
운영체제 수업 + Operating System Concepts 10E 정리 내용
Operating System Ch05 : CPU Scheduling
Process Execution
1. CPU Scheduling
- ready queue에 올라간 것들 중에서 어떤 것을 실행할 것인가를 결정
2. Alternating sequence
- process에서 CPU burst 와 IO burst가 번갈아서 실행한다.
- CPU burst : CPU 가 연산을 하는 시간
- load store
- add store
- read from file
- IO burst : IO요청이 들어와서 끝나기를 기다리는 시간
3. CPU burst vs IO burst
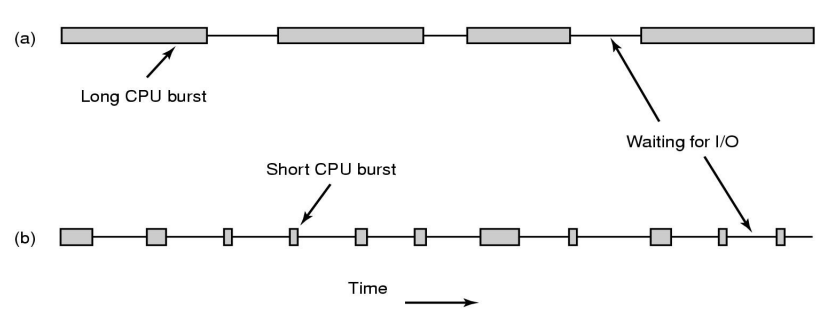
- CPU bound-process (a)
- CPU burst가 긴 process
- 사용자와의 interaction이 적다. -> 사용자 입장에서 크게 중요하지 않음
- IO bound-process (b)
- IO burst가 긴 process
- 사용자의 interact가 많은 process -> 일상생활의 대부분의 process
- 사용자 입장에서 중요하다.
Dispatcher
1. Dispatch
- 다음으로 실행할 process에 대하여 PCB에 넣어둔 정보를 복구하는 작업
- 이 과정을 진행하는 동안 dispatch latency가 걸린다.
- context switching하는 동안의 overhead 원인 중의 하나
2. Dispatch latency

Preemptive vs Non-Preemptive
OS의 ready queue에 새로 들어온 것의 우선순위가 현재 실행되는 process보다 우선순위가 높을 때 어떤 처리를 할 것인가에 대한 내용
1. Non-Preemptive
- 현재 하던 process를 마저 끝내고 새롭게 들어온 process를 실행
- 예전에 쓰던 방식
- cf) 현실세계 (우리의 삶)에서 자연스러운 방식
2. Preemptive
- 즉시 현재 진행중인 process를 멈추고 새로 들어온 (우선순위가 빠른) process를 실행
- 현재 사용하는 방식
Scheduling Criteria
1. High CPU bound process
- CPU utilization : CPU가 놀지 않고 실행하도록 하는 비율
- Throughput : 정해진 시간 동안에 프로세스가 동작을 완료하는 수
- high CPU bound process는 높을수록 좋다.
2. High IO bound process
- Turnaround time : 특정 프로세스가 시작해서 종료될 때 까지의 시간, ready queue에서 기다린 시간 + CPU에서 실행하는 시간 + IO 시간
- Waiting time : ready queue에 들어가서 스케쥴링 될 때 까지의 시간
- Response time : 프로세스에 요청이 들어오고 나서 해당 요청에 대한 첫번째 응답이 오기 전까지의 시간
- high IO bound process는 짧을수록 좋다
3. 정리
- cpu bound process랑 io bound process는 동시에 실행되는 경우가 많지만 서로 양립할 수 없다.
- 둘 간의 성능을 최대화시킬 수 있는 방향으로 최적화한다.
- Optimization Criteria
- Max CPU utilization
- Max throughput
- Min turnaround time
- Min waiting time
- Min response time
Scheduling Goals
1. All Systems
- Fairness
- 다수의 프로세스 중에서 누락되지 않고 OS의 관리를 받는 것
- CPU 자원을 공정하게 씀
- Balance
- 프로세스를 balance하게 관리하는 것
- 최대한 바쁘게 작동할 수 있도록 관리
2. Batch Systems
- 빨리 끝내는 것이 가장 중요함
- kernel의 개입이 없다.
- Throughput : maximize jobs per hour
- Turnaround time : minimize time between submission and termination
- CPU utilization : keep the CPU busy all the time
3. Interactive Systems
- 시간 관리 중요
- Response time
- minimize average time spent on ready queue
- 사용자랑 인터렉트 많을 때 짧아야 한다.
- Waiting time : minimize average time spent on wait queue
- Proportionality
- meet users' expectations
- 유저가 원하는 우선순위를 따지는 것도 중요하다.
4. Real-time Systems
- time deadline이 있는 시스템
- Meeting deadlines : avoiding losing data
- Predictability : 특정 프로세스가 얼마나 지나야 끝나는지 예측
Scheduling Non-goals
1. Starvation
- process가 스케줄링 되지 않은 상태가 유지될 때
Scheduling Algorithms
- FCFS (First Come First Served)
- 가장 단순한 방식
- 먼저 들어온 것 먼저 실행
- SJF (Shortest Job First)
- 가장 이상적인 방식
- 가장 짧은 것 먼저 실행
- SRTF (Shortest Remaining Time First)
- real time system에서 사용
- dead line 까지 남은 시간이 짧은 것 (급한 것) 먼저 실행
- Priority
- Round Robin (RR)
- Multi-Level Queue
- Multi-Level Feedback Queue (MLFQ)
1. FCFS Scheduling (FIFO)
- First-Come, First-Served
- 일반적으로는 non-preemptive
- 기다리다 보면 언젠가는 process에 올라가기 때문에 starvation 발생 x
- Problems
- 평균적인 waiting 시간이 길어진다.
- io와 CPU bound 간의 문제 해결 불가능
- examples

