📝 추천 학습 로드맵 (실습 제안)
- 이론만으로는 이해하기 어렵습니다.
VirtualBox안에서 다음 순서대로 실습해 보는 것을 추천합니다.- 네트워크:
ssh 서버를 설치하고, 호스트 PC(윈도우 등)의 터미널(PowerShell 등)에서 VM으로 접속해 봅니다.- 패키지: apt를 이용해 웹 서버인
nginx를 설치합니다.systemd: systemctl을 이용해 nginx를 켜고(start), 부팅 시 자동 실행(enable)되도록 설정합니다.- Bash/네트워크:
curl localhost명령어로 nginx가 잘 동작하는지 확인하고, grep을 사용해 결과물 중 특정 단어만 필터링해 봅니다.
[ 25.12.01 (월) ]
< 리눅스 - Bash 쉘 명령어, 패키지 관리, sytemd >
01. Bash Expansion(확장)
Bash(Shell & CLI)
리눅스 제어의 기본이 되는 영역입니다. 단순히 파일을 옮기는 것을 넘어, 자동화 스크립트를 작성할 수 있는 수준을 목표로 해야 합니다.
💡 중요 팁: .bashrc 파일이 무엇인지, 그리고 export PATH를 통해 환경 변수를 설정하는 방법은 개발 환경 세팅 시 반드시 마주치게 되므로 꼭 익혀두세요.

Bash 쉘(Shell)은 리눅스 커널과 사용자 사이를 연결해 주는 인터페이스이자, 그 자체로 강력한 프로그래밍 언어입니다. 특히 우분투 터미널에서 $ 기호는 단순한 프롬프트가 아니라 변수, 프로세스 상태, 명령어 치환 등 핵심 기능을 수행하는 특수 문자로 쓰입니다.
- 1. 변수 사용과 $ (Variables)
Bash에서 값을 저장하고 불러올 때 $를 사용합니다. 여기서 가장 중요한 것은 따옴표의 차이입니다.
✅개념: 변수명=값으로 할당하고, $변수명으로 값을 참조합니다.
✅주의: 변수 선언 시 등호(=) 앞뒤에 공백이 있으면 안 됩니다.
📢 해설: 시스템 환경 설정 파일이나 스크립트 작성 시, 값을 동적으로 바꿀 때는 ""를, 문자 그대로(Regex 등) 써야 할 때는 ''를 씁니다.
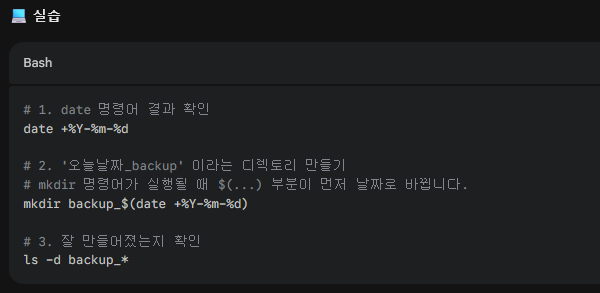
- 2. 명령어 치환 $( ) (Command Substitution)
명령어의 실행 결과를 다른 명령어의 입력 값으로 사용할 때 씁니다. 로그 파일 생성이나 자동화 스크립트에서 매우 빈번하게 사용됩니다.
✅개념: $(명령어) 형태로 작성하면, 괄호 안의 명령어가 먼저 실행되고 그 결과가 자리에 남습니다.
- 3. 종료 상태 확인 $? (Exit Status)
시스템 프로그래밍이나 배포 스크립트를 짤 때, 앞선 작업이 성공했는지 실패했는지 판단하는 가장 중요한 변수입니다.
✅ 개념: $?는 바로 직전에 실행된 명령어의 종료 코드를 담고 있습니다.
0: 성공 (Success)
0이 아닌 숫자: 실패 (Error)활용: 쉘 스크립트에서 if [ $? -eq 0 ]; then ... 구문으로 에러 처리를 할 때 핵심적으로 사용됩니다.

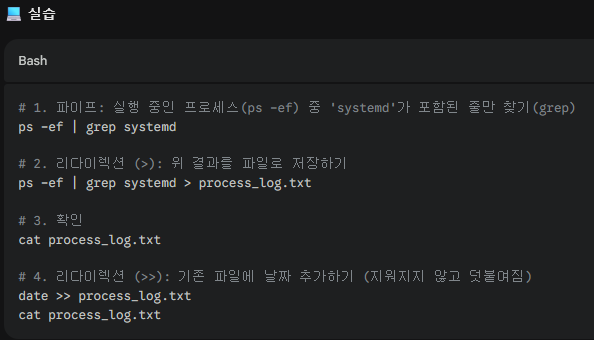
- 4. 파이프 | 와 리다이렉션 > (I/O Redirection)
명령어의 결과를 화면에 출력하는 대신 파일로 저장하거나, 다른 명령어에 넘겨줄 때 사용합니다.
✅ 개념:
|(Pipe): 왼쪽 명령어의 출력을 오른쪽 명령어의 입력으로 넘김.
>(Write): 출력을 파일에 저장 (기존 내용 덮어씀).
>>(Append): 출력을 파일 끝에 추가.
