운영체제 수업 + Operating System Concepts 10E 정리 내용
Operating System Ch14 : File System Implementation
Operating System Ch15 : File System Internals
Overview
1. User's view
- How files are named
- What operations are allowed on them
- What the directory tree looks like
2. Implementer's view
- How files and directories are stored
- How disk space is managed
- How to make everything work efficiently and reliably
File System Implementation
1. Overview
- In-memory Structure
- 실제 운영체제가 시작되서 특정 프로세스가 파일을 access하는데 필요한 구조
- 메모리에서 어떤 것이 이루어져 파일 시스템의 성능을 지원하는지
- On-disk structure
- 전원이 꺼져도 secondary storage가 저장하는 방식
2. In-memory Structure
- 특정 프로세스가 open 실행 -> file descriptor 반환 -> read write 실행
- open 할때 경로가 포함되어 있는 파일 이름 지정
- 여러 개의 프로세스가 파일에 접근하는 경우
- 프로세스가 파일을 read/write 하는 주체
-> 처리는 OS가 한다. (by system call) - OS
- system-wide open file table을 통해 오픈된 파일에 대한 정보를 가지고 있음
- count, offset, file attributes
- 프로세스
- per-process open file table에 정보 저장
-> system-wide open file table의 특정 공간을 가리키는 형태
- per-process open file table에 정보 저장
- 캐시
- 원래는 디스크에 존재 -> 느리므로 캐싱 사용
- 파티션 캐시, 디렉토리 캐시, 버퍼 캐시를 합쳐서 버퍼 캐시라고 부른다.
- 프로세스가 파일을 read/write 하는 주체
- cf) process 실행 시 기본적으로 open 되는 파일 3가지
- standard input / standard output / standard error
- system-wide open file table에 올라오게 되고, 공유해서 사용한다.
3. Virtual File System
- 다양하고 많은 파일을 따로 처리하면 호환성 문제가 발생
- 파일 시스템의 공통된 부분을 묶어서 개발
- 공통된 부분을 Virtual File System(VFS) 라고 한다.
- 공통되지 않은 부분들은 따로 개발한다.
4. Layered File System
- 레이어를 사용하여 파일 시스템 만들기
- 레이어 별로 나눠서 개발한다.
5. On-Disk Structure
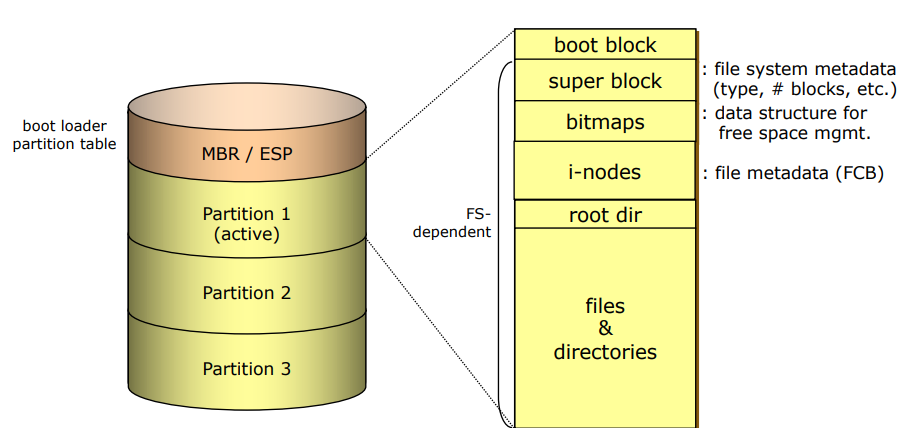
- MBR (Master Boot Record)
- 하드디스크 섹터 0번에 존재, 부트 로더가 저장되는 곳
- load할 OS가 여러개인 경우 MBR이 어떤 OS를 선택하여 실행할지 결정한다.
- Partition이 가지는 file system
- boot block
- window 에서는 boot sector라고 한다.
- 운영체제가 부팅에 필요한 것들을 저장
- partition이 OS가 아닌 일반 저장 매체로만 사용한다면 boot block이 존재하지 않는다.
