도 불구하고 Memory Controller Hub 쪽에 위치한다. - I/O Controller Hub : 상대적으로 느린 작업
2. What is Operating Systems?
- OS의 목적 : OS is a resource(hardware) manager
- Abstraction : hardware를 깊이 알지 못해도 User가 사용할 수 있게 해줌
- Sharing(Time multiplexing, Space multiplexing) : CPU는 한번에 하나의 일을 할 수 있지만, OS가 관리하에 동시에 여러가지 일을 하는 것처럼 도와줌
- Protection : 잘못된 메모리 주소의 접근을 방지해줌
- Fairness and Performance
- OS란..
- Resource allocator
- Control program
- Kernel
- 요약하자면..
- OS is software which manages computer hardware resources for convenience & efficiency
9/1 수업 + 책(~p 35)
3. Computer System Operation
- Computer Hardware Architecture

- ALU(Arithmetic Logical Unit) : 산술연산과 논리연산을 담당하는 부분
- CU(Control Unit) : 프로세서의 조작을 지시하는 부분, 명령들을 읽고 해석하는 역할, 전체 프로그램의 흐름을 제어
-> ALU와 CU가 CPU의 대부분의 연산을 차지한다. - MMU(Memory Management Unit) : CPU가 메모리에 접근하는 것을 관리하며, 빠른 처리를 위해서 존재한다.
- Register (아래의 구조들은 모두 register 종류이다.)
- PC(Program Counter) : 현재 실행해야 할 명령어의 주소를 가지는 레지스터
- IR(Instruction Register) : 명령어를 가져와서 저장해두는 역할을 하는 레지스터
- SP(Stack Pointer) : 프로세스를 스택으로 관리한다.
- PSW(Process Status Word) : 현재 Process의 상태를 알려주는 역할
- Gerneral purpose register : 연산 수행시 필요한 범용 데이터를 저장하는 레지스터, I/O device를 control 하기 위한 정보 저장
- Memory Structure
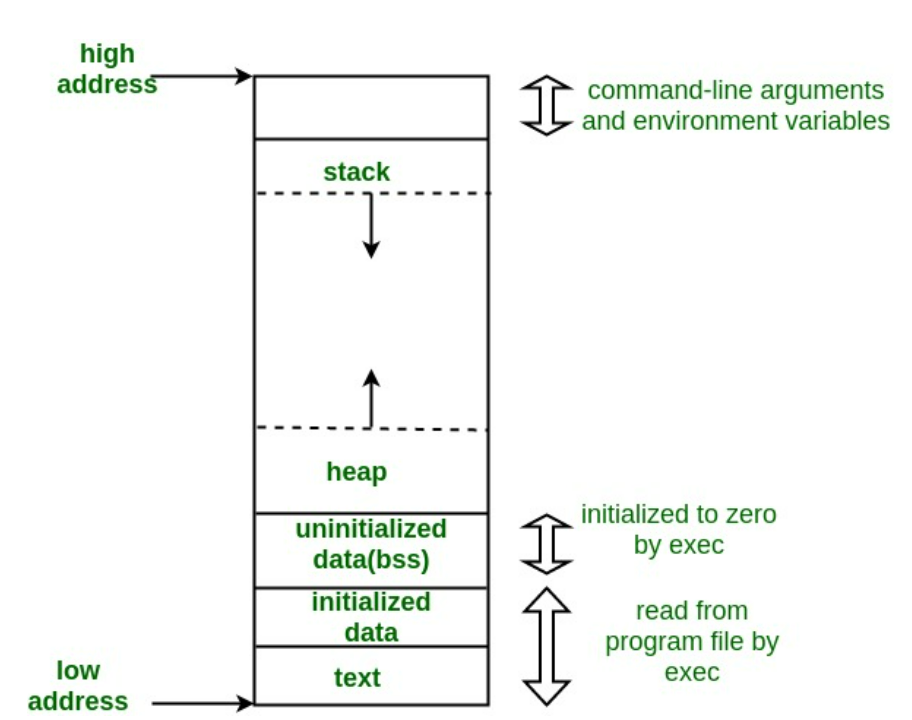
- low address(0x00000000), high address(0xffffffff)
- command line arguments : 실행하게 되는 코드들의 덩어리 code segmentation 이 존재하는 곳이다.