💡 다음 단계 제안
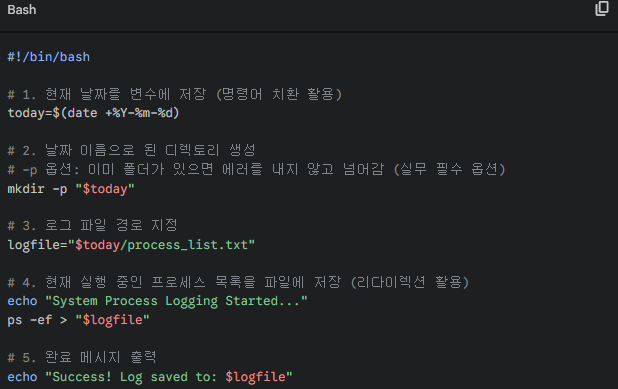
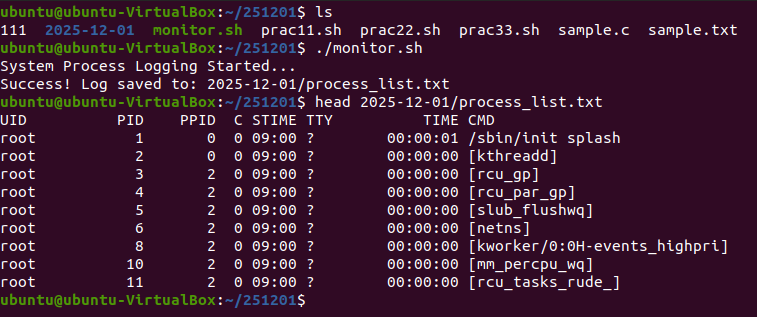
위의 명령어들은 터미널에서 한 줄씩 실행했지만, 이 명령어들을 파일 하나에 모아두면 그게 바로 쉘 스크립트(.sh)가 됩니다.Question) 지금 작성한 내용들을 바탕으로, "현재 날짜 이름의 폴더를 만들고, 그 안에 현재 실행 중인 프로세스 목록을 저장하는 자동화 스크립트(monitor.sh)"를 한번 만들어 보시겠습니까?
📍SOLUTION.
#!/bin/bash: 쉐뱅(Shebang)이라고 부릅니다. 이 스크립트를 실행할 해석기가 Bash임을 시스템에 알리는 필수적인 첫 줄입니다.
today=$(date ...): date 명령의 실행 결과가 today라는 변수에 담깁니다.
"$today": 변수를 사용할 때 습관적으로 쌍따옴표로 감싸는 것이 좋습니다. (만약 날짜 포맷에 공백이 들어가더라도 하나의 문자열로 인식하게 하기 위함)
"$logfile": 화면에 뿌려질 수천 줄의 프로세스 정보를 낚아채서 지정한 파일 안에 덮어씁니다.
💡 코드 상세 해석(핵심 포인트)
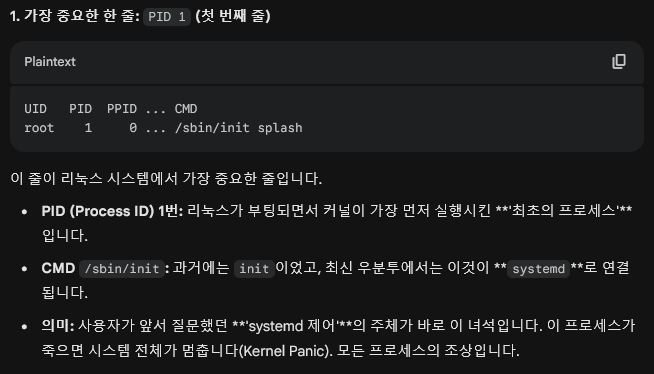
: head 명령어로 확인한 상위 10줄은 리눅스 시스템이 부팅된 직후 가장 먼저 태어난 프로세스들의 목록임.
💡 이번 실습의 핵심 개념 (Takeaway)
이 실습을 통해 단순히 파일을 만든 것이 아니라 다음 3가지 핵심 기술을 사용하신 겁니다.
- I/O 리다이렉션 (>):
ps -ef의 결과는 원래 모니터에 나와야 하지만, > 기호를 통해 파일 시스템(process_list.txt)으로 방향을 틀었습니다. "명령어의 출력을 파일로 저장한다"는 리눅스 로그 관리의 기초입니다.- 프로세스 트리 구조:
리눅스의 모든 프로그램은 누군가(부모)가 실행시켜서 탄생한다는 것을 확인했습니다. (PID 1이 시초)- Bash 스크립트 자동화:
명령어 3~4개를 칠 과정을 monitor.sh라는 파일 하나로 묶었습니다. 이제 이 파일만 실행하면 언제든 똑같은 작업을 반복할 수 있습니다.
02. Bash 쉘에서의 확장
📌 "명령어가 실행되기 전에, 쉘이 입력된 기호들을 실제 값으로 바꿔치기하는 과정".
- 우리가
*.txt라고 입력하면, 프로그램(ls, rm 등)이 실행되기 전에 쉘이 먼저 디렉토리를 뒤져서a.txt b.txt c.txt로 바꿔놓고 명령어를 실행한다.
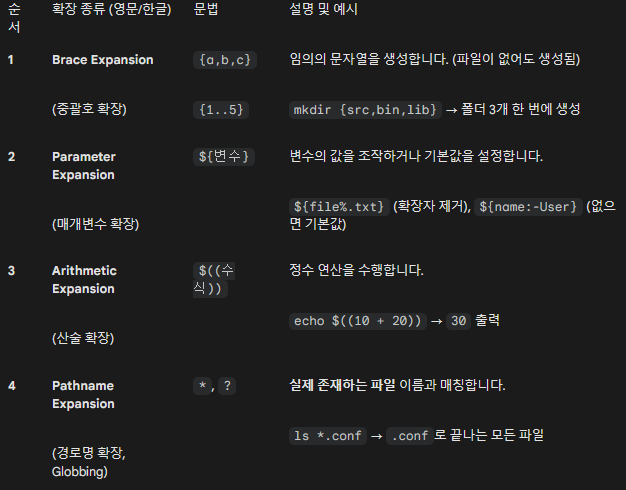
- 반드시 알아야 할 4가지 확장 기술 (Tech Stack)
Bash에는 7~8가지의 확장이 있지만, 실무에서 90% 이상 쓰이는 핵심 4가지를 정리했습니다.💡 실행 순서의 비밀: 쉘은 명령어를 보자마자 실행하지 않고, 중괄호 → ~ → 변수/명령어 → 산술 → 경로명(*) 순서대로 해석(확장)한 뒤 마지막에 실행합니다.