- super block
- window 에서는 master file table하고 한다.
- 파일 시스템 전체에 대한 정보 저장
- sector 단위로 관리하면 overhead가 크기 때문에 block 단위로 관리한다.
- bitmaps
- 존재하는 디스크 블록들이 사용 중인지 아닌지를 저장하는 곳
- 사용중인지 아닌지 0과 1로 표현
- i-nodes
- 파일 하나하나에 대한 정보 저장, 메타 데이터
- FCB(File Controll Block) -> 파일 이름, 수정 시간, owner, 몇 번째 블록에 저장되어있는지 등을 저장한다.
- Unix 구조에서 파일별로 하나의 i-nodes가 필요하다.
- FCB의 크기 4kb
- root dir
- 계층 구조를 만들기 위해 존재
- files & directories
- boot block
- 연속적으로 저장되는 파일 시스템
- 파일을 연속적으로 배치하는 것이 성능상으로 좋지만 여러가지 문제가 발생한다.
- 파일이 생성되고 사라지는 것이 반복되면서 hole이 생기고 external fragmentation이 발생한다.
- 한번 저장된 값의 수정이 없는 CD, DVD 등에서는 연속적으로 저장하는 방식을 사용한다.
6. Disk Block
- 0번 디스크 블록은 맨 위에 존재하는 platter의 가장 밖의 track에 존재하는 sector에서 시작한다.
- 한 sector에 8개의 block이 존재한다.
- 처음으로 시작한 sector를 다 채우면 같은 cylinder 상에 존재하는 한 층 아래의 platter에 쓰기 시작한다.
-> arm seek time 줄이기
Free-space Management
1. Overview
- bit map이 1이면 free 상태 0이면 occupied 상태
2. 저장 방식
- 하드디스크의 경우 연속적으로 데이터를 저장하는 방식은 비효율적이기 때문에 다른 방식을 사용한다.
- Linked list
- Grouping
- Counting
- Space maps
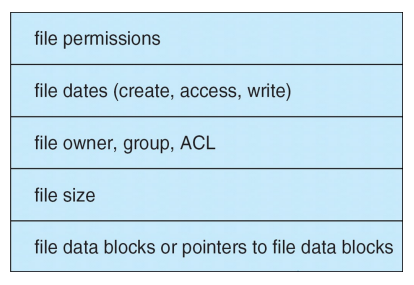
3. A Typical File Control Block
- File Control Block의 기본 구성요소
4. Directory Implementation
- 디렉토리 구현을 어떻게 할 것인가에 대한 내용
-> 위치, 어떤 파일을 저장하는 지 알고 있어야 한다. - In the directory entry
- 특정 디렉토리 안에 존재하는 파일의 정보를 모두 넣기

- 특정 디렉토리 안에 존재하는 파일의 정보를 모두 넣기
- In the separate data structure
- 파일 이름과 포인터를 저장하여 포인터로 파일의 정보(i-nodes)를 가리키는 방식
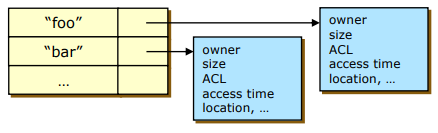
- 파일 이름과 포인터를 저장하여 포인터로 파일의 정보(i-nodes)를 가리키는 방식
- A hybrid approach
- 중요한 것은 디렉토리 안에 저장하고 나머지는 포인터로 가리키는 방식
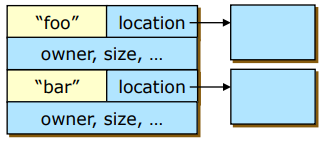
- 중요한 것은 디렉토리 안에 저장하고 나머지는 포인터로 가리키는 방식
Allocation Methods
- 파일 하나가 여러개의 블록을 사용할 때 어떻게 관리하고 배치할 것인가에 대한 방식
1. Contiguous Allocation
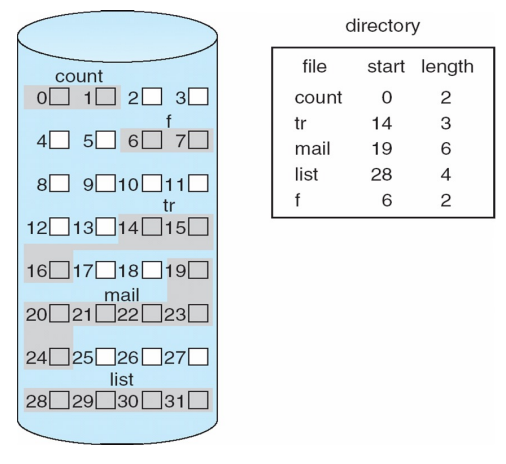
- 연속적으로 데이터 저장하기
- 장점
- 파일 이름, 시작 위치, 길이 정보만 알고 있으면 된다.