- initialized data : 초기값이 있는 전역변수, static 변수, 정적 배열, 구조체 등
- uninitialized data(bss) : bss(Block Started bt Symbol), 전역으로 초기화되지 않은 영역
- heap : 동적 할당되는 객체
- stack : 지역변수, 매개변수, 리턴 값 등 임시로 사용하는 객체, 매개 변수와 리턴값은 함수 호출 시 생성, 함수 수행 종료시 반환
- Assembly code


- .global main : main 함수를 나타낸다.
- %ebp : 메모리 구조에서 code와 data 부분을 저장한(코드 실행 전에 이미 메모리를 차지하는 값들) 주소의 top값을 가리킨다.
- %esp, %ebp : %ebp의 값을 %esp로 옮겨준다.
- $8, %esp : main 함수에 int 값 두개 있으므로 8 byte를 확보한다. 그 후 top 주소값을 esp에 저장한다.
- $10, -4(%ebp) : 변수 a에 값을 대입하는 과정. 그 값은 top주소보다 아래로 4byte 만큼 떨어진 곳에 저장되어 있다.
- func : func 함수를 call 해준다.
- Process VS Program
- Program : 파일 시스템에 존재하는 실행 파일
- Process : 프로그램 실행전(실행 하면서) 메모리 공간에 코드와 같은 실행과정이 올라간 상태, 프로그램을 실행하게되면 CPU를 차지하면서 수행하는 그 행동 자체
- CPU operation
- Von Neumann architecture VS Harvard architecture
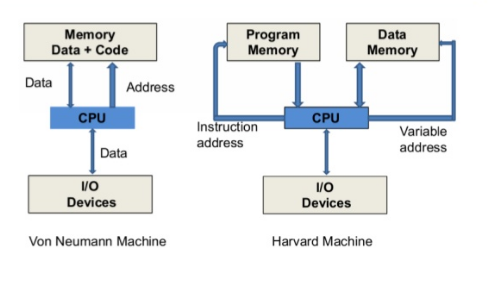
- Von Neumann architecture : Memory에 Code와 Data를 모두 넣어두고 CPU에서 가져와서 분류하여 사용하는 구조, 현재 사용되는 컴퓨터의 구조
- Harvard architecture : Memory의 Data와 Code를 미리 분류해서 두고 CPU에서 필요에 따라 골라서 사용하는 구조, 속도는 Von Neumann 보다 빠르지만, 하드웨어 구조가 너무 복잡해지기 때문에 실제로 사용하지는 않는다.
- Instructions
- Arithmetic instructions : add, subtract, multiply, divide...
- Logical instructions : and, or, xor, not, shift...
- Control flow instructions : goto, if, call, return...
-> 전체 프로그램의 흐름을 제어 - Data instructions : load & store & move (memory <-> CPU) / input & output (I/O device <-> CPU)
- Von Neumann architecture VS Harvard architecture
- Bootstrapping in Linux
-> 컴퓨터 실행시 동작하는 순서
1) CPU가 자기 자신을 초기화하고 스스로 문제가 있는지 checking
-> 문제가 없다면, 0xfffffff0 주소로 jump
2) BIOS(0xfffffff0 주소가 가리키는 곳)에서 CPU가 check하지 않은 hardware 관련 코드(memory나 IO 디바이스)를 실행하고 문제가 있는지 check 한다.(POST)
-> BIOS는 전기공급이 끊기더라도 동작해야 하므로 ROM이나 Flash Memory 등으로 저장한다.
-> UEFI(Unified Extensible Firmware Interface) : platform independent 한 BIOS (advanced BIOS)
3) BIOS는 Boot device를 찾고 Boot Loader를 실행한다.(OS가 메모리로 load)
-> Boot Loader는 OS의 시작, 끝 주소와 OS코드를 알고 있다.
-> 즉 Boot Loader를 실행하여 CPU의 사용 권한을 OS에게 넘겨주는 과정을 실행한다.
-> MBR(Master Boot Record): 가지고 있는 OS의 리스트를 모두 저장해둔 것
-> ESP(Efi System Partition): UEFI를 위한 MBR (advanced MBR)
4) LILO에게 권한을 넘겨주고 compressed kernel을 load한다.
