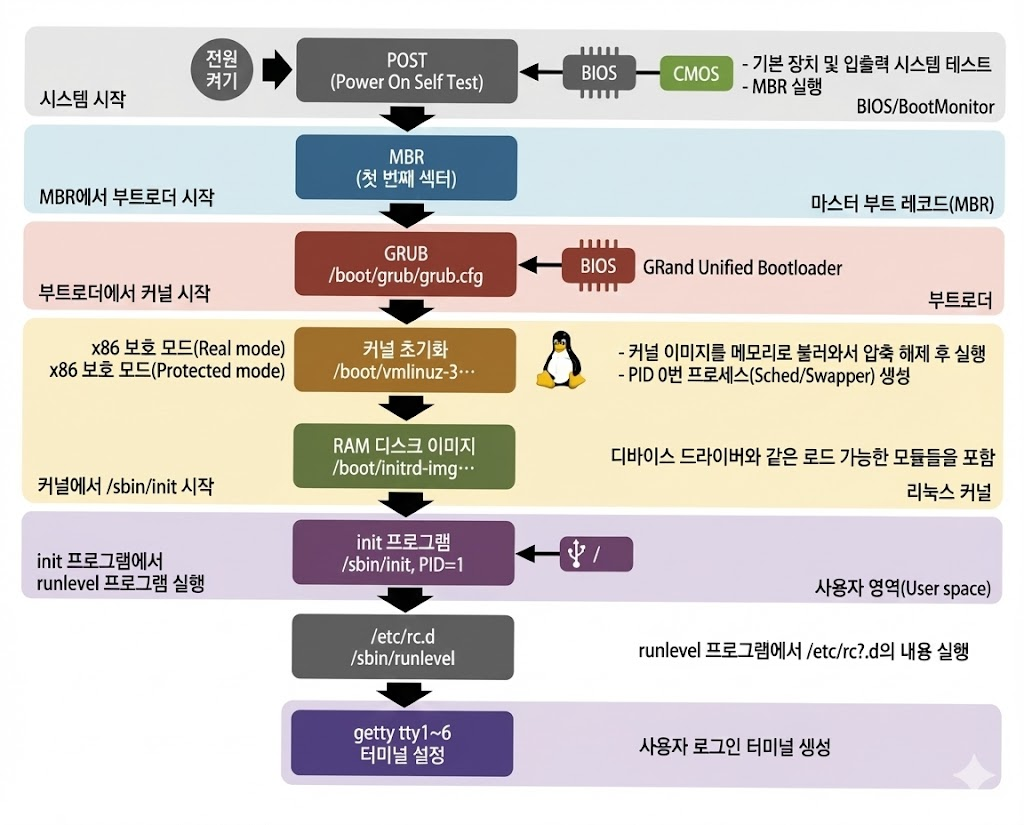
💻 리눅스 부팅 과정
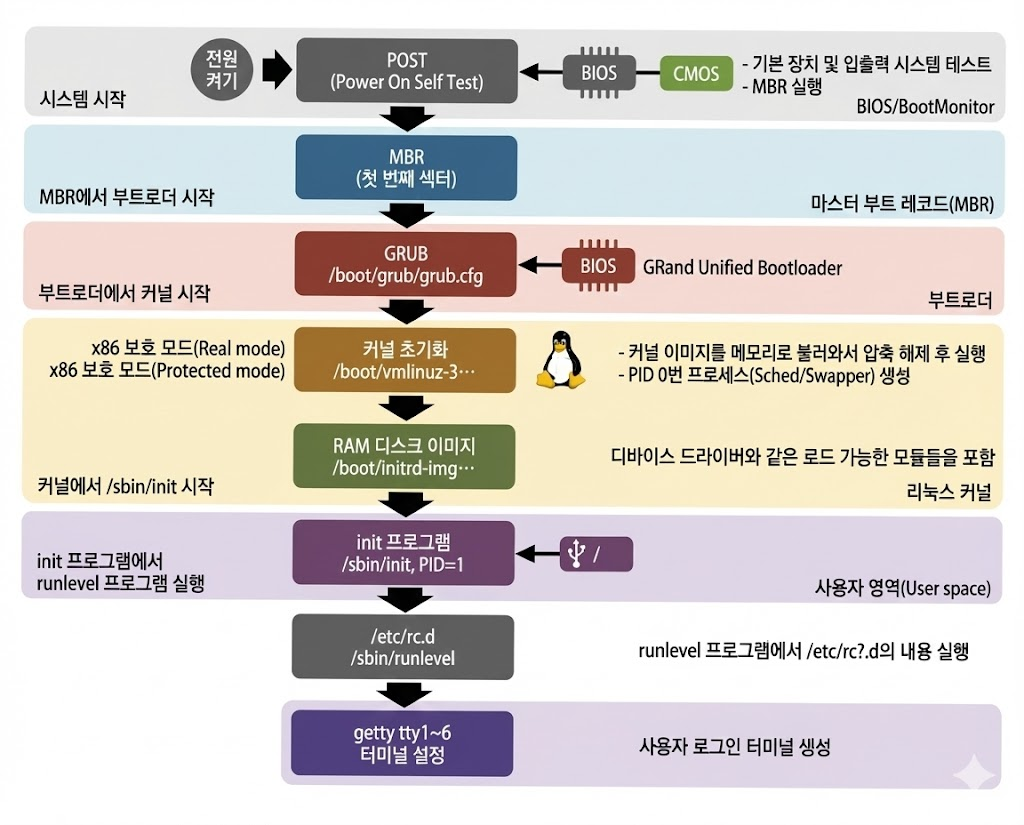
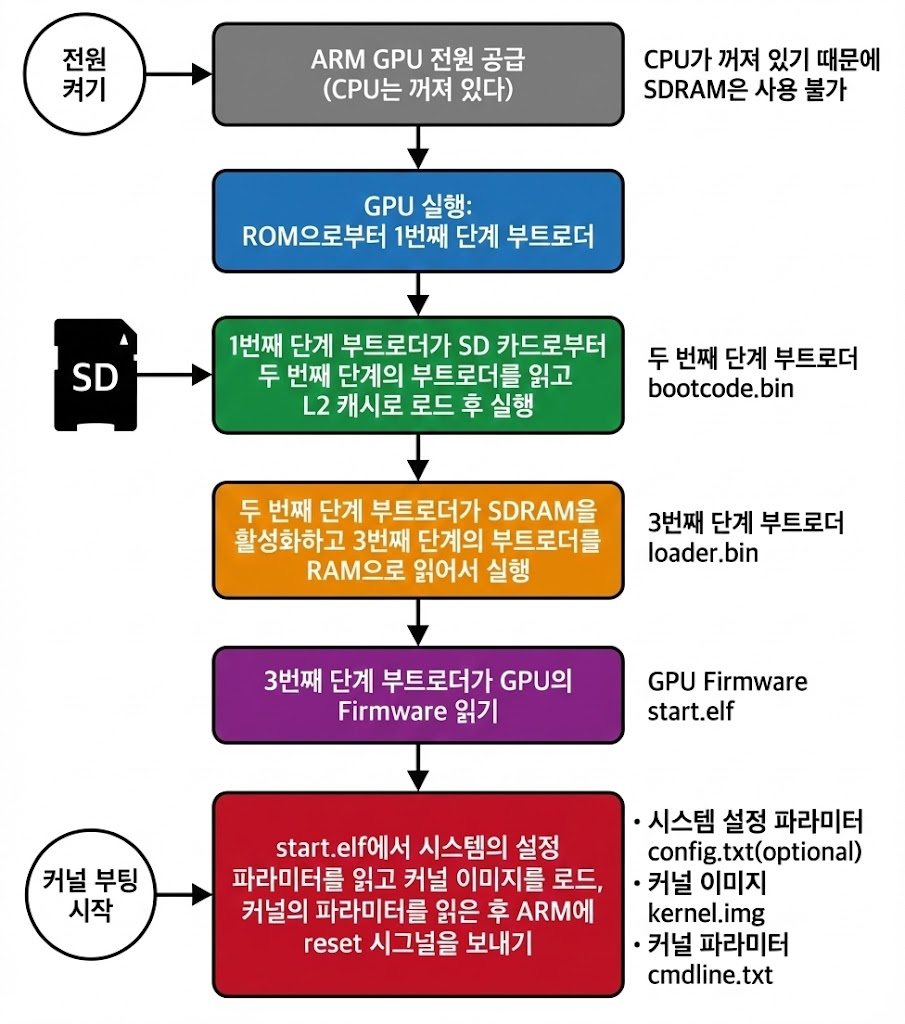
📲 라즈베리파이 부팅 과정
[ 25.12.15 (월) - 리눅스 프로그래밍(프로세스와 스레드) ]
01. 프로세스
"운영체제" : 스케줄, 우선순위 매우 중요
- bash -> hello
- by fork() -> by exec
1) dynamic schedule : nice 명령어 (priority)
CFS 스케줄링 - Completely Fairness Schedule
"완전 공평" - 잘난놈은 잘난대로, 못난놈은 못난대로.
vruntime = 적재총수행시간(가상시간:가중치적용)
2) static schedule : 변경가능 on the fly
스케일이 다르다. 리눅스에서 RT (Real Time) 용어는 좀 다르다.
우선순위가 가장 높은 프로세스가 여러개면 나눠먹기, 먼저 등등.. FIFO나 RR(Round Robin) 등에 따라 다르다.
1) 🔍 프로세스의 기본 개념 및 관리
: 프로세스의 정의와 상태, 그리고 커널이 이를 어떻게 관리하는지 이해하는 것이 기본입니다.
< 프로세스(Process) vs. 프로그램(Program) >
- 프로그램은 디스크에 저장된 정적인 엔터티(실행 파일)입니다.
- 프로세스는 실행 중인 프로그램의 인스턴스로, 메모리 공간, 레지스터, 스택, 힙 등 자원을 할당받은 동적인 엔터티입니다.
< 프로세스 상태 (Process State) >
- 생성(New), 실행(Running), 대기(Waiting/Blocked), 준비(Ready), 종료(Terminated) 등의 상태와 그 전이(Transition) 과정을 이해해야 합니다.
- 프로세스 제어 블록 (PCB, Process Control Block):
- 커널이 프로세스에 대한 중요한 정보를 저장하는 자료 구조(PID, 상태, 레지스터 값, 메모리 관리 정보 등)입니다.
< Context Switching (문맥 교환) >
- CPU가 한 프로세스에서 다른 프로세스로 제어권을 넘겨줄 때, 이전 프로세스의 상태를 PCB에 저장하고 새 프로세스의 상태를 PCB에서 로드하는 과정입니다. 이는 스케줄링의 핵심 비용(overhead)이 됩니다.
2) 🔍 프로세스 생성 및 관계
📌 fork() 시스템 호출
현재 실행 중인 부모 프로세스를 복사하여 자식 프로세스를 생성합니다. 부모와 자식은 거의 동일한 복사본이지만 PID만 다릅니다.
📌 exec() 계열 시스템 호출
현재 프로세스의 메모리 공간에 새로운 프로그램(실행 파일)을 로드하고 실행하여 프로그램 자체를 교체합니다. (새로운 프로세스를 만드는 것은 아님)
📌 wait() / waitpid() 시스템 호출
부모 프로세스가 자식 프로세스의 종료를 기다리거나 자식의 종료 상태를 확인하여 자식 프로세스의 리소스를 해제(회수)하는 방법입니다.
📌 좀비 프로세스 (Zombie Process) 및 고아 프로세스 (Orphan Process)
wait() 호출 없이 종료된 자식 프로세스의 상태(PCB)가 남아있는 것이 좀비 프로세스입니다.
부모가 자식보다 먼저 종료되어 자식이 init 프로세스에 입양되는 경우가 고아 프로세스입니다.
3) 🔍 프로세스 스케줄링
A. 스케줄링 정책 및 목표
-
목표: CPU 이용률 최대화, 처리량(Throughput) 최대화, 응답 시간(Response Time) 최소화, 대기 시간(Waiting Time) 최소화, 공정성(Fairness) 등
-
선점형 (Preemptive) vs. 비선점형 (Non-preemptive)
-선점형: 실행 중인 프로세스를 강제로 멈추고 다른 프로세스에게 CPU를 할당할 수 있습니다. (주로 시분할 시스템에 사용)
-비선점형: 프로세스가 스스로 CPU 사용을 종료하거나 대기 상태로 갈 때까지 CPU를 점유합니다.
B. 주요 스케줄링 알고리즘
📌 정적 스케줄링 (Static Scheduling): 실행 전에 결정된 순서대로 CPU를 할당합니다.
FCFS(First-Come, First-Served): 먼저 도착한 프로세스에게 먼저 CPU를 할당합니다.SJF(Shortest-Job-First): 실행 시간이 가장 짧은 프로세스에게 CPU를 먼저 할당합니다. (비선점형)SRTF(Shortest-Remaining-Time-First): 남은 실행 시간이 가장 짧은 프로세스에게 CPU를 먼저 할당합니다. (선점형 SJF)Priority Scheduling: 우선순위가 높은 프로세스에게 CPU를 먼저 할당합니다. (기아 현상(Starvation) 문제와 해결책인 Aging(노화) 이해)
📌 동적 스케줄링 (Dynamic Scheduling): 실행 중에 발생하는 상황(I/O, 이벤트 등)에 따라 실시간으로 CPU 할당을 변경합니다.
Round Robin (RR): 시분할 시스템의 핵심. 각 프로세스에 정해진 시간 할당량(Time Quantum 또는 Time Slice)을 주고, 이 시간 내에 완료하지 못하면 준비 큐의 맨 뒤로 이동합니다.Multilevel Queue (MLQ)/Multilevel Feedback Queue (MLFQ): 프로세스들을 여러 큐로 분류하고 각 큐마다 다른 스케줄링 알고리즘을 적용합니다. 특히 MLFQ는 프로세스가 큐 간에 이동(Feedback)하여 동적으로 우선순위를 변경합니다.
4) 🔍 스레드 (Thread)
: 프로세스 내에서 병행성을 달성하는 경량 프로세스 개념입니다.
📌 스레드 vs. 프로세스
스레드는 코드, 데이터, 파일 등의 자원을 프로세스와 공유하지만, 레지스터, 스택, 스레드 ID는 독자적으로 가집니다. (Context Switching 비용이 더 저렴)- 멀티스레딩을 통해 하나의 프로세스 내에서 여러 작업을 병렬적으로 처리합니다.
- POSIX Threads (Pthreads): 리눅스/유닉스 환경에서 표준으로 사용되는 스레드 API를 학습합니다.
- 커널 스레드 vs. 사용자 스레드: 커널이 직접 관리하는지, 사용자 레벨 라이브러리가 관리하는지에 따른 차이점을 이해합니다.
5) 🔍 프로세스 간 통신 (IPC, Inter-Process Communication)
: 독립적인 프로세스들이 서로 데이터를 교환하고 동기화하는 방법을 학습합니다.
📌 파이프 (Pipe): 단방향 통신, 부모-자식 관계의 프로세스 간 통신에 주로 사용됩니다. (| 연산자)
📌 메시지 큐 (Message Queue): 메시지 단위로 통신하며, 간접 통신이 가능합니다.
📌 공유 메모리 (Shared Memory): 가장 빠른 통신 방식. 프로세스들이 특정 메모리 영역을 공유하여 직접 데이터를 읽고 씁니다. (동기화 문제 발생 가능성 높음)
📌 세마포어 (Semaphore) 및 뮤텍스 (Mutex): 공유 자원에 대한 접근을 제어하여 프로세스 간 동기화 문제를 해결하는 도구입니다.
이러한 핵심 내용들을 C 언어를 사용하여 직접 fork(), exec(), pipe(), pthread_create() 등의 시스템 함수를 구현하고 테스트해 보는 것이 가장 효과적인 학습 방법입니다.
02. 시그널
⚙️ 시그널의 본질: 소프트웨어 인터럽트
시그널(Signal)은 커널이 프로세스에게
"중요한 사건이 발생했음"을 알리는 비동기적인 알림 메커니즘입니다.
A. 하드웨어 인터럽트 vs. 시그널
먼저 기존에 학습하신 하드웨어 인터럽트와 비교하면 이해가 쉽습니다.
-
하드웨어 인터럽트: 키보드 입력이나 타이머 만료 같은 하드웨어 사건이 CPU에게 전기 신호를 보냅니다. CPU는 하던 일을 멈추고 커널의 인터럽트 핸들러를 실행합니다.