- spacial locality 특성을 통해 빠르게 읽어올 수 있다.
- 단점
- external fragmentation이 발생한다.
- 파일 크기가 변하는 것의 처리가 어렵다.
- 데이터가 변하지 않는 저장장치에서 사용하는 방식
- ex) CD-ROMS
2. Linked Allocation
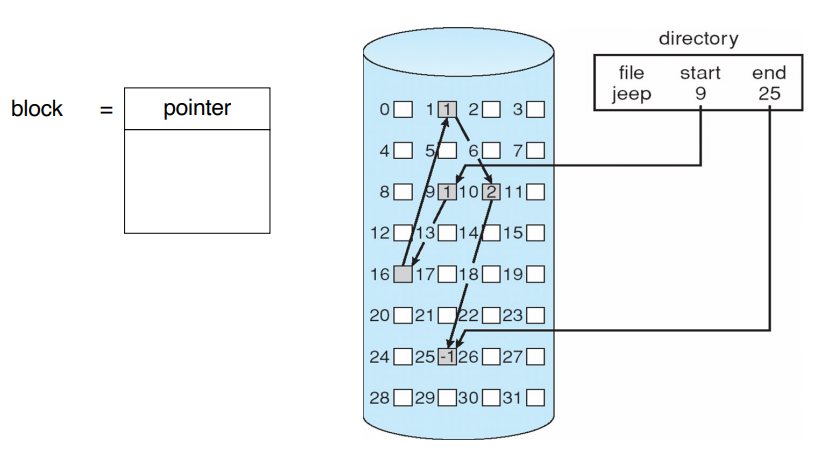
- 포인터를 통해 처음부터 연속적으로 block을 연결하고 끝에는 null을 사용한다.
- 장점
- external fragmentation 문제 없어진다.
- 파일의 크기가 가변적이어도 문제가 없다.
- 파일 이름과 시작 위치만 알면 된다.
- 단점
- spatial locality의 효율성이 떨어진다.
- 포인터가 중간에 하나라도 문제가 생기면 해당 데이터 전체의 문제가 생긴다.
-> 신뢰성이 좋지 못하다.
- 해결방안 : File-Allocation Table(FAT)
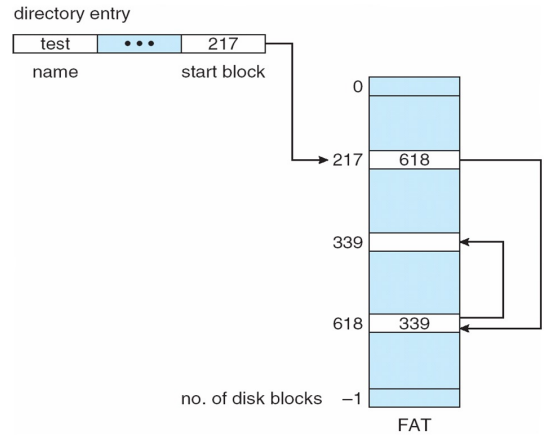
- 디스크는 그대로 두고 포인터 정보만 따로 저장하는 방식
- block에 포인터 정보를 넣지 않아서 성능이 좋다.
- 포인터 정보만 담긴 테이블을 복사해 두면 신뢰성 문제도 해결할 수 있다.