5) 모든 일을 마치고 busy waiting에 들어간다.
9/6 수업
cf) 컴퓨터를 켜고 가만히 있어도 CPU는 계속 작동한다(IDLE 프로세스 실행)
IDLE 프로세스 : while문 무한루프로 구성되며, 연산은 하지 않는다.
-> busy waiting
-> IDLE 프로세스가 거의 99%를 차지한다.(아무것도 하지 않을때 CPU 점유율)
-> CPU 점유율은 IDLE 프로세스가 차지하는 비율로 계산한다.
- CPU
- ISA(Instruction Set Architecture)
- Instruction Set : 특정 CPU에서 실행시킬 수 있는 명령어들의 집합
- CISC(Complexed Instruction Set Computer) : 복잡
-> 복잡한 계산(느린 계산)을 하나의 instruction으로 만들어 버린 것
-> ex) 최소한의 instruction을 조합하여 근의 공식을 만드는 것이 아닌 하나의 instruction을 근의 공식을 위해 만드는 것
-> 속도는 빨라지지만 설계의 복잡도와 비용이 증가한다.
-> 한계는 존재하지만 CISC의 형태로 CPU 가 진화를 해왔다.
-> 사용 예시) x86 컴퓨터 (구버전에 대한 호환성을 위해서 계속 사용중- intel) - RISC(Reduced Instruction Set Computer) : 간소화
-> RISC는 어려운 동작을 하기에 어렵지만 pipelining을 이용하여 개선하여 발전했다.
-> 각 과정들은 cpu가 독립적으로 작동한다.
-> RISC 방식은 명령어 하나하나가 SISC보다 빨리 끝나므로 pipelining 적합하다.
-> RISC가 pipelining을 해서 성능을 올리려면 cache가 필요하게 되므로 비싼 작업이 된다.(1% 성능 상승 -> cache 10% 상승)
-> 사용 예시) ARM, ATMEL, Embeded용 컴퓨터
- CISC(Complexed Instruction Set Computer) : 복잡
- pipelining
- fetch -> decode -> execution -> write back
- 하나의 명령어가 실행되는 도중에 다른 명령어 실행을 시작하는 식으로 동시에 여러개의 명령어를 실행하는 방식
- IR(register)에 저장된 instruction을 cpu가 실행하도록 재생성->실행->연산을 수행하여 생긴 output을 사용
=> 위 방식으로 그림처럼 네가지가 독립적으로 수행(최대 4배의 속도 향상) - 그러나 속도가 4배 향상되는 일은 거의 없다.(아래의 이유 때문)
-> 실행해야 하는 instruction의 실행시간의 차이가 있는 경우
-> 해당 일들이 종속성이 있는 경우
-> 분기문이 있는 경우
- Instruction-Level Parallelism
- Superscalar : 현재 실행되어야 하는 코드와 이후에 실행되어야 하는 코드를 cpu가 계속 보고 동시에 실행해도 될 것 같은 것들을 동시에 실행하기
- VLIW : 컴파일러가 parallel 한 것을 골라서 실행
-> multi-thread, multi-core로 발전함
-
Multi-core architecture
- cpu코어를 둘러싸는 큰 cpu가 존재

- cpu코어를 둘러싸는 큰 cpu가 존재
-
Symmetric multiprocessing architecture
- 하나의 큰 cpu로 둘러싸여 있지 않다.
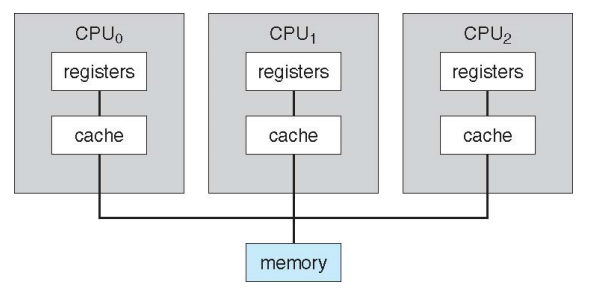
cf) NUMA : cpu마다 메모리가 달려있고 네트워크로 연결
-> 연산을 나눠서 진행하기에 적합 ex) 기상청 컴퓨터

- 하나의 큰 cpu로 둘러싸여 있지 않다.