-
시그널 (소프트웨어 인터럽트): 특정 사건(예: 0으로 나누기, 자식 프로세스 종료, 사용자 종료 요청)이 발생하면, 커널이 해당 프로세스에게 신호를 보냅니다. 프로세스는 하던 일을 멈추고 시그널 핸들러를 실행합니다.
즉, 시그널은 운영체제가 프로세스에게 보내는 가상의 인터럽트입니다.
🧠 시그널 처리 과정과 Program Counter (PC)
: 프로세스가 실행 중일 때 시그널이 도착하면, Program Counter (PC)와 Context가 어떻게 변하는지가 핵심입니다.
▶️ 01) 정상 실행 중
: 프로세스의 PC는 메모리 상의 다음 명령어를 가리키며 순차적으로 실행 중입니다.
▶️ 02) 시그널 도착 및 중단 (Interrupt):
- 시그널이 도착하면 커널은 프로세스의 실행을 일시 중지합니다.
- 이때, 현재의 PC 값(다음에 실행할 명령어 주소)과 레지스터 상태(Context)를 커널 스택(또는 유저 스택의 특정 공간)에 백업(Save)합니다. 이것이 중요합니다. 나중에 돌아와야 하기 때문입니다.
▶️ 03) 핸들러 실행 (Handler Execution):
- 커널은 PC를 강제로 시그널 핸들러 함수(Signal Handler)의 시작 주소로 덮어씁니다.
- CPU는 이제 원래 코드가 아닌, 시그널 핸들러 코드를 실행하게 됩니다.
▶️ 04) 복귀 (Return):
- 핸들러 함수가 종료(return)되면, sigreturn 시스템 콜을 통해 백업해두었던 원래의 PC 값과 레지스터 상태를 복원(Restore)합니다.
- 프로세스는 마치 아무 일도 없었던 것처럼 중단되었던 지점부터 다시 실행을 계속합니다.
🚨 주요 시그널 종류
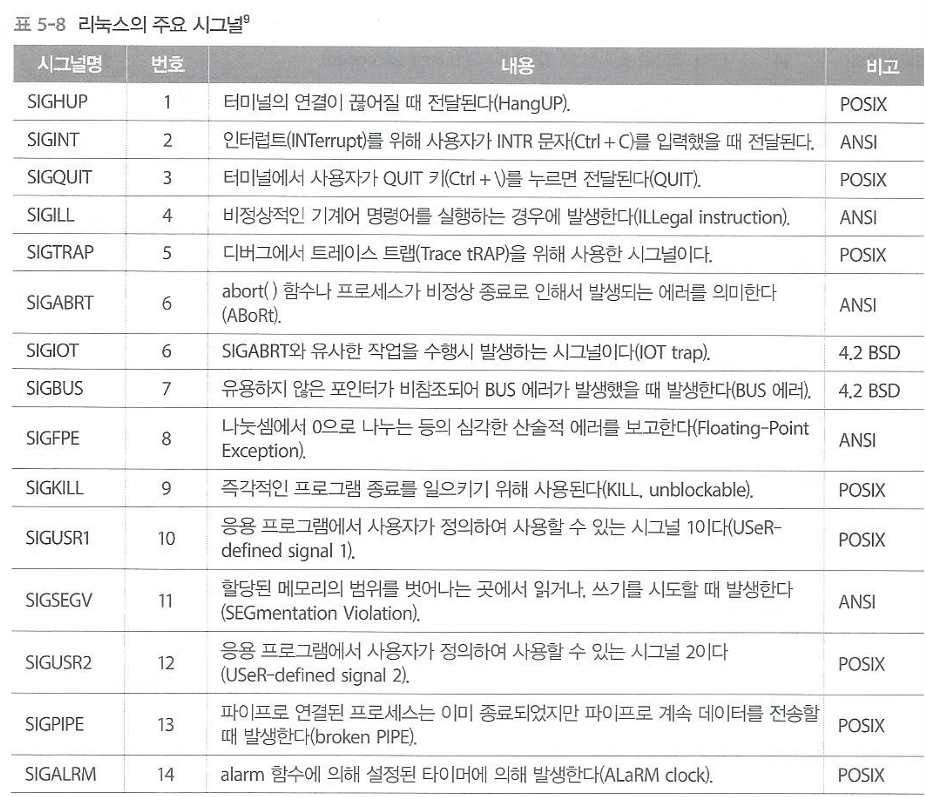
: 리눅스에는 약 64여 개의 시그널이 있지만, 프로그래밍에서 자주 다루는 핵심 시그널은 다음과 같습니다. (kill -l 명령어로 전체 확인 가능)
✅ SIGINT (Signal Interrupt)
- 키보드에서 Ctrl + C를 입력할 때 발생.
- 기본 동작: 프로세스 종료. (사용자가 프로그램을 멈추고 싶을 때 보냄)
✅ SIGSEGV (Signal Segmentation Violation)
- 프로세스가 허용되지 않은 메모리 영역에 접근할 때 발생 (예: NULL 포인터 역참조).
- 임베디드/시스템 프로그래밍에서 가장 흔하게 마주치는 오류입니다.
- 기본 동작: 코어 덤프(Core Dump)를 남기고 비정상 종료.
✅ SIGCHLD (Signal Child)
- 자식 프로세스가 종료되거나 멈출 때 부모 프로세스에게 전달됨.
- 부모는 이 시그널을 받아서 wait() 함수를 호출해 자식의 자원을 회수(좀비 프로세스 방지)합니다.
✅ SIGKILL vs SIGTERM
- SIGTERM (Terminate): "안전하게 종료해라"라고 요청하는 신호. 프로세스가 이 신호를 받아서 자원 정리 후 종료할 수 있음 (핸들링 가능).
- SIGKILL (Kill): "즉시 죽어라". 프로세스가 거부하거나 무시할 수 없음. 커널이 즉시 강제 종료시킴 (핸들링 불가능).
🛠️ 시그널 처리 방법 (Signal Handling)
: 개발자는 시그널이 들어왔을 때 프로세스가 어떻게 행동할지 결정할 수 있습니다.
▶️ 01) 기본 동작 수행 (Default): 따로 코드를 작성하지 않으면 커널이 정한 기본 동작(대부분 종료)을 수행합니다.
▶️ 02) 시그널 무시 (Ignore): 시그널이 와도 아무 일도 안 일어나게 설정합니다. (단, SIGKILL, SIGSTOP은 무시 불가)
▶️ 03) 사용자 정의 핸들러 호출 (Catch): 미리 정의해 둔 함수(핸들러)를 실행하도록 설정합니다. (예: SIGINT가 오면 "종료하시겠습니까?" 묻는 기능 구현)
🚀 핵심 시스템 호출 (System Calls)
signal(): 예전 방식(ANSI C 표준). 간단하지만 이식성 문제가 있을 수 있음.sigaction(): POSIX 표준 방식. 더 정교한 제어가 가능하며 리눅스 프로그래밍에서 권장되는 방식입니다.kill(): 다른 프로세스에게 시그널을 보내는 함수 (이름은 kill이지만 실제로는 '신호 전송'의 의미).
⚠️ 주의사항: Reentrancy (재진입성)
-
시그널은 비동기적으로 언제든 발생하여 현재 실행 흐름을 끊고 들어옵니다.
-
만약 malloc() 함수를 실행 중에 시그널이 와서, 시그널 핸들러 안에서 또 malloc()을 호출하면 꼬일 수 있습니다. (메모리 할당 구조가 망가짐)
-
따라서 시그널 핸들러 내부에서는 ''Async-Signal-Safe(재진입 안전한)'' 함수만 사용해야 합니다. (예: printf는 안전하지 않음, write는 안전함).
이러한 내용을 바탕으로, "직접 SIGINT를 핸들링하여 Ctrl+C를 눌러도 종료되지 않고 메시지를 출력하는 코드"를 작성해 보면 PC가 어떻게 가로채지는지 체감할 수 있습니다.
03. About... NAND flash(저장소), mDDR(메모리)
: "데이터가 어디에 존재하고, CPU가 어떻게 접근하는가?"를 다루는 메모리 계층 구조(Memory Hierarchy)의 이해가 필수적.

🏗️ 전체 그림: 메모리 계층 구조 (Memory Hierarchy)
지금까지 배운 프로세스는 실행 중인 프로그램입니다. 그렇다면 "실행 전의 프로그램"은 어디에 있고, "실행 중인 데이터"는 어디에 있을까요?
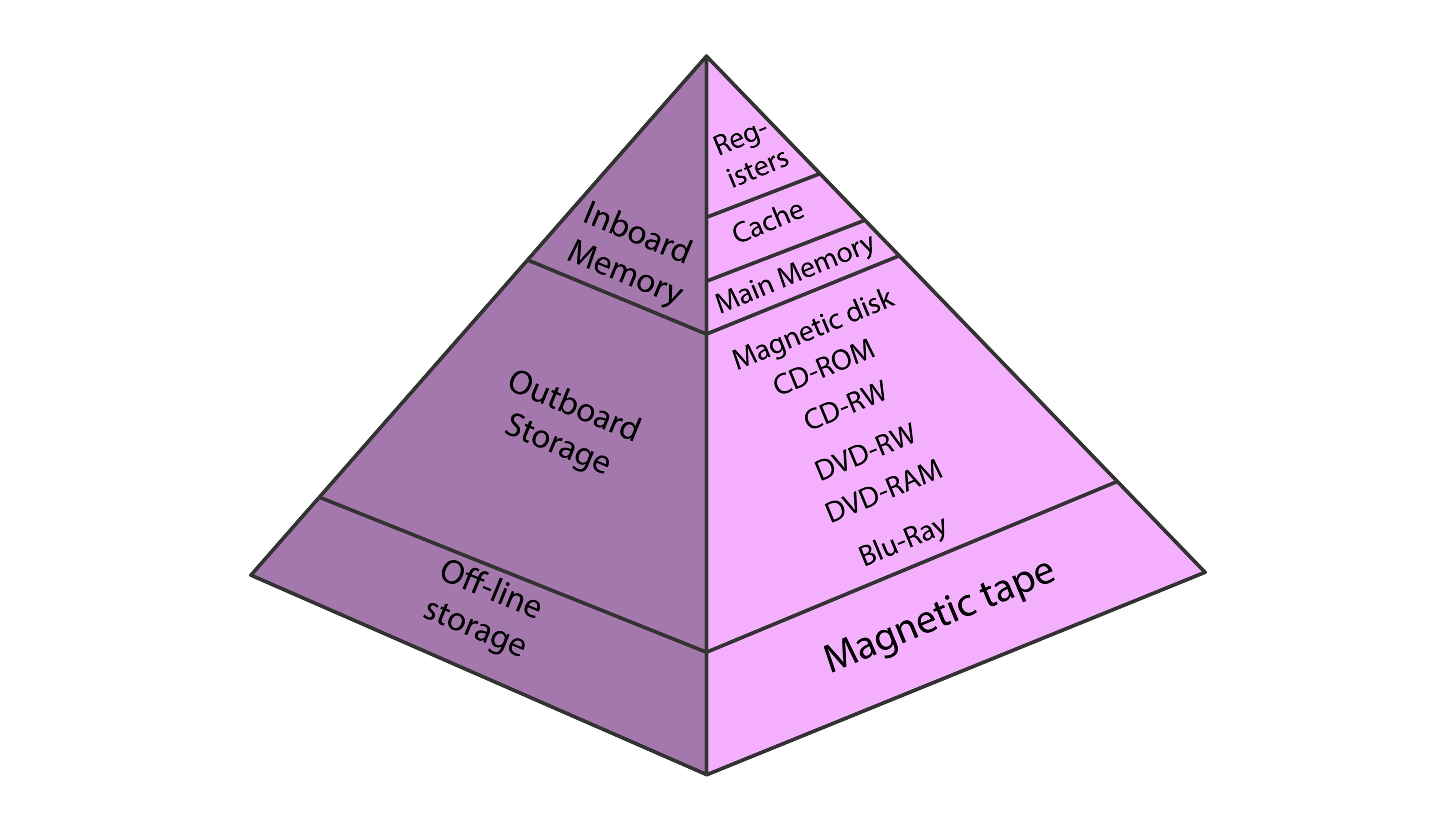
-> 위 이미지를 보면서 아래 개념을 연결해보세요.
-
CPU (Register/Cache): 가장 빠름. 현재 실행 중인 명령어(PC가 가리키는 곳)와 데이터가 존재. -
mDDR (Main Memory): "책상" 역할. 프로세스가 실행(Running)될 때, 코드와 변수(Stack, Heap)가 펼쳐지는 공간. (휘발성) -
NAND Flash (Storage): "책장" 역할. 실행 파일(프로그램), OS 이미지, 로그 파일 등이 저장되는 공간. (비휘발성)
⚡ mDDR (Mobile Double Data Rate) - 프로세스의 운동장
: mDDR은 일반 DDR 메모리보다 전력 소모를 줄인(Mobile) RAM입니다.
리눅스 프로그래밍 관점에서 알아야 할 핵심 개념은 다음과 같습니다.
A. 가상 메모리와 MMU (Memory Management Unit)
-
연결점: 앞서 배운 fork()나 프로세스의 메모리 공간(Text, Data, Heap, Stack)은 실제 물리적인 mDDR 주소를 직접 쓰지 않습니다.
-
개념: 가상 주소(Virtual Address)를 사용합니다. CPU가 가상 주소로 접근하면, MMU라는 하드웨어가 이를 실제 mDDR의 물리 주소(Physical Address)로 변환해줍니다.
-
핵심: 프로세스마다 독립된 메모리 공간을 갖는 것처럼 보이게 해주는 것이 바로 이 메커니즘 덕분입니다.
B. 타이밍(Timing)과 리프레시(Refresh)
-
DRAM은 전기가 통하지 않으면 데이터가 사라지며, 주기적으로 전하를 다시 채워주는 Refresh 작업이 필요합니다.
-
임베디드 개발자는 이 타이밍 설정이 맞지 않으면 부팅이 안 되거나 데이터가 깨지는 현상을 겪게 됩니다.
💾 NAND Flash - 데이터의 영구 저장소
: NAND는 전원이 꺼져도 데이터가 남는 저장소입니다. 하지만 RAM과 달리 접근 방식이 독특하여 특별한 관리가 필요합니다.
A. 블록 디바이스와 I/O 인터럽트
-
연결점: 프로세스가 파일을 읽으려(read()) 하면, CPU는 NAND 컨트롤러에게 "데이터 가져와"라고 시킵니다. NAND는 RAM보다 매우 느립니다.
-
개념: CPU는 데이터를 기다리며 멍하니 있지 않습니다. 해당 프로세스를 대기(Blocked) 상태로 바꾸고 다른 프로세스를 스케줄링합니다.
-
인터럽트: NAND에서 데이터 읽기가 끝나면, NAND 컨트롤러가 CPU에게 하드웨어 인터럽트를 보냅니다. "데이터 준비됐어!"라고 알리면, 커널은 다시 해당 프로세스를 준비(Ready) 상태로 깨웁니다.
B. 페이지(Page) vs 블록(Block) 구조
-
쓰기 특성: NAND는 읽기/쓰기는 페이지 단위(예: 4KB)로 하지만, 지우기(Erase)는 블록 단위(예: 128KB ~ 512KB)로만 가능합니다.
-
덮어쓰기 불가: 램(RAM)처럼 바로 덮어쓰기가 안 됩니다. 반드시 지우고(Erase) -> 써야(Write) 합니다.
C. FTL (Flash Translation Layer)
- 위의 복잡한 지우기/쓰기 특성을 파일 시스템이 일일이 신경 쓰지 않도록, 중간에서 논리 주소를 물리 주소로 매핑해주고 불량 블록(Bad Block)을 관리해주는 소프트웨어(펌웨어) 계층입니다.
04. 프로세스 간 통신

: 리눅스에서 프로세스는 자신만의 독립된 메모리 공간(가상 주소 공간)을 가지기 때문에, 다른 프로세스의 변수나 데이터에 직접 접근할 수 없습니다.
- 이 독립성을 극복하고 데이터를 주고받기 위한 기술이 바로 IPC (Inter-Process Communication)입니다.
IPC는 크게 데이터 전송(Data Transfer) 방식과 공유 메모리(Shared Memory) 방식으로 나뉩니다. 학습해야 할 핵심 개념과 주요 메커니즘을 정리해 드립니다.