- 실전 실습: 프로젝트 환경 자동 구축하기
이번에는 단순히 명령어를 치는 게 아니라, 확장 기능을 이용해 복잡한 폴더 구조와 파일들을 단 한 줄로 제어하는 실습을 해보겠습니다.✅ 실습 목표
1. 웹 프로젝트 폴더 구조(css, js, html)를 한 번에 생성
2. 테스트용 이미지 파일 5개를 한 번에 생성
3. 산술 연산으로 다음 버전 번호 계산
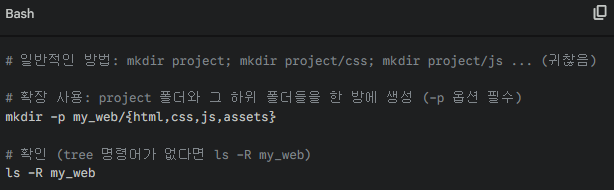
Step01 : 중괄호 확장 (폴더 구조 잡기)
해설: 쉘이 {html,css,js,assets}를 보고 4개의 mkdir 명령어로 풀어서 실행해 준 것과 같습니다.
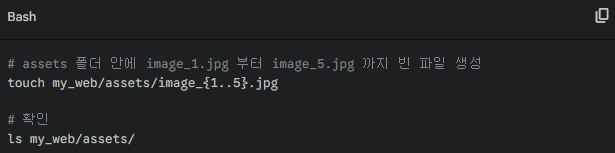
Step02 : 중괄호 + 경로명 확장 (파일 대량 생성)
해설: {1..5}는 1부터 5까지 숫자를 자동으로 생성해줍니다. 서버 테스트용 더미 데이터를 만들 때 매우 유용합니다.
Step03 : 매개변수 확장 (파일명 조작 맛보기)
이 부분은 쉘 스크립트에서 파일 확장자를 바꿀 때 정말 많이 씁니다.
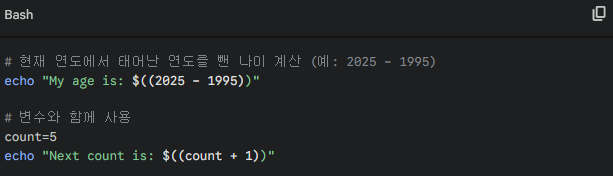
Step04 : 산술 확장 (간단한 계산)
Bash 쉘 내부에서 계산기 없이 바로 연산이 가능합니다.

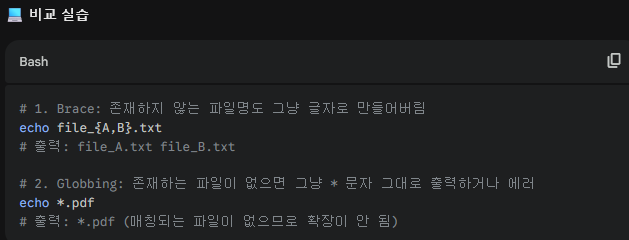
- 심화: Globbing(*)과 Brace({})의 결정적 차이
초보자가 가장 많이 헷갈리는 부분입니다. 이 차이를 알면 실수를 줄일 수 있습니다.
- Brace {a,b}: 파일이 있든 없든 무조건 문자열을 생성합니다. (주로 mkdir, touch 등 무언가 만들 때 사용)
- Globbing *: 실제 존재하는 파일하고만 매칭됩니다. (주로 ls, rm, cp 등 있는 파일을 다룰 때 사용)
03. 리눅스 - 패키지 관리 시스템
- 우분투는 데비안(Debian) 계열이므로 apt를(+DPKG도 사용) 주로 사용합니다. 라이브러리 의존성을 해결하고 시스템을 최신 상태로 유지하는 방법입니다.
- 리눅스 패키지 관리 시스템은 "검증된 소프트웨어 창고(저장소)에서 프로그램을
다운로드, 설치, 업데이트, 삭제를 자동으로해주는 시스템"입니다.
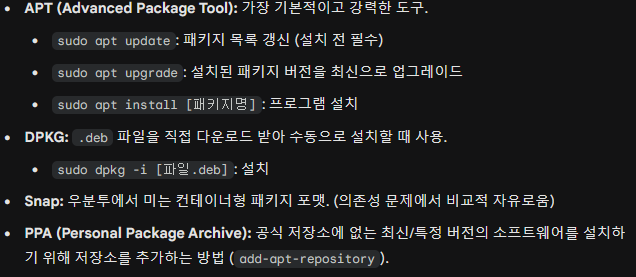
✅ APT와 DPKG의 관계
APT(Advanced Package Tool) : "관리자" 역할. 의존성(Dependency)을 자동으로 해결해줌. 인터넷에서 다운로드.
DPKG(Debian PacKaGe) : "기술자" 역할. ".deb" 파일을 직접 설치함. 의존성 해결 능력은 없음(에러 발생 가능)
💡 의존성(Dependency)이란? A라는 프로그램을 실행하려면 B라는 라이브러리가 반드시 필요할 때, "A는 B에 의존한다"고 합니다.
: APT는 A를 설치할 때 B도 알아서 같이 설치해 주지만, DPKG는 그렇지 않습니다.
✅ 필수 명령어 정리 (Cheat Sheet)
: 모든 명령어 앞에는 "sudo (관리자 권한)"이 필요함.
- 목록 갱신:
apt update(설치된 프로그램 업데이트가 아님! 저장소의 리스트를 최신으로 고침)- 프로그램 설치:
apt install[패키지명]- 실제 업그레이드:
apt upgrade(내 PC의 프로그램 버전을 최신으로 올림)- 삭제 (설정 유지):
apt remove[패키지명] (프로그램만 지움, 설정 파일은 남음)- 완전 삭제:
apt purge[패키지명] (설정 파일까지 깨끗하게 지움)- 찌꺼기 청소:
apt autoremove(의존성 때문에 깔렸다가 이제 필요 없어진 패키지 삭제)
✅ 실전 실습 : 시스템 모니터링 도구 htop 다루기
리눅스 서버 관리자들이 가장 사랑하는 도구 중 하나인htop을 설치하고 지워보며라이프사이클을 익혀봅시다.