-
Clustered system architecture
- clustered system : disk를 공유하는 컴퓨터가 네트워크로 연결된 구조
- Parallel VS Distributed
- Parallel : 하나의 컴퓨터 안에 여러 메모리가 존재
- Distributed : 완전한 하나의 컴퓨터가 여러개 존재하고 그 컴퓨터들이 네트워크로 연결된 상태
- I/O operation
- I/O : cpu로 인해서 동작하게 된다.
-> I/O는 cpu와 직접적으로 연결되는 것이 아닌 중간에 매개체 존재 - Direct I/O : 레지스터 번호당 어떤 장치와 연결되어있는지 말해주고 명령하기(빠르지만 데이터양이 커지면 문제 발생)
- Memory-mapped I/O : 레지스터 대신에 메모리 공간에 I/O 컨트롤러를 맵핑
-> I/O 장치의 양이 많아질 때 유용하다(레지스터 수는 제한되어있지만, 메모리는 레지스터보다는 더 크다) - I/O 입력을 처리하는 방법
1) Programmed IO : polling 이용
-> polling : 일정 시간마다 계속 끝났는지 물어보면서 확인(통신에서 많이 사용)
2) interrupt : I/O장치가 할일을 다하고 끝나면 코드, 신호로 알려줌
3) DMA(Direct Memory Access) : 용량이 큰 I/O가 실행될 때 메모리에서 cpu를 거치지 않고 바로 디스크로 보내는 역할(반대 방향도 ok)
-> 성능 향상(기존의 방식은 작은 부분으로 쪼개서 정보를 보내고 interrupt가 발생하는 것이 반복되는 구조이므로, 큰 io정보를 가져오려면 interrupt가 너무 많이 발생한다.)
-> ex) 용량이 큰 동영상 다운로드
- I/O : cpu로 인해서 동작하게 된다.
-
Interrupt-driven I/O cycle
- cpu에서 device driver 초기화
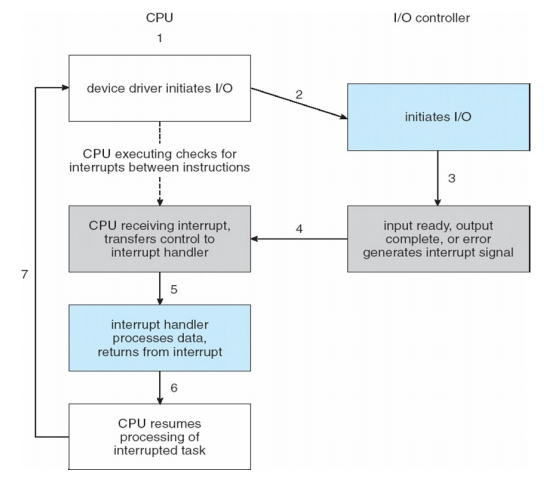
- cpu에서 device driver 초기화
-
I/O mode from the perspective of application process
- Synchronous/ Blocking : I/O가 다 끝나고 오면 다음 일 실행
- Asynchronous/ Non-blocking : 일이 끝나지 않아도 다음 일 진행
-> 자동 저장되는 순간에도 수정하는 경우
-> 게임시작시 중요데이터만 먼저 받아두고 부가적인 데이터는 게임 실행하면서 다운로드 하는 경우
-
Interrupt : cpu가 하는 것을 멈추고 interrupt가 오면 해당 일을 먼저 진행한다.