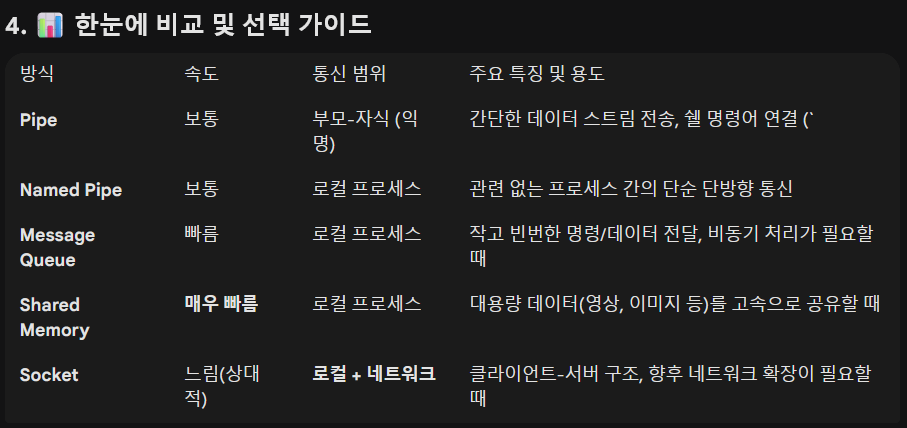
🚰 데이터 전송 (Data Transfer) 모델
: 커널을 통해 데이터를 한쪽에서 다른 쪽으로 복사해서 전달하는 방식입니다.
🚨 A. 파이프 (Pipe) - "단방향 통신의 정석"
: 가장 오래되고 기본적인 IPC 방식입니다. 물이 흐르는 파이프처럼 데이터가 한 방향으로만 흐릅니다.
< 익명 파이프 (Anonymous Pipe) >
- pipe() 시스템 콜 사용.
- 부모-자식 프로세스 간의 통신에만 사용할 수 있습니다.
- 파일 디스크립터(fd)를 통해서만 접근하며, 외부에서는 보이지 않습니다.
< 명명 파이프 (Named Pipe / FIFO) >
- mkfifo 명령이나 함수 사용.
- 파일 시스템에 특수 파일 형태로 존재합니다. 따라서 서로 관련 없는 프로세스끼리도 통신이 가능합니다.
- 여전히 단방향(Half-duplex)입니다. 양방향 통신을 하려면 파이프를 2개 만들어야 합니다.
🚨 B. 메시지 큐 (Message Queue) - "편지함"
: 데이터를 바이트 스트림(Byte Stream)이 아닌 구조화된
메시지(Message)단위로 주고받습니다.
= 커널 주소 공간에 존재하는 메시지의 연결 리스트(Linked List): 파이프와 달리 "데이터의 경계(Boundary)"가 명확하고, "우선순위(Priority)"를 지정할 수 있다는 강력한 장점이 있습니다.
< 특징 >
- 메시지마다 유형(Type)을 부여할 수 있어, 수신자가 원하는 유형의 메시지만 골라서 읽을 수 있습니다.
- 비동기(Asynchronous) 통신이 가능합니다. (보내는 쪽은 큐에 넣고 바로 다른 일을 할 수 있음)
- 표준: System V IPC(구형, msgget)와 POSIX IPC(신형, mq_open) 두 가지 표준이 있으며, 리눅스에서는 POSIX 방식이 더 직관적이고 권장됩니다.
🔬 POSIX 메시지 큐 상세 분석
: 가장 많이 쓰이는 POSIX 방식을 기준으로 깊게 들어갑니다.
A. 메시지 우선순위 (Priority)
: POSIX MQ의 가장 강력한 기능입니다.
- mq_send를 할 때 우선순위(숫자)를 같이 보냅니다.
- 큐에 메시지가 쌓여 있어도, 우선순위가 높은 메시지가 새치기를 해서 맨 앞으로 갑니다.
- 활용: 시스템 로그(우선순위 낮음)와 긴급 정지 신호(우선순위 높음)를 같은 큐로 처리할 때, 긴급 신호를 즉시 처리할 수 있습니다.
B. 주요 함수 및 흐름
01)
mq_open(): 큐를 생성하거나 엽니다.
- 이름은 반드시 /로 시작해야 합니다. (예: /test_mq)
- O_CREAT, O_RDWR 등의 플래그를 사용합니다.
02)
mq_send(): 메시지를 보냅니다. (큐가 꽉 차면 Block 됨)03)
mq_receive(): 메시지를 읽습니다. (큐가 비면 Block 됨)
- 주의: 버퍼 크기는 반드시 큐의 msgsize 속성보다 커야 합니다. 아니면 에러(EMSGSIZE) 발생.
04)
mq_close(): 프로세스 내에서 큐와의 연결을 끊습니다.05)
mq_unlink(): 커널에서 큐를 완전히 삭제합니다. (매우 중요)

🚨 C. 소켓 (Socket) - "확장성의 끝판왕"
: 원래 네트워크 통신을 위해 만들어졌지만, 같은 컴퓨터 내의 프로세스끼리 통신할 때도 매우 많이 쓰입니다.
- Unix Domain Socket: 로컬 통신 전용으로, TCP/IP보다 오버헤드가 적고 빠릅니다.
- 장점: 양방향 통신(Full-duplex)이 자유롭고, 나중에 프로그램이 서로 다른 컴퓨터로 분리되어도 코드를 크게 칠 필요가 없습니다.
🧠 공유 메모리 (Shared Memory) 모델
: IPC 중 가장 빠른 속도를 자랑하는 방식입니다.
< 원리 >
- 커널이 관리하는 물리 메모리의 일부를 두 프로세스의 가상 주소 공간에 매핑(Mapping)합니다.
- 데이터 복사(Copy)가 발생하지 않고, 바로 메모리에 쓰고 읽기 때문에 오버헤드가 거의 없습니다.
< 단점 (치명적) >
- 동시에 같은 메모리 번지에 쓰려고 할 때 데이터가 깨지는 경쟁 상태(Race Condition)가 발생할 수 있습니다.
- 반드시 동기화(Synchronization) 메커니즘과 함께 사용해야 합니다.
🛡️ 동기화 (Synchronization) - IPC의 필수 짝꿍
: 공유 메모리나 전역 자원을 안전하게 보호하기 위한 도구들입니다.
✅ A. 세마포어 (Semaphore)
- 개념: 공유 자원의 개수를 나타내는 카운터(Counter) 기반의 잠금 장치입니다.
- 동작:
P 연산 (Wait): 카운트를 감소시킴. 0이면 대기. (들어갈 때)
V 연산 (Signal): 카운트를 증가시킴. 대기 중인 프로세스를 깨움. (나올 때)
이진 세마포어(Binary Semaphore): 0과 1만 가지며, 뮤텍스와 유사하게 동작합니다.✅ B. 뮤텍스 (Mutex)
- 개념: "Mutual Exclusion(상호 배제)"의 약자. 소유권이 있는 잠금 장치(Lock)입니다.
- 특징: 자물쇠를 잠근(Lock) 프로세스만이 자물쇠를 열(Unlock) 수 있습니다. 스레드 간 동기화에 주로 사용됩니다.
05. Pipe의 자세한 내용
: 파이프(Pipe)와 Named Pipe(FIFO)는 리눅스 IPC 중 가장 기본이 되면서도, "파일(File)"이라는 유닉스 철학을 가장 잘 보여주는 메커니즘입니다.
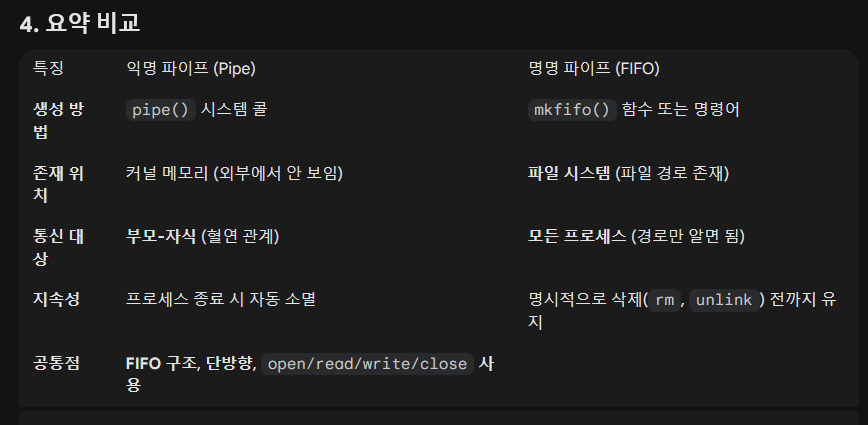
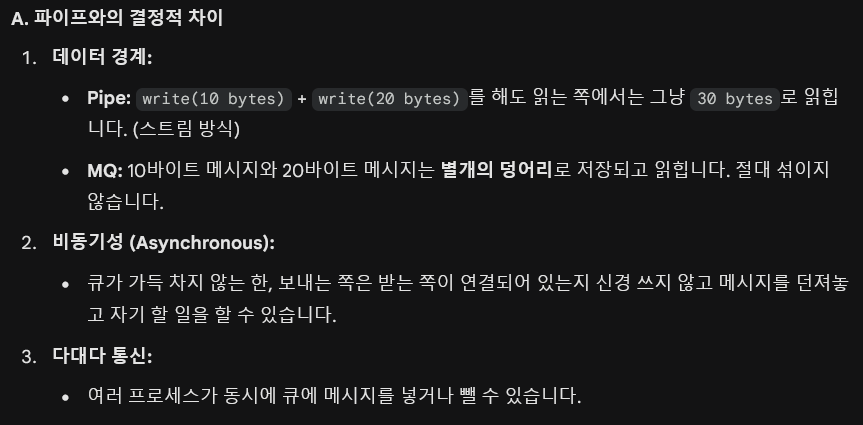
이 둘의 공통점은 "커널 영역에 생성된 버퍼(Buffer)"를 통해 데이터를 물 흐르듯(Stream) 전달한다는 점이며, 차이점은 "어떻게 접근하느냐(이름이 있냐 없냐)"입니다.
01) 익명 파이프 (Anonymous Pipe)
우리가 흔히 그냥 "파이프"라고 부르는 것입니다.
(아래는 익명 파이프 C 코드 예시.)
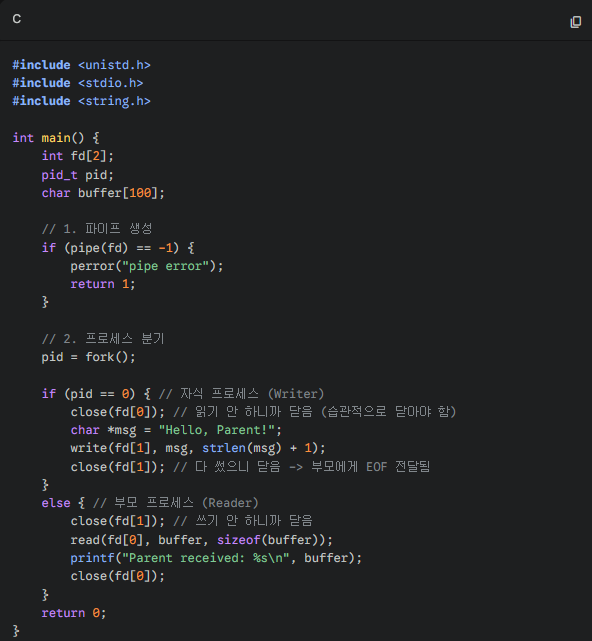
A. 핵심 특징
- 부모-자식 관계 전용: pipe() 함수를 호출하여 파이프를 만든 프로세스와, 그 프로세스가 fork()로 낳은 자식 프로세스 간에만 통신이 가능합니다. (파일 디스크립터를 상속받기 때문)
- 이름 없음: 파일 시스템에 존재하지 않습니다. 오직 실행 중인 커널 메모리에만 존재합니다.
- 단방향 (Unidirectional): 데이터는 한쪽으로만 흐릅니다. 양방향 통신을 하려면 파이프를 2개 만들어야 합니다.
B. 동작 원리 (파일 디스크립터): pipe(int fd[2]) 시스템 콜을 호출하면 커널은 버퍼를 만들고, 파일 디스크립터(fd) 두 개를 돌려줍니다.
- fd[0]: 읽기 전용 (Read end) - 수도꼭지 출구
- fd[1]: 쓰기 전용 (Write end) - 수도꼭지 입구
02) 명명 파이프 (Named Pipe / FIFO)
: 익명 파이프의 "관계된 프로세스끼리만 통신 가능"이라는 한계를 극복한 것입니다.
A. 핵심 특징 (FIFO)
- 파일 시스템에 존재: mkfifo 명령어나 함수로 생성하면, 디렉토리에 파일 형태로 보입니다. (ls -l로 보면 파일 타입이 p로 뜸)
- 관계 없는 프로세스 통신: 파일 경로(예: /tmp/my_fifo)만 알면, 전혀 상관없는 A 프로그램과 B 프로그램이 통신할 수 있습니다.
- FIFO (First-In, First-Out): 이름 그대로 먼저 들어간 데이터가 먼저 나옵니다. 중간 내용을 건너뛰거나 다시 읽을 수 없습니다(lseek 불가).
B. 동작 원리 (Blocking이 핵심): FIFO는 "동기화 포인트" 역할을 합니다.
- 어떤 프로세스가 FIFO를 읽기 위해 열었는데(open), 아직 쓰는 놈이 없다면? -> 쓰는 놈이 나타날 때까지 대기(Block)합니다.
- 반대로 쓰기 위해 열었는데, 읽는 놈이 없다면? -> 읽는 놈이 나타날 때까지 대기(Block)합니다.
- 이 특성 때문에 별도의 동기화 도구 없이도 두 프로세스의 타이밍을 맞출 수 있습니다.
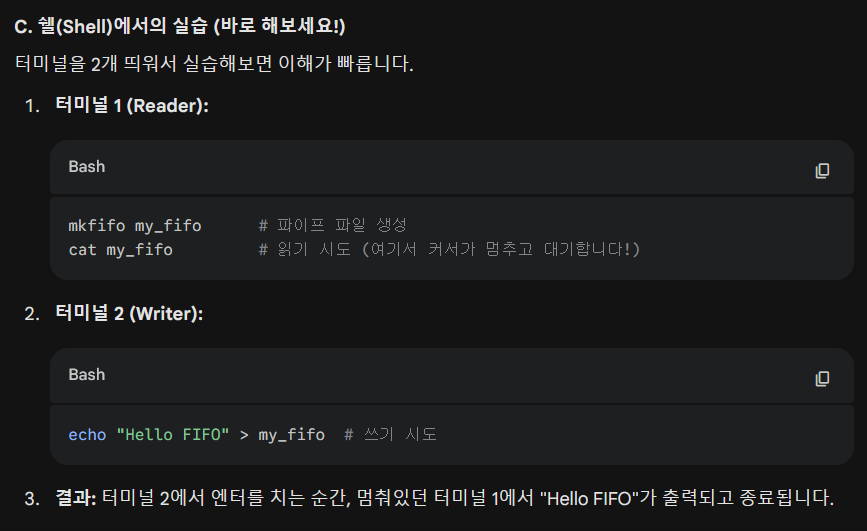
03) ⚠️ 깊이 있는 학습: 주의사항 및 상세 동작
: 실전 프로그래밍에서 파이프 사용 시 반드시 알아야 할 심화 내용입니다.
1. 원자성 (Atomicity)과 PIPE_BUF
- 여러 프로세스가 동시에 하나의 파이프에 쓰기를 시도하면 데이터가 섞일까요?
- 리눅스에는 PIPE_BUF (보통 4KB)라는 크기 제한이 있습니다.
- 4KB 이하의 데이터를 한 번에 write()하면, 데이터가 중간에 끊기거나 섞이지 않고 원자적(Atomic)으로 기록됨을 보장합니다.
2. SIGPIPE (Broken Pipe)
- 상황: 데이터를 열심히 파이프(fd[1])에 쓰고 있는데, 읽는 쪽 프로세스가 갑자기 파이프(fd[0])를 닫아버리고 종료했다면?
- 결과: 커널은 쓰는 프로세스에게 SIGPIPE 시그널을 보냅니다.
- 대처: 이 시그널을 핸들링하지 않으면 쓰는 프로세스도 강제 종료됩니다. 서버 프로그램 등을 짤 때 반드시 이 시그널을 무시(SIG_IGN)하거나 처리해줘야 서버가 죽지 않습니다.
3. 용량 제한
- 파이프는 무한하지 않습니다. (리눅스 최신 커널 기본값은 64KB 정도)
- 읽는 쪽이 데이터를 안 가져가서 파이프가 가득 차면, 쓰는 쪽의 write() 함수는 공간이 생길 때까지 무한정 대기(Block) 상태에 빠집니다.