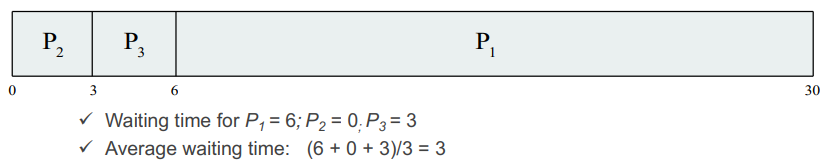
- process가 들어오는 순서에 따라 waiting time의 격차가 매우 심해진다.
- balance가 맞지 않는 문제가 발생한다.
- 해당 방식에서 개선하려면 수행시간이 짧은 것을 먼저 실행하는 방식으로 개선해야 한다.
2. SJF Scheduling
- Shortest Job First
- FCFS의 문제점을 해결하기 위해서 수행시간이 짧은 것을 우선으로 실행하자는 방식
- non-preemptive
- 이상적인 방식일 뿐 실제로 사용이 불가능하다. -> 실제로 어떤 process가 얼마나 수행할지에 대한 정보는 알 수 없기 때문에
- cf) optimal vs best
- optimal : 유일하지 않다, 좋은 것들 중 하나 (더 나은 것은 없다)
- best : 유일함
- Problems
- starvation이 일어날 가능성이 많다.
- 이상적인 방식일 뿐 실현 불가능하다.
- SRTF (Shortest Remaining Time First)
- Preemptive SJF 방식
- SJF examples

- SRTF examples ??

- SJF/SRTF Scheduling
- CPU burst time을 예측할 수 없기 때문에 문제가 발생한다.
- NP-HARD: CPU burst를 예측하는 경우 NP-HARD문제 발생 (답을 구할 수 없음)
3. Priority Scheduling
- 상황에 맞게끔 우선순위를 조정할 수 있다.
- 우선순위를 부여하고 해당 우선순위를 통해 높은 것을 먼저 스케줄링한다.
-> 우선순위를 따지는 것이 Priority scheduling의 문제 - 우선순위를 무엇으로 하느냐에 따라 다른 방식이 된다.
- arrival이 빠른 것을 먼저 스케줄링 한다면 FCFS 방식이 된다.
- SJF, SRTF 등도 될 수 있다.
- Problem
- Starvation이 발생하는 문제가 발생할 수 있다.
- 낮은 우선순위의 process는 계속 밀리게 된다.
- Aging
- starvation의 해결 방안으로 사용 가능하다.
- 낮은 우선순위의 process의 우선순위를 시간이 지날수록 조금씩 우선순위를 올려주는 방식
- aging 알고리즘이 적용되면 스케줄링 알고리즘이 복잡하게 되는 요인이 된다.
- ready queue를 여러개를 만들어서 우선순위에 따라 넣어두는 방식
- examples

4. Round Robin scheduling
- 각 프로세스가 time quantum을 가지는 형태
- time quantum이 끝나면 프로세스가 설정되고 ready queue의 끝에 추가된다.
- fair 하지만 응답성이 좋지 않다.
- time quantum이 크면 FIFO와 같은 방식
- time quantum을 짧게 해서 극복하지만 해당 경우에는 스케줄링 overhead가 발생한다.
- 적당한 time quantum을 결정하는 것이 중요하다.
- windows, mac : 10ms
- linux : 60ms
- examples