-> Asynchronous -
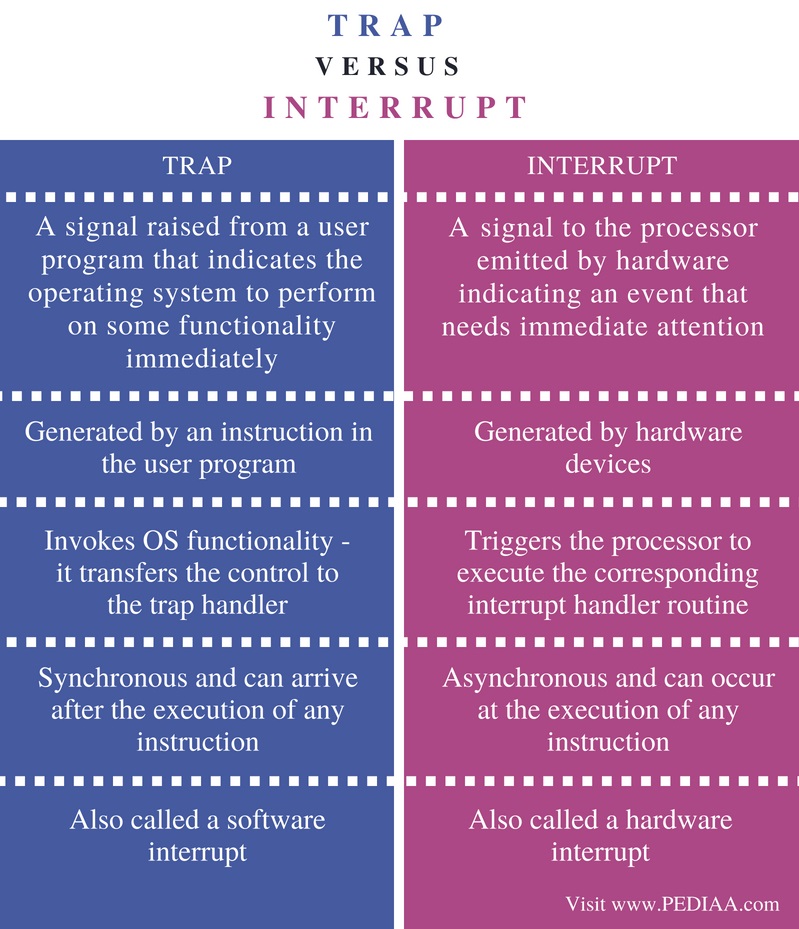
Trap : application process로 인해 생성, 일반 sw가 os에게 io 요청을 하는 경우 (system call이 발생하면 I/O 디바이스에게 명령을 내린다.)
-> synchronous
-
Fault : CPU instruction으로 인해 생성, cpu가 할 줄 모르는 것에 대한 요청이 오는 경우 (예외사항이 생길때 스스로에게 interrupt 실행)
-> synchronous
-> ex) 0으로 나누기, 잘못된 메모리 접근 등
- Hardware interrupt vs Software interrupt
- Hardware interrupt : Interrupt
- Software interrupt : Trap, Fault

9/8 수업
- Six steps process to perform DMA transfer
- DMA : 용량이 큰 disk
- io의 bottle neck 현상을 막아준다.
- os가 interrupt에게 권한을 넘겨주고, DMA가 다 실행하면 이후에 DMA가 interrupt를 준다.

- Storage hierachy

- 메모리 계층구조에서 위로 올라갈수록 빠르지만 비싸다
- ROM (Read Only Memory) : 한번만 쓸 수 있고 지울 수 없다 / 전력공급이 끊겨도 사용 가능하다 / 빠르다(BIOS, Bootloader)
- RAM (Random Access Memory) : 썻다 지웠다 가능하다 / 전기 공급이 끊기면 정보가 사라진다 / 속도는 ROM보다 조금 느리다
- SRAM (Static RAM) : 데이터를 한번 기입한 후 전기
공급만 있으면 data 뭉게지지 않음 / 매우 빠름 (register, hash memory) / refresh 하지 않음 - DRAM (Dynamic RAM) : refresh해주지 않으면 data가 뭉개진다 / refresh 하는 동안 access가 불가능하므로 느리다 / 싸다(main memory)
- Memory hierachy
- 프로그램은 전기신호가 없어도 사라지면 안된다.