[ 25.12.16 (화) - 리눅스 프로그래밍 (프로세스) ]
IPC ITC "Process / Task" - exeution entity --> scheduler --> CPU occupied
GPos - not realtime os ie, linux, windows, etc... -> PC, server "Process"
RTos - Realtime os ie, FreeRTos, VxWorks, Zyphyr -> for Embedded (실시간->장치) "Task"
📡 임베디드 리눅스 통신의 핵심 개념

임베디드 시스템에서 주변 장치(Peripherals)와 데이터를 주고받는 것은 시스템의 핵심 기능이며, 리눅스 커널은 이를 효율적으로 관리합니다.
one of means:
신호
1) kernel ---> process (user process)
2) process <--> process (aka. IPC)
3) windows : Messages ( WM_PAINT )
동기적 ( synchronous )
비동기적 ( asynchronous ) ie, 공 던지고 받기.
P1 <------------> P2
UART ( A : asynchronous )
USART ( A : asynchronous, S : synchronous )
speed : UART < USART ( share clock line )
process / thread
By. "Semaphore" and it's derivations.
1) 배타적 사용
ie, 화장실.
P1(o) P2(x)
2) 순서적 사용
이어 달리기.
one of IPC means:
pipe - unnamed pipe
fifo - name pipe ~~~ between other process
(ie, a.out vs b.out) by "file"
🔌 직렬 통신 하드웨어: UART와 USART
UART와 USART는 임베디드 시스템에서 가장 기본적이고 널리 사용되는 직렬(Serial) 통신 인터페이스입니다.
✅ UART (Universal Asynchronous Receiver/Transmitter)
- 비동기 (Asynchronous): 이름에서 알 수 있듯이, 데이터 전송 시 클럭 신호를 별도로 보내지 않습니다.
- 데이터 전송: 송신부와 수신부가 미리 정해진 속도(Baud Rate)를 사용하여 타이밍을 맞춥니다.
- 프레임: 데이터는 시작 비트(Start Bit)로 시작하고, 데이터 비트, 패리티 비트(선택적)를 거쳐 정지 비트(Stop Bit)로 끝나는 프레임 형태로 전송됩니다.
- 용도: GPS 모듈, 블루투스 모듈, 콘솔/디버그 포트 등 저속의 간단한 통신에 사용됩니다.
✅ USART (Universal Synchronous/Asynchronous Receiver/Transmitter)
- 동기/비동기 모두 지원: UART의 모든 기능(비동기)을 포함하며, 추가적으로 동기(Synchronous) 모드 통신도 지원합니다.
- 동기 모드: 데이터와 함께 별도의 클럭 신호(Clock Signal)를 전송 라인을 통해 보냅니다. 클럭을 통해 송수신 타이밍을 정확히 맞추므로, 고속 통신이나 정확한 타이밍이 필요한 통신 프로토콜(예: SPI, I2C의 일부 구현)에 사용될 수 있습니다. (다만, 실제 SPI/I2C는 전용 하드웨어 블록을 더 많이 사용합니다.)
- 용도: 더 빠르고 안정적인 통신이 필요할 때 사용되지만, 임베디드 리눅스 환경에서는 UART 모드로 더 자주 사용됩니다.
01. 공유 메모리 (Shared Memory)
IPC(Inter-Process Communication, 프로세스 간 통신)의 핵심인 공유 메모리(Shared Memory)와 이를 안전하게 제어하기 위한 세마포어(Semaphore)에 대해 알아보겠습니다.
이 두 가지는 보통 '짝'으로 함께 다닙니다.
📦 공유 메모리 (Shared Memory)
: "가장 빠른 IPC 메커니즘"
- 개념: 리눅스 시스템에서 각 프로세스는 자신만의 독립된 가상 메모리 공간을 가집니다. 공유 메모리는 물리 메모리의 특정 영역을 여러 프로세스가 함께 볼 수 있도록 매핑(Mapping)하는 기법입니다.
<작동 원리>
프로세스 A가 커널에 공유 메모리 공간 생성을 요청합니다.
커널은 고유한 ID(Key)를 가진 메모리 공간을 할당합니다.
프로세스 A와 프로세스 B는 이 공간을 자신의 가상 주소 공간에 첨부(Attach)합니다.
이제 A가 여기에 데이터를 쓰면, B는 별도의 복사 과정 없이 즉시 그 데이터를 읽을 수 있습니다.
-
장점 (핵심): 속도입니다. 파이프(Pipe)나 메시지 큐(Message Queue)와 달리, 데이터가 커널 공간을 거쳐 복사되는 오버헤드가 없습니다. 대용량 데이터(예: 카메라 영상 프레임) 처리에 필수적입니다.
-
단점: 동기화(Synchronization) 기능이 없습니다. 두 프로세스가 동시에 데이터를 쓰려고 하면 데이터가 깨질 수 있습니다.
비유 : 팀 프로젝트를 할 때, 각자 공책(개인 메모리)에 적어서 전달하는 것이 아니라, 회의실의 화이트보드(공유 메모리) 하나에 다 같이 쓰는 것과 같습니다. 빠르지만, 동시에 쓰려고 하면 글씨가 엉망이 됩니다.
💥 경쟁 상태 (Race Condition)와 임계 구역 (Critical Section)
: 이 두 가지 개념은 공유 메모리와 세마포어를 이해하는 데 필수적인 배경 지식입니다.
-
경쟁 상태 (Race Condition): 두 개 이상의 프로세스가 동시에 공유 자원을 변경하려고 할 때, 누가 먼저 접근하느냐에 따라 실행 결과가 달라지거나 엉망이 되는 상황입니다.
-
임계 구역 (Critical Section): 프로그램 코드 중에서 공유 자원(공유 메모리)에 접근하는 코드 블록을 말합니다. 이 구역은 한 번에 하나의 프로세스만 실행해야 합니다.
🧩 전체 그림: 공유 메모리와 세마포어의 협력
임베디드 시스템에서 센서 데이터를 처리하는 상황을 가정해 보겠습니다.
1) 준비 : shmget(공유 메모리 생성)과 semget(세마포어 생성, 초기값 1)을 수행합니다.
2) 프로세스 A (데이터 쓰기) :
-
P(sem): 세마포어를 확인합니다. 1이면 0으로 만들고 들어갑니다. (다른 놈들은 기다려!)
-
[임계 구역]: 공유 메모리에 센서 데이터를 씁니다.
V(sem): 세마포어를 1로 만듭니다. (다 썼다, 들어와!)
3) 프로세스 B (데이터 읽기) :
-
P(sem): 세마포어를 확인합니다. A가 쓰고 있어서 0이라면 대기합니다. 1이 되면 0으로 만들고 들어갑니다.
-
[임계 구역]: 공유 메모리에서 데이터를 읽어갑니다.
V(sem): 세마포어를 1로 증가시켜 잠금을 풉니다.
02. 세마포어(Semaphore)
🚦 "공유 자원을 지키는 신호등"
개념: 공유 메모리와 같은 공유 자원(Shared Resource)에 여러 프로세스가 동시에 접근하지 못하도록 제어하는 동기화 도구입니다. 본질적으로는 '정수형 변수(Counter)'입니다.
📌 핵심 연산 (원자적 연산)
- P 연산 (Wait/Lock): 자원을 사용하기 전에 실행합니다. 세마포어 값을 1 감소시킵니다. 값이 0이면, 누군가 자원을 쓰고 있다는 뜻이므로 기다립니다(Sleep).
- V 연산 (Signal/Unlock): 자원 사용을 마치고 실행합니다. 세마포어 값을 1 증가시킵니다. 기다리던 다른 프로세스를 깨웁니다.
📌 유형
- 바이너리 세마포어 (Binary Semaphore): 값이 0 또는 1만 가집니다. (뮤텍스(Mutex)와 유사하게 작동하며, 상호 배제(Mutual Exclusion)에 사용됨).
- 카운팅 세마포어 (Counting Semaphore): 값이 1 이상입니다. 동시에 접근 가능한 자원의 수가 여러 개일 때(예: 프린터 3대) 사용합니다.
비유: 화장실(공유 자원)이 하나뿐인 식당의 열쇠(세마포어)입니다. 열쇠가 있으면(값이 1) 들어가서 문을 잠그고(P 연산, 값 0), 나올 때 열쇠를 반납(V 연산, 값 1)해야 다음 사람이 쓸 수 있습니다.
03. 스레드 (Thread)
: 임베디드 리눅스 시스템 프로그래밍에서 멀티태스킹을 구현하는 가장 효율적인 방법인 스레드(Thread)와 그 표준 API인 POSIX 스레드(pthreads)에 대해 알아보겠습니다.
앞서 배운 공유 메모리 개념이 스레드에서는 기본으로 깔려 있다고 보시면 이해가 빠릅니다.

스레드는 임베디드 리눅스에서 실시간성을 높이고 자원을 효율적으로 사용하기 위한 필수 도구입니다. 하지만 잘못 사용하면 디버깅이 매우 어려운 동시성 버그(Race Condition, Deadlock)를 만들기 쉽습니다.
🧵 스레드 (Thread)의 기본 개념
=> "경량 프로세스 (Light Weight Process, LWP)"
- 정의: 프로세스 내에서 실행되는 실행의 단위입니다. 하나의 프로세스는 하나 이상의 스레드를 가질 수 있습니다.
✅ 프로세스와의 차이 (핵심):
- 프로세스: 운영체제로부터 자원을 할당받는 작업의 단위. 각자 완벽하게 독립된 메모리 공간을 가집니다. (서로 남남)
- 스레드: 프로세스 안에서 생성되며, 메모리를 공유합니다. (한 집에 사는 가족)
✅ 자원 공유:
- 공유함: 코드(Code), 데이터(Data), 힙(Heap) 영역. (따라서 전역 변수나 동적 할당 메모리에 모든 스레드가 접근 가능)
- 공유하지 않음: 스택(Stack), 레지스터(PC 포함). (각 스레드는 독립적인 함수 호출 기록과 실행 흐름을 가져야 하기 때문)
📌 비유
- 프로세스: 각각 독립된 '집'입니다. 옆집 냉장고를 열려면 전화를 걸어야(IPC) 합니다.
- 스레드: 한 집 안에 사는 '가족 구성원'입니다. 거실과 냉장고(공유 메모리)를 같이 씁니다. 하지만 각자의 방(스택)은 따로 있습니다.
📜 POSIX 스레드 (pthreads)
"리눅스 스레드 프로그래밍의 표준"
✅ 개념: UNIX 계열 운영체제(리눅스 포함)에서 스레드를 생성하고 제어하기 위해 만든 표준 API 인터페이스(IEEE 1003.1c)입니다. C언어에서 <pthread.h> 헤더를 사용합니다.
✅ 주요 함수:
- pthread_create(): 새로운 스레드를 생성합니다. (마치 fork()처럼, 하지만 훨씬 가볍게)
- pthread_join(): 특정 스레드가 종료될 때까지 기다립니다. (프로세스의 wait()와 유사, 스레드 간 동기화)
- pthread_detach(): 스레드를 분리시켜, 종료 시 자동으로 자원을 반납하게 합니다. (join을 기다리지 않음)
- pthread_exit(): 스레드를 종료합니다.
📌 참고
- 컴파일 시 -lpthread 옵션을 주어 pthread 라이브러리를 링크해야 합니다.
🔒 스레드 동기화: 뮤텍스(Mutex)와 조건 변수
: 스레드는 메모리(전역 변수 등)를 공유하기 때문에, 앞서 배운 세마포어와 같은 동기화 메커니즘이 필수적입니다. 스레드에서는 주로 뮤텍스를 사용합니다.
✅ 뮤텍스 (Mutex, Mutual Exclusion)
-
개념: "상호 배제"를 위한 잠금 장치입니다. 스레드 버전의 바이너리 세마포어라고 보면 됩니다.
-
동작:
Lock (잠금): 임계 구역(공유 자원 접근)에 들어가기 전에 문을 잠급니다. 이미 잠겨있다면 풀릴 때까지 대기합니다.
Unlock (해제): 나올 때 문을 엽니다. -
세마포어와의 차이: 뮤텍스는 소유권(Ownership)이 있습니다. 잠근 스레드만이 잠금을 풀 수 있습니다. (화장실 문을 잠근 사람이 나와야 문이 열리는 것과 같음)
✅ 조건 변수 (Condition Variable)
- 개념: 특정 조건(이벤트)이 만족될 때까지 스레드를 잠들게(Wait) 하고, 조건이 만족되면 깨우는(Signal) 장치입니다.
- 용도: "큐에 데이터가 들어오면 깨워줘"와 같은 생산자-소비자 패턴 구현 시 뮤텍스와 함께 사용됩니다. 불필요한 폴링(Polling)을 없애 CPU 사용률을 낮춥니다.
⚠️ 스레드 안전 (Thread Safety)
: 임베디드 프로그래밍에서 가장 주의해야 할 개념입니다.
✅ 정의: 여러 스레드가 동시에 함수를 호출하거나 변수에 접근해도 오동작(버그, 데이터 오염)이 발생하지 않는 성질을 말합니다.
✅ 위험 요소: 전역 변수(Global Variable)나 정적 변수(Static Variable)를 락(Mutex) 없이 수정하는 경우.
📌 해결책:
- 가능하면 지역 변수(Local Variable)만 사용합니다. (스택은 공유되지 않으므로 안전)
- 공유 자원 접근 시 반드시 뮤텍스를 사용합니다.
- 재진입 가능(Reentrant) 함수를 사용합니다. (예: strtok 대신 strtok_r 사용)
04. 리눅스 통신 (OSI 7계층과 TCP/IP 연관)
: 리눅스의 통신 시스템을 이해할 때, 이론적인 OSI 7계층과 실제 구현 모델인 TCP/IP, 그리고 이것이 리눅스 커널 내부에서 어떻게 매핑되는지 연결하는 것이 가장 중요합니다.
리눅스 네트워크 스택의 핵심은 "추상화된 계층 구조를 통해 사용자 애플리케이션이 하드웨어(NIC)를 몰라도 통신할 수 있게 하는 것"입니다.