- Step 1: 저장소 목록 갱신 (가장 중요)
패키지를 설치하기 전에는 습관적으로 업데이트를 해줘야 합니다.(bash) sudo apt update체크 포인트 :
터미널에 URL들이 쭉 뜨면서 마지막에 "All packages are up to date" 혹은 "X packages can be upgraded"라고 뜨면 성공입니다.
04. 우분투 CLI 명령어 활용 실습
🚀 Linux 현업의 핵심 : "서버 운영" , "자동화" , "트러블 슈팅"
✅ 핵심 내용 3가지
1. systemd: 커스텀 서비스 등록 및 제어
💡 핵심 개념: 데몬 관리, 부팅 자동화, 서비스 실패 분석
- 운영체제가 부팅될 때 내가 만든 프로그램(Python, Java 등)을 자동으로 실행하고, 실패하면 재시작하도록 만드는 과정은 모든 서버 관리의 기본입니다.
2. 네트워크 소켓 및 포트 진단 (ss/curl)
💡 핵심 개념: 포트 상태 확인, 연결 추적
- 특정 포트가 열려 있는지, 어떤 프로세스가 점유하고 있는지 확인하는 것은 네트워크 트러블슈팅의 80%를 차지합니다.
3. find + xargs (대량 파일 처리 및 청소)
💡 핵심 개념: 파이프의 한계 극복, 재귀적 대량 작업
- 수천 개의 파일 중 특정 조건을 만족하는 파일만 골라내서 삭제하거나 권한을 바꾸는 작업은 xargs가 없으면 불가능합니다.
cf. "Yocto" and Linux.
🚀 Yocto
: 특정 하드웨어에 맞게 사용자 정의된 리눅스 배포판을 구축할 수 있게 해주는 오픈소스 프로젝트이자, 임베디드 시스템을 위한 오픈소스 빌드 프레임워크.
: 이는 개발자가 원하는 구성의 리눅스 OS를 직접 만들 수 있도록 도와주며, 다양한 하드웨어 아키텍처에 독립적으로 적용할 수 있습니다.
🚀 Yocto 프로젝트의 특징
- 맞춤형 리눅스 OS 구축: 특정 임베디드 장치에 필요한 소프트웨어만을 포함하여 가볍고 효율적인 OS를 만들 수 있습니다.
- 표준화된 빌드 시스템: Poky라는 참조 빌드 시스템과 BitBake와 같은 도구를 통해 빌드 과정을 단순화하고 재현 가능하게 만듭니다.
- 하드웨어 독립성: 다양한 하드웨어 아키텍처에 구애받지 않고 커스텀 리눅스 구성을 쉽게 할 수 있습니다.
- 오픈소스 협업 프로젝트: 임베디드 리눅스 제품 개발을 위한 공동의 목적을 가진 개발자 커뮤니티가 참여하여 툴과 정보를 공유합니다.
05. 네트워크 관련 도구
- VirtualBox를 사용 중이라면 NAT, 브리지 어댑터 등의 설정과 맞물려 네트워크 설정이 중요해집니다. 서버의 연결 상태를 진단하고 포트를 확인하는 기술이 핵심입니다.

[ 25.12.02 (화) ]
< 리눅스 - Bash 쉘 >
00. 참고 : 우분투 루트 디렉토리 간단 설명
📁 우분투의 루트(/) 아래에 보이는 디렉토리들은 리눅스 파일시스템의 기본 구조(FHS, Filesystem Hierarchy Standard) 에 따라 의미가 정해져 있습니다.
bin: 기본 실행 프로그램(명령어) 보관 ex. ls, cp, mv, cat
boot: 부팅에 필요한 커널, initrd 같은 파일 (지우면 시스템 부팅 안 됨)
cdrom: 예전 CD-ROM 자동 마운트 지점 (요즘은 거의 사용X)
dev: 장치 파일(Device) ex. /dev/sda(디스크), /dev/tty(터미널)
etc: 시스템 설정 파일 ex. /etc/passwd, /etc/ssh/, /etc/fstab
home: 사용자의 개인 폴더. /home/username 형태
lib / lib32 / lib64 / libx32:프로그램 실행에 필요한 공용 라이브러리(.so 파일들). 아키텍처에 따라 나뉨
lost+found: 파일 시스템 오류 발생 후 복구된 파일들을 임시 저장 (ext 계열 파일 시스템에서 자동 생성됨)
media: USB, 외장하드 같은 외부 장치 자동 마운트 지점
mnt: 임시로 장치를 수동 마운트할 때 사용 (관리자가 직접 mount할 때 주로 사용)
opt: 선택적(optional) 프로그램 설치 위치. 구글 크롬, VMWare 등 여기 설치되기도 함
proc: 커널이 만든 가상 파일 시스템. 시스템 상태, 프로세스 정보 ex. /proc/cpuinfo, /proc/meminfo
root: root 사용자의 홈 디렉토리 (일반 사용자 home과 다름)
run: 부팅 이후 시스템 런타임 데이터 저장 (시스템 및 서비스의 PID 파일 등 있음)
sbin: 시스템 관리 명령어 ex. fdisk, iptables, reboot (일반 사용자가 잘 안 씀)
snap: snap 패키지들이 저장되는 디렉토리 (우분투의 앱 패키징 시스템)
srv: 웹서버, FTP 등 서비스 데이터 저장 ex./srv/www 같은 실제 서비스 데이터
swapfile: 스왑 공간을 파일로 제공하는 경우의 스왑 파일 (메모리 부족할 때 사용)
sys: 커널/장치 관련 가상 파일 시스템. udev, 장치 정보 등
tmp: 임시 파일 저장. 프로그램들이 잠깐 쓰고 지우는 파일들
(재부팅하면 비워짐)
usr: 대부분의 일반 사용자용 프로그램과 라이브러리 위치. 사실상 “큰 소프트웨어 창고” ex. /usr/bin, /usr/lib, /usr/share
var: 자주 변하는 데이터(variable) ex. 로그파일(/var/log), 캐시(/var/cache), 메일 큐
01. 패키지 관리(Package Management)
- 우분투는 데비안(Debian) 계열이므로 apt를 주로 사용합니다. 라이브러리 의존성을 해결하고 시스템을 최신 상태로 유지하는 방법입니다.