- SSD에서 main memory로 올리는 시간 필요
-> 똑같은 프로그램을 다시 실행한다면 남아있는 데이터를 이용하여 이전보다 빨리 올릴 수 있다. - Caching : 최근에 사용된 데이터 중에서 다시 한 번 사용될 수 있는 확률이 높은 경우 사용하여 빠르게 데이터를 올릴 수 있다. 통계적으로 최근에 실행된 데이터는 빠른 미래에 다시 사용될 가능성이 높다.
cf) 메모리는 지우는 개념이 없고 덮어쓰는 개념이다. (사용한지 오래된 부분부터 덮어쓴다) - Cache coherency : 캐싱된 데이터들 중에서 기존의 데이터와 달라진 경우를 찾기 (바뀐 데이터가 있으면 이전 데이터들도 다 바꿔준다)
방식1) write through : 바뀐 데이터가 있으면 바로 이전 데이터들도 다 바꿔줌 / 일관성은 좋지만 성능 과부화가 크다.
방식2) write back : cpu가 일을 할 때는 coherency 발생해도 무시한다 / coherency를 하지 않으면 일을 못하는 경우, cpu가 할 일을 다 한 경우에 이전까지 모아둔 데이터를 한번에 처리해준다 / 일관성은 조금 떨어지지만 성능이 좋다 (오늘날 cpu 작동 방식)
- HDD (Physical hard disk structure)
- arm이 platter 안으로 들어가서 head로 데이터를 확인한다.
- hdd가 느린 이유는 disk가 돌아가는 속도가 느린것이 아니고 arm이 움직이는 시간 때문에 느린 것이다.(arm seak time)
- 최대한 연속적으로 데이터를 저장하거나, 같은 깊이로 저장해서 arm이 움직임을 최소화 하는 것이 좋은 방법이다.

- SSD (Compact Flash card internals)
- Flash Controller가 있으면 ssd 없으면 usb
- Flash Controller 역할
-> 데이터를 저장하는 단위 block
-> 원하는 것만 하나하나 바꿀 수가 없다.
-> block의 수명이 있다.
-> Flash Controller의 주된 역할은 wear leveling / block이 하나만 마모되는 것을 방지해준다
9/13 수업
- System call
- user mode : cpu위에 우리가 실행하는 sw가 돌아가는 것
- kernel mode : system call을 프로그램에서 실행할 때
- dual mode operation ?? :
-> 현재 프로세스가 진행 중일 때 os가 cpu위로 올라오게 되면, 기존 프로세스는 이전 작업까지 저장해 둔다.
-> system call의 진행이 끝나면 interrupt가 들어오고 이전에 하던 프로세스를 진행한다.
- Hardware protection
- CPU protection : 작업을 공정하게 분배
- Memory protection : MMU, 잘못된 메모리 주소 접근 등을 방지
- I/O protection : os를 통해 io 디바이스를 사용하도록 강제 (운영체제만이 IO에게 명령을 내릴 수 있다.-Privileged)
- OS takes control of the system
OS가 cpu위로 올라와서 처리하는 세가지 경우
1) Bootstrapping : 컴퓨터 처음 실행시
2) System call or Trap
3) interrupt : io 처리
4. Computer History
- Computer History
- 1st Generation
- 진공관, 플러그판
- no OS, no Programming language, no Assembly language
- 2nd Generation
- 트랜지스터, mainframes (집적도 증가)
- Batch system : 특정 프로세스가 끝나기 전까지 어떤 프로세스나 os의 동작이 불가능
-> 한번에 하나만 실행가능
-> 프로세스 맨 위와 아래에만 연산작업이 있고, 가운데에는 io작업이 있는 경우 bottle neck이 매우 심함
- 3rd Generation
- ICs, Architectural advances
-> 이 시기에 만들어진 기능이 아직도 사용된다. - Multiprogramming systems : os의 동작과 여러개의 프로세스를 왔다갔다하면서 실행하는 것
- Time-sharing systems : fairness, response time
- ICs, Architectural advances
- 4th Generation
- Architectural advances : microprocessor, PC
- Modern OS system : GUI
- 1st Generation
5. Computing Environments
- Traditional Computing
- Mainframe system : 정통적인 발전 과정을 따라온 모든 컴퓨터 시스템
- Desktop system
- Mobile Computing
- hard-held system
- Real-time embedded computing
-> real-time : 특정 시간안에 원하는 작업이 끝나는 것을 보장해주는 시스템- hard real time : 시간을 지키는 것을 무조건적으로 맞춰야 한다.(ex) 원전 시스템
- soft real time : 시간을 지켜야 하지만 hard real time 만큼의 중요도는 없다. (ex) 유튜브 스트리밍
- Client-server computing
- Clustered system : Parallel + Distributed + Storage
- Peer-to-Peer Computing
- client가 동등한 위치에서 데이터를 주고받음
- sensor network : ad-hoc network
- Cloud Computing
- Cloud : 컴퓨터 여러개가 연결되어있는 것을 말한다.