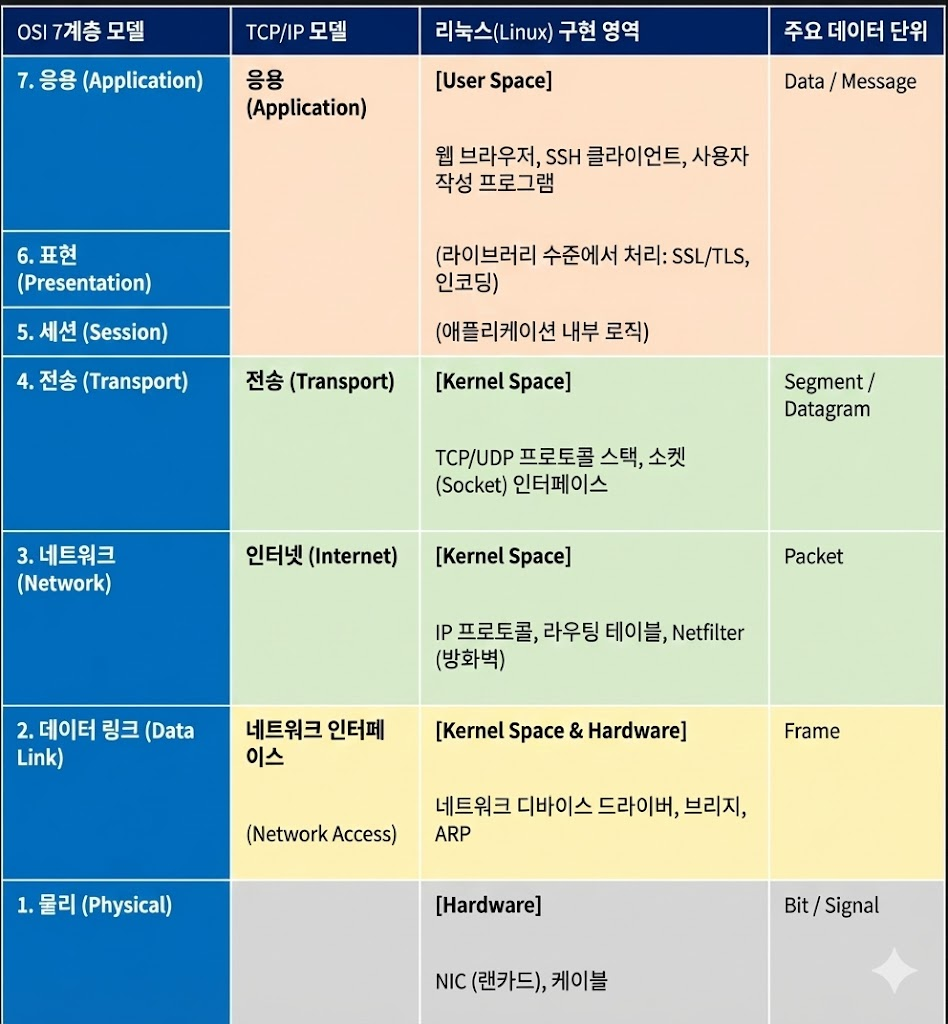
✅ 리눅스 관점에서의 계층별 핵심 메커니즘
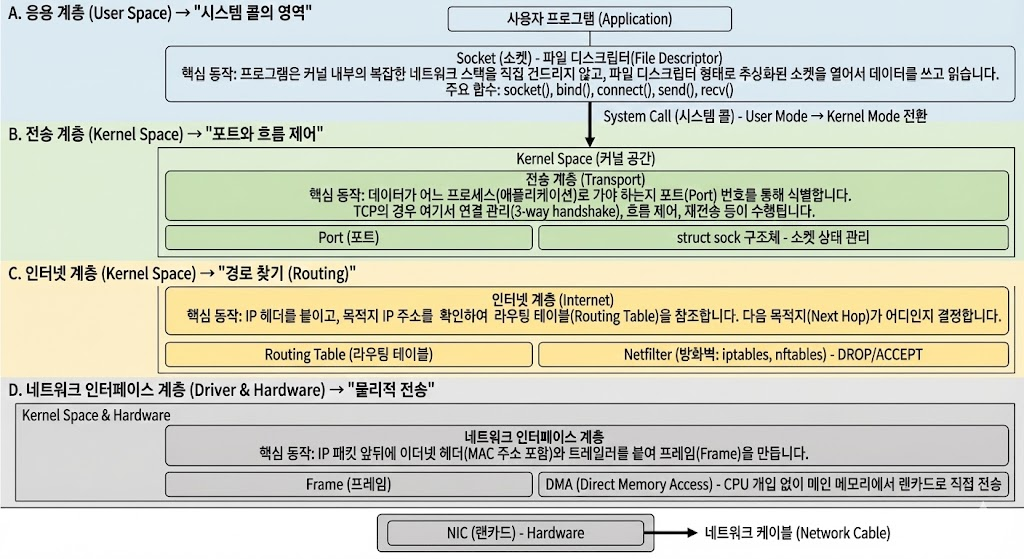
리눅스에서 통신이 일어날 때 각 계층에서 실제로 어떤 일이 벌어지는지 구체적으로 살펴보겠습니다.
📌 A. 응용 계층 (User Space) → "시스템 콜의 영역"
사용자가 작성한 프로그램이 존재하는 공간입니다.
- 핵심 동작: 프로그램은 커널 내부의 복잡한 네트워크 스택을 직접 건드리지 않고, 파일 디스크립터(File Descriptor) 형태로 추상화된 소켓(Socket)을 열어서 데이터를 쓰고 읽습니다.
- 주요 함수: socket(), bind(), connect(), send(), recv()
- 전환: 애플리케이션이 데이터를 보내기 위해 시스템 콜을 호출하면, CPU 모드가 User Mode에서 Kernel Mode로 전환됩니다.
📌 B. 전송 계층 (Kernel Space) → "포트와 흐름 제어"
커널 내부로 들어온 데이터가 처음 만나는 곳입니다.
- 핵심 동작: 데이터가 어느 프로세스(애플리케이션)로 가야 하는지 포트(Port) 번호를 통해 식별합니다. TCP의 경우 여기서 연결 관리(3-way handshake), 흐름 제어, 재전송 등이 수행됩니다.
- 구조체: 리눅스 커널에서는 struct sock 구조체가 소켓의 상태를 관리합니다.
📌 C. 인터넷 계층 (Kernel Space) → "경로 찾기 (Routing)"
데이터를 목적지까지 어떻게 보낼지 결정하는 단계입니다.
- 핵심 동작: IP 헤더를 붙이고, 목적지 IP 주소를 확인하여 라우팅 테이블(Routing Table)을 참조합니다. 다음 목적지(Next Hop)가 어디인지 결정합니다.
- Netfilter: 리눅스의 방화벽(iptables, nftables)이 작동하는 곳이 바로 이 계층입니다. 패킷을 가로채서 버리거나(DROP) 허용(ACCEPT)합니다.
📌 D. 네트워크 인터페이스 계층 (Driver & Hardware) → "물리적 전송"
커널이 실제 하드웨어인 랜카드(NIC)에게 명령을 내리는 단계입니다.
- 핵심 동작: IP 패킷 앞뒤에 이더넷 헤더(MAC 주소 포함)와 트레일러를 붙여 프레임(Frame)을 만듭니다.
- DMA (Direct Memory Access): CPU의 개입 없이 패킷 데이터를 메인 메모리에서 랜카드로 직접 전송하여 성능을 높입니다.
05. 멀티 스레드 / 멀티 프로세스
: 이 둘의 가장 큰 차이점은 "자원(메모리)을 공유하느냐, 격리하느냐"입니다. 이 차이가 성능과 코딩 방식(특히 동기화)을 결정짓습니다.

🚀 메모리 구조의 차이 (핵심)
리눅스 메모리 구조 관점에서 이 차이를 명확히 봐야 합니다.
📌 프로세스 (Process):
- fork()를 호출하면 부모 프로세스의 메모리 전체를 복사(COW: Copy On Write)하여 별도의 공간을 만듭니다.
- Code, Data, Heap, Stack 모든 영역이 독립적입니다.
📌 스레드 (Thread):
- 하나의 프로세스 내에서 생성됩니다.
- Code, Data, Heap 영역은 모든 스레드가 공유합니다. (전역 변수, 동적 할당 메모리 접근 가능)
- Stack 영역(함수 호출 기록, 지역 변수)과 레지스터(PC 포함)만 스레드별로 독립적으로 가집니다.
✅ 리눅스 커널의 시각: task_struct
: 리눅스 커널 입장에서 프로세스와 스레드는 사실 거의 같은 존재입니다.
-
Lightweight Process (LWP): 리눅스는 스레드를 '가벼운 프로세스'로 취급합니다.
-
스케줄링: 커널 스케줄러는 프로세스 단위가 아니라 TID(Thread ID) 단위로 스케줄링을 합니다.
-
clone() 시스템 콜: 프로세스 생성(fork)과 스레드 생성(pthread_create) 모두 내부적으로는 clone()이라는 시스템 콜을 사용합니다. 단지 clone()을 호출할 때 "메모리를 공유해라(CLONE_VM)"라는 플래그를 켜면 스레드가 되고, 끄면 프로세스가 되는 식입니다.
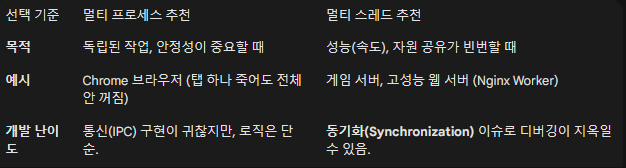
🔥 핵심 문제: 동기화 (Synchronization)
멀티 스레드는 메모리를 공유하기 때문에 Race Condition(경쟁 상태) 문제가 발생합니다. 두 스레드가 동시에 같은 변수 count를 +1 하려고 할 때, 타이밍이 꼬이면 값이 1만 증가하는 현상입니다.
이를 막기 위한 도구들이 필수적입니다:
- Mutex (뮤텍스): "화장실 열쇠". 열쇠를 가진 1명만 공유 자원에 접근 가능.
- Semaphore (세마포어): "빈 주차 공간". 정해진 개수만큼의 스레드만 접근 가능.
[ 25.12.17 (수) - 리눅스 프로그래밍 (통신) ]
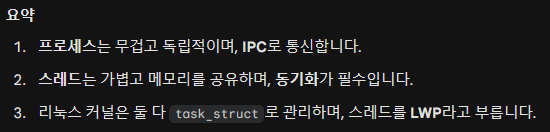
01. 동기화 (synchronization)
IPC는 프로세스들이 데이터를 교환하고 협력할 수 있도록 하는 메커니즘이며,동기화는 이러한 통신 과정에서 데이터의 일관성과 무결성을 보장하고 프로세스들의 실행 순서를 조정하는 데 필수적인 역할을 합니다

운영체제에서
동기화는 단순히 "시간을 맞춘다"는 의미를 넘어, 다수의 프로세스(또는 스레드)가 공유 자원에 접근할 때 충돌을 막고, 정해진 순서대로 실행되도록 제어하는 모든 행위를 말합니다
📌 01) 배타적 실행 (Mutual Exclusion)
: 이것은 "한 번에 한 놈만!"의 원칙입니다.
🔶 문제 상황 (경쟁 상태, Race Condition)
-
여러 프로세스가 동시에 하나의 변수(공유 메모리, 파일 등)를 읽고 쓰려고 할 때 발생합니다.
-
예를 들어, 통장 잔고가 100만 원인데, A와 B가 동시에 10만 원을 출금한다고 가정해 봅시다. 동기화가 없으면 둘 다 잔고를 100만 원으로 읽어서 출금 후 각각 90만 원을 기록해버리는 데이터 불일치가 발생할 수 있습니다.
🔷 해결책 (상호 배제)
-
임계 구역 (Critical Section): 공유 자원에 접근하는 코드 영역을 '임계 구역'이라고 합니다.
-
이 구역에는 반드시 한 번에 하나의 프로세스만 진입하도록 잠금(Lock)을 겁니다.
-
뮤텍스(Mutex): 가장 대표적인 도구입니다. "열쇠"를 가진 프로세스만 방(임계 구역)에 들어갈 수 있고, 나올 때 열쇠를 반납합니다.
📌 02) 순서적 실행 (Ordered Execution)
이것은 "너 끝나면 나 할게"의 원칙입니다.
🔶 상황
-
자원을 보호하는 것이 목적이 아니라, 작업의 순서가 중요할 때 사용합니다.
-
예를 들어, '데이터 생성 프로세스(Producer)'가 데이터를 만들어놔야 '데이터 처리 프로세스(Consumer)'가 일을 할 수 있습니다. 데이터가 없는데 처리를 시작하면 오류가 납니다.
🔷 해결책
-
프로세스 A가 작업을 마칠 때까지 프로세스 B는 대기(Block) 상태로 기다립니다.
-
A가 작업이 끝나면 "다 했어!"라고 시그널(Signal)을 보내고, 그제야 B가 깨어나서 작업을 시작합니다.
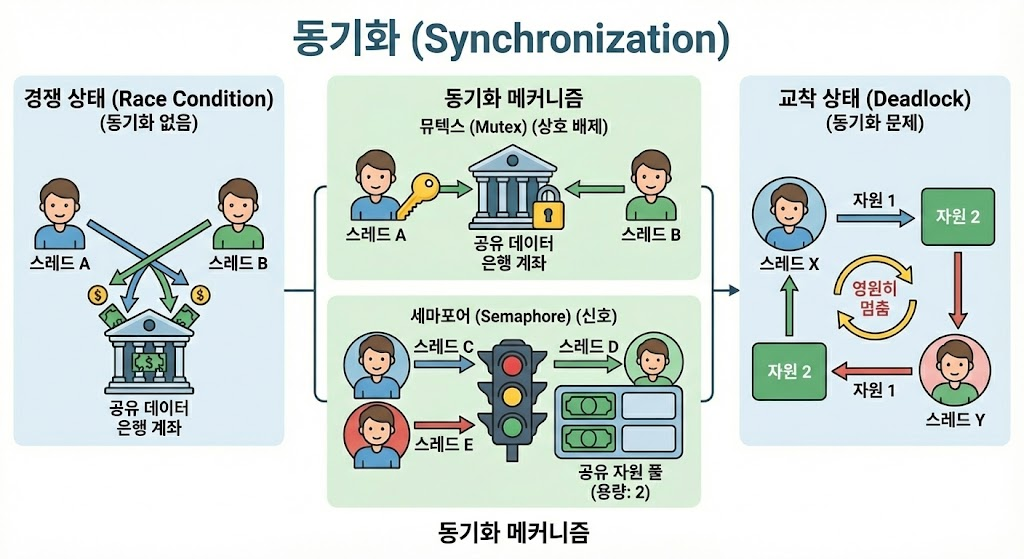
🚀 세마포어 (Semaphore)
: 세마포어는 위의 두 가지 개념(배타적 실행, 순서적 실행)을 모두 구현할 수 있는 일반화된 도구입니다.
- 쉽게 말해 "정수형 변수(Counter)를 이용한 신호등"입니다.
✅ 핵심 동작 원리
: 세마포어는 내부적으로 정수 값 S를 가집니다.
01) P 연산 (Wait / Decrease): 자원을 사용하겠다고 알림.
- S>0 이면: S를 1 감소시키고 계속 진행합니다. (자원 획득)
- S=0 이면: 자원이 없으므로 S가 0보다 커질 때까지 잠들어서 기다립니다(Block).
02) V 연산 (Signal / Post / Increase): 자원을 다 썼다고 알림.
- S를 1 증가시킵니다.
- 기다리고 있던 프로세스가 있다면 깨워줍니다.
✅ 세마포어의 두 가지 종류
01) 이진 세마포어 (Binary Semaphore)
- S가 0 또는 1만 가집니다.
- 사실상
뮤텍스(Mutex)와 거의 같습니다. (잠겨있거나, 열려있거나) - 배타적 실행을 위해 주로 사용합니다.
02) 카운팅 세마포어 (Counting Semaphore)
- S가 0 이상의 정수 값을 가집니다.
- 예를 들어 프린터가 3대(S=3)라면, 프로세스 3개까지는 동시에 통과시키고 4번째부터 대기시킵니다.
- 한정된 자원의 수량 관리에 사용됩니다.
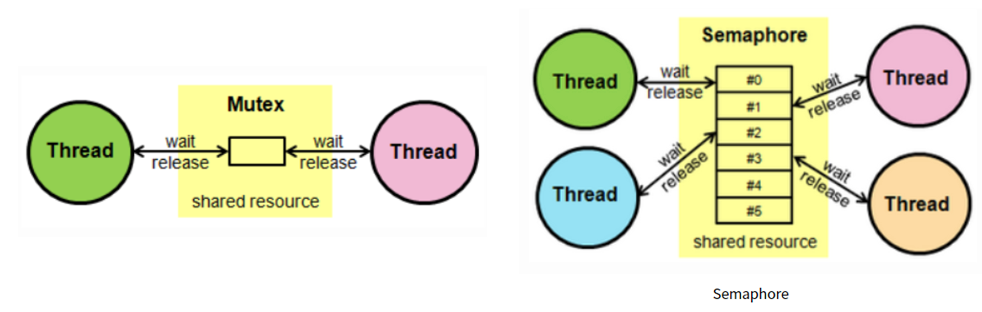
02. 뮤텍스 (Mutex)
뮤텍스(Mutex)는'Mutual Exclusion(상호 배제)'의 줄임말로, 동기화 도구 중 가장 기본이 되면서도 강력한 녀석입니다.

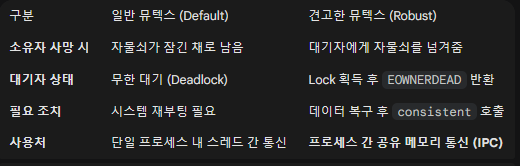
☝️ 뮤텍스(Mutex)의 핵심: "소유권(Ownership)"
: 세마포어와 뮤텍스는 비슷해 보이지만 결정적인 차이가 있습니다. 바로
소유권입니다.
- 세마포어: 소유권이 없습니다. A가 잠그고(Wait), B가 풀어줄(Signal) 수 있습니다. (🚦신호등 개념)
뮤텍스: 소유권이 있습니다. 잠근(Lock) 스레드만이 풀(Unlock) 수 있습니다.비유하자면 화장실 열쇠입니다. 열쇠를 가지고 들어간 사람만 문을 열고 나올 수 있습니다. 남이 밖에서 열어줄 수 없습니다.
☝️ 왜 Robustness (견고성)이 필요한가?
-> 일반적인 뮤텍스(Normal Mutex)에는 치명적인 약점이 하나 있습니다.
[ Question ] "만약 뮤텍스를 잠그고(Lock) 작업하던 스레드(또는 프로세스)가 갑자기 죽어버리면(Crash) 어떻게 될까?"