02. Linux - alias
🚀 우분투 리눅스에서 alias는
긴 명령어나 자주 사용하는 명령어에 짧고 기억하기 쉬운 별명(단축키)을 지정하는 데 사용되는 셸 기능입니다. 이를 통해 터미널 작업의 효율성을 크게 높일 수 있습니다.
✅ Alias 개념
alias는 Bourne Again Shell (Bash)과 같은 셸에서 제공하는 내장 명령어로, 사용자가 특정 문자열(별명)을 입력하면 셸이 이를 미리 정의된 원본 명령어로 대체하여 실행합니다.
-
목적: 복잡하거나 긴 명령어, 여러 옵션이 포함된 명령어를 간소화하여 입력 시간과 오타를 줄여줍니다.
-
특징: 현재 세션에서만 유효합니다. 터미널을 닫거나 시스템을 재부팅하면 설정이 사라집니다. 영구적으로 사용하려면 설정 파일을 수정해야 합니다.
-
alias 명령어 단독으로 현재 설정된 모든 alias 목록을 확인할 수 있습니다.
03. 네트워크 관련 내용
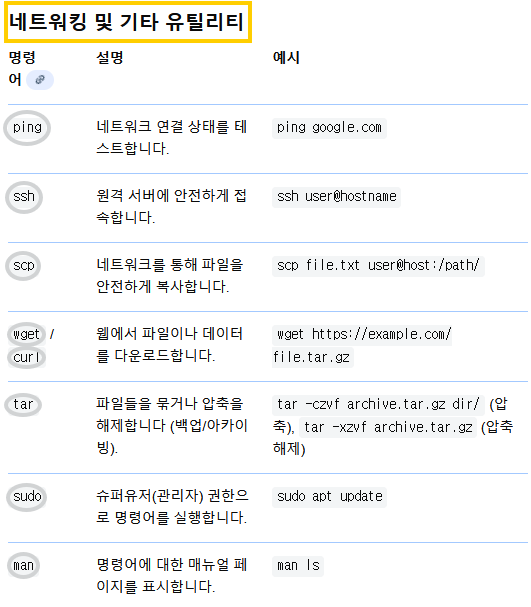
🚀 curl 명령어
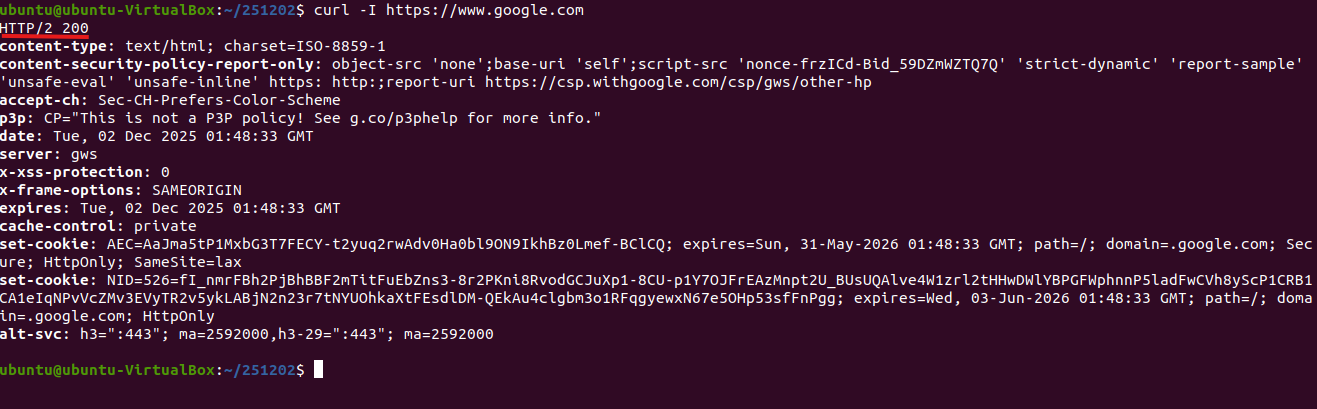
Question) 리눅스 우분투 환경 CLI에서 curl -I https://www.google.com를 입력했을 때, 가장 첫 줄에 HTTP/2 200이라고 뜨는 건 무슨 상황인지?
✔️ 1. 서버가 HTTP/2 프로토콜로 응답했다는 의미
- HTTP/2 는 서버가 클라이언트(curl)에게 응답을 보낼 때 사용한 HTTP 프로토콜 버전을 나타냅니다.
- 즉, 구글 서버가 curl과의 협상(ALPN)을 통해 HTTP/2로 통신하기로 결정했다는 뜻입니다.
✔️ 2. 200은 HTTP 상태 코드 (정상 응답)
- 200 은 요청이 성공했다는 의미의 표준 HTTP 상태 코드입니다.
- 즉, https://www.google.com 에 대한 요청이 성공적으로 도착했고
서버는 정상적인 헤더를 반환하고 있다는 뜻입니다.