- RR Scheduling 방식
- quantum이 작을 수록 context switching 많아지고 즉 overhead가 된다.
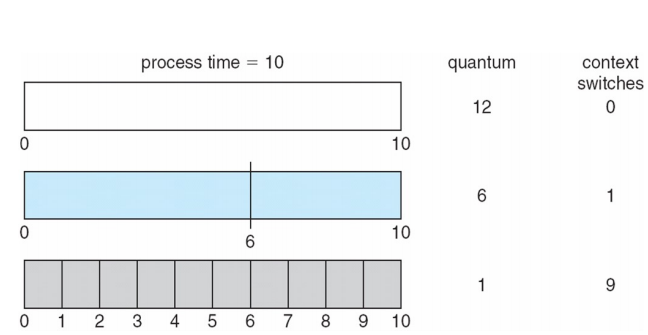
- Problem of RR
- 적당한 quantum을 찾는 것이 문제
- rule of thumb : CPU burst의 80%는 시간 퀀텀보다 짧아야 한다는 법칙 (개발자들이 통계를 통해 얻은 내용)
Combining Algorithms
- 이전까지의 스케줄링 알고리즘을 합치는 방식
- multiple queues
- pick a different algorithms for each queue
- have a mechanism to schedule among queues
- move process between queues
5. Multilevel Queue Scheduling
- ready queue의 종류를 두개로 나눔
- foreground: interactive, io burst, RR 알고리즘 사용
- background: batch, CPU burst, FCFS 방식
- starvation이 발생할 수 있다.
- foreground가 끝나야 background를 실행한다.
- Time Slice
- 각 queue는 CPU time을 나눠서 가진다.
- ex) 80% to foreground, 20% to background
- 단 해당 queue들의 우선순위는 개발자가 정하는 것이기 때문에 performance를 보장할 수 없다.
-> multilevel feedback queue 사용
6. Multilevel Feedback Queue Scheduling
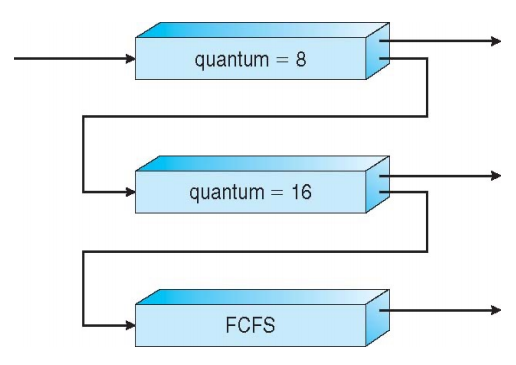
- 스케줄링 방식
- 8의 quantum을 다 쓰지 못하고 내려오는 것은 다시 quantum이 8인 queue에 넣는다.
- 8의 quantum을 다 쓰고 내려온 것은 높은 확률로 해당 quantum이 모자란 것이기 때문에(CPU bound process일 가능성 높음) quantum이 16인 queue로 넣는다.
- 16의 quantum도 다 채우고 내려오면 무조건 CPU bound process이므로 FCFS로 넣어서 처리한다.
- 스케줄링을 돌려보면서 CPU bound 인지를 확인하고 새롭게 분류해주는 방식
- canonical UNIX에서 실제로 사용하는 방식
- quantum을 다 쓰고 내려오면 우선순위가 낮은 곳으로 내려주고 quantum을 다 못쓰고 내려오면 우선순위가 높은 곳으로 올려준다.
- 정확한 우선순위를 가리는 것이 어렵기 때문에 직접 CPU bound에 가까운지 IO bound에 가까운지를 파악해서 적용하는 방식을 고안하게 된 것
7. Multiple-Processor Scheduling
- Symmetic VS Asymmetric
- Asymmetric : data 중심
- Symmetric : task 중심
- Symmetric의 두 가지 종류