🔵 일반 뮤텍스의 시나리오 (재앙의 시작)
01) 스레드 A가 뮤텍스를 획득(Lock)하고 임계 구역에서 작업 중입니다.
02) 그런데 스레드 A가 버그로 인해 비정상 종료(Segmentation Fault 등)되거나 강제로 죽습니다.
03) 스레드 A는 죽었기 때문에 Unlock을 하지 못했습니다.
04) 이 뮤텍스를 기다리던 스레드 B, C는 영원히 풀리지 않을 자물쇠 앞에서 무한 대기(Deadlock)에 빠집니다.
05) 결국 시스템 전체가 멈춥니다.
=> 이 문제를 해결하기 위해 도입된 것이 바로 Robust Mutex (견고한 뮤텍스)입니다.
☝️ Robust Mutex의 동작 원리
리눅스(Pthread)에서는 뮤텍스 속성을 PTHREAD_MUTEX_ROBUST로 설정하여 이 기능을 활성화할 수 있습니다.
📌 Robust Mutex의 시나리오 (구세주)
01) 스레드 A가 Lock을 건 채로 죽습니다.
02) 커널은 소유자가 죽었음을 감지합니다.
03) 스레드 B가 pthread_mutex_lock()을 호출하며 대기 중이었습니다.
04) 운영체제는 스레드 B에게 Lock을 줍니다. 단, 그냥 주는 것이 아니라 "야, 전 주인이 작업하다 죽었어. 데이터가 망가졌을 수도 있으니까 확인해 봐!" 라는 특별한 신호를 보냅니다.
- 이때 pthread_mutex_lock 함수의 리턴값은 0(성공)이 아니라
EOWNERDEAD가 됩니다.
📌 복구 절차 (Recovery)
EOWNERDEAD를 받은 스레드 B는 다음과 같은 절차를 따라야 합니다.
01) 데이터 검사: 공유 메모리나 자원의 상태가 일관성 있는지(깨지지 않았는지) 확인하고 수구합니다.
02) 일관성 선언 (pthread_mutex_consistent): "내가 다 고쳐서 이제 안전해!"라고 시스템에 알립니다.
03) 작업 수행: 원래 하려던 작업을 하고 Unlock 합니다.
04) 만약 복구가 불가능하다면? Unlock만 하고 해당 뮤텍스는 더 이상 사용할 수 없는 상태(ENOTRECOVERABLE)로 만듭니다.
🚀 Mutex 핵심 요약 및 팁
✅ IPC에서는 필수: 프로세스 간에 공유 메모리(Shared Memory)를 쓰고 있다면, 반드시 Robust Mutex를 써야 합니다. 한 프로세스가 죽어도 다른 프로세스는 살아야 하기 때문입니다.
✅ 오버헤드: Robust Mutex는 일반 뮤텍스보다 관리해야 할 상태가 많아 약간의 성능 오버헤드가 있지만, 안정성을 위해 감수할 만합니다.
✅ 일관성 함수: pthread_mutex_consistent() 함수가 Robustness의 핵심입니다. 이걸 호출하지 않고 Unlock 하면, 다음 타자에게 ENOTRECOVERABLE(복구 불가능) 에러가 떨어집니다.
03. 네트워크 (inter Network)
리눅스 네트워크 프로그래밍의 핵심은
"소켓(Socket)"이라는 개념을 이해하는 것에서 시작합니다.
-
이전 시간의 IPC가 '컴퓨터 내부'의 대화였다면, 소켓은 '컴퓨터 외부'와의 대화입니다.
-
리눅스 입장에서는 IPC와 소켓 모두를
파일(File)처럼 다룬다는 점이 흥미롭습니다.
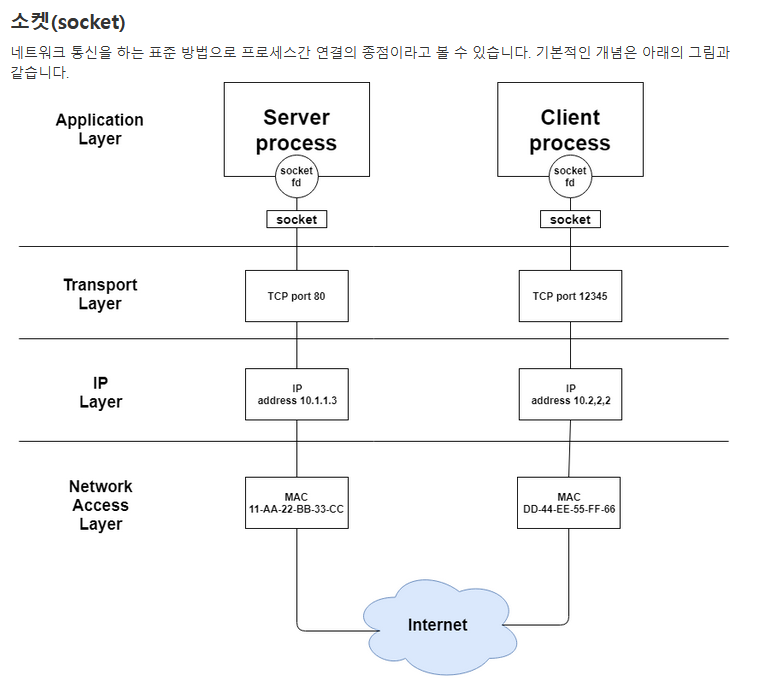
💡 소켓 (Socket): 네트워크로 향하는 문
: 리눅스 철학 중 하나는 "모든 것은 파일이다"입니다. 네트워크 연결도 예외가 아닙니다.
-
개념: 네트워크 통신을 위한 엔드포인트(Endpoint)입니다.
-
파일 디스크립터(File Descriptor): 프로그래머가
socket()함수를 호출하면, 리눅스 커널은 정수형 숫자(File Descriptor)를 하나 던져줍니다. 우리는 이 숫자를 가지고 읽고(read), 쓰고(write), 닫으며(close) 통신합니다. 마치 파일을 다루듯이 말이죠.
💡 프로토콜 (Protocol): 통신 규칙
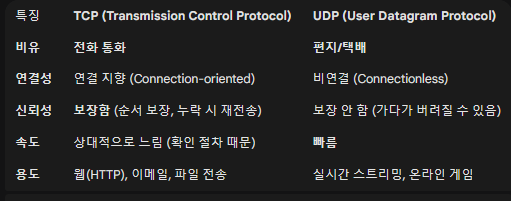
데이터를 주고받을 때의 약속입니다. 가장 중요한 두 가지는 TCP와 UDP입니다.
💡 클라이언트-서버 모델 (Client-Server Model)
: 네트워크 프로그래밍의 가장 표준적인 구조입니다. "서비스를 주는 쪽(Server)"과 "요청하는 쪽(Client)"의 역할이 명확히 나뉩니다.
이 흐름을 이해하는 것이 프로그래밍의 90%입니다. 아래 다이어그램을 통해 흐름을 한눈에 익혀봅시다.
✅ 핵심 함수 흐름 (TCP 기준)
(1)
socket(): (공통) 전화기를 듭니다. (소켓 생성)(2)
bind(): (서버) 전화번호를 부여받습니다. (IP/Port 할당)(3)
listen(): (서버) 벨이 울릴 수 있게 연결해 둡니다. (대기 상태)(4)
accept(): (서버) 걸려온 전화를 받습니다. (수락 및 실제 통신용 소켓 생성)
- 중요: accept는 클라이언트가 올 때까지 블로킹(대기) 됩니다.
(5)
connect(): (클라이언트) 서버의 전화번호로 전화를 겁니다.(6)
read() / write(): (공통) 대화를 나눕니다. (데이터 송수신)
[ 25.12.18 (목) = 리눅스 프로그래밍 (네트워크) ]
01. TCP/IP의 주소 체계 (+Raspberry Pi)
# 리눅스 소켓(Socket) 프로그래밍의 흐름
✅ (참고) BSD 계열(ubuntu) vs Red Hat 계열
: BSD 계열과 Red Hat은 근본적으로 다른 운영체제 커널과 개발 철학을 기반으로 합니다.
BSD는 완전한 운영체제(커널 및 시스템 도구 포함)로 개발된 반면,Red Hat은 리눅스 커널과 다양한 GNU/타사 소프트웨어를 결합한 리눅스 배포판입니다.

->
BSD는 고도의 안정성과 일관성이 요구되는 특정 서버 및 네트워크 환경에 적합하며,Red Hat은 광범위한 엔터프라이즈 환경과 최신 기술 도입이 필요한 범용적인 용도에 주로 사용됩니다.
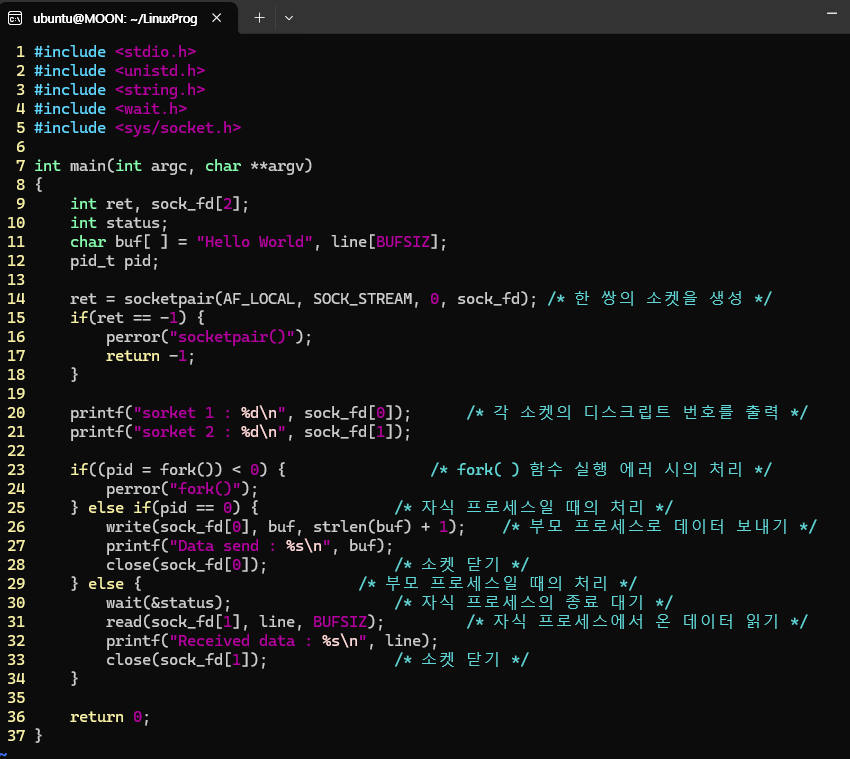
📌 Socket Programming 예시
📌 엔디안(Endian)의 개념
사람이 숫자를 쓰는 방식과 비슷하면
빅 엔디언, 역순이면리틀 엔디언입니다.

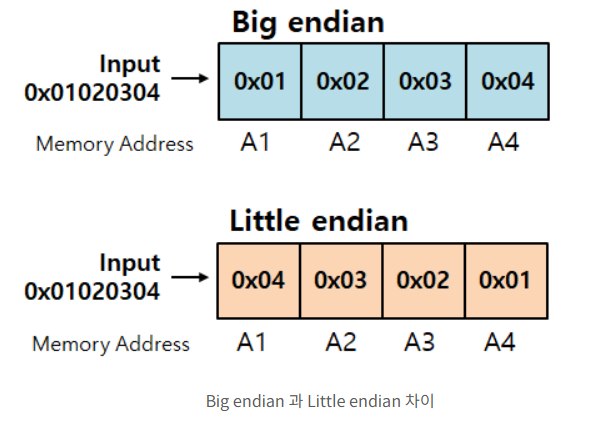
-
빅 엔디언(Big-Endian)은 큰 바이트(상위 바이트)부터 메모리 주소의 앞쪽에 저장하는 방식 -> 네트워크 통신(TCP/IP) 표준이며, 숫자를 직관적으로 읽기 좋습니다. -
리틀 엔디언(Little-Endian)은 반대로 작은 바이트(하위 바이트)부터 메모리 주소의 앞쪽에 저장하는 방식 -> x86 계열 CPU 등에서 사용되며, 데이터 연산이 더 빠르다는 장점이 있습니다.
02. upd_client & udp_server
03. 📲 라즈베리 파이 연동 예시
라즈베리 파이는 리눅스(Raspberry Pi OS) 기반이므로 일반 PC와 프로그래밍 방식은 동일합니다. 하지만 'HW 제어'라는 특수성이 결합됩니다.
📲 시나리오: 센서 데이터 전송 시스템
(1) 라즈베리 파이(Client): 온습도 센서 값을 읽어서 소켓을 통해 서버로 전송합니다.
(2) 메인 PC(Server): 라즈베리 파이가 보낸 데이터를 받아서 DB에 저장하거나 화면에 출력합니다.
✅ 연동 시 주의할 점 (네트워크 설정)
-
IP 주소 확인: 라즈베리 파이 터미널에서
hostname -I명령어로 자신의 IP를 알아야 합니다. -
방화벽(UFW): 리눅스 서버에서
통신 포트(예: 8080)가 열려 있는지 확인해야 합니다. -
엔디안(Endianness): PC와 라즈베리 파이의 CPU 아키텍처가 다를 경우, 숫자를 표현하는 바이트 순서를 맞추기 위해
htons(), htonl()같은 함수를 반드시 사용해야 데이터 왜곡이 없습니다.
04. 소켓 프로그래밍 관련
do { csock = accept() ... read(csock write(csock ...
소켓 프로그래밍, 특히
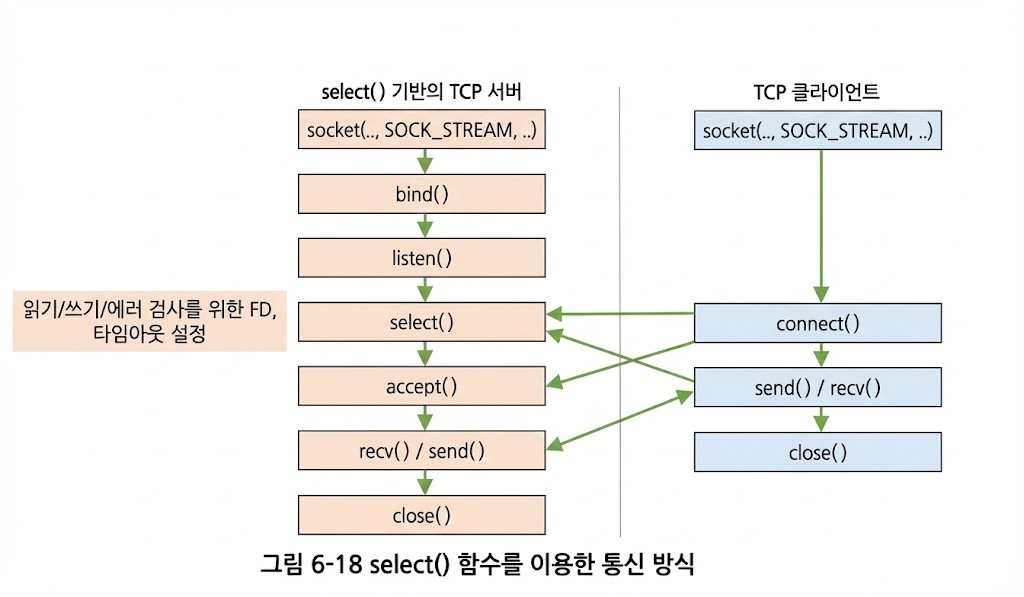
멀티플렉싱(Multiplexing)의 핵심 원리와 리눅스 커널 내부에서 이것이 어떻게 처리되는지 더 깊게 들어가 보겠습니다. "왜 멀티플렉싱을 써야 하는가?"에 대한 답은 결국자원 효율성에 있습니다.
1. 블로킹(Blocking) vs 논블로킹(Non-blocking) I/O
멀티플렉싱을 이해하기 위한 가장 중요한 전제 조건입니다.
-
블로킹 I/O:
read()나accept()를 호출했을 때 데이터가 올 때까지 프로그램이 그 자리에 멈춰 있는 방식입니다. 여러 클라이언트를 상대하려면 각 클라이언트마다 스레드를 만들어야 하므로 메모리 소모가 큽니다. -
논블로킹 I/O: 데이터가 없으면 "지금은 데이터가 없다"는 에러 코드(
EAGAIN)를 즉시 반환하고 다음 코드를 실행합니다. 하지만 데이터가 언제 올지 모르니 무한 루프를 돌며 계속 확인해야 하는(Polling) 단점이 있습니다.