✔️ 3. curl이 자동으로 HTTP/2 지원
- 요즘 우분투 환경의 curl은 대부분 HTTP/2 지원(libnghttp2 포함)이 되어 있어서 HTTPS 사이트에 접속하면 다음 과정을 거칩니다:
- TLS handshake 중 ALPN(Application-Layer Protocol Negotiation)을 수행
- 서버(google)가 “http/2 지원함” 이라고 응답
- curl이 HTTP/2로 요청 전송
- 서버가 HTTP/2 응답 → 첫 줄에 HTTP/2 200
✔️ 4. HTTP/1.1이 아닌 이유
- 과거에는 HTTP/1.1 200이 일반적이었지만, 대규모 사이트(구글, 유튜브, 네이버 등)는 대부분 HTTP/2를 기본 사용합니다.
- 만약 일부 서버가 HTTP/2를 지원하지 않는다면 첫 줄이 HTTP/1.1 200 으로 표시됩니다.
✔️ 참고: 강제로 HTTP/1.1로 요청하기
(bash) curl -I --http1.1 https://www.google.com
✔️ 요약 : HTTP/2 200 이 뜨는 것?
- 브라우저/CLI와 구글 서버가 HTTP/2로 통신하기로 협상했고
- 요청이 성공했음을 나타내는 정상적인 상황
- 즉, 아무 문제도 아니며 오히려 최신 프로토콜을 사용하는 정상 동작입니다.
04. 로그 분석 및 텍스트 필터링(에러 원인 찾기)
🚀 리눅스 실력의 척도는 "로그 파일에서 원하는 정보를 얼마나 빨리 뽑아내느냐"에 달려있습니다.
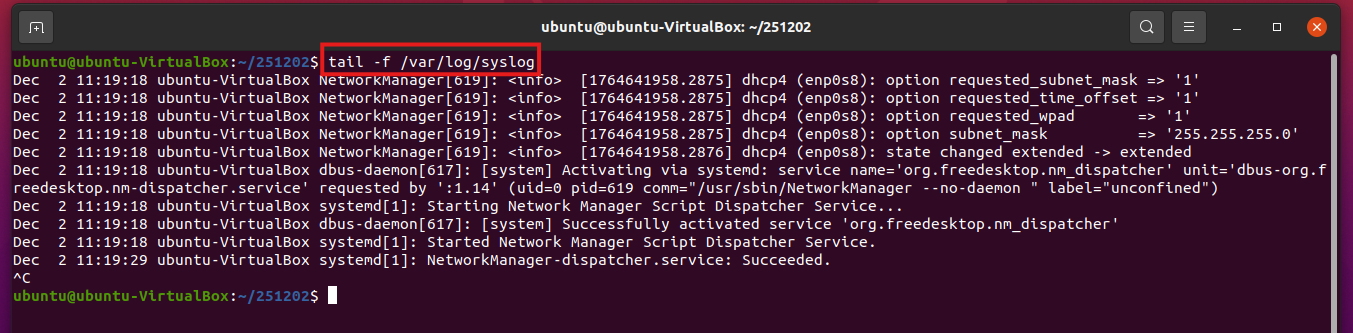
✔️ 실시간 로그 모니터링 (tail) 서버를 켜두고 실시간으로 올라오는 에러를 봅니다.
(Bash) tail -f /var/log/syslog
# /var/log/syslog 는 시스템의 메인 로그 파일입니다.
-f: Follow. 파일 끝에 내용이 추가되면 실시간으로 화면에 뿌려줍니다. (종료는Ctrl + C)✔️ 대용량 로그에서 에러만 뽑아내기 (
grep, cat, 파이프)
: 로그 파일이 수백 MB라면 눈으로 볼 수 없습니다.
:'Error'라는 단어가 포함된 줄만 뽑아서 봅니다.✔️ 응용: 파이프라인 연결 (현업 스타일) "최근 로그 100줄 중에서, 'fail'이라는 단어가 들어간 것을 찾고 싶다"면?
(bash) tail -n 100 /var/log/syslog | grep "fail"
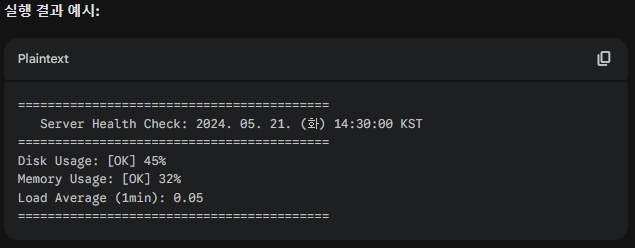
05. 실습 프로젝트 : "Server Health Check Script"
- 이 스크립트는 CPU 부하, 메모리 사용량, 디스크 용량을 체크하고 문제 발생 시 빨간색 경고를 띄웁니다. (vi나 nano 에디터 사용)
#!/bin/bash # --- 설정값 (Threshold) --- # 임계치를 변수로 빼는 것이 유지보수의 핵심입니다. DISK_LIMIT=80 # 디스크 사용량이 80% 넘으면 경고 MEM_LIMIT=80 # 메모리 사용량이 80% 넘으면 경고 # --- 색상 변수 (가독성을 위해 현업에서 많이 씁니다) --- RED='\033[0;31m' GREEN='\033[0;32m' NC='\033[0m' # No Color echo "==========================================" echo " Server Health Check: $(date)" echo "==========================================" # 1. 디스크 사용량 체크 (루트 파티션 / 기준) # df -h: 디스크 용량 확인 | grep /$: 루트 마운트 라인만 추출 | awk: 5번째 컬럼(%) 추출 | tr: % 기호 제거 CURRENT_DISK=$(df -h / | grep '/$' | awk '{print $5}' | tr -d '%') if [ "$CURRENT_DISK" -ge "$DISK_LIMIT" ]; then echo -e "Disk Usage: ${RED}[DANGER] ${CURRENT_DISK}% (Limit: $DISK_LIMIT%)${NC}" else echo -e "Disk Usage: ${GREEN}[OK] ${CURRENT_DISK}%${NC}" fi # 2. 메모리 사용량 체크 # free -m: 메가바이트 단위 | awk: 2번째 줄(Mem)에서 사용량($3)/전체량($2)*100 계산 # bash에서는 소수점 계산이 까다로워 awk 내부에서 계산하는 것이 정석입니다. CURRENT_MEM=$(free -m | awk 'NR==2{printf "%.0f", $3*100/$2 }') if [ "$CURRENT_MEM" -ge "$MEM_LIMIT" ]; then echo -e "Memory Usage: ${RED}[DANGER] ${CURRENT_MEM}% (Limit: $MEM_LIMIT%)${NC}" else echo -e "Memory Usage: ${GREEN}[OK] ${CURRENT_MEM}%${NC}" fi # 3. CPU Load Average (1분 평균) 체크 # top이나 uptime에서 로드 에버리지 추출 LOAD_AVG=$(uptime | awk -F'load average:' '{print $2}' | cut -d, -f1 | xargs) # 쉘에서 소수점 비교는 bc 명령어가 필요하지만, 간단히 정수형으로 비교하거나 그냥 출력하는 경우가 많습니다. echo -e "Load Average (1min): ${GREEN}$LOAD_AVG${NC}" echo "=========================================="
🚀 코드 분석 (현업 포인트)
- Shebang (#!/bin/bash): 스크립트의 첫 줄은 항상 이 파일이 어떤 해석기(Shell)로 실행될지 명시해야 합니다.