- 문제점 : 루트 디렉토리가 저장된 포인터의 문제가 생기면 데이터까지 문제가 생겨 또다시 신뢰성의 문제가 생긴다.
3. Indexed Allocation
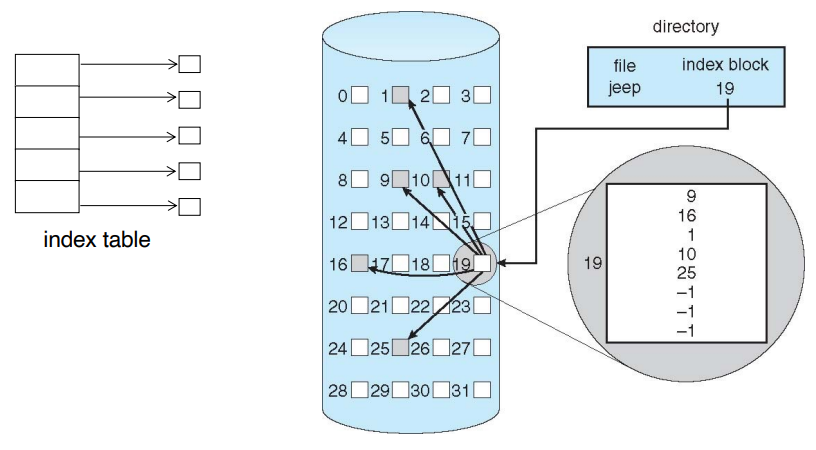
- 블록 들 중에서 일부가 index를 저장하는 방식, 해당 블록에 써있는 index를 읽으면 된다.
- 장점
- external fragmentation 문제 없어진다.
- 인덱스에 문제가 생기더라도 데이터 전체의 문제가 생길 일은 없다.
-> 해당 인덱스가 포함된 데이터는 문제가 생김 - 신뢰성에서 가장 좋은 방식
- 단점
- space overhead
- 해당 block안에 index를 다 넣지 못하는 문제가 발생한다.
- 해결방안 : Combined scheme (UFS)
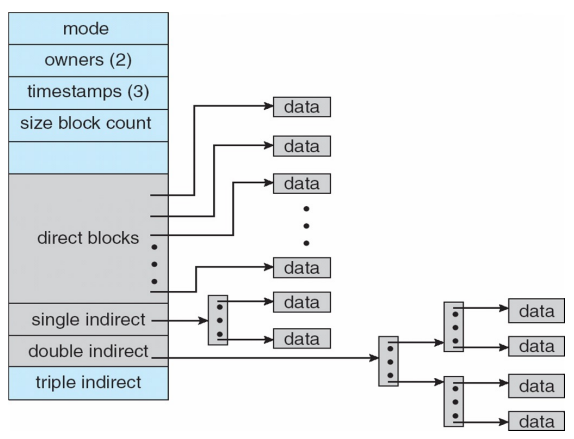
- 처음에는 direct blocks사용 (12개의 block)
- 통계적으로 대부분의 파일 크기는 50kb를 넘지 않기 때문에 12개의 block을 할당함 (12*4 byte)
- if) 12개의 block이 모자라면
- single indirect
- 1000개의 하위 block 존재
- double indirect
- 1000*1000개의 하위 block 존재
- 약 4GB 저장 가능
- triple indirect
- 약 4TB저장 가능
- 현재 사용하지는 않는다
- single indirect
- 처음에는 direct blocks사용 (12개의 block)
4. Unix File System Structure
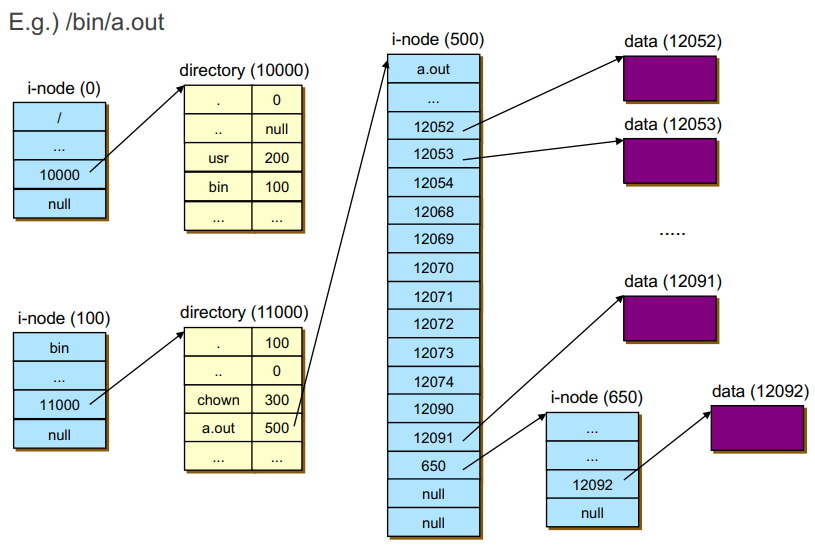
- bin이 root directory이고 a.out 을 실행하는 경우
1) bin이 몇 번을 가리키는지 확인 (100)
2) i-node 가 100인 곳으로 가기
3) i-node(100)의 directory를 확인하여 a.out의 번지 확인 (500)
4) i-node가 500인 곳으로 가기
5) direct block을 이용해서 data 가져오기(5자리 숫자가 12개)