멀티플렉싱은 이 두 가지의 장점을 합쳐, "데이터가 준비된 소켓이 생길 때까지만 효율적으로 대기"하는 기술입니다.
2. epoll의 내부 메커니즘: 왜 빠른가?
select는 매번 모든 소켓 리스트를 커널에 넘겨줘야 하지만, 리눅스의 epoll은 다릅니다. 커널 내부에 관심 대상 소켓 저장소를 따로 만듭니다.
(1) 관심 목록 관리 (Red-Black Tree):
epoll_ctl을 통해 등록된 소켓들은 커널 내부에서 '레드-블랙 트리'라는 자료구조로 관리됩니다. 삽입, 삭제, 검색이 매우 빠릅니다.(2) 이벤트 발생 알림 (Ready List): 특정 소켓에 데이터가 도착하면, 커널은 해당 소켓을 별도의 'Ready List'에 담습니다.
(3) 효율적 수확: 사용자가
epoll_wait를 호출하면 커널은 전체 소켓을 뒤지는 게 아니라, 이미 채워진 'Ready List'만 사용자에게 전달합니다.
이 과정 덕분에 연결된 소켓이 10,000개여도 실제 데이터가 온 소켓이 2개뿐이라면, 의 속도로 즉각 처리가 가능합니다. (반면 select는 으로 10,000개를 다 확인해야 합니다.)
3. Level Triggered(LT) vs Edge Triggered(ET)
epoll을 깊게 공부할 때 반드시 마주치는 개념입니다. 이벤트가 발생하는 "시점"에 대한 정의입니다.
-
Level Triggered (기본값): 소켓에 데이터가 남아있는 한 계속해서 이벤트를 발생시킵니다. (안전하지만 호출 횟수가 많아질 수 있음)
-
Edge Triggered: 데이터가 새로 도착한 순간에 딱 한 번만 이벤트를 발생시킵니다.
-> 이 방식에서는 한 번 알림이 왔을 때 read()를 반복해서 데이터가 완전히 없어질 때까지 다 읽어야 합니다.
-> 성능은 가장 뛰어나지만, 코딩 실수가 있으면 데이터를 놓칠 수 있어 정교한 설계가 필요합니다.
🚀 라즈베리 파이 실전 적용: 게이트웨이 설계
: 라즈베리 파이를 이용해 여러 대의 아두이노나 센서 노드로부터 데이터를 받는 IoT 게이트웨이를 만든다고 가정해 봅시다.
-
구조: 메인 루프에서 epoll_wait를 실행합니다.
-
동작:
(1) 새로운 센서가 접속하면 accept() 후 epoll에 등록합니다.
(2) 특정 센서에서 온습도 데이터가 오면 epoll이 알림을 줍니다.
(3) 해당 데이터를 파싱하여 DB에 저장하거나 클라우드로 전송합니다. -
장점: 라즈베리 파이 같은 임베디드 기기는 자원(CPU, RAM)이 제한적이므로, 수백 개의 센서 연결을 스레드 없이 단 하나의 루프로 처리하는 멀티플렉싱이 필수적입니다.
05. HTTP와 웹 서버 프로그래밍
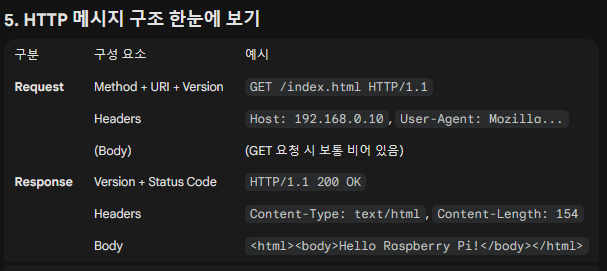
: 소켓 프로그래밍에서 한 단계 더 올라가면, 우리가 매일 사용하는 웹의 기반인 HTTP(HyperText Transfer Protocol)와 이를 처리하는 웹 서버 프로그래밍의 영역에 도달하게 됩니다.
단순히 데이터를 주고받는 소켓 통신에 '약속된 형식(Protocol)'을 입히는 과정이라고 이해하시면 됩니다.
📌 HTTP의 핵심 개념: "약속된 대화법"
: HTTP는 TCP 소켓 위에서 동작하는 응용 계층(Application Layer) 프로토콜입니다. 가장 중요한 특징은 비연결성(Connectionless)과 무상태(Stateless)입니다.
-
Request/Response 모델: 클라이언트가 요청을 보내면 서버가 응답하는 일대일 구조입니다.
-
Stateless (무상태): 서버는 클라이언트의 이전 상태를 기억하지 않습니다. (이 문제를 해결하기 위해 쿠키나 세션을 사용합니다.)
-
텍스트 기반 프로토콜: 바이너리가 아닌 사람이 읽을 수 있는 텍스트 형식을 사용하므로 디버깅이 용이합니다.
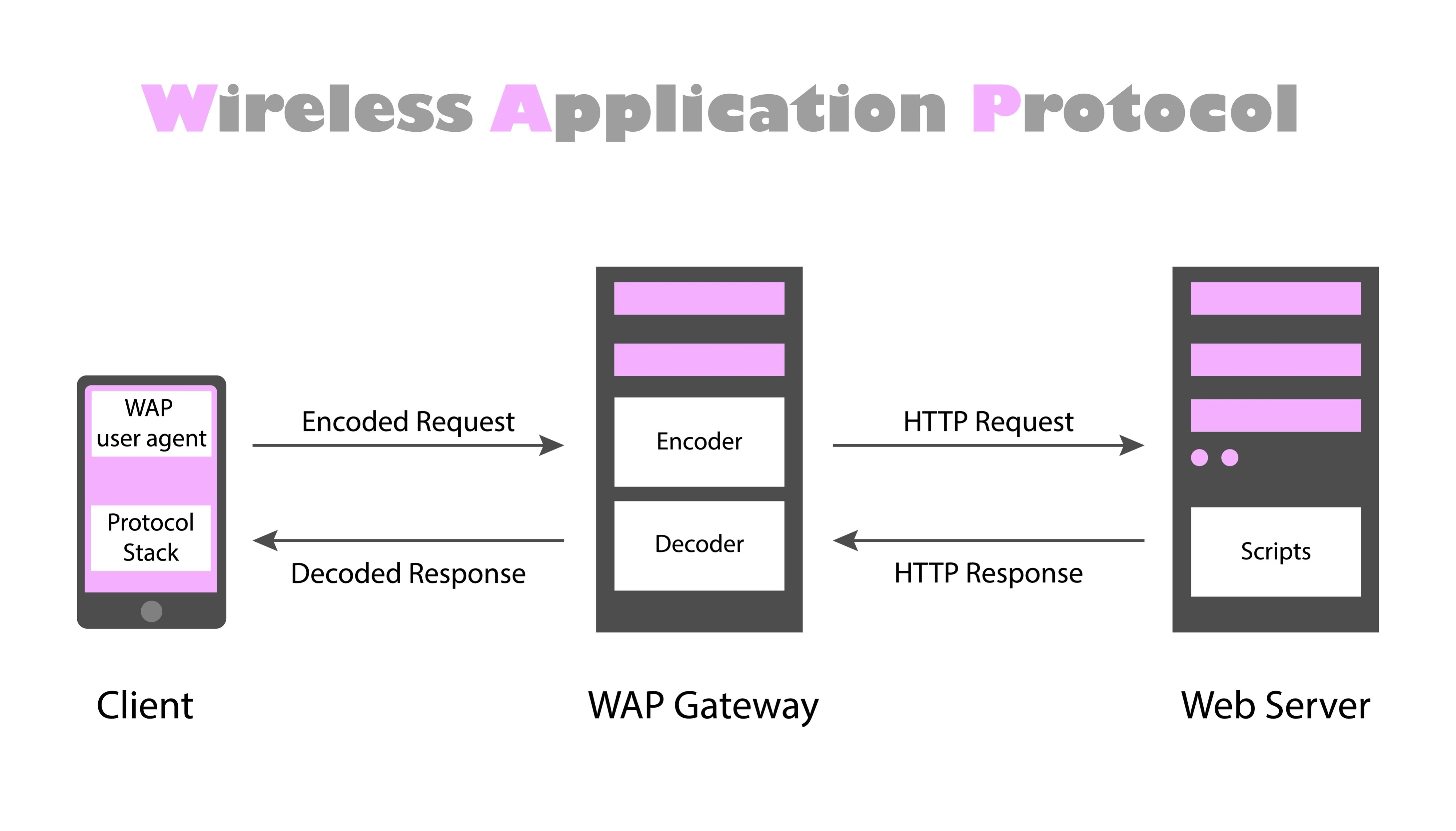
📌 웹 서버 프로그래밍의 내부 동작 과정
: 리눅스 환경에서 C나 C++로 직접 웹 서버를 만든다면, 앞서 배운 소켓 프로그래밍 흐름에 다음 과정이 추가됩니다.
(1) 소켓 연결 (accept): 클라이언트(브라우저)와 TCP 연결을 맺습니다.
(2) 요청 읽기 (read/recv): 브라우저가 보낸 HTTP 요청 메시지를 읽어옵니다.
(3) HTTP 파싱 (Parsing):
- Method 확인: GET(데이터 요청), POST(데이터 전송) 등 확인.
- URI 확인: 사용자가 요청한 파일 경로(예:
/index.html) 파싱.
(4) 리소스 처리:
- 정적 컨텐츠: 해당 파일을 디스크에서 읽어옵니다.
- 동적 컨텐츠: CGI나 다른 로직을 통해 데이터를 생성합니다(예: 센서 값 읽기).
(5) 응답 생성 및 전송 (write/send): HTTP 규격에 맞춰 헤더와 본문을 만들어 클라이언트에 보냅니다.
(6) 연결 종료 (close): HTTP/1.1의 Keep-Alive 설정이 없다면 보통 연결을 끊습니다.
📌 효율적인 웹 서버 아키텍처 (멀티플렉싱과의 결합)
실제 운영 환경의 웹 서버(Nginx, Apache 등)는 수많은 요청을 동시에 처리해야 합니다. 여기서 epoll과 같은 멀티플렉싱 기술이 빛을 발합니다.
- Event-Driven 방식:
epoll이 수천 개의 소켓을 감시하다가, HTTP 요청이 완전히 도착한 소켓만 골라 작업 스레드에게 넘겨줍니다. - 비동기 처리: 파일을 읽거나 DB에서 데이터를 가져오는 동안 CPU가 쉬지 않고 다른 네트워크 요청을 처리할 수 있게 설계합니다.
🚀 라즈베리 파이 기반 IoT 웹 서버 활용

: 라즈베리 파이에서 웹 서버 프로그래밍을 배우면 다음과 같은 실전 프로젝트가 가능해집니다.
- 센서 모니터링 대시보드: 브라우저에서 라즈베리 파이 IP에 접속하면, 실시간 온습도 데이터를 그래프로 보여주는 서버.
- 원격 하드웨어 제어: 웹 페이지의 버튼을 누르면 서버가 HTTP POST 요청을 받아 GPIO를 조작하여 LED를 켜거나 모터를 구동.
REST API 서버: 스마트폰 앱과 라즈베리 파이 간의 데이터 통신 규격을 HTTP JSON으로 통일.
[ 25.12.19 (금) 리눅스 프로그래밍 (네트워크) ]
01. 인터넷 패킷 모니터링 Wireshark
1. Wireshark: 네트워크의 현미경
:
Wireshark는 네트워크 인터페이스를 통과하는 실시간 패킷을 캡처하고 분석하는 도구입니다. 리눅스 환경에서는 주로tcpdump로 패킷을 캡처(파일 확장자.pcap)한 뒤, 이를 Wireshark에서 시각적으로 분석하는 방식으로 많이 사용합니다.
✅ 주요 기능: 패킷 캡처, 프로토콜 분석(HTTP, TCP, IP 등), 데이터 흐름 추적.
✅ 작동 원리: 네트워크 카드(NIC)를 Promiscuous Mode(무차별 모드)로 설정하여, 자신에게 오는 패킷뿐만 아니라 해당 세그먼트의 모든 패킷을 수집합니다.
2. 핵심 프로토콜: TCP vs UDP
: 리눅스 프로그래밍에서 소켓(Socket)을 생성할 때 가장 먼저 결정해야 하는 부분입니다.
📌 TCP (Transmission Control Protocol)
- 특징: 연결 지향형, 신뢰성 보장, 흐름 제어.
- 3-Way Handshake: 연결을 설정할 때
SYN->SYN-ACK->ACK과정을 거칩니다. - 용도: 데이터 손실이 없어야 하는 웹 통신(HTTP), 파일 전송(FTP).
📌 UDP (User Datagram Protocol)
- 특징: 비연결형, 빠른 속도, 오버헤드 적음.
- 용도: 실시간 스트리밍, 온라인 게임, DNS 조회.
3. IP 주소와 포트(Port) 번호
: 네트워크 상에서 목적지를 찾는 두 가지 핵심 식별자입니다.
-
IP 주소 (L3): 네트워크 상의 특정 호스트(컴퓨터)를 식별합니다. (예:
192.168.0.10) -
포트 번호 (L4): 해당 컴퓨터 내에서 실행 중인 특정 프로세스를 식별합니다.
-
80: HTTP
-443: HTTPS
-22: SSH
4. 리눅스 네트워크 주요 명령어
: 프로그래밍이나 트러블슈팅 시 자주 사용하는 명령어들입니다.
ip addr: 현재 시스템의 네트워크 인터페이스와 IP 주소 확인.ss -tulnp: 현재 열려 있는 포트와 대기 중인 소켓 상태 확인.ping \[목적지]: 상대방 호스트와의 연결 상태 확인 (ICMP 프로토콜).tcpdump -i eth0: 터미널에서 실시간 패킷 캡처.
02. 웹 서버와 라즈베리 파이의 제어

1. 시스템 아키텍처 (Data Flow)
: 전체적인 데이터의 흐름은 다음과 같습니다.
(1)
데이터 수집: 라즈베리 파이가 DHT11 센서로부터 온도/습도 데이터를 읽어옵니다. (L1~L2 수준의 비트 통신)(2)
데이터 처리: 수집된 가공되지 않은(Raw) 데이터를 리눅스 프로세스가 섭씨(∘C)와 습도(%) 단위로 계산합니다.(3)
네트워크 전송: 프로세스가 내장된 HTTP 서버를 통해 데이터를 외부로 노출하거나, 외부 데이터베이스/웹 서버로 패킷을 보냅니다. (L4 TCP, L7 HTTP)(4)
제어 및 모니터링: 사용자가 웹 브라우저를 통해 실시간 데이터를 확인하고, 필요 시 라즈베리 파이의 GPIO(예: 팬 구동, LED 점등)를 제어합니다.
2. 핵심 개념: DHT11 통신 프로토콜
: DHT11은 일반적인 I2C나 SPI와 달리 단선(Single-Wire) 양방향 프로토콜을 사용합니다.
✅ 비트 판별: 데이터 라인이 'High' 상태를 유지하는 시간(μs)에 따라 0과 1을 구분합니다.
-
0: 약 26∼28μs 동안 High 유지
-
1: 약 70μs 동안 High 유지
✅ 리눅스에서의 처리: 라즈베리 파이의 OS(Linux)는 실시간 OS(RTOS)가 아니기 때문에, 나노초(ns) 단위의 정밀한 타이밍 제어를 위해 커널 드라이버나 libgpiod 같은 라이브러리를 주로 활용합니다.

3. 구축 절차 (Step-by-Step)
🚀 Step 1: 하드웨어 연결 (Wiring)
: DHT11 센서는 보통 3개의 핀을 사용합니다.
- VCC: 라즈베리 파이 3.3V 또는 5V
- GND: 라즈베리 파이 Ground
- DATA: 라즈베리 파이 GPIO 핀 (예: GPIO 4)
🚀 Step 2: 센서 데이터 읽기 (System Programming)
: 리눅스 환경에서 데이터를 읽어오는 로직을 구현해야 합니다.
- 직접 구현:
/dev/gpiomem에 접근하여 레지스터를 제어하거나, C++로libgpiod라이브러리를 사용하여 타이밍을 체크합니다.- 기존 드라이버 활용: 라즈베리 파이 OS에 포함된
dht11커널 모듈을dtoverlay설정으로 로드하면/sys/bus/iio/devices/경로에서 텍스트 형태로 데이터를 읽을 수 있어 관리가 훨씬 편해집니다.