- 변수 사용 (DISK_LIMIT): 숫자 80을 코드 중간에 하드코딩하지 않고 상단 변수로 뺐습니다. 나중에 기준이 바뀌면 상단만 고치면 됩니다.
- Command Substitution $(...): 명령어의 실행 결과를 변수에 담을 때 백틱(`) 대신 $(...)를 사용하는 것이 최신 표준이며 중첩 사용 시 가독성이 좋습니다.
- Awk 활용: awk는 리눅스 데이터 처리의 핵심입니다.
awk '{print $5}': 공백으로 구분된 텍스트에서 5번째 칸만 가져옵니다. - 색상 코드: 로그 가독성을 높이기 위해 ANSI Escape Code(\033...)를 사용했습니다.
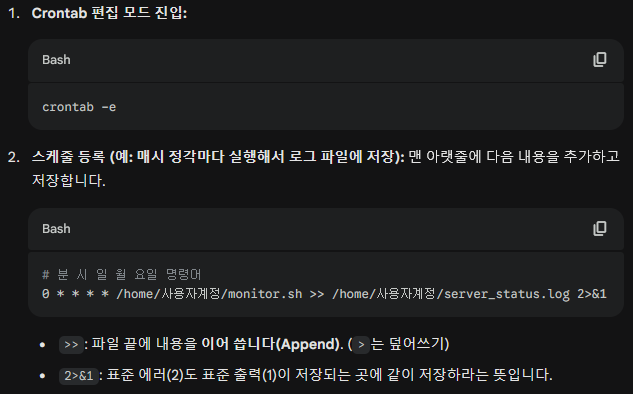
✅ 자동화 (Crontab)
- 스크립트를 매번 손으로 실행하면 자동화가 아닙니다. Crontab(크론탭)을 사용해 주기적으로 실행하고 로그를 남겨야 완성입니다.
[ 25.12.03 (수)]
< 리눅스 개발 도구 >
제시해주신 7가지 키워드(GCC, GDB, Library, Make, CMake, Git, Docker)는 리눅스 시스템 개발자가 되기 위한 필수 로드맵 그 자체입니다.
이 도구들은 개별적으로 존재하는 것이 아니라, "코드 작성 → 빌드 → 디버깅 → 배포 및 협업"이라는 개발 수명 주기(Cycle) 안에서 유기적으로 연결됩니다.
01 compile / build (gcc)
- Unix (Linux) : c, cc, gcc (GNU c compiler -> GNU compiler collection)
- gcc --> .c --> c compiler .s --> assembler
- cpp
- ccl : c compiler
- g++ : c++ compiler
- gas : gnu assembler
- gnm : name
- gdb : debugger
- ld : linker
# Native vs Cross
- host, targ, ie, elf
# build process
Build: GCC (GNU Compiler Collection)
가장 기본이 되는 컴파일러입니다. 사람이 짠 C/C++ 코드를 기계어(바이너리)로 변환합니다.
- 핵심 개념: 컴파일 4단계 (전처리 → 컴파일 → 어셈블리 → 링킹)
- 학습 포인트:
- 옵션: -o(출력 파일명), -c(오브젝트 파일만 생성), -g(디버깅 정보 포함), -Wall(경고 메시지 출력), -I(헤더 경로), -L(라이브러리 경로).
- 크로스 컴파일: 임베디드에서는 PC(x86)에서 보드(ARM)용 코드를 빌드해야 하므로 arm-linux-gnueabihf-gcc 같은 크로스 컴파일러의 개념을 익혀야 합니다.
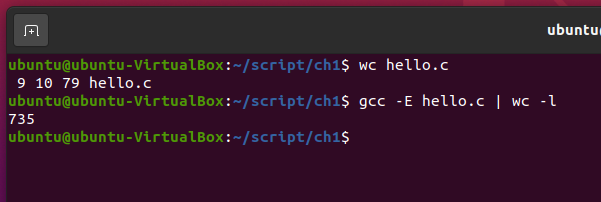
1) pre processing (전처리) : gcc -E hello.c | wc -l
2) compile : .c(c소스) -> .s(ASM소스) = { instruction + assembly 언어} ( AT gcc manual )
ie, gcc -s와 gcc -S는 다르다.
3) assemble
.s ---> .o (object file)
ie, gcc -c 
4) locate (PC에서는 신경쓰지 않아도 됨.)