6) direct block으로 모자라서 single indirect 이용 i-node(650) - 만약 해당 a.out을 다른 프로세스가 여러 번 실행하면 똑같은 과정을 반복한다.
-> 낭비되기 때문에 directory cache를 이용해서 read 성능을 높인다.
-> 만일 cache 과정 중에 수정이 일어나면 write back 으로 처리한다.
Other considerations
1. Block size Performance vs Efficiency
- 가장 효율적인 Block size를 찾아보면 4kb일때의 효율이 가장 좋다.
2. Read Ahead
- 목표로 하여 access하는 곳을 한번에 다 읽어와서 arm seek time의 낭비를 줄인다.
-> spatial locality 특성 이용
3. Buffer Cache
- 최근 사용된 disk block을 메모리에 cache해서 locality 특성을 이용하여 접근 시간을 줄일 수 있다.
4. Caching Writes
- 디스크에서 속도 향상을 위해 cache를 사용
- cache 사용시 기존 data의 수정이 일어난 후 write back 처리를 해야하지만 어떠한 문제로 write back을 하지 않고 꺼짐
-> inconsistent 문제 발생 - 해결 방안 (완벽한 해결방안은 아니다)
- windows : scan disk
- UNIX : fsck
- Log Structured File System (Journaling file systems)
- 더 좋은 해결방안
- 디스크에 log를 남겨서 시스템이 write back을 하면서 남겨진 log를 지우는 방식
- inconsistent 한 상태에서 재부팅 될 시 log 확인
1) log가 없음 -> 제대로 write back 된 상태
2) log가 남아있음 -> 로그 데이터를 가지고 복구 시도
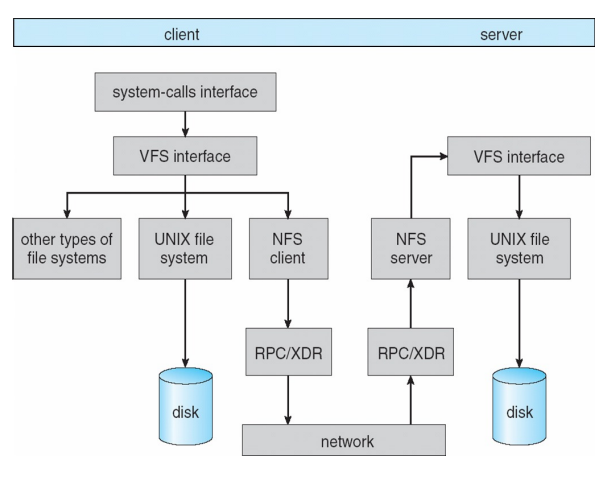
5. Remote File Systems
- Network File Systems (NFS)
- 원격의 디스크를 내 디스크처럼 붙여서 쓰기
- RPC/XDR 부분이 NFS 프로토콜