- Cloud system : 복잡한 연산은 클라우드에서 진행하고, 연산 결과를 주는 시스템
- IaaS : 필요한 cpu, 메모리 등을 줌
- PaaS : 원하는 플랫폼 까지 줌 (ex) AWS
- SaaS : 원하는 것 다해줌 (ex) Google
- 추가내용 (새로운 컴퓨팅 기술의 발전)
- 사물 인터넷 : 모든 things에 컴퓨팅 기술이 있고 네트워크로 연결된 것
-> 데이터를 많이 수집할 수 있다.(데이터 수집 인프라를 구축) - 빅 데이터 : 연산하려면 매우 큰 능력이 필요하다.
-> 일반적인 컴퓨터의 경우 연산을 진행해봤자 10% 미만을 사용한다.
-> 남는 컴퓨터 자원을 모아서 써보기(가상화)
-> 따로 따로 존재하는 남는 컴퓨터 자원을 모아서 하나로 구성 후 필요할 때 나눠주기(클라우드) - AI : 사물 인터넷, 빅 데이터, 클라우드, deep learning 등을 통해 얻은 가장 의미있는 결과물
-> 이전에는 해당 계산을 하기에는 컴퓨팅 파워가 매우 부족했다
-> 클라우드 컴퓨팅을 하더라도 컴퓨터 자원이 남는다.
-> deep learning이 발전
- 사물 인터넷 : 모든 things에 컴퓨팅 기술이 있고 네트워크로 연결된 것
- Virtualization
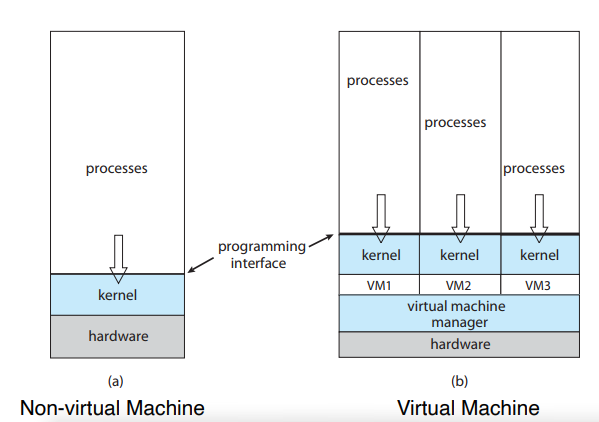
- Distributed Computing
- Collection of separate, possibly heterogeneous, systems networked together
6. OS History
- IBM OS/360
- MIT CTSS
- MIT, Bell Labs, GE, MULTICS
7. OS History : Unix(1985~1996)
- Unix :
-> Bell lab에서 만들기 시작
-> 개발을 위해 c언어도 개발(6th 부터 c언어로 개발)
-> 오픈소스 - BSD :
-> Unix를 가져와서 만든 것
-> 나중에 Linux에게 밀려서 망함 - Sun OS :
-> BSD에서 나온 가지 - System 5 :
-> Bell lab에서 나온 사람이 만든것
-> 계속 발전함 - XENIX :
-> 정통 Unix의 발전 계보를 따라감 - NeXT step :
-> 스티브 잡스가 애플에서 나와서 발전
8. OS History : Unix(1997~)
- 종류
- Sun Solaris
- HP HP-UX
- IBM AIX
- Caldera (SCO) Unixware
- Compaq (Digital) Tru64
- SGI Irix
- Linux, FreeBSD, NetBSD
- Apple Mac OS X, etc.
-> 모두 유닉스 계열이지만 따로 개발해서 기준이 없었다.
-> POSIX : 유닉스 표준
9. OS History : Windows & Linux
10. OS History : Linux
11. OS History : Taxonomy
- VxWorks :
-> 항공기용 OS
-> 매우 안정성이 높다(비쌈)
9/15 수업