.o (relocatable) ---> located
? location == address !
func() --> &func // @.TEXT
gi --> &gi // @.DATA
li --> &li ( @stack on the fly )
ie, by ld hello.o <-- XXXXX.ld ( address )
on PC : locat X
on board : locate O ( rom? ram? )
ie, uvision - Nucleo
5) link
hello.o
startup.o
math.a ( sin.o cos.o. tan.o ) (+ ... hello 만듦.
ie, gcc -o helloworld hello.o startup.o math.a
-> ./helloworld (ELF)
-> uVision ( Build (F7) )
6) elf2bin // elf2hex
.bin
.hex ( ROMalbe file ) by rom writer ( JTAG debugger )
--> .TEXT .RODATA --> ROM
--> .DATA .RSS --> ROM ( VMA: RAM )
--> uVision ( Flash, (F8), debugging (^F5) )
"undefined reference to" : 중요
- 정의되지 않은 참조 ( 링크 오류. 함수 정의 X )
"Segmentation fault (core dumped)"
- 세그폴트(Segfault) : 남의 땅을 침범했다.
- Core dumped : 프로그램이 죽는 순간의 메모리 상태를 core라는 파일에 기록해뒀다.
02 debug (gdb는 잘 안씀.)
- 리눅스 환경에서 코딩 + 디버깅하기. (기본)
1) touch sample.c (파일 만들기)
2) nano sample.c (코드 입력하기)
3) gcc -o sample sample.c (sample이라는 실행파일 생성)
4) ./sample (실행하기)-> 4단계 프로세스는 가장 기초적이고 완벽한 흐름입니다. 여기서 "제대로 된 개발" (디버깅, 자동화, 에러 추적)을 하려면 3번(컴파일)과 4번(실행) 단계에 옵션과 도구를 추가해야 합니다.
[ (추가) 업그레이드된 개발 프로세스 ]
1) touch sample.c (파일 만들기)
추가할 것: git (버전 관리)
설명: 파일을 만들자마자 git init을 해두면, 나중에 코드가 꼬였을 때 과거로 되돌릴 수 있습니다. 실무에서는 필수입니다.
2) nano sample.c (코드 입력하기)
추가할 것: vim 또는 VS Code
설명: nano는 좋지만 기능이 너무 단순합니다. 코드 줄 번호를 보거나 문법 강조(색깔)를 제대로 보려면 나중에는 vi 계열이나 VS Code(Remote-WSL)로 넘어가는 게 좋습니다.
3) gcc -o sample sample.c (컴파일) ★ 여기가 제일 중요
이 단계는 단순히 "변환"만 하는 게 아니라, 디버깅을 위한 준비를 해야 합니다. 명령어를 아래처럼 바꿔보세요.
변경 전: gcc -o sample sample.c 변경 후: gcc -g -Wall -o sample sample.c
-g 옵션 (필수): 실행 파일 안에 "디버깅 정보(족보)"를 심어줍니다. 이게 있어야 나중에 에러가 났을 때 "몇 번째 줄에서 죽었는지" 알 수 있습니다.
-Wall 옵션 (권장): "Warning All"의 약자입니다. 에러는 아니지만 실수할 만한 문법(경고)을 깐깐하게 다 알려줍니다.
3.5) make (빌드 자동화)
매번 gcc -g -Wall... 이렇게 길게 치기 귀찮겠죠? 파일이 10개가 넘어가면 더 힘듭니다. 이 명령어를 파일(Makefile)에 미리 적어두고, 터미널에 make라고만 치면 알아서 컴파일되게 만듭니다.
4) ./sample (실행 및 디버깅)
그냥 실행해서 잘 되면 다행이지만, Segmentation fault가 뜨거나 결과가 이상하면 도구를 붙여서 실행합니다.
디버거 사용: gdb ./sample
프로그램을 한 줄씩 실행하면서 변수 값을 뜯어볼 수 있습니다. (아까 -g 옵션을 넣어야 작동함)
메모리 검사: valgrind ./sample
메모리 누수(Memory Leak)나 잘못된 메모리 접근을 현미경처럼 찾아줍니다. (설치 필요: sudo apt install valgrind)
03 library
한 눈에 보는 차이점(비유)
✅ static library
-
개념: 컴파일할 때 라이브러리의 코드(hello.c의 기계어)를 내 실행 파일(main) 안에 그대로 복사해서 넣습니다.
-
장점: 이 실행 파일 하나만 있으면 어디서든 돌아갑니다. (의존성 없음) 실행 속도가 아주 미세하게 더 빠를 수 있습니다.
-
단점: 실행 파일 용량이 커집니다.
라이브러리에 버그가 있어서 고치면, 내 프로그램을 다시 컴파일해야 합니다. -
만드는 법: ar (archiver) 명령어를 씁니다.
✅ shared library
-
개념: 실행 파일에는 라이브러리의 코드가 들어가지 않고, "어디에 있다"는 주소(Link)만 기록됩니다. 프로그램이 시작될 때 리눅스(OS)가 이 파일을 메모리에 로딩해서 연결해 줍니다.
-
장점: 실행 파일 용량이 매우 작습니다.
-
메모리 절약: printf 같은 기능은 모든 프로그램이 쓰죠? 메모리에 딱 한 번만 올려두고 모두가 공유해서 씁니다. (그래서 Shared)
라이브러리만 교체하면 프로그램 재컴파일 없이 업데이트가 가능합니다. -
단점: 실행할 때 그 라이브러리 파일(.so)이 없으면 에러가 나면서 실행조차 안 됩니다.
-
만드는 법: gcc에 -shared -fPIC 옵션을 씁니다.
✅ dynamic library
-
주의: 리눅스에서는 보통 Shared Library(.so)를 사용하는 방식을 통틀어 Dynamic Linking이라고 부릅니다.
-
하지만 좁은 의미로 "Dynamic Loading"은 프로그램이 시작될 때가 아니라, 실행 도중에(Runtime) 코드가 필요해지면 그때 라이브러리를 메모리로 불러오는 방식입니다.
-
용도: 주로 플러그인 시스템을 만들 때 씁니다. (예: 포토샵 필터, 게임 모드 등 필요할 때만 불러오는 기능)
-
사용법: 소스 코드 안에서 dlopen(), dlsym() 같은 특별한 함수를 써서 코딩합니다.