🚀 Step 3: 웹 서버 구축 (Network Programming)
: 수집된 데이터를 웹으로 띄워야 합니다.
- Lightweight Server: C++을 공부 중이시라면 Mongoose나 Crow 같은 가벼운 C++ 웹 프레임워크를 추천합니다.
- REST API 구성: /temp나 /humi 같은 엔드포인트를 만들어 JSON 형태로 데이터를 반환하게 설정합니다.
예: {"temperature": 24, "humidity": 45}
🚀 Step 4: Wireshark로 모니터링
: 서버를 띄웠다면, 지난 시간에 공부한 Wireshark를 활용해 보세요.
브라우저에서 라즈베리 파이 IP로 접속했을 때, 실제 HTTP GET Request가 들어오고 TCP 3-Way Handshake가 일어나는 과정을 캡처하여 데이터가 누락 없이 전달되는지 확인합니다.
📢 4. 제어(Control) 로직 추가
: 단순 모니터링을 넘어 '제어'를 하려면 다음의 흐름이 추가됩니다.
👉 (1) 웹 버튼 클릭: 사용자가 웹 UI에서 "Fan ON" 버튼을 누릅니다.
👉 (2) HTTP POST: 브라우저가 서버로 제어 신호(POST 요청)를 보냅니다.
👉 (3) GPIO Write: 서버 프로세스가 해당 요청을 받으면 라즈베리 파이의 특정 GPIO 핀을 High로 출력하여 릴레이(Relay)나 팬을 동작시킵니다.
03. 웹 서버를 이용한 R-pi4 LED 제어 실습
"
네트워크 요청(HTTP)->프로세스 수신 및 해석->커널/드라이버 호출(GPIO)->하드웨어 동작"
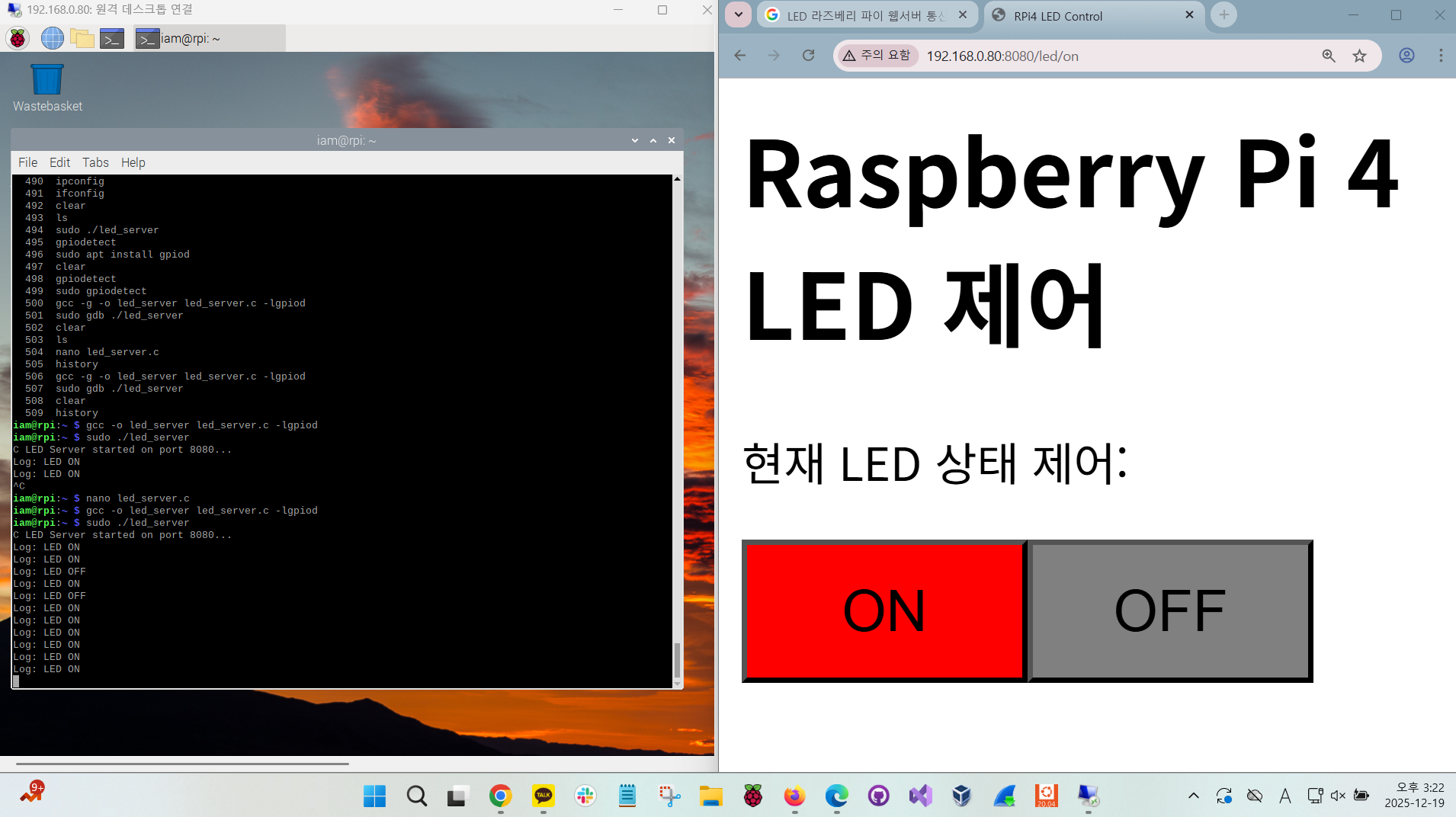
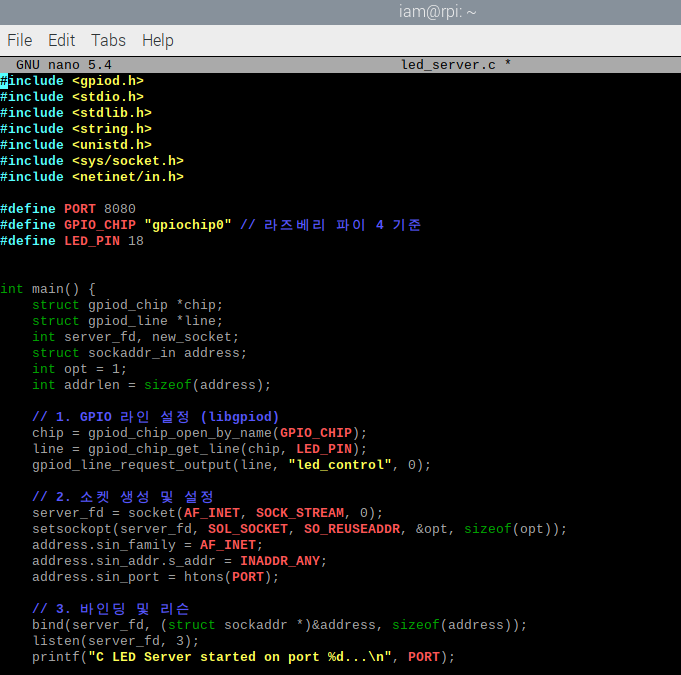
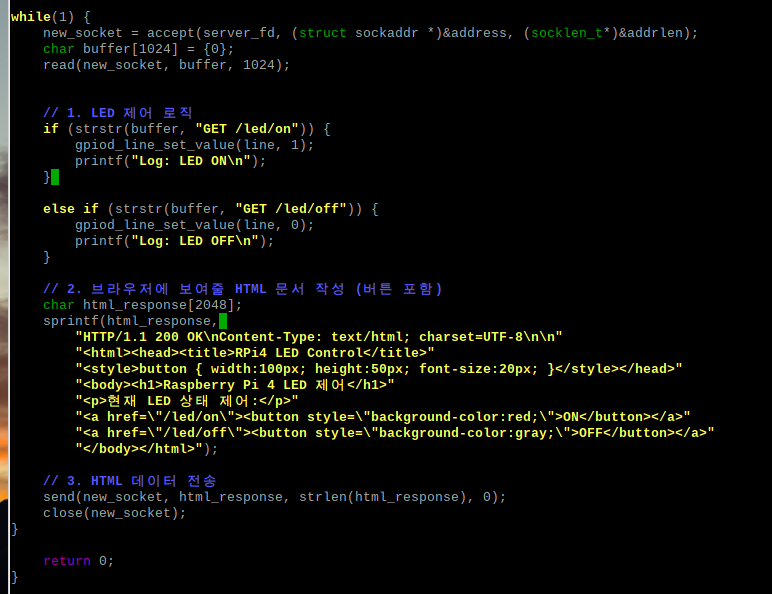
🚀 리눅스 시스템 프로그래밍 포인트
이 실습에서 눈여겨봐야 할 핵심 개념은 다음과 같습니다.
📌 가. HTTP Header와 Body의 구분
코드에서 HTTP/1.1 200 OK... 부분은 헤더(Header)이고, <html>... 부분은 바디(Body)입니다. 이 둘 사이에는 반드시 빈 줄(Double Newline, \n\n)이 있어야 브라우저가 "아, 여기서부터 진짜 웹 페이지구나!"라고 인식합니다.
📌 나. Stateless (무상태성)
HTTP는 연결을 유지하지 않습니다. 버튼을 누를 때마다 소켓이 새로 열리고(accept), 데이터를 주고받은 뒤 바로 닫힙니다(close). LED의 현재 상태(켜짐/꺼짐)를 기억하려면 C 코드 내부의 변수(예: int current_state)에 저장해두어야 합니다.
✅ Wireshark로 분석해보기
이제 다시 Wireshark를 켜고 패킷을 캡처해 보세요.
버튼을 누를 때마다 TCP SYN 패킷부터 시작해 HTTP GET 요청이 발생하는 것을 볼 수 있습니다.
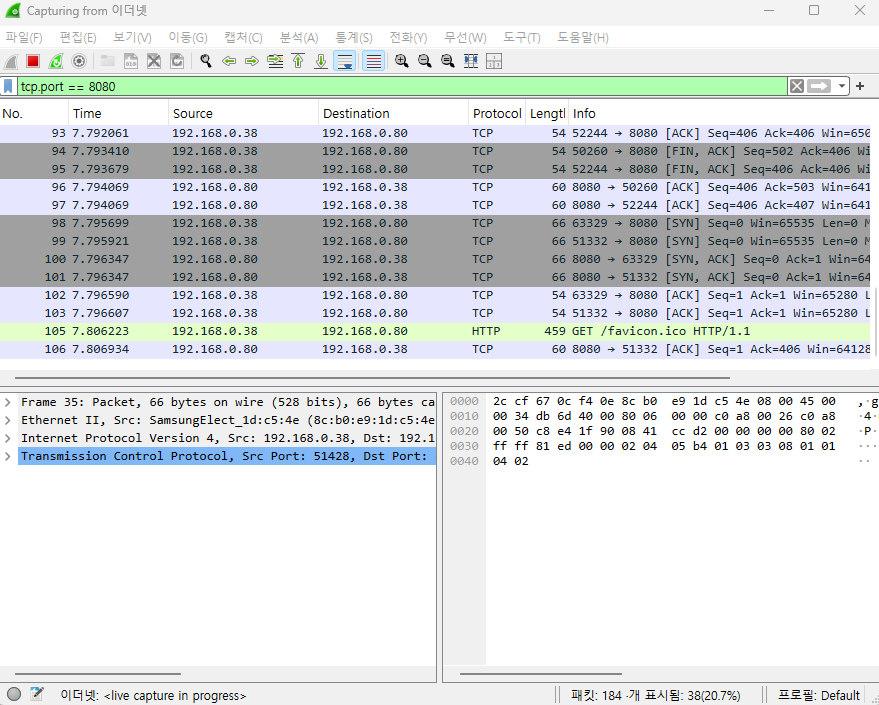
C 코드에서 보낸 html_response 문자열이 TCP Segment의 데이터(Payload) 영역에 그대로 담겨 전송되는 것을 확인해 보세요. 패킷 레벨에서 HTML 태그들을 직접 확인하는 것은 매우 흥미로운 경험이 될 것입니다.
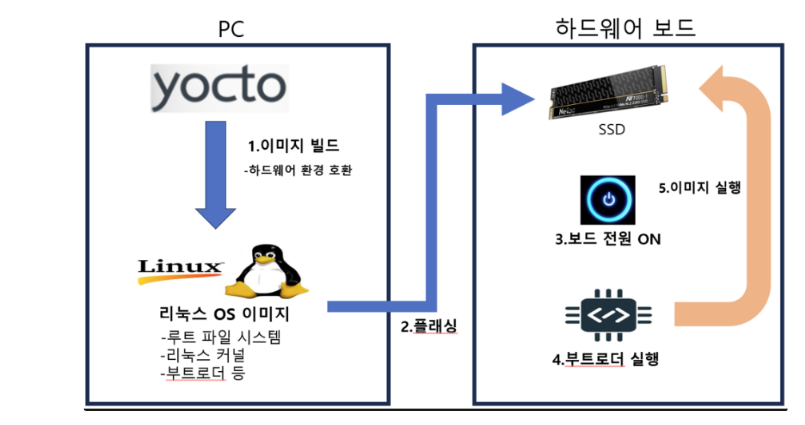
🚀 리눅스 Yocto와의 연관 공부
: C 언어 + 웹 서버 + LED 제어 코드 + Yocto Project => '나만의 맞춤형 임베디드 운영체제'
📌 Yocto Project 핵심 개념
Yocto는 단순한 OS가 아니라 "리눅스 배포판을 만드는 빌드 시스템"입니다. 지금까지는 라즈베리 파이 OS라는 만들어진 OS 위에서 작업했다면, 이제는 그 OS 자체를 직접 구성하게 됩니다.
-
Recipe (.bb 파일): 소프트웨어를 빌드하는 '레시피'입니다. 작성하신 led_server.c를 어디서 가져올지, 어떤 라이브러리(libgpiod)가 필요한지, 어떻게 컴파일할지 정의합니다.
-
Layer (meta-): 레시피들의 묶음입니다. 예를 들어 라즈베리 파이 하드웨어 설정을 담은 meta-raspberrypi 층 위에, 본인의 프로젝트용 meta-myproject 층을 쌓아 올리는 구조입니다.
-
BitBake: Yocto의 엔진입니다. 레시피를 읽어 소스코드를 다운로드하고, 크로스 컴파일하여 최종 이미지 파일을 만들어내는 실행 주체입니다.
-
SDK (Software Development Kit): 라즈베리 파이용 실행 파일을 PC(Ubuntu)에서 만들기 위한 '크로스 컴파일러 환경'입니다.
🚀 난이도별 학습 절차 (Roadmap)

☑️ Level 1: 환경 구축 및 기본 이미지 빌드 (입문)
가장 먼저 라즈베리 파이 4를 지원하는 기본 이미지를 빌드해 보는 단계입니다.
(1) Poky 및 meta-raspberrypi 다운로드: 기본 빌드 도구와 라즈베리 파이 전용 레이어를 준비합니다.
(2) local.conf 설정: 대상 보드를 raspberrypi4로 지정합니다.
(3) 기본 이미지 빌드: bitbake core-image-minimal 명령으로 아주 가벼운 터미널 기반 OS를 생성합니다.
☑️ Level 2: 커스텀 레이어 및 레시피 작성 (중급)
작성하신
led_server.c를 OS의 기본 구성 요소로 포함시키는 단계입니다.
(1) Custom Layer 생성: bitbake-layers create-layer meta-my-led 명령으로 나만의 레이어를 만듭니다.
(2) Recipe 작성: led-server.bb 파일을 만들어 libgpiod 의존성을 추가하고, 컴파일 규칙을 적습니다.
(3) 이미지 포함: 빌드 결과물에 내가 만든 서버 프로그램이 /usr/bin 등에 자동으로 들어가도록 설정합니다.
☑️ Level 3: 시스템 최적화 및 자동화 (고급)
실제 CCTV 제품처럼 전원을 켜자마자 서버가 돌고 관리하기 편한 상태로 만듭니다.
(1) Systemd 서비스 등록: 리눅스가 부팅될 때 LED 서버가 자동으로 실행되도록 systemd 서비스 유닛을 레시피에 추가합니다.
(2) 패키지 그룹 관리: tcpdump나 strace 같은 디버깅 도구를 포함할지 말지를 Yocto 설정을 통해 결정합니다.
(3) SDK 생성: 팀원들이 내 빌드 환경 없이도 코드를 짤 수 있게 SDK를 추출(-c populate_sdk)합니다.