- (a): 공통된 ready queue를 공유하는 방식 - soft affinity
-> 스케줄링 overhead가 적지만 캐싱이 매우 나쁘다.
-> 공유된 ready queue에서 경쟁 조건이 생길 수 있다.
-> 성능상 병목 현상이 생길 수 있다. - (b): 각 프로세스마다 자신만의 queue존재 - hard affinity
-> (a)의 성능상 문제 해결
-> 개발 복잡도가 높지만 캐싱 성능이 좋다.
-> 각각의 queue마다 부하의 양이 달라서 균형이 맞지 않을 수 있다.
- Load balancing : 노는 것 없이 모두가 공평하게 만드는 방식(migration)
- pull : 놀고있는 코어가 바쁜 코어의 process를 가져온다.
- push : 바쁜 코어의 process를 안바쁜 코어에게 준다.
- pull과 push는 개발자가 어떤것을 사용할지 결정한다.
8. Real-Time Scheduling
- dead line이 존재하는 scheduling
- hard real time and soft real time
- 중요하게 지켜야 하는 것 세가지
- burst time
- period
- dead line
- static priority scheduling
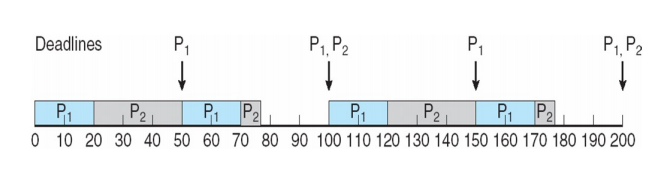
- Rate-Monotonic algorithms
- 주기가 짧은 process가 높은 우선순위를 가진다.
=> "우선순위 부여 알고리즘" - CPU 이용률 = 수행시간/주기
- 우선순위 고정, 주기 고정, deadline 고정
- dead line을 못지킨 경우
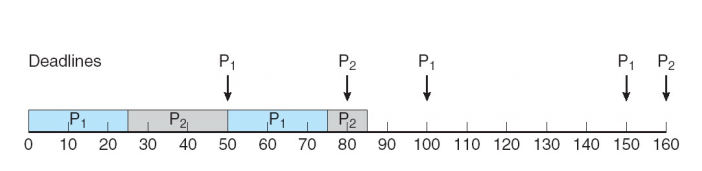
- 좋은 하드웨어를 써서 극복
- burst time을 줄이는 방향으로 코드 최적화 하기 (어려움)
- dynamic priority scheduling
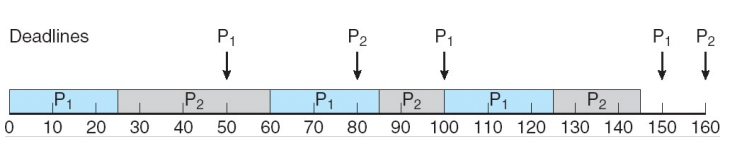
- EDF (Earlist Deadline First) algorithms
- deadline에 더 가까워질수록 우선순위를 높여주는 것 (주기가 데드라인)
=> "스케줄링 알고리즘" - 동적으로 수행해야 할 process의 데드라인을 계속 확인해서 우선순위를 바꿔준다.
- 성능적으로는 제일 좋지만 overhead가 크다.
- 실제로 embedded 환경에서 사용하려면 특정 목적을 위해 설계되고 하드웨어적으로 한계가 있기 때문에 static 방식을 사용한다.
Operating System Examples
1. Linux Scheduling
- Real-time scheduling according to POSIX.1b
- static 방식
- real-time과 normal map방식
- 같은 우선순위라면 RR을 사용한다.
- real-time (kernel)
- 어떤 것이 중요한 것인지 알 수 있으므로 큰 범위로 구성된다.
- 스케줄링의 우선순위를 미리 더 세분화 한 것
- normal (user level)
- 어떤 작업을 할 지 모르기 때문에 real-time보다 작은 범위를 가진다.
- CFS (Completely Fair Scheduling) 구조 사용
- Linux는 server로 많이 사용 -> kernel과 user level이 나눠져있다.
2. Windows Scheduling
- user level에 더 집중
- kernel을 위해서 따로 우선순위를 나누지 않고 모두가 같은 우선순위를 나눠서 사용한다. (높은 값이 더 빠른 우선순위)
- Linux와 마찬가지고 같은 우선순위인 경우 RR을 사용한다.
3. Solaris Scheduling
Algorithm Evaluation
1. Deterministic Modeling
- 수학적인 분석
- 가장 쉽고 변수 통제가 가능한 방식
2. Simulation/Emulation
- 컴퓨터 CS분야에서 많이 사용하는 방식
- Simulation : 중요한 변수를 모아서 SW로 돌려보는 것
- Emulation : 실제 상황과 유사한 실제 상황에서 돌려보는 것
- example
- evalutaion of CPU scheulaers by simulation
- simulation의 성능을 높이기 위해서 실제 환경에서 받은 변수를 토대로 돌려보면 Emulation과 거의 유사한 성능으로 테스트 할 수 있다.
3. Implementation
- 실제로 구현해서 측정
- 가장 좋은 방식이지만 어렵고 잘 사용하지 않는다.
